
Challenges For Mapreduce in Big Data: Scholarship@Western
Challenges For Mapreduce in Big Data: Scholarship@Western
You might also like
- Digital Fundamentals LAB #5 Binary Adders: ObjectiveDocument3 pagesDigital Fundamentals LAB #5 Binary Adders: ObjectiveAnonymous uPUm1vh4H100% (1)
- Desigo PX Open PX Modbus: Engineering GuideDocument38 pagesDesigo PX Open PX Modbus: Engineering GuideelhbabacarNo ratings yet
- Big Data AnalyticsDocument12 pagesBig Data AnalyticsGautam PrajapatiNo ratings yet
- RDBMS ConceptsDocument73 pagesRDBMS ConceptsMinaxi Mantri100% (1)
- Map ReduceDocument27 pagesMap ReduceAndreas RousalisNo ratings yet
- 347 VLDBJ2013 MapReduceSurveyDocument27 pages347 VLDBJ2013 MapReduceSurveyJitendra Singh RauthanNo ratings yet
- A Comparison of Big Remote Sensing Data Processing With Hadoop MspReduce and SparkDocument4 pagesA Comparison of Big Remote Sensing Data Processing With Hadoop MspReduce and SparkSara sherifNo ratings yet
- IEEE Conf Paper FormatvvDocument5 pagesIEEE Conf Paper FormatvvRajatNo ratings yet
- DOLAP 2011-Analytics Over Large Scale MD DataDocument3 pagesDOLAP 2011-Analytics Over Large Scale MD DataannoojjaNo ratings yet
- Mapreduce: Simplified Data Analysis of Big Data: SciencedirectDocument9 pagesMapreduce: Simplified Data Analysis of Big Data: Sciencedirectmfs coreNo ratings yet
- Big Data Analytics Litrature ReviewDocument7 pagesBig Data Analytics Litrature ReviewDejene DagimeNo ratings yet
- Jargon of Hadoop Mapreduce Scheduling Techniques A Scientific CategorizationDocument33 pagesJargon of Hadoop Mapreduce Scheduling Techniques A Scientific CategorizationThet Su AungNo ratings yet
- A Comprehensive View of Hadoop Research - A Systematic Literature ReviewDocument28 pagesA Comprehensive View of Hadoop Research - A Systematic Literature ReviewAshraf Sayed AbdouNo ratings yet
- A Comparison of Big Data Analytics Approaches Based On Hadoop MapreduceDocument9 pagesA Comparison of Big Data Analytics Approaches Based On Hadoop MapreduceKyar Nyo AyeNo ratings yet
- Mapreduce With Hadoop For Simplified Analysis of Big Data: Ch. Shobha Rani Dr. B. RamaDocument4 pagesMapreduce With Hadoop For Simplified Analysis of Big Data: Ch. Shobha Rani Dr. B. RamaAnil KashyapNo ratings yet
- Lab Manual BDADocument36 pagesLab Manual BDAhemalata jangaleNo ratings yet
- HadoopDocument14 pagesHadoopsrcesrbije.onlineNo ratings yet
- 3412ijwsc01 PDFDocument13 pages3412ijwsc01 PDFssambangi555No ratings yet
- Addressing Big Data ProblemDocument5 pagesAddressing Big Data Problemnew userNo ratings yet
- Big Data Mining and Knowledge DiscoveryDocument6 pagesBig Data Mining and Knowledge DiscoveryRANIA_MKHININI_GAHARNo ratings yet
- Ijwsc 030401Document13 pagesIjwsc 030401ijwscNo ratings yet
- Big Feature Data Analytics: Split and Combine Linear Discriminant Analysis (SC-LDA) For Integration Towards Decision Making AnalyticsDocument10 pagesBig Feature Data Analytics: Split and Combine Linear Discriminant Analysis (SC-LDA) For Integration Towards Decision Making Analyticskanna_dhasan25581No ratings yet
- Hadoop Based Feature Selection and Decision Making Models On Big DataDocument6 pagesHadoop Based Feature Selection and Decision Making Models On Big DataDr. Thulasi BikkuNo ratings yet
- Scaling Up To Billions of Cells With: Supporting Large Spreadsheets With DatabasesDocument16 pagesScaling Up To Billions of Cells With: Supporting Large Spreadsheets With Databasessarthak405No ratings yet
- TMP - 11927-Information Retrieval From Big Data For Sensor Data Collection-520372139741037689682152Document3 pagesTMP - 11927-Information Retrieval From Big Data For Sensor Data Collection-520372139741037689682152Boy NataNo ratings yet
- A Comparison of Mapreduce and Parallel Database Management SystemsDocument5 pagesA Comparison of Mapreduce and Parallel Database Management SystemsRon CyjNo ratings yet
- MapReduce Algorithms For Big Data AnalysisDocument2 pagesMapReduce Algorithms For Big Data AnalysisFreeman JacksonNo ratings yet
- Big Data Problems: Understanding Hadoop Framework: G S Aditya Rao, Palak PandeyDocument3 pagesBig Data Problems: Understanding Hadoop Framework: G S Aditya Rao, Palak PandeyportlandonlineNo ratings yet
- Mapreduce Google Research PaperDocument7 pagesMapreduce Google Research Paperzgkuqhxgf100% (1)
- 2338 2017 Inffus FusionmrDocument11 pages2338 2017 Inffus FusionmrsergioNo ratings yet
- The Growing Enormous of Big Data StorageDocument6 pagesThe Growing Enormous of Big Data StorageEddy ManurungNo ratings yet
- Research Paper On MapreduceDocument7 pagesResearch Paper On Mapreducegjosukwgf100% (1)
- Na BIC20122Document8 pagesNa BIC20122jefferyleclercNo ratings yet
- Analysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterDocument8 pagesAnalysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Research Publish JournalDocument7 pagesResearch Publish Journalrikaseo rikaNo ratings yet
- HADOOP - Big Data Overview and SolutionsDocument10 pagesHADOOP - Big Data Overview and SolutionsCHOL MALUALNo ratings yet
- Web Oriented FIM For Large Scale Dataset Using HadoopDocument5 pagesWeb Oriented FIM For Large Scale Dataset Using HadoopdbpublicationsNo ratings yet
- On The Use of Mapreduce To Build Linguistic Fuzzy Rule Based Classification Systems For Big DataDocument8 pagesOn The Use of Mapreduce To Build Linguistic Fuzzy Rule Based Classification Systems For Big DatalolilocigaNo ratings yet
- 30 Comparative Performance Analysis of Apache Spark and Map Reduce Using K-Means EDocument7 pages30 Comparative Performance Analysis of Apache Spark and Map Reduce Using K-Means EjefferyleclercNo ratings yet
- Big Data AnalysisDocument8 pagesBig Data AnalysismjrobustNo ratings yet
- Research Paper On HadoopDocument5 pagesResearch Paper On Hadoopwlyxiqrhf100% (1)
- Matrix-Vector Multiplication Using MapReduce in Big Data.Document4 pagesMatrix-Vector Multiplication Using MapReduce in Big Data.Pallavi giraseNo ratings yet
- BFSMpR:A BFS Graph Based Recommendation System Using Map ReduceDocument5 pagesBFSMpR:A BFS Graph Based Recommendation System Using Map ReduceEditor IJRITCCNo ratings yet
- Machine Learning With Big Data: Challenges and ApproachesDocument22 pagesMachine Learning With Big Data: Challenges and ApproachesVipin GeorgeNo ratings yet
- Predictive Analytics For Big Data ProcessingDocument3 pagesPredictive Analytics For Big Data ProcessingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- BDA Answers-1Document15 pagesBDA Answers-1afreed khanNo ratings yet
- Analyzing and Processing Data Faster Bas PDFDocument6 pagesAnalyzing and Processing Data Faster Bas PDFangelocutoloNo ratings yet
- Unit No. 4Document67 pagesUnit No. 4vishal phuleNo ratings yet
- Beginning Database DesignDocument2 pagesBeginning Database DesignI Made PutramaNo ratings yet
- V3i308 PDFDocument9 pagesV3i308 PDFIJCERT PUBLICATIONSNo ratings yet
- An Insight On Big Data Analytics Using Pig ScriptDocument7 pagesAn Insight On Big Data Analytics Using Pig ScriptInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Big Data TutorialDocument2 pagesBig Data TutorialAnand Singh GadwalNo ratings yet
- Big Data: New Tricks For Econometrics: Hal R. VarianDocument27 pagesBig Data: New Tricks For Econometrics: Hal R. VarianJose Fernandez FernandezNo ratings yet
- Big Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Document8 pagesBig Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Renuka PandeyNo ratings yet
- Engineering College, Ajmer: "Big Data Analytics"Document17 pagesEngineering College, Ajmer: "Big Data Analytics"aditya rangrooNo ratings yet
- Knowledge Discovery in Data Science: KDD Meets Big DataDocument6 pagesKnowledge Discovery in Data Science: KDD Meets Big DataPatricio UlloaNo ratings yet
- Document Clustering With Map Reduce Using Hadoop FrameworkDocument5 pagesDocument Clustering With Map Reduce Using Hadoop FrameworkEditor IJRITCCNo ratings yet
- Modeling of Big Data ProcessingDocument15 pagesModeling of Big Data ProcessingRocio LoayzaNo ratings yet
- Big Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttDocument8 pagesBig Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttdineshNo ratings yet
- 2012 Efficient Big Data Processing in Hadoop MapReduceDocument2 pages2012 Efficient Big Data Processing in Hadoop MapReduceEduardo Cotrin TeixeiraNo ratings yet
- FidoopDocument5 pagesFidoopJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Frequent Itemsets Mining For Big Data AComparative Analysis-2017 DoneDocument17 pagesFrequent Itemsets Mining For Big Data AComparative Analysis-2017 DoneramNo ratings yet
- Developing Analytic Talent: Becoming a Data ScientistFrom EverandDeveloping Analytic Talent: Becoming a Data ScientistRating: 3 out of 5 stars3/5 (7)
- Task: FIB Fibonacci Representations: InputDocument1 pageTask: FIB Fibonacci Representations: InputAndrei FlorinNo ratings yet
- Task: TOY Toys: InputDocument2 pagesTask: TOY Toys: InputAndrei FlorinNo ratings yet
- Problem A: Bird RescueDocument22 pagesProblem A: Bird RescueAndrei FlorinNo ratings yet
- Icpc 2019Document22 pagesIcpc 2019Andrei FlorinNo ratings yet
- Problem I Reflection and Refraction of Light A. An Interesting PrismDocument9 pagesProblem I Reflection and Refraction of Light A. An Interesting PrismAndrei FlorinNo ratings yet
- RMPH 2017 PT3 QuestionDocument4 pagesRMPH 2017 PT3 QuestionAndrei FlorinNo ratings yet
- RMPH 2017 PT2 QuestionDocument6 pagesRMPH 2017 PT2 QuestionAndrei FlorinNo ratings yet
- This Is GoldDocument47 pagesThis Is GoldAndrei FlorinNo ratings yet
- 1963 EngDocument2 pages1963 EngAndrei FlorinNo ratings yet
- Am Mortised Analysis ErrataDocument1 pageAm Mortised Analysis ErrataAndrei FlorinNo ratings yet
- Cae Writing A Competition Entry1Document1 pageCae Writing A Competition Entry1ali_nusNo ratings yet
- Sample Question Paper Computer Science (Code: 083)Document7 pagesSample Question Paper Computer Science (Code: 083)Mutual Fund JunctionNo ratings yet
- EEE - BEE603 - Microprocessor and Microcontroller - Mr. K. DwarakeshDocument24 pagesEEE - BEE603 - Microprocessor and Microcontroller - Mr. K. Dwarakeshsatishcoimbato12No ratings yet
- Resistance ExerciseDocument2 pagesResistance ExerciseD7ooM 612100% (1)
- Mi603 - Micro Service ArchitectureDocument7 pagesMi603 - Micro Service ArchitectureShubham AgarwalNo ratings yet
- Clevo m720t m730t m728t m729t PDFDocument116 pagesClevo m720t m730t m728t m729t PDFAntonio BellidoNo ratings yet
- Topics Covered: Memory SubsystemDocument7 pagesTopics Covered: Memory SubsystemDhana LingamNo ratings yet
- Error:: Defect, Bug, Fault & ErrorDocument1 pageError:: Defect, Bug, Fault & ErrorAA RRNo ratings yet
- Micro ProcessorDocument10 pagesMicro ProcessorBharath ManchikodiNo ratings yet
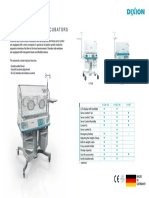
- Brosur Dixion Babyguard IncubatorDocument1 pageBrosur Dixion Babyguard IncubatormyrnaganiNo ratings yet
- Overcoming RIA Challenges With Magic XpaDocument7 pagesOvercoming RIA Challenges With Magic XpaLorenzoBencosmeNo ratings yet
- Upgrade Fails When User-Defined Field Is Defined On TableDocument3 pagesUpgrade Fails When User-Defined Field Is Defined On TableDant NazarNo ratings yet
- Multi ThreadingDocument17 pagesMulti ThreadingshivuhcNo ratings yet
- Corso Documentum Base - 5 ArchitectureDocument22 pagesCorso Documentum Base - 5 ArchitectureEnrico PavesiNo ratings yet
- Arithmetic Circuits in CMOS VLSIDocument52 pagesArithmetic Circuits in CMOS VLSIPrasad NamaNo ratings yet
- Last Area Day 8 - Basic Electronics-1Document7 pagesLast Area Day 8 - Basic Electronics-1ellajanepoNo ratings yet
- Installation & Operational Manual ALPHAWIND MF ENG v1.4 A4 PDFDocument52 pagesInstallation & Operational Manual ALPHAWIND MF ENG v1.4 A4 PDFAjay Singh0% (1)
- LadderProgramConverter Appendices (Mitsubishi)Document161 pagesLadderProgramConverter Appendices (Mitsubishi)yukaokto2No ratings yet
- 4059 Telephonic Keyboard Installation Issue - Alcatel UnleashedDocument2 pages4059 Telephonic Keyboard Installation Issue - Alcatel UnleashedWael FathyNo ratings yet
- Abhishek Kumar ResumeDocument6 pagesAbhishek Kumar ResumeSandip GhoshNo ratings yet
- CCNP Enterprise v1.1 Release NotesDocument12 pagesCCNP Enterprise v1.1 Release NotessheinhtetNo ratings yet
- Free Primavera p6 Training PDFDocument2 pagesFree Primavera p6 Training PDFChad0% (3)
- Dta Cisco 7016863Document4 pagesDta Cisco 7016863ixmarcNo ratings yet
- High-Voltage Switching Transistor (Camera Strobes and Telephone, Power Supply) ( 400V, 0.1A)Document4 pagesHigh-Voltage Switching Transistor (Camera Strobes and Telephone, Power Supply) ( 400V, 0.1A)Reinaldo OliveiraNo ratings yet
- Total Station ZTS-720 Series Instruction Manual: Software IntroductionDocument10 pagesTotal Station ZTS-720 Series Instruction Manual: Software IntroductionRENE BRIONESNo ratings yet
- AmcDocument37 pagesAmcjunkgr8mail6092No ratings yet
- Raspberry Pi As A Sensor Web Node For Home AutomationDocument19 pagesRaspberry Pi As A Sensor Web Node For Home AutomationDavid GhisaysNo ratings yet
- Dell EMC Unisphere For PowerMax Install Guide V9.2.1Document39 pagesDell EMC Unisphere For PowerMax Install Guide V9.2.1peterwoolstonNo ratings yet



































































































Download as pdf or txt
You might also like
- Digital Fundamentals LAB #5 Binary Adders: ObjectiveDocument3 pagesDigital Fundamentals LAB #5 Binary Adders: ObjectiveAnonymous uPUm1vh4H100% (1)
- Desigo PX Open PX Modbus: Engineering GuideDocument38 pagesDesigo PX Open PX Modbus: Engineering GuideelhbabacarNo ratings yet
- Big Data AnalyticsDocument12 pagesBig Data AnalyticsGautam PrajapatiNo ratings yet
- RDBMS ConceptsDocument73 pagesRDBMS ConceptsMinaxi Mantri100% (1)
- Map ReduceDocument27 pagesMap ReduceAndreas RousalisNo ratings yet
- 347 VLDBJ2013 MapReduceSurveyDocument27 pages347 VLDBJ2013 MapReduceSurveyJitendra Singh RauthanNo ratings yet
- A Comparison of Big Remote Sensing Data Processing With Hadoop MspReduce and SparkDocument4 pagesA Comparison of Big Remote Sensing Data Processing With Hadoop MspReduce and SparkSara sherifNo ratings yet
- IEEE Conf Paper FormatvvDocument5 pagesIEEE Conf Paper FormatvvRajatNo ratings yet
- DOLAP 2011-Analytics Over Large Scale MD DataDocument3 pagesDOLAP 2011-Analytics Over Large Scale MD DataannoojjaNo ratings yet
- Mapreduce: Simplified Data Analysis of Big Data: SciencedirectDocument9 pagesMapreduce: Simplified Data Analysis of Big Data: Sciencedirectmfs coreNo ratings yet
- Big Data Analytics Litrature ReviewDocument7 pagesBig Data Analytics Litrature ReviewDejene DagimeNo ratings yet
- Jargon of Hadoop Mapreduce Scheduling Techniques A Scientific CategorizationDocument33 pagesJargon of Hadoop Mapreduce Scheduling Techniques A Scientific CategorizationThet Su AungNo ratings yet
- A Comprehensive View of Hadoop Research - A Systematic Literature ReviewDocument28 pagesA Comprehensive View of Hadoop Research - A Systematic Literature ReviewAshraf Sayed AbdouNo ratings yet
- A Comparison of Big Data Analytics Approaches Based On Hadoop MapreduceDocument9 pagesA Comparison of Big Data Analytics Approaches Based On Hadoop MapreduceKyar Nyo AyeNo ratings yet
- Mapreduce With Hadoop For Simplified Analysis of Big Data: Ch. Shobha Rani Dr. B. RamaDocument4 pagesMapreduce With Hadoop For Simplified Analysis of Big Data: Ch. Shobha Rani Dr. B. RamaAnil KashyapNo ratings yet
- Lab Manual BDADocument36 pagesLab Manual BDAhemalata jangaleNo ratings yet
- HadoopDocument14 pagesHadoopsrcesrbije.onlineNo ratings yet
- 3412ijwsc01 PDFDocument13 pages3412ijwsc01 PDFssambangi555No ratings yet
- Addressing Big Data ProblemDocument5 pagesAddressing Big Data Problemnew userNo ratings yet
- Big Data Mining and Knowledge DiscoveryDocument6 pagesBig Data Mining and Knowledge DiscoveryRANIA_MKHININI_GAHARNo ratings yet
- Ijwsc 030401Document13 pagesIjwsc 030401ijwscNo ratings yet
- Big Feature Data Analytics: Split and Combine Linear Discriminant Analysis (SC-LDA) For Integration Towards Decision Making AnalyticsDocument10 pagesBig Feature Data Analytics: Split and Combine Linear Discriminant Analysis (SC-LDA) For Integration Towards Decision Making Analyticskanna_dhasan25581No ratings yet
- Hadoop Based Feature Selection and Decision Making Models On Big DataDocument6 pagesHadoop Based Feature Selection and Decision Making Models On Big DataDr. Thulasi BikkuNo ratings yet
- Scaling Up To Billions of Cells With: Supporting Large Spreadsheets With DatabasesDocument16 pagesScaling Up To Billions of Cells With: Supporting Large Spreadsheets With Databasessarthak405No ratings yet
- TMP - 11927-Information Retrieval From Big Data For Sensor Data Collection-520372139741037689682152Document3 pagesTMP - 11927-Information Retrieval From Big Data For Sensor Data Collection-520372139741037689682152Boy NataNo ratings yet
- A Comparison of Mapreduce and Parallel Database Management SystemsDocument5 pagesA Comparison of Mapreduce and Parallel Database Management SystemsRon CyjNo ratings yet
- MapReduce Algorithms For Big Data AnalysisDocument2 pagesMapReduce Algorithms For Big Data AnalysisFreeman JacksonNo ratings yet
- Big Data Problems: Understanding Hadoop Framework: G S Aditya Rao, Palak PandeyDocument3 pagesBig Data Problems: Understanding Hadoop Framework: G S Aditya Rao, Palak PandeyportlandonlineNo ratings yet
- Mapreduce Google Research PaperDocument7 pagesMapreduce Google Research Paperzgkuqhxgf100% (1)
- 2338 2017 Inffus FusionmrDocument11 pages2338 2017 Inffus FusionmrsergioNo ratings yet
- The Growing Enormous of Big Data StorageDocument6 pagesThe Growing Enormous of Big Data StorageEddy ManurungNo ratings yet
- Research Paper On MapreduceDocument7 pagesResearch Paper On Mapreducegjosukwgf100% (1)
- Na BIC20122Document8 pagesNa BIC20122jefferyleclercNo ratings yet
- Analysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterDocument8 pagesAnalysis of Dynamic Data Placement Strategy For Heterogeneous Hadoop ClusterInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Research Publish JournalDocument7 pagesResearch Publish Journalrikaseo rikaNo ratings yet
- HADOOP - Big Data Overview and SolutionsDocument10 pagesHADOOP - Big Data Overview and SolutionsCHOL MALUALNo ratings yet
- Web Oriented FIM For Large Scale Dataset Using HadoopDocument5 pagesWeb Oriented FIM For Large Scale Dataset Using HadoopdbpublicationsNo ratings yet
- On The Use of Mapreduce To Build Linguistic Fuzzy Rule Based Classification Systems For Big DataDocument8 pagesOn The Use of Mapreduce To Build Linguistic Fuzzy Rule Based Classification Systems For Big DatalolilocigaNo ratings yet
- 30 Comparative Performance Analysis of Apache Spark and Map Reduce Using K-Means EDocument7 pages30 Comparative Performance Analysis of Apache Spark and Map Reduce Using K-Means EjefferyleclercNo ratings yet
- Big Data AnalysisDocument8 pagesBig Data AnalysismjrobustNo ratings yet
- Research Paper On HadoopDocument5 pagesResearch Paper On Hadoopwlyxiqrhf100% (1)
- Matrix-Vector Multiplication Using MapReduce in Big Data.Document4 pagesMatrix-Vector Multiplication Using MapReduce in Big Data.Pallavi giraseNo ratings yet
- BFSMpR:A BFS Graph Based Recommendation System Using Map ReduceDocument5 pagesBFSMpR:A BFS Graph Based Recommendation System Using Map ReduceEditor IJRITCCNo ratings yet
- Machine Learning With Big Data: Challenges and ApproachesDocument22 pagesMachine Learning With Big Data: Challenges and ApproachesVipin GeorgeNo ratings yet
- Predictive Analytics For Big Data ProcessingDocument3 pagesPredictive Analytics For Big Data ProcessingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- BDA Answers-1Document15 pagesBDA Answers-1afreed khanNo ratings yet
- Analyzing and Processing Data Faster Bas PDFDocument6 pagesAnalyzing and Processing Data Faster Bas PDFangelocutoloNo ratings yet
- Unit No. 4Document67 pagesUnit No. 4vishal phuleNo ratings yet
- Beginning Database DesignDocument2 pagesBeginning Database DesignI Made PutramaNo ratings yet
- V3i308 PDFDocument9 pagesV3i308 PDFIJCERT PUBLICATIONSNo ratings yet
- An Insight On Big Data Analytics Using Pig ScriptDocument7 pagesAn Insight On Big Data Analytics Using Pig ScriptInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Big Data TutorialDocument2 pagesBig Data TutorialAnand Singh GadwalNo ratings yet
- Big Data: New Tricks For Econometrics: Hal R. VarianDocument27 pagesBig Data: New Tricks For Econometrics: Hal R. VarianJose Fernandez FernandezNo ratings yet
- Big Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Document8 pagesBig Data: Spot Business Trends, Prevent Diseases, C Ombat Crime and So On"Renuka PandeyNo ratings yet
- Engineering College, Ajmer: "Big Data Analytics"Document17 pagesEngineering College, Ajmer: "Big Data Analytics"aditya rangrooNo ratings yet
- Knowledge Discovery in Data Science: KDD Meets Big DataDocument6 pagesKnowledge Discovery in Data Science: KDD Meets Big DataPatricio UlloaNo ratings yet
- Document Clustering With Map Reduce Using Hadoop FrameworkDocument5 pagesDocument Clustering With Map Reduce Using Hadoop FrameworkEditor IJRITCCNo ratings yet
- Modeling of Big Data ProcessingDocument15 pagesModeling of Big Data ProcessingRocio LoayzaNo ratings yet
- Big Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttDocument8 pagesBig Data: How To Handle: A Survey: Dinesh MCA Deptt. PDM University, Bahadurgarh ABC MCA DepttdineshNo ratings yet
- 2012 Efficient Big Data Processing in Hadoop MapReduceDocument2 pages2012 Efficient Big Data Processing in Hadoop MapReduceEduardo Cotrin TeixeiraNo ratings yet
- FidoopDocument5 pagesFidoopJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Frequent Itemsets Mining For Big Data AComparative Analysis-2017 DoneDocument17 pagesFrequent Itemsets Mining For Big Data AComparative Analysis-2017 DoneramNo ratings yet
- Developing Analytic Talent: Becoming a Data ScientistFrom EverandDeveloping Analytic Talent: Becoming a Data ScientistRating: 3 out of 5 stars3/5 (7)
- Task: FIB Fibonacci Representations: InputDocument1 pageTask: FIB Fibonacci Representations: InputAndrei FlorinNo ratings yet
- Task: TOY Toys: InputDocument2 pagesTask: TOY Toys: InputAndrei FlorinNo ratings yet
- Problem A: Bird RescueDocument22 pagesProblem A: Bird RescueAndrei FlorinNo ratings yet
- Icpc 2019Document22 pagesIcpc 2019Andrei FlorinNo ratings yet
- Problem I Reflection and Refraction of Light A. An Interesting PrismDocument9 pagesProblem I Reflection and Refraction of Light A. An Interesting PrismAndrei FlorinNo ratings yet
- RMPH 2017 PT3 QuestionDocument4 pagesRMPH 2017 PT3 QuestionAndrei FlorinNo ratings yet
- RMPH 2017 PT2 QuestionDocument6 pagesRMPH 2017 PT2 QuestionAndrei FlorinNo ratings yet
- This Is GoldDocument47 pagesThis Is GoldAndrei FlorinNo ratings yet
- 1963 EngDocument2 pages1963 EngAndrei FlorinNo ratings yet
- Am Mortised Analysis ErrataDocument1 pageAm Mortised Analysis ErrataAndrei FlorinNo ratings yet
- Cae Writing A Competition Entry1Document1 pageCae Writing A Competition Entry1ali_nusNo ratings yet
- Sample Question Paper Computer Science (Code: 083)Document7 pagesSample Question Paper Computer Science (Code: 083)Mutual Fund JunctionNo ratings yet
- EEE - BEE603 - Microprocessor and Microcontroller - Mr. K. DwarakeshDocument24 pagesEEE - BEE603 - Microprocessor and Microcontroller - Mr. K. Dwarakeshsatishcoimbato12No ratings yet
- Resistance ExerciseDocument2 pagesResistance ExerciseD7ooM 612100% (1)
- Mi603 - Micro Service ArchitectureDocument7 pagesMi603 - Micro Service ArchitectureShubham AgarwalNo ratings yet
- Clevo m720t m730t m728t m729t PDFDocument116 pagesClevo m720t m730t m728t m729t PDFAntonio BellidoNo ratings yet
- Topics Covered: Memory SubsystemDocument7 pagesTopics Covered: Memory SubsystemDhana LingamNo ratings yet
- Error:: Defect, Bug, Fault & ErrorDocument1 pageError:: Defect, Bug, Fault & ErrorAA RRNo ratings yet
- Micro ProcessorDocument10 pagesMicro ProcessorBharath ManchikodiNo ratings yet
- Brosur Dixion Babyguard IncubatorDocument1 pageBrosur Dixion Babyguard IncubatormyrnaganiNo ratings yet
- Overcoming RIA Challenges With Magic XpaDocument7 pagesOvercoming RIA Challenges With Magic XpaLorenzoBencosmeNo ratings yet
- Upgrade Fails When User-Defined Field Is Defined On TableDocument3 pagesUpgrade Fails When User-Defined Field Is Defined On TableDant NazarNo ratings yet
- Multi ThreadingDocument17 pagesMulti ThreadingshivuhcNo ratings yet
- Corso Documentum Base - 5 ArchitectureDocument22 pagesCorso Documentum Base - 5 ArchitectureEnrico PavesiNo ratings yet
- Arithmetic Circuits in CMOS VLSIDocument52 pagesArithmetic Circuits in CMOS VLSIPrasad NamaNo ratings yet
- Last Area Day 8 - Basic Electronics-1Document7 pagesLast Area Day 8 - Basic Electronics-1ellajanepoNo ratings yet
- Installation & Operational Manual ALPHAWIND MF ENG v1.4 A4 PDFDocument52 pagesInstallation & Operational Manual ALPHAWIND MF ENG v1.4 A4 PDFAjay Singh0% (1)
- LadderProgramConverter Appendices (Mitsubishi)Document161 pagesLadderProgramConverter Appendices (Mitsubishi)yukaokto2No ratings yet
- 4059 Telephonic Keyboard Installation Issue - Alcatel UnleashedDocument2 pages4059 Telephonic Keyboard Installation Issue - Alcatel UnleashedWael FathyNo ratings yet
- Abhishek Kumar ResumeDocument6 pagesAbhishek Kumar ResumeSandip GhoshNo ratings yet
- CCNP Enterprise v1.1 Release NotesDocument12 pagesCCNP Enterprise v1.1 Release NotessheinhtetNo ratings yet
- Free Primavera p6 Training PDFDocument2 pagesFree Primavera p6 Training PDFChad0% (3)
- Dta Cisco 7016863Document4 pagesDta Cisco 7016863ixmarcNo ratings yet
- High-Voltage Switching Transistor (Camera Strobes and Telephone, Power Supply) ( 400V, 0.1A)Document4 pagesHigh-Voltage Switching Transistor (Camera Strobes and Telephone, Power Supply) ( 400V, 0.1A)Reinaldo OliveiraNo ratings yet
- Total Station ZTS-720 Series Instruction Manual: Software IntroductionDocument10 pagesTotal Station ZTS-720 Series Instruction Manual: Software IntroductionRENE BRIONESNo ratings yet
- AmcDocument37 pagesAmcjunkgr8mail6092No ratings yet
- Raspberry Pi As A Sensor Web Node For Home AutomationDocument19 pagesRaspberry Pi As A Sensor Web Node For Home AutomationDavid GhisaysNo ratings yet
- Dell EMC Unisphere For PowerMax Install Guide V9.2.1Document39 pagesDell EMC Unisphere For PowerMax Install Guide V9.2.1peterwoolstonNo ratings yet