
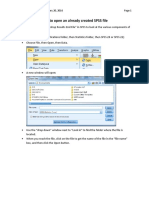
SPSS - What Is It?: SPSS - Quick Overview Main Features
SPSS - What Is It?: SPSS - Quick Overview Main Features
You might also like
- Differentiating Instruction in Response To Student Learning Interest in Araling PanlipunanDocument6 pagesDifferentiating Instruction in Response To Student Learning Interest in Araling PanlipunanJohnny Abad100% (1)
- ACTS Prayer SampleDocument1 pageACTS Prayer SampleJohnny Abad100% (2)
- RM PRACTICAL FILE RekhaDocument37 pagesRM PRACTICAL FILE RekhaRekha RawatNo ratings yet
- SPSS AssignmentDocument8 pagesSPSS AssignmentYamini JohriNo ratings yet
- RM Project DevanshDocument65 pagesRM Project DevanshGautam KumarNo ratings yet
- Andy Field Using SpssDocument115 pagesAndy Field Using SpssRomer GesmundoNo ratings yet
- Experiment-1 1Document10 pagesExperiment-1 1Ishika SrivastavaNo ratings yet
- SPSSDocument3 pagesSPSSAmbreen SabaNo ratings yet
- Furman University Statistics Using SPSSDocument117 pagesFurman University Statistics Using SPSSRomer GesmundoNo ratings yet
- SPSS: A Tool For Survey Analysis: Alok Kumar PGDM 2 YearDocument3 pagesSPSS: A Tool For Survey Analysis: Alok Kumar PGDM 2 YearRonavlau LauganasNo ratings yet
- Lab Manual Practical 1Document11 pagesLab Manual Practical 1Gaurav Rajput100% (1)
- Lab Manual Practical 1Document11 pagesLab Manual Practical 1Gaurav RajputNo ratings yet
- Sample PROJECT RM LabDocument39 pagesSample PROJECT RM LabVinay SinghNo ratings yet
- SpssDocument16 pagesSpssSUMITNo ratings yet
- Data Management & SPSS: Khan Sarfaraz AliDocument10 pagesData Management & SPSS: Khan Sarfaraz AliDr. Khan Sarfaraz AliNo ratings yet
- Very Basics PssDocument61 pagesVery Basics PssthenameoftrustNo ratings yet
- An Introduction To JASP: A Free and User-Friendly Statistics PackageDocument13 pagesAn Introduction To JASP: A Free and User-Friendly Statistics PackageGianni BasileNo ratings yet
- Lesson 1 SPSS Windows and FilesDocument125 pagesLesson 1 SPSS Windows and FilesEnatnesh AsayeNo ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDARamyLloydLotillaNo ratings yet
- Data Preparation With SPSS: History of Data Analysis in PsychologyDocument9 pagesData Preparation With SPSS: History of Data Analysis in PsychologyBharichalo007No ratings yet
- (Ebook PDF) - Statistics. .Spss - TutorialDocument15 pages(Ebook PDF) - Statistics. .Spss - TutorialMASAIER4394% (17)
- SPSSDocument18 pagesSPSSSnow DropNo ratings yet
- Experimental WorksheetDocument8 pagesExperimental WorksheetAlPHA NiNjANo ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDAscr33nwriterNo ratings yet
- A Quick and Easy Guide in Using SPSS for Linear Regression AnalysisFrom EverandA Quick and Easy Guide in Using SPSS for Linear Regression AnalysisNo ratings yet
- SPSSDocument12 pagesSPSSSuhotra GuptaNo ratings yet
- RM Practical FileDocument59 pagesRM Practical Filegarvit sharmaNo ratings yet
- Spss Coursework HelpDocument8 pagesSpss Coursework Helpfzdpofajd100% (2)
- Workshop Series: ContentsDocument10 pagesWorkshop Series: ContentsAnonymous kTVBUxrNo ratings yet
- SPSS For The Classroom - The BasicsDocument1 pageSPSS For The Classroom - The BasicsBirikset ZemedkunNo ratings yet
- Module 2 Introduction To SPSS - WordDocument17 pagesModule 2 Introduction To SPSS - WordJordine UmayamNo ratings yet
- SPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataFrom EverandSPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataNo ratings yet
- Hans Raj Mahila Maha Vidyalaya: Submitted To: Submitted byDocument35 pagesHans Raj Mahila Maha Vidyalaya: Submitted To: Submitted by04 Shaina SachdevaNo ratings yet
- Analysis of Statistical Software With Special Reference To Statistical Package For Social Sciences (SPSS)Document29 pagesAnalysis of Statistical Software With Special Reference To Statistical Package For Social Sciences (SPSS)ShrutiNo ratings yet
- Analysing Quantitative Data Using SPSS 10 For WindowsDocument31 pagesAnalysing Quantitative Data Using SPSS 10 For Windowsपशुपति नाथNo ratings yet
- Research Paper Using SpssDocument9 pagesResearch Paper Using Spssfyrqkxfq100% (1)
- SpssDocument50 pagesSpssTech_MXNo ratings yet
- Quantitative TechniquesDocument18 pagesQuantitative TechniquesJithin JohnNo ratings yet
- Spss Workshop NotesDocument20 pagesSpss Workshop Notesfrancisco_araujo_22100% (2)
- Data Collection and OrganizationDocument3 pagesData Collection and OrganizationRuby SmithNo ratings yet
- SPSS Program TutorialsDocument50 pagesSPSS Program TutorialsAmer A. HasanNo ratings yet
- Introduction To SpssDocument48 pagesIntroduction To Spssy.No ratings yet
- RESEARCHMETHODOLOGYLABDocument20 pagesRESEARCHMETHODOLOGYLABAtisha JainNo ratings yet
- SPSS Step-by-Step Tutorial: Part 1Document50 pagesSPSS Step-by-Step Tutorial: Part 1Ram Krishn PandeyNo ratings yet
- SPSS Tutorial by Dr. Rahul KulkarniDocument50 pagesSPSS Tutorial by Dr. Rahul KulkarniWasim PathanNo ratings yet
- Spss AssignmentDocument28 pagesSpss AssignmentAnu S R100% (1)
- SpssDocument23 pagesSpssGlenn OthersNo ratings yet
- SPSS Program FunctionalityDocument2 pagesSPSS Program Functionalityjashu negiNo ratings yet
- Document (2) 2Document11 pagesDocument (2) 2Rishi VandhyaNo ratings yet
- Spss Introduction Document-SahyadriDocument13 pagesSpss Introduction Document-Sahyadristarvindsouza91No ratings yet
- 17ME-ENV-48 SPSS PracticalDocument41 pages17ME-ENV-48 SPSS Practicalhmkalyar_118702895No ratings yet
- SPSSDocument22 pagesSPSS21PR15 Dinesh Kumar SNo ratings yet
- Final SSB Manual Mbn605 08.08Document46 pagesFinal SSB Manual Mbn605 08.08khanrules2012No ratings yet
- Spss Presentation by Nafees HashmiDocument35 pagesSpss Presentation by Nafees HashmiHoorya HashmiNo ratings yet
- طرق متقدمة في الإحصاء الحيوي بواسطة SPSSDocument194 pagesطرق متقدمة في الإحصاء الحيوي بواسطة SPSSsuleiman.abuhasaneinNo ratings yet
- Part I: SPSS and Data Analysis: ExerciseDocument6 pagesPart I: SPSS and Data Analysis: ExercisefhgfghgfhNo ratings yet
- Top 50 SAS Interview Questions For 2019 - SAS Training - Edureka PDFDocument9 pagesTop 50 SAS Interview Questions For 2019 - SAS Training - Edureka PDFSudhanshu KumarNo ratings yet
- Lesson 3 PDFDocument7 pagesLesson 3 PDFDmzjmb SaadNo ratings yet
- Spss CourseworkDocument5 pagesSpss Courseworkf5dt39tp100% (2)
- Experiment 2 - Lab 2.2Document7 pagesExperiment 2 - Lab 2.2ELYSIUMNo ratings yet
- SPSS ExtractDocument5 pagesSPSS ExtractakinNo ratings yet
- Base SAS Interview Questions You'll Most Likely Be AskedFrom EverandBase SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- Round HE Orld N 0 AYS: A T W I 8 DDocument4 pagesRound HE Orld N 0 AYS: A T W I 8 DJohnny AbadNo ratings yet
- Thanksgiving Mass High SchoolDocument41 pagesThanksgiving Mass High SchoolJohnny AbadNo ratings yet
- Filipino Trivia QuizDocument15 pagesFilipino Trivia QuizJohnny AbadNo ratings yet
- Factors Affecting Career Track and Strand ChoicesDocument32 pagesFactors Affecting Career Track and Strand ChoicesJohnny AbadNo ratings yet
- Class Observation Guide SHSDocument1 pageClass Observation Guide SHSJohnny AbadNo ratings yet
- Deed of SaleDocument2 pagesDeed of SaleJohnny AbadNo ratings yet
- Form 5 School Library Directory 1Document2 pagesForm 5 School Library Directory 1Johnny Abad100% (1)
- Remarks: Sample Club Academic 97 Yes No Poetry Reading, Book Fair National BookstoreDocument1 pageRemarks: Sample Club Academic 97 Yes No Poetry Reading, Book Fair National BookstoreJohnny AbadNo ratings yet
- Individual Learning Monitoring Plan ArPan-BelleDocument1 pageIndividual Learning Monitoring Plan ArPan-BelleJohnny AbadNo ratings yet
- RM No. 296, s.2020Document28 pagesRM No. 296, s.2020Johnny AbadNo ratings yet
- Guide Lines On How To Study Our PreDocument2 pagesGuide Lines On How To Study Our PreJohnny AbadNo ratings yet
- Looking Back Series OutlineDocument1 pageLooking Back Series OutlineJohnny AbadNo ratings yet
- Sample MC Draft ScriptDocument2 pagesSample MC Draft ScriptJohnny AbadNo ratings yet
- How To Calibrate Your LaptopDocument6 pagesHow To Calibrate Your LaptopJohnny AbadNo ratings yet
- How To Speed Up A Slow IphoneDocument3 pagesHow To Speed Up A Slow IphoneJohnny AbadNo ratings yet
- CHAPTER 11: Dynamic Behaviour & Stability of Closed-Loop Control SystemsDocument69 pagesCHAPTER 11: Dynamic Behaviour & Stability of Closed-Loop Control Systemshakita86No ratings yet
- Qualitative Data Analysis - 2Document30 pagesQualitative Data Analysis - 2Nas AronzsNo ratings yet
- EmpiricismDocument8 pagesEmpiricismIrfan U Shah75% (4)
- Grade 10 Physics Week 1 Lesson 2 Worksheet 1 and AnswersheetDocument2 pagesGrade 10 Physics Week 1 Lesson 2 Worksheet 1 and AnswersheetDaniel DowdingNo ratings yet
- Comsol Multiphysics Tips and TricksDocument11 pagesComsol Multiphysics Tips and TricksYaser AkarNo ratings yet
- Scikit Learn Infographic PDFDocument1 pageScikit Learn Infographic PDFRohit GhaiNo ratings yet
- Gr-6 Math-1st To 4thDocument291 pagesGr-6 Math-1st To 4thRachel Macanas Fabilane-Dela Peña100% (1)
- 7 Equations To Build A Secure RetirementDocument9 pages7 Equations To Build A Secure RetirementSatinder BhallaNo ratings yet
- Quantum Mechanics The Key To Understanding MagnetismDocument17 pagesQuantum Mechanics The Key To Understanding Magnetismnicusor.iacob5680No ratings yet
- Parking TorquesDocument17 pagesParking TorquesIlijaBošković100% (1)
- Casebook: EditionDocument30 pagesCasebook: EditionNaura TsabitaNo ratings yet
- Statistics Module IDocument94 pagesStatistics Module ILove Is100% (1)
- DPP (19-21) 11th J-Batch MathsDocument10 pagesDPP (19-21) 11th J-Batch MathsRaju SinghNo ratings yet
- 14.0 Quadratic Function Word Problems1Document2 pages14.0 Quadratic Function Word Problems1Elgen B. AgravanteNo ratings yet
- Core Mathematics C1: Pearson Edexcel GCEDocument28 pagesCore Mathematics C1: Pearson Edexcel GCEni99leNo ratings yet
- Fourier Transform PDFDocument26 pagesFourier Transform PDFAnonymous JgrIK6LNo ratings yet
- Add Maths Diagnostic Test - PretestDocument5 pagesAdd Maths Diagnostic Test - PretestzuNo ratings yet
- Broman HolditchDocument11 pagesBroman HolditchTekitoNo ratings yet
- 222222Document11 pages222222pak bosssNo ratings yet
- Tbtrans ScreenDocument31 pagesTbtrans ScreenLevema SiraNo ratings yet
- Examples Dfa PDFDocument2 pagesExamples Dfa PDFShawn0% (1)
- Syllabus For B. Tech in Electrical EngineeringDocument20 pagesSyllabus For B. Tech in Electrical EngineeringRISHAV kumarNo ratings yet
- Final Syllabus B. Tech Chemical Engineering March 2015Document69 pagesFinal Syllabus B. Tech Chemical Engineering March 2015SHIVAM CHATURVEDI IET Lucknow StudentNo ratings yet
- Math6 - Q2 - WEEK 2 - V2 Finally Approved For Printing 4Document10 pagesMath6 - Q2 - WEEK 2 - V2 Finally Approved For Printing 4Mariel SalazarNo ratings yet
- 02 Assignments MECDocument22 pages02 Assignments MECWillis ChekovNo ratings yet
- Types of Black HolesDocument3 pagesTypes of Black HolesAbhigit KashyapNo ratings yet
- 4 5 Applications of Circles NotesDocument13 pages4 5 Applications of Circles Notesapi-27677453950% (2)
- Class 9 Maths Project and Group ActivityDocument18 pagesClass 9 Maths Project and Group ActivitySanjit PaulNo ratings yet
- CH 17 - 03 - Gausses LawDocument44 pagesCH 17 - 03 - Gausses LawJeanetteNo ratings yet
- Hacon UmDocument88 pagesHacon UmTiago CoutoNo ratings yet










































































































Download as docx, pdf, or txt
You might also like
- Differentiating Instruction in Response To Student Learning Interest in Araling PanlipunanDocument6 pagesDifferentiating Instruction in Response To Student Learning Interest in Araling PanlipunanJohnny Abad100% (1)
- ACTS Prayer SampleDocument1 pageACTS Prayer SampleJohnny Abad100% (2)
- RM PRACTICAL FILE RekhaDocument37 pagesRM PRACTICAL FILE RekhaRekha RawatNo ratings yet
- SPSS AssignmentDocument8 pagesSPSS AssignmentYamini JohriNo ratings yet
- RM Project DevanshDocument65 pagesRM Project DevanshGautam KumarNo ratings yet
- Andy Field Using SpssDocument115 pagesAndy Field Using SpssRomer GesmundoNo ratings yet
- Experiment-1 1Document10 pagesExperiment-1 1Ishika SrivastavaNo ratings yet
- SPSSDocument3 pagesSPSSAmbreen SabaNo ratings yet
- Furman University Statistics Using SPSSDocument117 pagesFurman University Statistics Using SPSSRomer GesmundoNo ratings yet
- SPSS: A Tool For Survey Analysis: Alok Kumar PGDM 2 YearDocument3 pagesSPSS: A Tool For Survey Analysis: Alok Kumar PGDM 2 YearRonavlau LauganasNo ratings yet
- Lab Manual Practical 1Document11 pagesLab Manual Practical 1Gaurav Rajput100% (1)
- Lab Manual Practical 1Document11 pagesLab Manual Practical 1Gaurav RajputNo ratings yet
- Sample PROJECT RM LabDocument39 pagesSample PROJECT RM LabVinay SinghNo ratings yet
- SpssDocument16 pagesSpssSUMITNo ratings yet
- Data Management & SPSS: Khan Sarfaraz AliDocument10 pagesData Management & SPSS: Khan Sarfaraz AliDr. Khan Sarfaraz AliNo ratings yet
- Very Basics PssDocument61 pagesVery Basics PssthenameoftrustNo ratings yet
- An Introduction To JASP: A Free and User-Friendly Statistics PackageDocument13 pagesAn Introduction To JASP: A Free and User-Friendly Statistics PackageGianni BasileNo ratings yet
- Lesson 1 SPSS Windows and FilesDocument125 pagesLesson 1 SPSS Windows and FilesEnatnesh AsayeNo ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDARamyLloydLotillaNo ratings yet
- Data Preparation With SPSS: History of Data Analysis in PsychologyDocument9 pagesData Preparation With SPSS: History of Data Analysis in PsychologyBharichalo007No ratings yet
- (Ebook PDF) - Statistics. .Spss - TutorialDocument15 pages(Ebook PDF) - Statistics. .Spss - TutorialMASAIER4394% (17)
- SPSSDocument18 pagesSPSSSnow DropNo ratings yet
- Experimental WorksheetDocument8 pagesExperimental WorksheetAlPHA NiNjANo ratings yet
- Learning SPSS: Data and EDADocument40 pagesLearning SPSS: Data and EDAscr33nwriterNo ratings yet
- A Quick and Easy Guide in Using SPSS for Linear Regression AnalysisFrom EverandA Quick and Easy Guide in Using SPSS for Linear Regression AnalysisNo ratings yet
- SPSSDocument12 pagesSPSSSuhotra GuptaNo ratings yet
- RM Practical FileDocument59 pagesRM Practical Filegarvit sharmaNo ratings yet
- Spss Coursework HelpDocument8 pagesSpss Coursework Helpfzdpofajd100% (2)
- Workshop Series: ContentsDocument10 pagesWorkshop Series: ContentsAnonymous kTVBUxrNo ratings yet
- SPSS For The Classroom - The BasicsDocument1 pageSPSS For The Classroom - The BasicsBirikset ZemedkunNo ratings yet
- Module 2 Introduction To SPSS - WordDocument17 pagesModule 2 Introduction To SPSS - WordJordine UmayamNo ratings yet
- SPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataFrom EverandSPSS For Beginners: An Illustrative Step-by-Step Approach to Analyzing Statistical dataNo ratings yet
- Hans Raj Mahila Maha Vidyalaya: Submitted To: Submitted byDocument35 pagesHans Raj Mahila Maha Vidyalaya: Submitted To: Submitted by04 Shaina SachdevaNo ratings yet
- Analysis of Statistical Software With Special Reference To Statistical Package For Social Sciences (SPSS)Document29 pagesAnalysis of Statistical Software With Special Reference To Statistical Package For Social Sciences (SPSS)ShrutiNo ratings yet
- Analysing Quantitative Data Using SPSS 10 For WindowsDocument31 pagesAnalysing Quantitative Data Using SPSS 10 For Windowsपशुपति नाथNo ratings yet
- Research Paper Using SpssDocument9 pagesResearch Paper Using Spssfyrqkxfq100% (1)
- SpssDocument50 pagesSpssTech_MXNo ratings yet
- Quantitative TechniquesDocument18 pagesQuantitative TechniquesJithin JohnNo ratings yet
- Spss Workshop NotesDocument20 pagesSpss Workshop Notesfrancisco_araujo_22100% (2)
- Data Collection and OrganizationDocument3 pagesData Collection and OrganizationRuby SmithNo ratings yet
- SPSS Program TutorialsDocument50 pagesSPSS Program TutorialsAmer A. HasanNo ratings yet
- Introduction To SpssDocument48 pagesIntroduction To Spssy.No ratings yet
- RESEARCHMETHODOLOGYLABDocument20 pagesRESEARCHMETHODOLOGYLABAtisha JainNo ratings yet
- SPSS Step-by-Step Tutorial: Part 1Document50 pagesSPSS Step-by-Step Tutorial: Part 1Ram Krishn PandeyNo ratings yet
- SPSS Tutorial by Dr. Rahul KulkarniDocument50 pagesSPSS Tutorial by Dr. Rahul KulkarniWasim PathanNo ratings yet
- Spss AssignmentDocument28 pagesSpss AssignmentAnu S R100% (1)
- SpssDocument23 pagesSpssGlenn OthersNo ratings yet
- SPSS Program FunctionalityDocument2 pagesSPSS Program Functionalityjashu negiNo ratings yet
- Document (2) 2Document11 pagesDocument (2) 2Rishi VandhyaNo ratings yet
- Spss Introduction Document-SahyadriDocument13 pagesSpss Introduction Document-Sahyadristarvindsouza91No ratings yet
- 17ME-ENV-48 SPSS PracticalDocument41 pages17ME-ENV-48 SPSS Practicalhmkalyar_118702895No ratings yet
- SPSSDocument22 pagesSPSS21PR15 Dinesh Kumar SNo ratings yet
- Final SSB Manual Mbn605 08.08Document46 pagesFinal SSB Manual Mbn605 08.08khanrules2012No ratings yet
- Spss Presentation by Nafees HashmiDocument35 pagesSpss Presentation by Nafees HashmiHoorya HashmiNo ratings yet
- طرق متقدمة في الإحصاء الحيوي بواسطة SPSSDocument194 pagesطرق متقدمة في الإحصاء الحيوي بواسطة SPSSsuleiman.abuhasaneinNo ratings yet
- Part I: SPSS and Data Analysis: ExerciseDocument6 pagesPart I: SPSS and Data Analysis: ExercisefhgfghgfhNo ratings yet
- Top 50 SAS Interview Questions For 2019 - SAS Training - Edureka PDFDocument9 pagesTop 50 SAS Interview Questions For 2019 - SAS Training - Edureka PDFSudhanshu KumarNo ratings yet
- Lesson 3 PDFDocument7 pagesLesson 3 PDFDmzjmb SaadNo ratings yet
- Spss CourseworkDocument5 pagesSpss Courseworkf5dt39tp100% (2)
- Experiment 2 - Lab 2.2Document7 pagesExperiment 2 - Lab 2.2ELYSIUMNo ratings yet
- SPSS ExtractDocument5 pagesSPSS ExtractakinNo ratings yet
- Base SAS Interview Questions You'll Most Likely Be AskedFrom EverandBase SAS Interview Questions You'll Most Likely Be AskedNo ratings yet
- Round HE Orld N 0 AYS: A T W I 8 DDocument4 pagesRound HE Orld N 0 AYS: A T W I 8 DJohnny AbadNo ratings yet
- Thanksgiving Mass High SchoolDocument41 pagesThanksgiving Mass High SchoolJohnny AbadNo ratings yet
- Filipino Trivia QuizDocument15 pagesFilipino Trivia QuizJohnny AbadNo ratings yet
- Factors Affecting Career Track and Strand ChoicesDocument32 pagesFactors Affecting Career Track and Strand ChoicesJohnny AbadNo ratings yet
- Class Observation Guide SHSDocument1 pageClass Observation Guide SHSJohnny AbadNo ratings yet
- Deed of SaleDocument2 pagesDeed of SaleJohnny AbadNo ratings yet
- Form 5 School Library Directory 1Document2 pagesForm 5 School Library Directory 1Johnny Abad100% (1)
- Remarks: Sample Club Academic 97 Yes No Poetry Reading, Book Fair National BookstoreDocument1 pageRemarks: Sample Club Academic 97 Yes No Poetry Reading, Book Fair National BookstoreJohnny AbadNo ratings yet
- Individual Learning Monitoring Plan ArPan-BelleDocument1 pageIndividual Learning Monitoring Plan ArPan-BelleJohnny AbadNo ratings yet
- RM No. 296, s.2020Document28 pagesRM No. 296, s.2020Johnny AbadNo ratings yet
- Guide Lines On How To Study Our PreDocument2 pagesGuide Lines On How To Study Our PreJohnny AbadNo ratings yet
- Looking Back Series OutlineDocument1 pageLooking Back Series OutlineJohnny AbadNo ratings yet
- Sample MC Draft ScriptDocument2 pagesSample MC Draft ScriptJohnny AbadNo ratings yet
- How To Calibrate Your LaptopDocument6 pagesHow To Calibrate Your LaptopJohnny AbadNo ratings yet
- How To Speed Up A Slow IphoneDocument3 pagesHow To Speed Up A Slow IphoneJohnny AbadNo ratings yet
- CHAPTER 11: Dynamic Behaviour & Stability of Closed-Loop Control SystemsDocument69 pagesCHAPTER 11: Dynamic Behaviour & Stability of Closed-Loop Control Systemshakita86No ratings yet
- Qualitative Data Analysis - 2Document30 pagesQualitative Data Analysis - 2Nas AronzsNo ratings yet
- EmpiricismDocument8 pagesEmpiricismIrfan U Shah75% (4)
- Grade 10 Physics Week 1 Lesson 2 Worksheet 1 and AnswersheetDocument2 pagesGrade 10 Physics Week 1 Lesson 2 Worksheet 1 and AnswersheetDaniel DowdingNo ratings yet
- Comsol Multiphysics Tips and TricksDocument11 pagesComsol Multiphysics Tips and TricksYaser AkarNo ratings yet
- Scikit Learn Infographic PDFDocument1 pageScikit Learn Infographic PDFRohit GhaiNo ratings yet
- Gr-6 Math-1st To 4thDocument291 pagesGr-6 Math-1st To 4thRachel Macanas Fabilane-Dela Peña100% (1)
- 7 Equations To Build A Secure RetirementDocument9 pages7 Equations To Build A Secure RetirementSatinder BhallaNo ratings yet
- Quantum Mechanics The Key To Understanding MagnetismDocument17 pagesQuantum Mechanics The Key To Understanding Magnetismnicusor.iacob5680No ratings yet
- Parking TorquesDocument17 pagesParking TorquesIlijaBošković100% (1)
- Casebook: EditionDocument30 pagesCasebook: EditionNaura TsabitaNo ratings yet
- Statistics Module IDocument94 pagesStatistics Module ILove Is100% (1)
- DPP (19-21) 11th J-Batch MathsDocument10 pagesDPP (19-21) 11th J-Batch MathsRaju SinghNo ratings yet
- 14.0 Quadratic Function Word Problems1Document2 pages14.0 Quadratic Function Word Problems1Elgen B. AgravanteNo ratings yet
- Core Mathematics C1: Pearson Edexcel GCEDocument28 pagesCore Mathematics C1: Pearson Edexcel GCEni99leNo ratings yet
- Fourier Transform PDFDocument26 pagesFourier Transform PDFAnonymous JgrIK6LNo ratings yet
- Add Maths Diagnostic Test - PretestDocument5 pagesAdd Maths Diagnostic Test - PretestzuNo ratings yet
- Broman HolditchDocument11 pagesBroman HolditchTekitoNo ratings yet
- 222222Document11 pages222222pak bosssNo ratings yet
- Tbtrans ScreenDocument31 pagesTbtrans ScreenLevema SiraNo ratings yet
- Examples Dfa PDFDocument2 pagesExamples Dfa PDFShawn0% (1)
- Syllabus For B. Tech in Electrical EngineeringDocument20 pagesSyllabus For B. Tech in Electrical EngineeringRISHAV kumarNo ratings yet
- Final Syllabus B. Tech Chemical Engineering March 2015Document69 pagesFinal Syllabus B. Tech Chemical Engineering March 2015SHIVAM CHATURVEDI IET Lucknow StudentNo ratings yet
- Math6 - Q2 - WEEK 2 - V2 Finally Approved For Printing 4Document10 pagesMath6 - Q2 - WEEK 2 - V2 Finally Approved For Printing 4Mariel SalazarNo ratings yet
- 02 Assignments MECDocument22 pages02 Assignments MECWillis ChekovNo ratings yet
- Types of Black HolesDocument3 pagesTypes of Black HolesAbhigit KashyapNo ratings yet
- 4 5 Applications of Circles NotesDocument13 pages4 5 Applications of Circles Notesapi-27677453950% (2)
- Class 9 Maths Project and Group ActivityDocument18 pagesClass 9 Maths Project and Group ActivitySanjit PaulNo ratings yet
- CH 17 - 03 - Gausses LawDocument44 pagesCH 17 - 03 - Gausses LawJeanetteNo ratings yet
- Hacon UmDocument88 pagesHacon UmTiago CoutoNo ratings yet