Download as pdf or txt
You might also like
- Hayt Cap 8 SolutionDocument26 pagesHayt Cap 8 SolutionVitor Campos100% (4)
- Chapra Numerical Methods For Engineers 7th Ed 2015 PDFDocument2 pagesChapra Numerical Methods For Engineers 7th Ed 2015 PDFIsa AbubakarNo ratings yet
- Robustness of Logit Analysis: Unobserved Heterogeneity and Misspecified DisturbancesDocument14 pagesRobustness of Logit Analysis: Unobserved Heterogeneity and Misspecified DisturbancesAditya Agung SatrioNo ratings yet
- Estimating Dynamic Panel Data Models: A Guide For MacroeconomistsDocument7 pagesEstimating Dynamic Panel Data Models: A Guide For MacroeconomistsMuhamad Fikri AzizNo ratings yet
- Generalized Linear Models: Simon Jackman Stanford UniversityDocument7 pagesGeneralized Linear Models: Simon Jackman Stanford UniversityababacarbaNo ratings yet
- CH 5 SlidesDocument92 pagesCH 5 SlidesJohn DangNo ratings yet
- Condition NumDocument23 pagesCondition Num026Berochan MarikNo ratings yet
- Chapter 2: Causal and Noncausal Models: Advanced Econometrics 1Document31 pagesChapter 2: Causal and Noncausal Models: Advanced Econometrics 1Dana7117No ratings yet
- Extensions of The Two-Variable Linear Regression Model: TrueDocument13 pagesExtensions of The Two-Variable Linear Regression Model: TrueshrutiNo ratings yet
- Final 2006Document15 pagesFinal 2006Muhammad MurtazaNo ratings yet
- 1 Loglinear Models For Contingency TablesDocument12 pages1 Loglinear Models For Contingency TablesgennydatuinNo ratings yet
- Zhelonkin (2021) - R Package Robust AnalysisDocument35 pagesZhelonkin (2021) - R Package Robust AnalysisluisNo ratings yet
- CH 03Document8 pagesCH 03Carlos RogerioNo ratings yet
- Chapter 9Document48 pagesChapter 9John WongNo ratings yet
- ODE ProblemsDocument14 pagesODE ProblemsNelson RodríguezNo ratings yet
- Ecoa PivDocument4 pagesEcoa PivJudhajeet ChoudhuriNo ratings yet
- Silvapulle ExistenceMaximumLikelihood 1981Document5 pagesSilvapulle ExistenceMaximumLikelihood 1981jchill2018No ratings yet
- Integrating Without Polar CoordinatesDocument3 pagesIntegrating Without Polar CoordinatesDiego Pizarro RocoNo ratings yet
- 7th Lesson EconometricsDocument17 pages7th Lesson EconometricsGiorgi GetsadzeNo ratings yet
- Gretl Guide (401 450)Document50 pagesGretl Guide (401 450)Taha NajidNo ratings yet
- A Computational Study With Finite Element Method ADocument21 pagesA Computational Study With Finite Element Method AEisten Daniel Neto BombaNo ratings yet
- IE474 Summer2022 MathReview Ch0 PDFDocument33 pagesIE474 Summer2022 MathReview Ch0 PDFAmon SimatwoNo ratings yet
- Calculus I - Chapter 5 (Printed Version)Document65 pagesCalculus I - Chapter 5 (Printed Version)tranvutruynamNo ratings yet
- Heteroscedasticity 2024Document36 pagesHeteroscedasticity 2024ahmedtobar2003No ratings yet
- Econometrica - 2022 - Alvarez - The Analytic Theory of A Monetary Shock - OADocument26 pagesEconometrica - 2022 - Alvarez - The Analytic Theory of A Monetary Shock - OA穆伯扬No ratings yet
- 2019 Moderation SEM AsparouhovDocument46 pages2019 Moderation SEM AsparouhovUsman BaigNo ratings yet
- Generalized Ordered Logit/partial Proportional Odds Models For Ordinal Dependent VariablesDocument25 pagesGeneralized Ordered Logit/partial Proportional Odds Models For Ordinal Dependent VariablesCristopher Brandon Paucar TorreNo ratings yet
- MathDocument2 pagesMathHabiba ElsaghirNo ratings yet
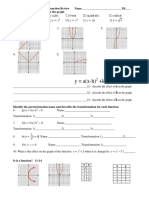
- 0-1 Parent Function ws1Document2 pages0-1 Parent Function ws1Andrew KimNo ratings yet
- 6 MulticolinearityDocument6 pages6 Multicolinearityhashinidharshikaso01No ratings yet
- TMQCD and Disconnected Diagrams: 1 Twisted Mass Basis and Physical BasisDocument6 pagesTMQCD and Disconnected Diagrams: 1 Twisted Mass Basis and Physical BasisAlejandro Marino Vaquero Avilés-CascoNo ratings yet
- Fea HandoutsDocument51 pagesFea HandoutsDr.A.Maniram KumarNo ratings yet
- Econometrics (EM2008) Specification Error in The The K-Variable ModelDocument31 pagesEconometrics (EM2008) Specification Error in The The K-Variable ModelSelMarie Nutelliina GomezNo ratings yet
- STEP 2 2020 MockDocument50 pagesSTEP 2 2020 MockAdrian PredaNo ratings yet
- The Independence of Irrelevant Alternatives - 230919 - 191757Document26 pagesThe Independence of Irrelevant Alternatives - 230919 - 191757davNo ratings yet
- Econometrie1 Split MergeDocument7 pagesEconometrie1 Split MergeLuuk van der KleijNo ratings yet
- Rec 4 20Document4 pagesRec 4 20Malek BlrNo ratings yet
- Published Paper ProjectDocument8 pagesPublished Paper ProjectModupeNo ratings yet
- MIT8 324F10 Lecture8Document6 pagesMIT8 324F10 Lecture8Ayham ziadNo ratings yet
- Yeni 1Document7 pagesYeni 1Lahcen AkerkouchNo ratings yet
- Gromov-Witten Theory of Bicyclic PairsDocument37 pagesGromov-Witten Theory of Bicyclic Pairshello.fleandrNo ratings yet
- Another Proof of 6ζ (2) =π^2 Using Double Integrals - Daniele Ritelli (AMM, v120, n7, 2013)Document5 pagesAnother Proof of 6ζ (2) =π^2 Using Double Integrals - Daniele Ritelli (AMM, v120, n7, 2013)Leandro AzNo ratings yet
- CHAPTER 2 - Lesson 3Document19 pagesCHAPTER 2 - Lesson 3Meljoy TenorioNo ratings yet
- GB ApplicationsDocument29 pagesGB Applicationsrandomrandom221No ratings yet
- New Inequalities Involving The Geometric-Arithmetic IndexDocument14 pagesNew Inequalities Involving The Geometric-Arithmetic Indexdragance106No ratings yet
- Fast Fourier Emulators Based On Space (Lling Lattices: R.A. Bates, E. Riccomagno, R. Schwabe and H.P. WynnDocument6 pagesFast Fourier Emulators Based On Space (Lling Lattices: R.A. Bates, E. Riccomagno, R. Schwabe and H.P. WynnEva RiccomagnoNo ratings yet
- Stochastic Volatility Models With Closed-Form SsolutionsDocument99 pagesStochastic Volatility Models With Closed-Form SsolutionsSolomon AntoniouNo ratings yet
- Disturbance Decoupling of Nonlinear MISO Systems BDocument10 pagesDisturbance Decoupling of Nonlinear MISO Systems Bhajar daoudiNo ratings yet
- Weyl EquationDocument6 pagesWeyl EquationadriandiracNo ratings yet
- The Dirac Matrix Group and Fierz TransformationsDocument21 pagesThe Dirac Matrix Group and Fierz TransformationsBenjamín Medina CarrilloNo ratings yet
- Five-dimensional Bigravity-New Topological Description of the UniverseDocument22 pagesFive-dimensional Bigravity-New Topological Description of the UniversePierre NICOLENo ratings yet
- AitkinDocument9 pagesAitkinbeli1070916480No ratings yet
- Limited Dependent Variables - Binary Dependent VariablesDocument24 pagesLimited Dependent Variables - Binary Dependent Variables颜推之No ratings yet
- Tut9 Soln SlidesDocument20 pagesTut9 Soln SlidesNathan HuangNo ratings yet
- 1.2.3 The Fundamental Theorem of Calculus: A F B F X F DX X FDocument8 pages1.2.3 The Fundamental Theorem of Calculus: A F B F X F DX X FEverything What U WantNo ratings yet
- Archiveiygb Practice Papersmathmeth1 Practice Papersmathmeth1 D PDFDocument9 pagesArchiveiygb Practice Papersmathmeth1 Practice Papersmathmeth1 D PDFsukhman070306No ratings yet
- Mathaeng3 M1-Cu5Document14 pagesMathaeng3 M1-Cu5Gdeity PlaysNo ratings yet
- JEDC2001Document18 pagesJEDC2001martin souman moulsiaNo ratings yet
- DecompositionDocument12 pagesDecompositionLuciana NóbregaNo ratings yet
- Ordered Logit Models - Basic & Intermediate TopicsDocument16 pagesOrdered Logit Models - Basic & Intermediate TopicsJavier Vargas DiazNo ratings yet
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)From EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)No ratings yet
- ml5 0 PDFDocument185 pagesml5 0 PDFDemitria Dini AriyaniNo ratings yet
- The Use of Multidimensional Scalling (MDS) For Mapping The Preference of Buying A CarDocument2 pagesThe Use of Multidimensional Scalling (MDS) For Mapping The Preference of Buying A CarDemitria Dini AriyaniNo ratings yet
- Aplikasi Integral:: Luas Bidang DatarDocument9 pagesAplikasi Integral:: Luas Bidang DatarDemitria Dini AriyaniNo ratings yet
- Daftar Perbaikan Praktikum Program Linear Kelas CDocument2 pagesDaftar Perbaikan Praktikum Program Linear Kelas CDemitria Dini AriyaniNo ratings yet
- Method 3 and ConclusionDocument2 pagesMethod 3 and Conclusion倩影No ratings yet
- Steps To Determine Wind Loads On MWFRS Rooftop Equipment and Other Structures (Solid Freestanding)Document8 pagesSteps To Determine Wind Loads On MWFRS Rooftop Equipment and Other Structures (Solid Freestanding)Jephte Soriba DequiniaNo ratings yet
- Predicting The Hydrate FormationDocument10 pagesPredicting The Hydrate FormationmviteazuNo ratings yet
- ES032 Assignment6Document6 pagesES032 Assignment6TerkNo ratings yet
- Siberian DiceDocument4 pagesSiberian DiceBarbNo ratings yet
- BA II Plus Calculator - User GuideDocument17 pagesBA II Plus Calculator - User GuidekithuciNo ratings yet
- Unbalanced Faults PDFDocument36 pagesUnbalanced Faults PDFnafahimNo ratings yet
- 5-1 Shock Waves and Expansion WavesDocument35 pages5-1 Shock Waves and Expansion WavesIndra KhandulukNo ratings yet
- 14.dear FriendsDocument14 pages14.dear FriendsSATISHNo ratings yet
- Designing and Implementing A Performance Management System in A Textile Company For Competitive AdvantageDocument26 pagesDesigning and Implementing A Performance Management System in A Textile Company For Competitive Advantager01852009paNo ratings yet
- Summative Test No. 1Document6 pagesSummative Test No. 1Shaine Dzyll KuizonNo ratings yet
- LibreOffice Calc Guide 6Document20 pagesLibreOffice Calc Guide 6Violeta XevinNo ratings yet
- Foundations of Math 1 SyllabusDocument4 pagesFoundations of Math 1 SyllabusMorlee MojicaNo ratings yet
- UCK351E Fall2012 M1QsDocument2 pagesUCK351E Fall2012 M1QsEser GülNo ratings yet
- Multivariate - Data - Selection: 0.1 How To Select Dataframe Subsets From Multivariate DataDocument8 pagesMultivariate - Data - Selection: 0.1 How To Select Dataframe Subsets From Multivariate DataSarah MendesNo ratings yet
- Utilization of ElectricalDocument421 pagesUtilization of ElectricalSuma SumalathaNo ratings yet
- Filters and Ultrafilters in Real AnalysisDocument31 pagesFilters and Ultrafilters in Real AnalysislerhlerhNo ratings yet
- Geometria PLDocument32 pagesGeometria PLjhdmssNo ratings yet
- The Hidden Symmetry of The Coulomb Problem in Relativistic Quantum Mechanics - From Pauli To Dirac (2006)Document5 pagesThe Hidden Symmetry of The Coulomb Problem in Relativistic Quantum Mechanics - From Pauli To Dirac (2006)Rivera ValdezNo ratings yet
- ME 2016 Spring 24 Homework 1Document3 pagesME 2016 Spring 24 Homework 1Pedro TNo ratings yet
- Haskell NotesDocument192 pagesHaskell Notesvikramkrishnan100% (1)
- Physics Report Simple PendulumDocument3 pagesPhysics Report Simple PendulumGracey- Ann Johnson100% (3)
- 315lecturech1 2 4Document19 pages315lecturech1 2 4noayran120No ratings yet
- Adoc - Pub Analisis Dan Perancangan 3d Modeling Kapal DenganDocument20 pagesAdoc - Pub Analisis Dan Perancangan 3d Modeling Kapal DenganBilly JonathanNo ratings yet
- الخطة الدراسية لتخصص الأوتوترونيكس الدبلومDocument9 pagesالخطة الدراسية لتخصص الأوتوترونيكس الدبلومAmer Fayz Masha'erhNo ratings yet
- PH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingDocument24 pagesPH D Agric EconomicsSeminarinAdvancedResearchMethodsHypothesistestingJummy Dr'chebatickNo ratings yet
- 2.0 - P34x - EN - MD - J76Document184 pages2.0 - P34x - EN - MD - J76Diana Vanessa VelCruzNo ratings yet
- 1mathematics SM025 (Integration) by Azmil Hafez (Student)Document32 pages1mathematics SM025 (Integration) by Azmil Hafez (Student)muhd zulkifliNo ratings yet
- Engineering Mechanics Statics Westmead International School: For Practice: Problem 1: Problem 3: Problem 5: Problem 7Document2 pagesEngineering Mechanics Statics Westmead International School: For Practice: Problem 1: Problem 3: Problem 5: Problem 7Up DownNo ratings yet