Download as doc, pdf, or txt
You might also like
- AP Calculus BC Study GuideDocument5 pagesAP Calculus BC Study GuideJohn MoonNo ratings yet
- Multiple Integrals and Its Application in Telecomm EngineeringDocument38 pagesMultiple Integrals and Its Application in Telecomm EngineeringNaveed Ramzan71% (7)
- Changing Fractions To Decimals and Percent and Vice VersaDocument13 pagesChanging Fractions To Decimals and Percent and Vice Versarommel legaspi100% (1)
- Simplex Algorithm - WikipediaDocument20 pagesSimplex Algorithm - WikipediaGalata BaneNo ratings yet
- Simplex AlgorithmDocument9 pagesSimplex AlgorithmMed AlmkhaifiNo ratings yet
- Simplex AlgorithmDocument10 pagesSimplex AlgorithmGetachew MekonnenNo ratings yet
- Module 7Document18 pagesModule 7shaina sucgangNo ratings yet
- 2nd Sem MathDocument15 pages2nd Sem MathJayesh khachaneNo ratings yet
- A New Algorithm For Linear Programming: Dhananjay P. Mehendale Sir Parashurambhau College, Tilak Road, Pune-411030, IndiaDocument20 pagesA New Algorithm For Linear Programming: Dhananjay P. Mehendale Sir Parashurambhau College, Tilak Road, Pune-411030, IndiaKinan Abu AsiNo ratings yet
- Open MethodsDocument9 pagesOpen Methodstatodc7No ratings yet
- Choosing Numbers For The Properties of Their SquaresDocument11 pagesChoosing Numbers For The Properties of Their SquaresHarshita ChaturvediNo ratings yet
- Least Squares OptimizationDocument8 pagesLeast Squares OptimizationAmnart L. JantharasukNo ratings yet
- Linear Programming: I Simulated AnnealingDocument5 pagesLinear Programming: I Simulated AnnealingIrfan Satrio MardaniNo ratings yet
- 9-Optimization and SimplexDocument16 pages9-Optimization and SimplexmelihNo ratings yet
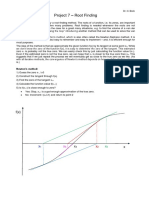
- Project 7 - Root Finding: Newton's MethodDocument4 pagesProject 7 - Root Finding: Newton's Methodhannan1993No ratings yet
- Understanding Lagrange Multipliers: F (X, Y) Constant, in The Xy Plane. The Bold Curve IsDocument3 pagesUnderstanding Lagrange Multipliers: F (X, Y) Constant, in The Xy Plane. The Bold Curve IscarolinaNo ratings yet
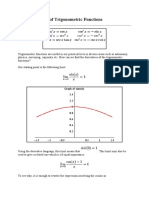
- The Derivatives of Trigonometric FunctionsDocument29 pagesThe Derivatives of Trigonometric FunctionsM Arifin RasdhakimNo ratings yet
- LP NotesDocument7 pagesLP NotesSumit VermaNo ratings yet
- Operational Research NotesDocument62 pagesOperational Research NotesMayank SainiNo ratings yet
- Simplex MethodDocument4 pagesSimplex MethodTharaka MethsaraNo ratings yet
- 16 LP 6 SimplexDocument25 pages16 LP 6 Simplexquangnhat1220No ratings yet
- Analysis of Solving The K-Center Problem Efficiently With A Dominating Set AlgorithmDocument11 pagesAnalysis of Solving The K-Center Problem Efficiently With A Dominating Set AlgorithmvkNo ratings yet
- Solution of Nonlinear EquationsDocument4 pagesSolution of Nonlinear Equationstarun gehlotNo ratings yet
- Quadratic ProgrammingDocument19 pagesQuadratic Programmingjabir sulaimanNo ratings yet
- A3 110006223Document7 pagesA3 110006223Samuel DharmaNo ratings yet
- ETH Zurich - Mechanics of Building Materials, Elastic TheoryDocument64 pagesETH Zurich - Mechanics of Building Materials, Elastic TheoryYan Naung KoNo ratings yet
- Operational Research Notes by AbhishekDocument55 pagesOperational Research Notes by AbhishekFirozaNo ratings yet
- 16 Linear Programming (November 29, December 1) : Confusingly, Some Authors Call This Standard FormDocument8 pages16 Linear Programming (November 29, December 1) : Confusingly, Some Authors Call This Standard FormYe MyatNo ratings yet
- Linear Programming TerminologyDocument16 pagesLinear Programming Terminologyradha gautamNo ratings yet
- Mathematical InductionDocument17 pagesMathematical InductionJayaram BhueNo ratings yet
- Assignment ProblemDocument7 pagesAssignment ProblemkesmatNo ratings yet
- Notes On NP Completeness: Rich Schwartz November 10, 2013Document18 pagesNotes On NP Completeness: Rich Schwartz November 10, 2013Sam ShoukatNo ratings yet
- Reviewer BSEE (Calculus)Document13 pagesReviewer BSEE (Calculus)Ronalyn ManzanoNo ratings yet
- Math OptimizationDocument11 pagesMath OptimizationAlexander ValverdeNo ratings yet
- Method of Steepest Descent and Its Applications: Department of Engineering, University of Tennessee, Knoxville, TN 37996Document3 pagesMethod of Steepest Descent and Its Applications: Department of Engineering, University of Tennessee, Knoxville, TN 37996seenagregoryNo ratings yet
- Comparing Riemann and Monte Carlo ApproximationDocument8 pagesComparing Riemann and Monte Carlo ApproximationryanfieldNo ratings yet
- Efficient Parallel Non-Negative Least Squares On Multi-Core ArchitecturesDocument16 pagesEfficient Parallel Non-Negative Least Squares On Multi-Core ArchitecturesJason StanleyNo ratings yet
- Xequivalence Between Schrödinger and Feynman Formalisms For Quantum Mechanics The Path Integral FormulationDocument14 pagesXequivalence Between Schrödinger and Feynman Formalisms For Quantum Mechanics The Path Integral FormulationDaniel FerreiraNo ratings yet
- Optimization Without Gradients: Powell's Method: Slides Adapted From Numerical Recipes in C, Second Edition (1992)Document35 pagesOptimization Without Gradients: Powell's Method: Slides Adapted From Numerical Recipes in C, Second Edition (1992)Nagendra KumarNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Huffman Codes: Spanning TreeDocument6 pagesHuffman Codes: Spanning TreeBhartiya NagrikNo ratings yet
- Chp2 LinalgDocument8 pagesChp2 LinalgLucas KevinNo ratings yet
- Thomson ProblemDocument11 pagesThomson ProblemdiegoNo ratings yet
- ME 17 - Homework #5 Solving Partial Differential Equations Poisson's EquationDocument10 pagesME 17 - Homework #5 Solving Partial Differential Equations Poisson's EquationRichardBehielNo ratings yet
- Differential CalculusDocument45 pagesDifferential CalculusShifra Jane PiqueroNo ratings yet
- Group 6Document39 pagesGroup 61DT20CS148 Sudarshan SinghNo ratings yet
- 5.7 Level Sets and The Fast Marching Method: C 2006 Gilbert StrangDocument4 pages5.7 Level Sets and The Fast Marching Method: C 2006 Gilbert StrangJay KanthNo ratings yet
- Helvetic Coding Contest 2018: A. Death StarsDocument8 pagesHelvetic Coding Contest 2018: A. Death StarsShahnaj ParvinNo ratings yet
- Bisection MethodDocument9 pagesBisection MethodAtika Mustari SamiNo ratings yet
- Name 1: - Drexel Username 1Document4 pagesName 1: - Drexel Username 1Bao DangNo ratings yet
- Math Integration 1DDocument7 pagesMath Integration 1Dమత్సా చంద్ర శేఖర్No ratings yet
- Differentiation and IntegrationDocument3 pagesDifferentiation and IntegrationElyssamae PonceNo ratings yet
- Numerical Solution of Ordinary Differential Equations Part 2 - Nonlinear EquationsDocument38 pagesNumerical Solution of Ordinary Differential Equations Part 2 - Nonlinear EquationsMelih TecerNo ratings yet
- CAM Part II: Intersections:) ), 0.0) Tolerance) X - F (X) /F' (X)Document5 pagesCAM Part II: Intersections:) ), 0.0) Tolerance) X - F (X) /F' (X)Thangadurai Senthil Ram PrabhuNo ratings yet
- 5 Linear Programming 2Document26 pages5 Linear Programming 2ReparrNo ratings yet
- Local Search in Smooth Convex Sets: CX Ax B A I A A A A A A O D X Ax B X CX CX O A I J Z O Opt D X X C A B P CXDocument9 pagesLocal Search in Smooth Convex Sets: CX Ax B A I A A A A A A O D X Ax B X CX CX O A I J Z O Opt D X X C A B P CXhellothapliyalNo ratings yet
- Sparse Implementation of Revised Simplex Algorithms On Parallel ComputersDocument8 pagesSparse Implementation of Revised Simplex Algorithms On Parallel ComputersKaram SalehNo ratings yet
- Describe The Structure of Mathematical Model in Your Own WordsDocument10 pagesDescribe The Structure of Mathematical Model in Your Own Wordskaranpuri6No ratings yet
- DAA - Unit V - Dynamic ProgrammingDocument37 pagesDAA - Unit V - Dynamic ProgrammingnishkarshNo ratings yet
- Scan Doc0002Document9 pagesScan Doc0002jonty777No ratings yet
- Notes On Linear Programming: CE 377K Stephen D. Boyles Spring 2015Document17 pagesNotes On Linear Programming: CE 377K Stephen D. Boyles Spring 2015SIRSHA PATTANAYAKNo ratings yet
- CH 9 Differential Equations Multiple Choice Questions With Answers PDFDocument2 pagesCH 9 Differential Equations Multiple Choice Questions With Answers PDFAman ChauhanNo ratings yet
- Advanced Numerical Analysis: Dr. Hisam Uddin Shaikh Professor and ChairmanDocument132 pagesAdvanced Numerical Analysis: Dr. Hisam Uddin Shaikh Professor and ChairmanZaheer Abbas PitafiNo ratings yet
- Student Text Answers: UNIT 22 Algebraic ConceptsDocument5 pagesStudent Text Answers: UNIT 22 Algebraic Conceptsapi-195130729No ratings yet
- Chapter 2 Isoparametric ElementDocument27 pagesChapter 2 Isoparametric ElementVijayakumarGsNo ratings yet
- Mathematics PetaDocument12 pagesMathematics PetaFrances OtanesNo ratings yet
- DBM 1013Document11 pagesDBM 1013Hari HaranNo ratings yet
- 53-Consolidation Exercise 3GDocument5 pages53-Consolidation Exercise 3G4D16 Lee Hoi Lam, Helen s190073No ratings yet
- ALGEBRADocument4 pagesALGEBRAJames Darwin SorianoNo ratings yet
- Chap 6.3Document15 pagesChap 6.3ntokozocecilia81No ratings yet
- FXN BNSLDocument46 pagesFXN BNSLAman ChandeNo ratings yet
- Degeneracy Methods in Real ArithmeticDocument8 pagesDegeneracy Methods in Real ArithmeticSreekar SahaNo ratings yet
- Unit Ii Vector Calculus Part-A: Problem 1 SolutionDocument22 pagesUnit Ii Vector Calculus Part-A: Problem 1 Solutionkenny kannaNo ratings yet
- Letts GcseDocument28 pagesLetts GcseAisha Brown100% (1)
- DERIVATIVEDocument8 pagesDERIVATIVENoel S. De Juan Jr.No ratings yet
- Unit 8 PackDocument25 pagesUnit 8 Pack11zeshan11No ratings yet
- 1 Quadratic Equations in One VariableDocument233 pages1 Quadratic Equations in One VariableMark Anthony B. IsraelNo ratings yet
- Quadratic Equation WeeblyDocument3 pagesQuadratic Equation Weeblyapi-633813701No ratings yet
- Villa College: Centre For Foundation StudiesDocument2 pagesVilla College: Centre For Foundation StudiesMular Abdul ShukoorNo ratings yet
- Algebra PDFDocument367 pagesAlgebra PDFGaurav GhoshNo ratings yet
- M 3 Assignment VDocument4 pagesM 3 Assignment Vrs VivoNo ratings yet
- HCI H2 Maths 2012 Prelim P1 SolutionsDocument12 pagesHCI H2 Maths 2012 Prelim P1 Solutionsnej200695No ratings yet
- 23.4.3 - The Method of Undetermined Coefficients Higher OrderDocument7 pages23.4.3 - The Method of Undetermined Coefficients Higher Orderanon_422073337No ratings yet
- Domain and Range Homework WorksheetDocument6 pagesDomain and Range Homework Worksheeterdy4162100% (1)
- Sheet Math2Document38 pagesSheet Math2Abdulmalik UmarNo ratings yet
- Numerical Methods For Scientists and Engineers by K. S. RaoDocument123 pagesNumerical Methods For Scientists and Engineers by K. S. RaoMeliza SouzaNo ratings yet
- Series FormulasDocument1 pageSeries FormulasFrank WilliamsNo ratings yet
- Karatsuba's Algorithm For Integer Multiplication: Jeremy R. JohnsonDocument17 pagesKaratsuba's Algorithm For Integer Multiplication: Jeremy R. Johnsonmaheepa pavuluriNo ratings yet
- Space Curves: B Spline Curves and Their ConstructionDocument28 pagesSpace Curves: B Spline Curves and Their ConstructionRubina HannureNo ratings yet
- Taylor Series Method For Solving Linear Fredholm Integral Equation of Second Kind Using MATLABDocument10 pagesTaylor Series Method For Solving Linear Fredholm Integral Equation of Second Kind Using MATLABHari Madhavan Krishna KumarNo ratings yet