Download as pdf or txt
You might also like
- Marketing 12th Edition Kerin Test BankDocument35 pagesMarketing 12th Edition Kerin Test Bankketmieoilstoneqjdnwq97% (31)
- Ultra Practice Aptitude Bundle PDF SBI PO Prelims Exam 2020-21Document564 pagesUltra Practice Aptitude Bundle PDF SBI PO Prelims Exam 2020-21Rishabh Gangwar100% (1)
- Themultipleregressionmodel: I I1 I2 I3Document16 pagesThemultipleregressionmodel: I I1 I2 I3Mon LuffyNo ratings yet
- BookSlides 7A Error-Based LearningDocument49 pagesBookSlides 7A Error-Based LearningMba NaniNo ratings yet
- Demo SOFTEXPERT GRC PDFDocument59 pagesDemo SOFTEXPERT GRC PDFMba NaniNo ratings yet
- BookSlides 3B Data ExplorationDocument60 pagesBookSlides 3B Data ExplorationSyedul MursaleenNo ratings yet
- Course Project A: Disscussion of First Variable Using Graphical, Numerical Summary and InterpretationDocument8 pagesCourse Project A: Disscussion of First Variable Using Graphical, Numerical Summary and InterpretationKazueNo ratings yet
- Quant Checklist Module 2 by Aashish AroraDocument57 pagesQuant Checklist Module 2 by Aashish AroraDarkwebs VampireNo ratings yet
- Business Analytics Practical ProblemsDocument26 pagesBusiness Analytics Practical ProblemsPriyaNo ratings yet
- Quant Checklist Module 28 by Aashish AroraDocument47 pagesQuant Checklist Module 28 by Aashish AroraUtkarsh MathurNo ratings yet
- QuantDocument59 pagesQuantKiran KumariNo ratings yet
- Marketing 12th Edition Kerin Test BankDocument25 pagesMarketing 12th Edition Kerin Test BankStacyCarrgpjkb100% (59)
- Decision Science Assignment 2Document6 pagesDecision Science Assignment 2Vishnu TiwariNo ratings yet
- Maths Book - DI PDFDocument83 pagesMaths Book - DI PDFRamesh kumarNo ratings yet
- TUGAS 11 SPSS - Luthfi Hadi Prasetyo (2212231021)Document32 pagesTUGAS 11 SPSS - Luthfi Hadi Prasetyo (2212231021)luthfiNo ratings yet
- Dwnload Full Marketing 12th Edition Kerin Test Bank PDFDocument35 pagesDwnload Full Marketing 12th Edition Kerin Test Bank PDFdalikifukiauj100% (10)
- LC HL Physics 2021Document28 pagesLC HL Physics 2021sarahNo ratings yet
- 2 Years StrategyDocument56 pages2 Years Strategymdfaizan8066No ratings yet
- Exercices On Chapter 13Document21 pagesExercices On Chapter 13gheedaNo ratings yet
- Data Descriptive StatisticsDocument15 pagesData Descriptive StatisticsRascel SumalinogNo ratings yet
- SFM Class CoverageDocument5 pagesSFM Class Coveragekmanoj20060701No ratings yet
- Coupler Curves of A FourDocument2 pagesCoupler Curves of A Fourvelma0483No ratings yet
- Tugas 1 Statistika MsiDocument5 pagesTugas 1 Statistika MsiClara LovinaNo ratings yet
- Settlement For Cohesive SoilDocument9 pagesSettlement For Cohesive SoilQuach TuanNo ratings yet
- CS1 Chapter 0 Assumed Knowledge 2024Document37 pagesCS1 Chapter 0 Assumed Knowledge 2024Chipo TuyaraNo ratings yet
- Basic Mathematical Operations in Microsoft ExcelDocument4 pagesBasic Mathematical Operations in Microsoft ExcelBəhmən OrucovNo ratings yet
- Spract 6Document40 pagesSpract 6xtremfree5485No ratings yet
- Test Bank For Marketing 12Th Edition Kerin Hartley Rudelius 0077861035 978007786103 Full Chapter PDFDocument36 pagesTest Bank For Marketing 12Th Edition Kerin Hartley Rudelius 0077861035 978007786103 Full Chapter PDFfrank.mosley595100% (19)
- Construction of The Arm Circumference-For-Age Standards 4.1 Indicator-Specific MethodologyDocument50 pagesConstruction of The Arm Circumference-For-Age Standards 4.1 Indicator-Specific MethodologyPatNoppadolNo ratings yet
- Graduatesinnongraduaterolesbypartsoftheuk 2021 To 2022Document80 pagesGraduatesinnongraduaterolesbypartsoftheuk 2021 To 2022Summit ResearchNo ratings yet
- Homework 2 NewDocument5 pagesHomework 2 Newspringfield12No ratings yet
- IQC-OE3-Ch1-Introduction-Part 2Document10 pagesIQC-OE3-Ch1-Introduction-Part 2Dhruv AgarwalNo ratings yet
- RumusDocument7 pagesRumusmade mas juliastikaNo ratings yet
- CM8.3 Spearman Rank CorrelationDocument4 pagesCM8.3 Spearman Rank CorrelationJasher VillacampaNo ratings yet
- Ultra Practice Aptitude Bundle PDF Ibps Po PrelimsDocument199 pagesUltra Practice Aptitude Bundle PDF Ibps Po Prelimsramesh100% (1)
- Marketing Kerin 12th Edition Test BankDocument24 pagesMarketing Kerin 12th Edition Test BankSharonYoungeizr100% (39)
- Week 1 Basic Mathematical Operations in Microsoft Excel LDocument4 pagesWeek 1 Basic Mathematical Operations in Microsoft Excel LeynullabeyliseymurNo ratings yet
- Project Report: Model File: UNIDADES Revision 0 22/5/2019Document59 pagesProject Report: Model File: UNIDADES Revision 0 22/5/2019Valeria EscalanteNo ratings yet
- CS1 Assumed Knowledge 2023 (For Website)Document38 pagesCS1 Assumed Knowledge 2023 (For Website)Andani siavheNo ratings yet
- MGT 636 Chapter 12 ProblemDocument6 pagesMGT 636 Chapter 12 ProblemHieu TruongNo ratings yet
- Test Item Table by Major Section of The Chapter and Level of Learning Major Section of The and Tracking Studies Level of Learning (LL)Document227 pagesTest Item Table by Major Section of The Chapter and Level of Learning Major Section of The and Tracking Studies Level of Learning (LL)ROMULO CUBIDNo ratings yet
- SPSS Q 18 NovDocument3 pagesSPSS Q 18 NovKunal parekhNo ratings yet
- CA Found. Maths, Reasoning & Stats English BookDocument359 pagesCA Found. Maths, Reasoning & Stats English BookRaghav SomaniNo ratings yet
- Sample Math IADocument14 pagesSample Math IATakshi MehtaNo ratings yet
- Rank CorrelationDocument19 pagesRank CorrelationRishab Jain 2027203No ratings yet
- Score Report R-00804013 PDFDocument8 pagesScore Report R-00804013 PDFTierra Bender100% (1)
- Camm 3e Ch03 PPT PDFDocument66 pagesCamm 3e Ch03 PPT PDFRhigene SolanaNo ratings yet
- Quant Checklist Module 18 by Aashish AroraDocument64 pagesQuant Checklist Module 18 by Aashish AroraAjay rajputNo ratings yet
- Data Science in PractiseDocument267 pagesData Science in PractiseRajaNo ratings yet
- BUS173 AssignmentDocument19 pagesBUS173 Assignmentসাবাতুম সাম্যNo ratings yet
- Institute of Statistical Research & Training University of Dhaka Applied Statistics AST 130: Statistical Computing 01Document9 pagesInstitute of Statistical Research & Training University of Dhaka Applied Statistics AST 130: Statistical Computing 01Mojahidul Islam jaburNo ratings yet
- Beacon Mock 2020 Conversion TableDocument4 pagesBeacon Mock 2020 Conversion TableMelodyLoNo ratings yet
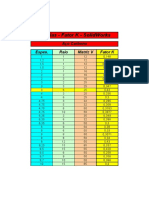
- Tabela Fator KDocument3 pagesTabela Fator KMarceloPolicastroNo ratings yet
- validitasDocument41 pagesvaliditasbprass operasionalNo ratings yet
- 5 6321014510391919515Document59 pages5 6321014510391919515Aveek ModakNo ratings yet
- Module 3 Topic 3 StatsapDocument3 pagesModule 3 Topic 3 StatsapMila MercadoNo ratings yet
- Ronie Dan Cedrick R. FinalsDocument9 pagesRonie Dan Cedrick R. FinalsPaul OrbinoNo ratings yet
- Full Download Book Statistics For Engineers and Scientists 2 PDFDocument41 pagesFull Download Book Statistics For Engineers and Scientists 2 PDFkevin.martinez492100% (28)
- Rokicki, Kociemba, Davidson, and DethridgeDocument1 pageRokicki, Kociemba, Davidson, and DethridgeDiocleziano IINo ratings yet
- EntrepDocument2 pagesEntrepefesonbantillo18No ratings yet
- Harmonic Equation 2 DDocument48 pagesHarmonic Equation 2 DMiranda Roque AlanNo ratings yet
- BookSlides 6B Probability-Based LearningDocument74 pagesBookSlides 6B Probability-Based LearningMba NaniNo ratings yet
- BookSlides 11 The Art of Machine Learning For Predictive Data AnalyticsDocument27 pagesBookSlides 11 The Art of Machine Learning For Predictive Data AnalyticsMba NaniNo ratings yet
- BookSlides 5B Similarity Based LearningDocument69 pagesBookSlides 5B Similarity Based LearningMba NaniNo ratings yet
- BookSlides 6A Probability-Based Learning PDFDocument68 pagesBookSlides 6A Probability-Based Learning PDFMba NaniNo ratings yet
- Bahan SilabusDocument5 pagesBahan SilabusMba NaniNo ratings yet
- BookSlides 5B Similarity Based LearningDocument69 pagesBookSlides 5B Similarity Based LearningMba NaniNo ratings yet
- BookSlides 5A Similarity Based LearningDocument40 pagesBookSlides 5A Similarity Based LearningMba NaniNo ratings yet
- Fundamentals of Machine Learning For Predictive Data AnalyticsDocument52 pagesFundamentals of Machine Learning For Predictive Data AnalyticsMba NaniNo ratings yet
- BookSlides 3A Data ExplorationDocument43 pagesBookSlides 3A Data ExplorationMba NaniNo ratings yet
- BookSlides 4A Information-Based Learning PDFDocument65 pagesBookSlides 4A Information-Based Learning PDFMba NaniNo ratings yet
- Fundamentals of Machine Learning For Predictive Data AnalyticsDocument49 pagesFundamentals of Machine Learning For Predictive Data AnalyticsMba NaniNo ratings yet
- A Descriptive Statistics and DataVisualization - For - Machine - LearningDocument42 pagesA Descriptive Statistics and DataVisualization - For - Machine - LearningMba NaniNo ratings yet
- Ch15-RF Site Survey Fundamentals - 190615Document12 pagesCh15-RF Site Survey Fundamentals - 190615Mba NaniNo ratings yet
- Some Definitions: Selection. in Order To Have A Random Selection Method, You Must Set Up Some Process orDocument9 pagesSome Definitions: Selection. in Order To Have A Random Selection Method, You Must Set Up Some Process orAldrinTEñanoNo ratings yet
- Individual AssignmentDocument12 pagesIndividual AssignmentLife of LokiniNo ratings yet
- Introduction To Research in Education 9th Edition Ary Test Bank DownloadDocument19 pagesIntroduction To Research in Education 9th Edition Ary Test Bank DownloadPaul Kelley100% (27)
- Chapter 3Document79 pagesChapter 3Sisay Mesele100% (1)
- Soil Survey Mapping - LectureNotes2Document132 pagesSoil Survey Mapping - LectureNotes2Udaya KumarNo ratings yet
- Chapter 5 - SamplingDocument56 pagesChapter 5 - SamplingElenear De OcampoNo ratings yet
- Collecting Data Sensibly: Chapter Is VERY Important!Document52 pagesCollecting Data Sensibly: Chapter Is VERY Important!Albert AmadoNo ratings yet
- Reports Sartre 4 ReportDocument496 pagesReports Sartre 4 ReportAnonymous YhQ471cNo ratings yet
- LP4 - Unit4 - GE10-Methods of ResearchDocument12 pagesLP4 - Unit4 - GE10-Methods of ResearchCza Mae ArsenalNo ratings yet
- Methods of Research (2 Semester, 2020-2021) Pedrito Jose V. Bermudo, Edd PHD ProfessorDocument154 pagesMethods of Research (2 Semester, 2020-2021) Pedrito Jose V. Bermudo, Edd PHD ProfessorYuriiNo ratings yet
- Sampling Methods: Community Medicine Unit International Medical School Management and Science UniversityDocument37 pagesSampling Methods: Community Medicine Unit International Medical School Management and Science UniversitySayapPutihNo ratings yet
- Sampling TechniquesDocument23 pagesSampling TechniquesChaedryll JamoraNo ratings yet
- 12 - Writing CHapter 3Document64 pages12 - Writing CHapter 3Ruztin TanaelNo ratings yet
- MainDocument7 pagesMainsanty071No ratings yet
- WEEK 5 - Random SamplingDocument27 pagesWEEK 5 - Random SamplingHilton D. Calawen0% (1)
- Samplin DistnDocument37 pagesSamplin DistnRaffayNo ratings yet
- Environmental Sampling TechniquesDocument16 pagesEnvironmental Sampling TechniquesJosu agirre moraguesNo ratings yet
- Chapter 4 Practice QuizDocument11 pagesChapter 4 Practice QuizTinaNo ratings yet
- Oil and Gas Sector Research in Uganda - Constraints and Opportunities For SMEsDocument61 pagesOil and Gas Sector Research in Uganda - Constraints and Opportunities For SMEsGyagenda Kenneth100% (1)
- A Researcher Wants To Conduct A Research Project ADocument6 pagesA Researcher Wants To Conduct A Research Project AMordecai SaceNo ratings yet
- BIOMETRYDocument37 pagesBIOMETRYAddisu GedamuNo ratings yet
- Survey Research For EltDocument31 pagesSurvey Research For EltParlindungan Pardede100% (3)
- Sampling TechniquesDocument11 pagesSampling TechniquesHafsah JavedNo ratings yet
- Sampling PDFDocument45 pagesSampling PDFYousuf AdamNo ratings yet
- II. Research Aptitude: Concept and Type of ResearchDocument26 pagesII. Research Aptitude: Concept and Type of ResearchPREETHA SHERI GNo ratings yet
- Block-2 Methods and Techniques of Data CollectionDocument155 pagesBlock-2 Methods and Techniques of Data CollectionRatika DanielNo ratings yet
- Journal ArticleDocument7 pagesJournal ArticleImmaculately Pretty0% (1)
- CHAPTER 1 (Recovered)Document45 pagesCHAPTER 1 (Recovered)Alif PramonoNo ratings yet
- Sampling ProceduresDocument19 pagesSampling ProceduresNiharika Satyadev Jaiswal100% (1)
- Descriptive StatisticsDocument98 pagesDescriptive StatisticsNMNG100% (1)