
BAB IV Skripsi
BAB IV Skripsi
You might also like
- Chapter 3 Quantitative Research MethodologyDocument54 pagesChapter 3 Quantitative Research MethodologyClarence Dave T. TolentinoNo ratings yet
- Faulkner2017 Data SaturationDocument2 pagesFaulkner2017 Data SaturationSharida ShaharudinNo ratings yet
- Study Guide for Practical Statistics for EducatorsFrom EverandStudy Guide for Practical Statistics for EducatorsRating: 4 out of 5 stars4/5 (1)
- Nvivo 12 Training ManualDocument49 pagesNvivo 12 Training ManualDaniel Hernandez75% (4)
- Iii. Research MethodologyDocument16 pagesIii. Research MethodologyArindaa Rifana NabilaaNo ratings yet
- Chapter III ProposalDocument7 pagesChapter III Proposalainunr zkyNo ratings yet
- Bab 3 RasemaDocument19 pagesBab 3 RasemakrllpdsNo ratings yet
- CHAPTER III - EditedDocument15 pagesCHAPTER III - Editedwiwin saputraaNo ratings yet
- Chapter IiiDocument38 pagesChapter IiiAMIROTUL NABILAH BIG171No ratings yet
- Chapter 3 & AppendixDocument22 pagesChapter 3 & AppendixSyah MinaNo ratings yet
- Action ResearchDocument42 pagesAction Researchpatrick patinoNo ratings yet
- Fatimah Riska 2315030 CHAPTER IIIDocument6 pagesFatimah Riska 2315030 CHAPTER IIIAnnisa Nurhadi MayaNo ratings yet
- Research Methods A. Research Type and Design 1. Type of ResearchDocument26 pagesResearch Methods A. Research Type and Design 1. Type of ResearchParida AryaniNo ratings yet
- Utilization of IMRAD Format in Practical Research II and 3i's at Siena College of TaytayDocument9 pagesUtilization of IMRAD Format in Practical Research II and 3i's at Siena College of TaytayAriel Eliyah AbejuroNo ratings yet
- Chapter IiiDocument37 pagesChapter Iiin17048949No ratings yet
- Penerapan Model Pembelajaran Kooperatif Tipe Teams Games Tournament (TGT) Untuk Meningkatkan Keaktifan Dan Hasil Belajar Fisika Peserta DidikDocument16 pagesPenerapan Model Pembelajaran Kooperatif Tipe Teams Games Tournament (TGT) Untuk Meningkatkan Keaktifan Dan Hasil Belajar Fisika Peserta DidikSri Wahyu WidyaningsihNo ratings yet
- Bab IiiDocument19 pagesBab IiiAulia SantikaNo ratings yet
- Chapter Iii UswatunDocument9 pagesChapter Iii UswatunLisa RLNo ratings yet
- Chapter IiiDocument12 pagesChapter IiiNurhasanah SasmaliaNo ratings yet
- CHAPTER III Metode BasmalahDocument10 pagesCHAPTER III Metode BasmalahForney ZegaNo ratings yet
- Chapter Three ChineduDocument4 pagesChapter Three ChineduChinedu ChikezieNo ratings yet
- Bab IiiDocument9 pagesBab IiiKiki PratiwiNo ratings yet
- Chapter Iii True ExperimentalDocument15 pagesChapter Iii True Experimentalmiftachul ilmiNo ratings yet
- Bab 3Document15 pagesBab 3Dwyane CaliwanNo ratings yet
- RES 1 Learning ContentDocument14 pagesRES 1 Learning ContentJaycob NazarenoNo ratings yet
- Chapter IiiDocument6 pagesChapter IiiMuhammad RamadhaniNo ratings yet
- MATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataDocument16 pagesMATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataJeann DelacruzNo ratings yet
- Chapter Ii1Document12 pagesChapter Ii1Agus SetiadiNo ratings yet
- Chapter III-WPS OfficeDocument11 pagesChapter III-WPS OfficeStar Gunao SwiftNo ratings yet
- Reaserahc PapiersDocument11 pagesReaserahc Papiersfree booksNo ratings yet
- Chapter IIIDocument18 pagesChapter IIIAji WijayaNo ratings yet
- Chapter IiDocument7 pagesChapter IiMuhammad RamadhaniNo ratings yet
- Bab 3Document15 pagesBab 3ancu kahuNo ratings yet
- Formulating Statistical Mini ResearchDocument34 pagesFormulating Statistical Mini Researchcharityjoyvitug07No ratings yet
- Chapter 3Document5 pagesChapter 3Mary Cris MalanoNo ratings yet
- Formulating Statistical Mini-Research: Week 5 Fourth Quarter S.Y. 2020-2021Document34 pagesFormulating Statistical Mini-Research: Week 5 Fourth Quarter S.Y. 2020-2021Eric de Guzman83% (6)
- CHAPTER III Mr. BambangDocument18 pagesCHAPTER III Mr. BambangTaju DeenNo ratings yet
- Portfolio-Work ImmersionDocument32 pagesPortfolio-Work Immersionbabyboy boogyNo ratings yet
- Chapter IIIDocument6 pagesChapter IIIAkrom M. AlhaqNo ratings yet
- Chapter 3 MethodologyDocument9 pagesChapter 3 MethodologyMerry Rose Angeles SoroNo ratings yet
- CHAPTER THREE Docx - SalmyDocument6 pagesCHAPTER THREE Docx - SalmySamaila ShamsuddeenNo ratings yet
- Q4-APPLIED-Practical Research 2-12-Weeks3-4Document2 pagesQ4-APPLIED-Practical Research 2-12-Weeks3-4KIM ANN OPENA VILLAROSANo ratings yet
- Practical Research 2: Quarter 2: Module 1-4Document31 pagesPractical Research 2: Quarter 2: Module 1-4Jan Bryan ManguaNo ratings yet
- Chapter IIIDocument22 pagesChapter IIIarilricky5No ratings yet
- Yuda Chapter 3Document3 pagesYuda Chapter 3indra yudaNo ratings yet
- Bab Iii KokamiDocument6 pagesBab Iii Kokaminabila husnaNo ratings yet
- Chapter IIIDocument18 pagesChapter IIIElaiza Jane SisonNo ratings yet
- S Pts 055132 Chapter3Document19 pagesS Pts 055132 Chapter3Legenda P. PratamaNo ratings yet
- Mezi Yulia Astuti, Heffi Alberida, Yosi Laila Rahmi: PendahuluanDocument8 pagesMezi Yulia Astuti, Heffi Alberida, Yosi Laila Rahmi: PendahuluanWàîțýNo ratings yet
- Chapter III - FinishedDocument9 pagesChapter III - Finishedagus mustofaNo ratings yet
- Practical Research 2 Module 8Document12 pagesPractical Research 2 Module 8Izza Furto0% (1)
- Chapter 3Document7 pagesChapter 3level xxiiiNo ratings yet
- Chapter III - MethodologyDocument3 pagesChapter III - MethodologyAlthea OrolazaNo ratings yet
- Research HHH KkoDocument10 pagesResearch HHH KkoMira CuevasNo ratings yet
- Chapter Iii Research MethodologyDocument15 pagesChapter Iii Research MethodologyStar Gunao SwiftNo ratings yet
- MethodologyDocument4 pagesMethodologyChristhel Kaye MametesNo ratings yet
- UntitledDocument8 pagesUntitledCon D RianoNo ratings yet
- Bab 3Document2 pagesBab 3Denesti AliNo ratings yet
- Sample 2. Research MethodsDocument16 pagesSample 2. Research MethodsXuan ThanhNo ratings yet
- Chapter IiiDocument10 pagesChapter IiiSheryl JesslynNo ratings yet
- Mmwresearch PDFDocument18 pagesMmwresearch PDFMARIA VERONICA ANA CALLORINANo ratings yet
- Statistical Methods for Validation of Assessment Scale Data in Counseling and Related FieldsFrom EverandStatistical Methods for Validation of Assessment Scale Data in Counseling and Related FieldsNo ratings yet
- 608-621.ercan JBSE Vol.13 No.5Document14 pages608-621.ercan JBSE Vol.13 No.5GufronNo ratings yet
- Impact of Multimedia-Aided Teaching On Students' Academic Achievement and Attitude at Elementary LevelDocument12 pagesImpact of Multimedia-Aided Teaching On Students' Academic Achievement and Attitude at Elementary LevelGufronNo ratings yet
- 12-22-1-SM Daftar PustakaDocument8 pages12-22-1-SM Daftar PustakaGufronNo ratings yet
- Development of An Interactive Multimedia InstructionalDocument14 pagesDevelopment of An Interactive Multimedia InstructionalGufronNo ratings yet
- Sentence Comprehension and Working Memory Limitation in Aphasia: A Dissociation Between Semantic-Syntactic and Phonological ReactivationDocument17 pagesSentence Comprehension and Working Memory Limitation in Aphasia: A Dissociation Between Semantic-Syntactic and Phonological ReactivationGufronNo ratings yet
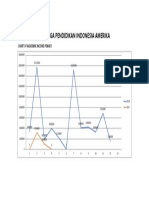
- Lembaga Pendidikan Indonesia Amerika: Chart of Academic Income (Yearly)Document1 pageLembaga Pendidikan Indonesia Amerika: Chart of Academic Income (Yearly)GufronNo ratings yet
- Analysis Second Edition. London: Routledge: Daftar PustakaDocument3 pagesAnalysis Second Edition. London: Routledge: Daftar PustakaGufronNo ratings yet
- The Effect of Local Wisdom-Based Speaking Instruction On Students' Motivation (An Experimental Research at Grade XI of SMA Negeri 1 Kasokandel)Document1 pageThe Effect of Local Wisdom-Based Speaking Instruction On Students' Motivation (An Experimental Research at Grade XI of SMA Negeri 1 Kasokandel)GufronNo ratings yet
- Lead2Pass Latest Free Oracle 1Z0 060 Dumps (81 90) Download!Document5 pagesLead2Pass Latest Free Oracle 1Z0 060 Dumps (81 90) Download!aaNo ratings yet
- Archpurg - GL BalancesDocument10 pagesArchpurg - GL BalancesSriram KalidossNo ratings yet
- Chapitre 4Document80 pagesChapitre 4Chaima BelhediNo ratings yet
- Data Governance: Higher EducationDocument12 pagesData Governance: Higher EducationHeru NugrohoNo ratings yet
- Solved - Extracting Hostname From Filename - Inputs - Conf On... - Splunk CommunityDocument7 pagesSolved - Extracting Hostname From Filename - Inputs - Conf On... - Splunk CommunityVinuNo ratings yet
- Advocacy IntroductionDocument137 pagesAdvocacy IntroductionLaura Deotti100% (1)
- Query OptimizationDocument138 pagesQuery OptimizationRadu Borza100% (1)
- A Beginners Guide To Applied Educational Research Using ThematicDocument16 pagesA Beginners Guide To Applied Educational Research Using ThematicGetachew TegegneNo ratings yet
- Midterm Review/Practice For SQL and ConstraintsDocument27 pagesMidterm Review/Practice For SQL and ConstraintsMd. Rakibul HasanNo ratings yet
- GROUP 1 Conceptions of Privacy and The Values of Privacy LIVING in The IT ERADocument56 pagesGROUP 1 Conceptions of Privacy and The Values of Privacy LIVING in The IT ERAina gastadorNo ratings yet
- Book V11gDocument46 pagesBook V11gdescaerNo ratings yet
- Molin 6Document45 pagesMolin 6Yor - ChannelNo ratings yet
- Technical Overview of Data ExchangeDocument35 pagesTechnical Overview of Data ExchangetopankajsharmaNo ratings yet
- EWM SourceDocument2 pagesEWM SourceRaghavendra MJNo ratings yet
- Toad For SQL Server 6.8: Release NotesDocument60 pagesToad For SQL Server 6.8: Release NotesLitzana Rodriguez BautistaNo ratings yet
- Storage Area Network (SAN)Document81 pagesStorage Area Network (SAN)anonymous_9888No ratings yet
- Gate Question On DbmsDocument5 pagesGate Question On DbmsNallala Satya venkata rama krishnaNo ratings yet
- ERD Optionality: OOD Inge PowellDocument19 pagesERD Optionality: OOD Inge PowellSuhayfa AbdulrahmanNo ratings yet
- Xii Preboard1 QP Set BDocument10 pagesXii Preboard1 QP Set BRishika VermaNo ratings yet
- Introduction To BIDocument1 pageIntroduction To BIZubeen ShahNo ratings yet
- Infobright ICE User GuideDocument62 pagesInfobright ICE User Guidepeterpan107No ratings yet
- Developing Digital Worksheet by Using Wizer - Me For Teaching Listening Skill To The Tenth Grade Students in SMK Negeri 7 MedanDocument13 pagesDeveloping Digital Worksheet by Using Wizer - Me For Teaching Listening Skill To The Tenth Grade Students in SMK Negeri 7 MedanargugNo ratings yet
- Py ExcelDocument152 pagesPy ExcelLakshmi KiranNo ratings yet
- 3is FORMATDocument10 pages3is FORMATAlbert Manzano Labra0% (1)
- Tunning Oracle Reports 6iDocument24 pagesTunning Oracle Reports 6iMelvin GrijalbaNo ratings yet
- ABAP - Data DictionaryDocument30 pagesABAP - Data DictionarysatishputranNo ratings yet
- File IODocument26 pagesFile IOKobo ChowNo ratings yet
- Oracle TestkingDocument41 pagesOracle TestkingGhanou StarlineNo ratings yet
































































































Download as docx, pdf, or txt
You might also like
- Chapter 3 Quantitative Research MethodologyDocument54 pagesChapter 3 Quantitative Research MethodologyClarence Dave T. TolentinoNo ratings yet
- Faulkner2017 Data SaturationDocument2 pagesFaulkner2017 Data SaturationSharida ShaharudinNo ratings yet
- Study Guide for Practical Statistics for EducatorsFrom EverandStudy Guide for Practical Statistics for EducatorsRating: 4 out of 5 stars4/5 (1)
- Nvivo 12 Training ManualDocument49 pagesNvivo 12 Training ManualDaniel Hernandez75% (4)
- Iii. Research MethodologyDocument16 pagesIii. Research MethodologyArindaa Rifana NabilaaNo ratings yet
- Chapter III ProposalDocument7 pagesChapter III Proposalainunr zkyNo ratings yet
- Bab 3 RasemaDocument19 pagesBab 3 RasemakrllpdsNo ratings yet
- CHAPTER III - EditedDocument15 pagesCHAPTER III - Editedwiwin saputraaNo ratings yet
- Chapter IiiDocument38 pagesChapter IiiAMIROTUL NABILAH BIG171No ratings yet
- Chapter 3 & AppendixDocument22 pagesChapter 3 & AppendixSyah MinaNo ratings yet
- Action ResearchDocument42 pagesAction Researchpatrick patinoNo ratings yet
- Fatimah Riska 2315030 CHAPTER IIIDocument6 pagesFatimah Riska 2315030 CHAPTER IIIAnnisa Nurhadi MayaNo ratings yet
- Research Methods A. Research Type and Design 1. Type of ResearchDocument26 pagesResearch Methods A. Research Type and Design 1. Type of ResearchParida AryaniNo ratings yet
- Utilization of IMRAD Format in Practical Research II and 3i's at Siena College of TaytayDocument9 pagesUtilization of IMRAD Format in Practical Research II and 3i's at Siena College of TaytayAriel Eliyah AbejuroNo ratings yet
- Chapter IiiDocument37 pagesChapter Iiin17048949No ratings yet
- Penerapan Model Pembelajaran Kooperatif Tipe Teams Games Tournament (TGT) Untuk Meningkatkan Keaktifan Dan Hasil Belajar Fisika Peserta DidikDocument16 pagesPenerapan Model Pembelajaran Kooperatif Tipe Teams Games Tournament (TGT) Untuk Meningkatkan Keaktifan Dan Hasil Belajar Fisika Peserta DidikSri Wahyu WidyaningsihNo ratings yet
- Bab IiiDocument19 pagesBab IiiAulia SantikaNo ratings yet
- Chapter Iii UswatunDocument9 pagesChapter Iii UswatunLisa RLNo ratings yet
- Chapter IiiDocument12 pagesChapter IiiNurhasanah SasmaliaNo ratings yet
- CHAPTER III Metode BasmalahDocument10 pagesCHAPTER III Metode BasmalahForney ZegaNo ratings yet
- Chapter Three ChineduDocument4 pagesChapter Three ChineduChinedu ChikezieNo ratings yet
- Bab IiiDocument9 pagesBab IiiKiki PratiwiNo ratings yet
- Chapter Iii True ExperimentalDocument15 pagesChapter Iii True Experimentalmiftachul ilmiNo ratings yet
- Bab 3Document15 pagesBab 3Dwyane CaliwanNo ratings yet
- RES 1 Learning ContentDocument14 pagesRES 1 Learning ContentJaycob NazarenoNo ratings yet
- Chapter IiiDocument6 pagesChapter IiiMuhammad RamadhaniNo ratings yet
- MATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataDocument16 pagesMATH 101-WEEK 7-8-HANDOUT-Managing and Understanding DataJeann DelacruzNo ratings yet
- Chapter Ii1Document12 pagesChapter Ii1Agus SetiadiNo ratings yet
- Chapter III-WPS OfficeDocument11 pagesChapter III-WPS OfficeStar Gunao SwiftNo ratings yet
- Reaserahc PapiersDocument11 pagesReaserahc Papiersfree booksNo ratings yet
- Chapter IIIDocument18 pagesChapter IIIAji WijayaNo ratings yet
- Chapter IiDocument7 pagesChapter IiMuhammad RamadhaniNo ratings yet
- Bab 3Document15 pagesBab 3ancu kahuNo ratings yet
- Formulating Statistical Mini ResearchDocument34 pagesFormulating Statistical Mini Researchcharityjoyvitug07No ratings yet
- Chapter 3Document5 pagesChapter 3Mary Cris MalanoNo ratings yet
- Formulating Statistical Mini-Research: Week 5 Fourth Quarter S.Y. 2020-2021Document34 pagesFormulating Statistical Mini-Research: Week 5 Fourth Quarter S.Y. 2020-2021Eric de Guzman83% (6)
- CHAPTER III Mr. BambangDocument18 pagesCHAPTER III Mr. BambangTaju DeenNo ratings yet
- Portfolio-Work ImmersionDocument32 pagesPortfolio-Work Immersionbabyboy boogyNo ratings yet
- Chapter IIIDocument6 pagesChapter IIIAkrom M. AlhaqNo ratings yet
- Chapter 3 MethodologyDocument9 pagesChapter 3 MethodologyMerry Rose Angeles SoroNo ratings yet
- CHAPTER THREE Docx - SalmyDocument6 pagesCHAPTER THREE Docx - SalmySamaila ShamsuddeenNo ratings yet
- Q4-APPLIED-Practical Research 2-12-Weeks3-4Document2 pagesQ4-APPLIED-Practical Research 2-12-Weeks3-4KIM ANN OPENA VILLAROSANo ratings yet
- Practical Research 2: Quarter 2: Module 1-4Document31 pagesPractical Research 2: Quarter 2: Module 1-4Jan Bryan ManguaNo ratings yet
- Chapter IIIDocument22 pagesChapter IIIarilricky5No ratings yet
- Yuda Chapter 3Document3 pagesYuda Chapter 3indra yudaNo ratings yet
- Bab Iii KokamiDocument6 pagesBab Iii Kokaminabila husnaNo ratings yet
- Chapter IIIDocument18 pagesChapter IIIElaiza Jane SisonNo ratings yet
- S Pts 055132 Chapter3Document19 pagesS Pts 055132 Chapter3Legenda P. PratamaNo ratings yet
- Mezi Yulia Astuti, Heffi Alberida, Yosi Laila Rahmi: PendahuluanDocument8 pagesMezi Yulia Astuti, Heffi Alberida, Yosi Laila Rahmi: PendahuluanWàîțýNo ratings yet
- Chapter III - FinishedDocument9 pagesChapter III - Finishedagus mustofaNo ratings yet
- Practical Research 2 Module 8Document12 pagesPractical Research 2 Module 8Izza Furto0% (1)
- Chapter 3Document7 pagesChapter 3level xxiiiNo ratings yet
- Chapter III - MethodologyDocument3 pagesChapter III - MethodologyAlthea OrolazaNo ratings yet
- Research HHH KkoDocument10 pagesResearch HHH KkoMira CuevasNo ratings yet
- Chapter Iii Research MethodologyDocument15 pagesChapter Iii Research MethodologyStar Gunao SwiftNo ratings yet
- MethodologyDocument4 pagesMethodologyChristhel Kaye MametesNo ratings yet
- UntitledDocument8 pagesUntitledCon D RianoNo ratings yet
- Bab 3Document2 pagesBab 3Denesti AliNo ratings yet
- Sample 2. Research MethodsDocument16 pagesSample 2. Research MethodsXuan ThanhNo ratings yet
- Chapter IiiDocument10 pagesChapter IiiSheryl JesslynNo ratings yet
- Mmwresearch PDFDocument18 pagesMmwresearch PDFMARIA VERONICA ANA CALLORINANo ratings yet
- Statistical Methods for Validation of Assessment Scale Data in Counseling and Related FieldsFrom EverandStatistical Methods for Validation of Assessment Scale Data in Counseling and Related FieldsNo ratings yet
- 608-621.ercan JBSE Vol.13 No.5Document14 pages608-621.ercan JBSE Vol.13 No.5GufronNo ratings yet
- Impact of Multimedia-Aided Teaching On Students' Academic Achievement and Attitude at Elementary LevelDocument12 pagesImpact of Multimedia-Aided Teaching On Students' Academic Achievement and Attitude at Elementary LevelGufronNo ratings yet
- 12-22-1-SM Daftar PustakaDocument8 pages12-22-1-SM Daftar PustakaGufronNo ratings yet
- Development of An Interactive Multimedia InstructionalDocument14 pagesDevelopment of An Interactive Multimedia InstructionalGufronNo ratings yet
- Sentence Comprehension and Working Memory Limitation in Aphasia: A Dissociation Between Semantic-Syntactic and Phonological ReactivationDocument17 pagesSentence Comprehension and Working Memory Limitation in Aphasia: A Dissociation Between Semantic-Syntactic and Phonological ReactivationGufronNo ratings yet
- Lembaga Pendidikan Indonesia Amerika: Chart of Academic Income (Yearly)Document1 pageLembaga Pendidikan Indonesia Amerika: Chart of Academic Income (Yearly)GufronNo ratings yet
- Analysis Second Edition. London: Routledge: Daftar PustakaDocument3 pagesAnalysis Second Edition. London: Routledge: Daftar PustakaGufronNo ratings yet
- The Effect of Local Wisdom-Based Speaking Instruction On Students' Motivation (An Experimental Research at Grade XI of SMA Negeri 1 Kasokandel)Document1 pageThe Effect of Local Wisdom-Based Speaking Instruction On Students' Motivation (An Experimental Research at Grade XI of SMA Negeri 1 Kasokandel)GufronNo ratings yet
- Lead2Pass Latest Free Oracle 1Z0 060 Dumps (81 90) Download!Document5 pagesLead2Pass Latest Free Oracle 1Z0 060 Dumps (81 90) Download!aaNo ratings yet
- Archpurg - GL BalancesDocument10 pagesArchpurg - GL BalancesSriram KalidossNo ratings yet
- Chapitre 4Document80 pagesChapitre 4Chaima BelhediNo ratings yet
- Data Governance: Higher EducationDocument12 pagesData Governance: Higher EducationHeru NugrohoNo ratings yet
- Solved - Extracting Hostname From Filename - Inputs - Conf On... - Splunk CommunityDocument7 pagesSolved - Extracting Hostname From Filename - Inputs - Conf On... - Splunk CommunityVinuNo ratings yet
- Advocacy IntroductionDocument137 pagesAdvocacy IntroductionLaura Deotti100% (1)
- Query OptimizationDocument138 pagesQuery OptimizationRadu Borza100% (1)
- A Beginners Guide To Applied Educational Research Using ThematicDocument16 pagesA Beginners Guide To Applied Educational Research Using ThematicGetachew TegegneNo ratings yet
- Midterm Review/Practice For SQL and ConstraintsDocument27 pagesMidterm Review/Practice For SQL and ConstraintsMd. Rakibul HasanNo ratings yet
- GROUP 1 Conceptions of Privacy and The Values of Privacy LIVING in The IT ERADocument56 pagesGROUP 1 Conceptions of Privacy and The Values of Privacy LIVING in The IT ERAina gastadorNo ratings yet
- Book V11gDocument46 pagesBook V11gdescaerNo ratings yet
- Molin 6Document45 pagesMolin 6Yor - ChannelNo ratings yet
- Technical Overview of Data ExchangeDocument35 pagesTechnical Overview of Data ExchangetopankajsharmaNo ratings yet
- EWM SourceDocument2 pagesEWM SourceRaghavendra MJNo ratings yet
- Toad For SQL Server 6.8: Release NotesDocument60 pagesToad For SQL Server 6.8: Release NotesLitzana Rodriguez BautistaNo ratings yet
- Storage Area Network (SAN)Document81 pagesStorage Area Network (SAN)anonymous_9888No ratings yet
- Gate Question On DbmsDocument5 pagesGate Question On DbmsNallala Satya venkata rama krishnaNo ratings yet
- ERD Optionality: OOD Inge PowellDocument19 pagesERD Optionality: OOD Inge PowellSuhayfa AbdulrahmanNo ratings yet
- Xii Preboard1 QP Set BDocument10 pagesXii Preboard1 QP Set BRishika VermaNo ratings yet
- Introduction To BIDocument1 pageIntroduction To BIZubeen ShahNo ratings yet
- Infobright ICE User GuideDocument62 pagesInfobright ICE User Guidepeterpan107No ratings yet
- Developing Digital Worksheet by Using Wizer - Me For Teaching Listening Skill To The Tenth Grade Students in SMK Negeri 7 MedanDocument13 pagesDeveloping Digital Worksheet by Using Wizer - Me For Teaching Listening Skill To The Tenth Grade Students in SMK Negeri 7 MedanargugNo ratings yet
- Py ExcelDocument152 pagesPy ExcelLakshmi KiranNo ratings yet
- 3is FORMATDocument10 pages3is FORMATAlbert Manzano Labra0% (1)
- Tunning Oracle Reports 6iDocument24 pagesTunning Oracle Reports 6iMelvin GrijalbaNo ratings yet
- ABAP - Data DictionaryDocument30 pagesABAP - Data DictionarysatishputranNo ratings yet
- File IODocument26 pagesFile IOKobo ChowNo ratings yet
- Oracle TestkingDocument41 pagesOracle TestkingGhanou StarlineNo ratings yet