Download as doc, pdf, or txt
You might also like
- MGMT627 NotesDocument33 pagesMGMT627 NotesSyed Abdul Mussaver Shah71% (7)
- MGMT627 AssignmentDocument1 pageMGMT627 AssignmentSyed Abdul Mussaver ShahNo ratings yet
- Measures of Dispersion TendencyDocument7 pagesMeasures of Dispersion Tendencyashraf helmyNo ratings yet
- Tech Seminar Sem 2Document35 pagesTech Seminar Sem 2Athira SajeevNo ratings yet
- 3 Dispersion Skewness Kurtosis PDFDocument42 pages3 Dispersion Skewness Kurtosis PDFKelvin Kayode OlukojuNo ratings yet
- V2 Chapter4 Summer 2020 - 21 - TaggedDocument48 pagesV2 Chapter4 Summer 2020 - 21 - TaggedlamaNo ratings yet
- Lec006 - Measures of DispersionDocument42 pagesLec006 - Measures of DispersionTiee TieeNo ratings yet
- PDF Document 3Document35 pagesPDF Document 3Vivi ValentineNo ratings yet
- Statchapter 4Document22 pagesStatchapter 4Omar KamilNo ratings yet
- Stat (I) 4-6 MaterialDocument42 pagesStat (I) 4-6 Materialamareadios60No ratings yet
- Business Data Analytics Student 4-5Document74 pagesBusiness Data Analytics Student 4-5Siddharth KumarNo ratings yet
- Measures of DispersionDocument48 pagesMeasures of DispersionBiswajit RathNo ratings yet
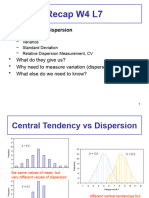
- Recap W4 L7: - Measures of DispersionDocument50 pagesRecap W4 L7: - Measures of Dispersionirdina athirahNo ratings yet
- Lecture 2.2 - Statistics - Desc Stat and DistribDocument48 pagesLecture 2.2 - Statistics - Desc Stat and Distribnguyenaiquynh150801No ratings yet
- Final Module 15 Measures of VariabilityDocument18 pagesFinal Module 15 Measures of Variability[G-08] Cristobal, Maria Pauline G.No ratings yet
- Measures of DispersionDocument22 pagesMeasures of DispersionCharisse R. Santillan80% (5)
- 1 - Descriptive Statistics Part 3Document41 pages1 - Descriptive Statistics Part 3Stephanie CañeteNo ratings yet
- Central TendencyDocument23 pagesCentral TendencyHatem DheerNo ratings yet
- Lecture 4 Measure of Central Tendency Ungrouped Freq DistDocument28 pagesLecture 4 Measure of Central Tendency Ungrouped Freq DistGeckoNo ratings yet
- Numerical Measures: Bf1206-Business Mathematics SEMESTER 2 - 2016/2017Document25 pagesNumerical Measures: Bf1206-Business Mathematics SEMESTER 2 - 2016/2017Muhammad AsifNo ratings yet
- Lecture No. 6 Measures of VariabilityDocument25 pagesLecture No. 6 Measures of VariabilityCzarina GuevarraNo ratings yet
- Worksheet 3 - CH3 (Numerical Measures)Document6 pagesWorksheet 3 - CH3 (Numerical Measures)abbasalawieh808No ratings yet
- Chapter Four: Measures of VariationDocument26 pagesChapter Four: Measures of VariationsossiNo ratings yet
- Unit 4 AssessmentDocument34 pagesUnit 4 AssessmentdaisylodorNo ratings yet
- Lecture 5Document25 pagesLecture 5Luna eukharisNo ratings yet
- ch03 Ver3Document25 pagesch03 Ver3Mustansar Hussain NiaziNo ratings yet
- Module 1c Descriptive Statistical MeasuresDocument41 pagesModule 1c Descriptive Statistical MeasuresLorifel Antonette Laoreno TejeroNo ratings yet
- Introduction To Probability and Statistics Thirteenth EditionDocument46 pagesIntroduction To Probability and Statistics Thirteenth EditionFadzli ZulkifiliNo ratings yet
- Measures of DispersionDocument71 pagesMeasures of DispersionvedikaNo ratings yet
- Descriptive Statistics 1Document63 pagesDescriptive Statistics 1Dr EngineerNo ratings yet
- Probability MC3020Document28 pagesProbability MC3020S Dinuka MadhushanNo ratings yet
- Week 5 - Result and Analysis 1 (UP)Document7 pagesWeek 5 - Result and Analysis 1 (UP)eddy siregarNo ratings yet
- 2 Descriptive StatDocument36 pages2 Descriptive Statshweta batraNo ratings yet
- 8Document6 pages8ameerel3tma77No ratings yet
- Saint Ma 'S College September 4, 2021: 6 October 2021Document30 pagesSaint Ma 'S College September 4, 2021: 6 October 2021Chin TampipiNo ratings yet
- Topic 1 Describing Data IIDocument68 pagesTopic 1 Describing Data IIanneshadas2005No ratings yet
- Lesson 5 Measure of Spread 1Document9 pagesLesson 5 Measure of Spread 1rahmanzainiNo ratings yet
- Handnote On B-Stat.-I-chapter-3Document57 pagesHandnote On B-Stat.-I-chapter-3Kim NamjoonneNo ratings yet
- Measures of DispersionDocument27 pagesMeasures of DispersionSakshi KarichNo ratings yet
- MAT2001-Statistics For Engineers: Measures of VariationDocument22 pagesMAT2001-Statistics For Engineers: Measures of VariationBharghav RoyNo ratings yet
- STAE Lecture Notes - LU3Document24 pagesSTAE Lecture Notes - LU3aneenzenda06No ratings yet
- MMW-MODULE6-Statistics Part 3 PDFDocument4 pagesMMW-MODULE6-Statistics Part 3 PDFJan Mark CastilloNo ratings yet
- Measure of Variation: Range: ST RDDocument10 pagesMeasure of Variation: Range: ST RDRyan wilfred LazadasNo ratings yet
- Chapter 4Document58 pagesChapter 4meia quiderNo ratings yet
- Chapter FourDocument21 pagesChapter FourAlazerNo ratings yet
- Chapter 3 ReviewDocument12 pagesChapter 3 Reviewapi-3829767100% (1)
- Chapter 1 Episode 3 - Measure of DispersionDocument10 pagesChapter 1 Episode 3 - Measure of DispersionAngel Ruby NovioNo ratings yet
- 2 - Chapter 1 - Measures of Central Tendency and Variation NewDocument18 pages2 - Chapter 1 - Measures of Central Tendency and Variation NewDmddldldldl100% (1)
- Measures of Central Tendency: Presentation By: Dr. Sampda RajurkarDocument44 pagesMeasures of Central Tendency: Presentation By: Dr. Sampda RajurkarVaishnavi Tiwari100% (1)
- Emgt 512 SP 2024Document156 pagesEmgt 512 SP 2024Vijay Kumar RashimalaluNo ratings yet
- Measures of Central Tendency: Presentation By: DR DharuvDocument44 pagesMeasures of Central Tendency: Presentation By: DR DharuvdharuvNo ratings yet
- Chapter 1Document44 pagesChapter 1Mohamed AdelNo ratings yet
- Summary of Midterm Lessons (20231106134417)Document9 pagesSummary of Midterm Lessons (20231106134417)Antonette LaurioNo ratings yet
- Chapter FourDocument21 pagesChapter Fourbeshahashenafe20No ratings yet
- Measures of The Centre AdvDocument42 pagesMeasures of The Centre AdvLight ChristopherNo ratings yet
- Lecture 1, BAS115Document57 pagesLecture 1, BAS115Viola JNo ratings yet
- Instructor'S Manual: Statistical Techniques in Financial ManagementDocument3 pagesInstructor'S Manual: Statistical Techniques in Financial Managementjoebloggs1888No ratings yet
- Last Formuas of First ChapterDocument20 pagesLast Formuas of First ChapterBharghav RoyNo ratings yet
- Measures of Central TendencyDocument15 pagesMeasures of Central TendencyAmit Gurav100% (15)
- Lecture 6Document34 pagesLecture 6Luna eukharisNo ratings yet
- IE 220 Probability and Statistics: 2009-2010 Spring Chapter 2: Descriptive Statistics: Numerical SummaryDocument41 pagesIE 220 Probability and Statistics: 2009-2010 Spring Chapter 2: Descriptive Statistics: Numerical SummaryTuna CanNo ratings yet
- GCSE Maths Revision: Cheeky Revision ShortcutsFrom EverandGCSE Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (2)
- Physics Philosophy Statistics Economics Finance Insurance Psychology Sociology Engineering Information Science MeasurementsDocument14 pagesPhysics Philosophy Statistics Economics Finance Insurance Psychology Sociology Engineering Information Science MeasurementsSyed Abdul Mussaver ShahNo ratings yet
- Sta301 GDB No 3Document7 pagesSta301 GDB No 3Syed Abdul Mussaver ShahNo ratings yet
- Assignment # 1 MC190205134 Q1.: Draw A Decision Tree Diagram Given The Above ConditionsDocument2 pagesAssignment # 1 MC190205134 Q1.: Draw A Decision Tree Diagram Given The Above ConditionsSyed Abdul Mussaver ShahNo ratings yet
- MGMT614 (2) NotesDocument82 pagesMGMT614 (2) NotesSyed Abdul Mussaver ShahNo ratings yet
- ENG301 Assignment Solution 2Document2 pagesENG301 Assignment Solution 2Syed Abdul Mussaver ShahNo ratings yet
- Assignment # 1 MC190205134 Q1. Intrinsic Value of The BondDocument3 pagesAssignment # 1 MC190205134 Q1. Intrinsic Value of The BondSyed Abdul Mussaver ShahNo ratings yet
- Fixed by The Supply Configuration From Previous PhaseDocument32 pagesFixed by The Supply Configuration From Previous PhaseSyed Abdul Mussaver Shah0% (1)
- Assignment # 1 MC190205134 Q1. Schematic Diagram: Moderate VariableDocument2 pagesAssignment # 1 MC190205134 Q1. Schematic Diagram: Moderate VariableSyed Abdul Mussaver ShahNo ratings yet
- MGT201 GDBDocument1 pageMGT201 GDBSyed Abdul Mussaver Shah100% (1)
- MGT510 GDB Idea Solution 2020Document1 pageMGT510 GDB Idea Solution 2020Syed Abdul Mussaver ShahNo ratings yet
- Discussion Question:: Type - I Projects Type - II Projects Type - III Projects Type - IV ProjectsDocument2 pagesDiscussion Question:: Type - I Projects Type - II Projects Type - III Projects Type - IV ProjectsSyed Abdul Mussaver ShahNo ratings yet
- Short Notes 23-34Document74 pagesShort Notes 23-34Syed Abdul Mussaver ShahNo ratings yet
- MGT510 AssignmentDocument2 pagesMGT510 AssignmentSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument67 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument90 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- MGT201 Lesson 6 & 7: Present Time Opportunity CostDocument2 pagesMGT201 Lesson 6 & 7: Present Time Opportunity CostSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument64 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument68 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- Eco402 GDB 1 Idea Solution Spring 2019Document2 pagesEco402 GDB 1 Idea Solution Spring 2019Syed Abdul Mussaver ShahNo ratings yet
- MGMT 627 Paper Question AnswerDocument2 pagesMGMT 627 Paper Question AnswerSyed Abdul Mussaver Shah0% (1)
- By Dr. Ali SajidDocument77 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument63 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument67 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument61 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- STA301 IMP Notes Headings and Some Questions Answers Prepared byDocument32 pagesSTA301 IMP Notes Headings and Some Questions Answers Prepared bySyed Abdul Mussaver ShahNo ratings yet
- By Dr. Ali SajidDocument54 pagesBy Dr. Ali SajidSyed Abdul Mussaver ShahNo ratings yet
- WWW - Vutube.Edu - PK: Finalterm ExaminationDocument11 pagesWWW - Vutube.Edu - PK: Finalterm ExaminationSyed Abdul Mussaver ShahNo ratings yet
- Today My MGT201 Paper: Please Pray For Me MCQ's Were ConceptualDocument3 pagesToday My MGT201 Paper: Please Pray For Me MCQ's Were ConceptualSyed Abdul Mussaver ShahNo ratings yet
- PDFDocument10 pagesPDFTu NguyenNo ratings yet
- Question Bank: Information Coding TechniquesDocument10 pagesQuestion Bank: Information Coding TechniquesManikandan ArunachalamNo ratings yet
- Fluid Dynamics: Ideal Fluid: Steady Flow: Streamline FlowDocument2 pagesFluid Dynamics: Ideal Fluid: Steady Flow: Streamline FlowVenu GopalNo ratings yet
- T Are A Potencial Electrico 2016Document4 pagesT Are A Potencial Electrico 2016Servando De La CruzNo ratings yet
- Stem Curriculum Sched Oct2016 PDFDocument1 pageStem Curriculum Sched Oct2016 PDFAlyssa PerniaNo ratings yet
- 5-E Model Lesson PlanDocument3 pages5-E Model Lesson Planapi-418555834No ratings yet
- Physics Research Assignment - G-Forces Acceleration of A Spin Hook KickDocument3 pagesPhysics Research Assignment - G-Forces Acceleration of A Spin Hook KickAsh PachelliNo ratings yet
- U5 L6 Applicationsof Quadratic Functions Day 1Document4 pagesU5 L6 Applicationsof Quadratic Functions Day 1jlo4uNo ratings yet
- (Solns and Errata) Dummit & Foote - Abstract Algebra - JulypraiseDocument3 pages(Solns and Errata) Dummit & Foote - Abstract Algebra - Julypraiseelvis3rebeliNo ratings yet
- PercentsDocument2 pagesPercentsonlineacademyatnhsdNo ratings yet
- Electron Spin Resonance Analysis and InterpretationDocument186 pagesElectron Spin Resonance Analysis and InterpretationMiyuki Speleo100% (1)
- How To Create A Geometric, WPAP Vector Portrait in Adobe IllustratorDocument16 pagesHow To Create A Geometric, WPAP Vector Portrait in Adobe IllustratorGabriel SetyohandokoNo ratings yet
- Edda ReportDocument18 pagesEdda Report140557No ratings yet
- Prob StatsDocument80 pagesProb StatsRahul SaxenaNo ratings yet
- Hobsonajjustthemaths20021296smcetp PDFDocument1,296 pagesHobsonajjustthemaths20021296smcetp PDFAIvan DCam G0% (1)
- Black-Scholes Options Pricing Calculator: Effect of A Change in The Stock PriceDocument7 pagesBlack-Scholes Options Pricing Calculator: Effect of A Change in The Stock PriceVinay KaraguppiNo ratings yet
- Cost Suggested Answer May 19Document28 pagesCost Suggested Answer May 19Saurabh sharmaNo ratings yet
- Introduction To Algorithms: Divide and ConquerDocument38 pagesIntroduction To Algorithms: Divide and Conquerchakshu agarwalNo ratings yet
- Tzidc-200 18348Document24 pagesTzidc-200 18348satindiaNo ratings yet
- Examinerreport Unit3 (WPH03) June2019Document7 pagesExaminerreport Unit3 (WPH03) June2019Rui Ming ZhangNo ratings yet
- Manual Stata 13Document371 pagesManual Stata 13IsaacCisneros100% (1)
- SyllabusDocument2 pagesSyllabusparas hasijaNo ratings yet
- ReapDocument1 pageReapAnil PambaNo ratings yet
- Paper Induced Subgraphs of Hypercubes and A Proof of The Sensitivity ConjectureDocument6 pagesPaper Induced Subgraphs of Hypercubes and A Proof of The Sensitivity ConjectureMuhamad Doris Bagindo SatiNo ratings yet
- Relationship Between Harmonics and Symmetrical Components: G. Atkinson-HopeDocument12 pagesRelationship Between Harmonics and Symmetrical Components: G. Atkinson-HopeMurali Krishna GbNo ratings yet
- Measuring S-Parameters - The First 50 YearsDocument15 pagesMeasuring S-Parameters - The First 50 YearsScribdFgNo ratings yet
- 2023 AMC - SeniorDocument7 pages2023 AMC - Seniorwangyong99No ratings yet
- Chapter 6 (Integration Techniques) : DX X XDocument27 pagesChapter 6 (Integration Techniques) : DX X XAfiqah ZainuddinNo ratings yet
- Civsyll 2018 Syllabus PDFDocument121 pagesCivsyll 2018 Syllabus PDFಗುರು ಪ್ರಶಾಂತ್No ratings yet