Download as pdf or txt
You might also like
- CH 4Document14 pagesCH 4Nazia Enayet100% (1)
- Uad Local Search Opt Final-1Document35 pagesUad Local Search Opt Final-1PrashantyelekarNo ratings yet
- Local Search and OptimizationDocument28 pagesLocal Search and OptimizationMazharulislamNo ratings yet
- Local Search Algos - Hill Climbing Simulated Anesaling Beam Search AlgosDocument31 pagesLocal Search Algos - Hill Climbing Simulated Anesaling Beam Search AlgostusharNo ratings yet
- Informed Search: Chapter 4 (B)Document27 pagesInformed Search: Chapter 4 (B)SHAMAL DANDGENo ratings yet
- Artificial Intelligence: Informed SearchDocument19 pagesArtificial Intelligence: Informed SearchalokchoudhuryNo ratings yet
- Informed SearchDocument27 pagesInformed SearchEwrwer EwrrwerNo ratings yet
- Hill ClimbingDocument5 pagesHill Climbinggabby209No ratings yet
- Institute of Southern Punjab Multan: Syed Zohair Quain Haider Lecturer ISP MultanDocument18 pagesInstitute of Southern Punjab Multan: Syed Zohair Quain Haider Lecturer ISP MultanCh MaaanNo ratings yet
- Local Search Algorithms: Chapter 4, Sections 3-4Document24 pagesLocal Search Algorithms: Chapter 4, Sections 3-4Carlos ArenasNo ratings yet
- AI Lab Assignmentc7Document5 pagesAI Lab Assignmentc7Sagar PrasadNo ratings yet
- CO2-session 8 & 9: Session No: Session Topic: Local Search AlgorithmsDocument43 pagesCO2-session 8 & 9: Session No: Session Topic: Local Search Algorithmssunny bandelaNo ratings yet
- Artificial Intelligence Chapter 4: Informed Searching MethodsDocument41 pagesArtificial Intelligence Chapter 4: Informed Searching MethodsMuhammad Sadiq Khan NasarNo ratings yet
- Local Search AlgorithmsDocument34 pagesLocal Search AlgorithmsMubasher ShahzadNo ratings yet
- Simulated Annealing and Tabu SearchDocument35 pagesSimulated Annealing and Tabu SearchIcko Judha Dharma PutraNo ratings yet
- Inform Search Chapter4 3 6Document8 pagesInform Search Chapter4 3 6vaghelamiralNo ratings yet
- 3 4optimizationDocument52 pages3 4optimizationashish.rawatNo ratings yet
- Iterative Improvement Algorithms: Prof. Tuomas Sandholm Carnegie Mellon University Computer Science DepartmentDocument10 pagesIterative Improvement Algorithms: Prof. Tuomas Sandholm Carnegie Mellon University Computer Science DepartmentBisrateab GebrieNo ratings yet
- AI Module 3 PartialDocument29 pagesAI Module 3 Partialsaiyaswin2004No ratings yet
- Problem SolvingDocument85 pagesProblem Solvingiu1nguoiNo ratings yet
- Searching Techniques-Heuristic Search: Sanjay Jain Associate Professor, ITM-MCA, GwaliorDocument54 pagesSearching Techniques-Heuristic Search: Sanjay Jain Associate Professor, ITM-MCA, GwaliorSanjay JainNo ratings yet
- Ahsanullah University of Science and Technology (AUST)Document6 pagesAhsanullah University of Science and Technology (AUST)Ashna AhmedNo ratings yet
- Problem Graphs Matching Hill ClimbingDocument32 pagesProblem Graphs Matching Hill ClimbingRaghu SomuNo ratings yet
- Heuristic SearchDocument44 pagesHeuristic SearchVighneshwarMadasNo ratings yet
- NIOT-UnitII-HillClimbing - and-SADocument6 pagesNIOT-UnitII-HillClimbing - and-SArt.cseNo ratings yet
- Hill Climbing ALgorithmDocument19 pagesHill Climbing ALgorithmVikash YadavNo ratings yet
- Local Search and Optimization: (Based On Slides of Padhraic Smyth, Stuart Russell, Rao Kambhampati, Raj Rao, Dan Weld )Document44 pagesLocal Search and Optimization: (Based On Slides of Padhraic Smyth, Stuart Russell, Rao Kambhampati, Raj Rao, Dan Weld )BalajiNo ratings yet
- Topic 3.6 Simulated AnnealingDocument19 pagesTopic 3.6 Simulated Annealingraju bhaiNo ratings yet
- SRDocument53 pagesSRMonisha KabramNo ratings yet
- Artificial Intelligence: Beyond Classical SearchDocument29 pagesArtificial Intelligence: Beyond Classical SearchPrasidha PrabhuNo ratings yet
- Fundamentals of Artificial Intelligence: Local Search AlgorithmsDocument32 pagesFundamentals of Artificial Intelligence: Local Search AlgorithmsDrRohini SharmaNo ratings yet
- Lecture-3 Problems Solving by SearchingDocument79 pagesLecture-3 Problems Solving by SearchingmusaNo ratings yet
- Lecture 3 Problems Solving by SearchingDocument78 pagesLecture 3 Problems Solving by SearchingMd.Ashiqur RahmanNo ratings yet
- c64f5b6f 1643697068078Document28 pagesc64f5b6f 1643697068078Preeti ToppoNo ratings yet
- Heuristic SearchDocument49 pagesHeuristic SearchsaikiranNo ratings yet
- Artificial Intelligence: Dr. Md. Nasim AdnanDocument25 pagesArtificial Intelligence: Dr. Md. Nasim AdnanshohanNo ratings yet
- Local Search and OptimizationDocument41 pagesLocal Search and OptimizationSupriya NevewaniNo ratings yet
- Summary AIDocument35 pagesSummary AIAnna Daalderop van WiggenNo ratings yet
- Hill Climbing Algorithm in AIDocument5 pagesHill Climbing Algorithm in AIAfaque AlamNo ratings yet
- 06 Local SearchDocument29 pages06 Local SearchmalaikaNo ratings yet
- Aiml DocxDocument11 pagesAiml DocxWbn tournamentsNo ratings yet
- Lecture 9 - Heuristic Search-I (AI)Document18 pagesLecture 9 - Heuristic Search-I (AI)Muhammad Umer ShahNo ratings yet
- 4.module3 INFORMED SEARCH 3Document48 pages4.module3 INFORMED SEARCH 3justadityabistNo ratings yet
- Hill Climbing MethodsDocument14 pagesHill Climbing Methodsapi-370591280% (5)
- We Will See A Different Form of Heuristic Search AppliedDocument17 pagesWe Will See A Different Form of Heuristic Search AppliedahsanulmNo ratings yet
- State Space Search: Week 3Document47 pagesState Space Search: Week 3tech surgeonsNo ratings yet
- Search StrategiesDocument16 pagesSearch StrategiesFranklin DorobaNo ratings yet
- Assignment - 05: Shivam Kamlesh Yadav BEIT-B4 77Document6 pagesAssignment - 05: Shivam Kamlesh Yadav BEIT-B4 77Game TwitcherNo ratings yet
- HeuristicDocument73 pagesHeuristicSwati HansNo ratings yet
- Problem Solving and SearchDocument100 pagesProblem Solving and SearchMohammad Omar FaruqNo ratings yet
- 1.2 Problem Solving - State Space Search (AIML)Document29 pages1.2 Problem Solving - State Space Search (AIML)Dogiparthi ManishaNo ratings yet
- Extra Notes Unit-5Document11 pagesExtra Notes Unit-5avishkargaikwad2024No ratings yet
- Heuristic SearchDocument50 pagesHeuristic SearchsahusandipanNo ratings yet
- 2-Heuristic SearchDocument19 pages2-Heuristic SearchSwapnil JoshiNo ratings yet
- Optimization Techniques: Sources UsedDocument54 pagesOptimization Techniques: Sources UsedPrasanth ShivanandamNo ratings yet
- Optimization Algorithms in MATLABDocument18 pagesOptimization Algorithms in MATLABYoun Seok ChoiNo ratings yet
- Chapter3 ProblemSolvingBySearchingDocument61 pagesChapter3 ProblemSolvingBySearchingimehedi357No ratings yet
- AI LAB 3bDocument17 pagesAI LAB 3bMAYURI PAWARNo ratings yet
- Stochastic Search Algorithms-IDocument19 pagesStochastic Search Algorithms-ITania CENo ratings yet
- End-to-End Efficient Heuristic Algorithm For 5G Network SlicingDocument7 pagesEnd-to-End Efficient Heuristic Algorithm For 5G Network Slicingpeter hardyNo ratings yet
- BTech IDocument2 pagesBTech Ipeter hardyNo ratings yet
- Chapter 6: STL Associative Containers and IteratorsDocument43 pagesChapter 6: STL Associative Containers and Iteratorspeter hardyNo ratings yet
- Bash Scripting Tutorial - LinuxConfigDocument23 pagesBash Scripting Tutorial - LinuxConfigpeter hardyNo ratings yet
- Gurukul Hindi e Book by Sirhud KalraDocument17 pagesGurukul Hindi e Book by Sirhud KalraPARVANo ratings yet
- Networx Nx-548E Receiver Installation Instructions: ContentDocument12 pagesNetworx Nx-548E Receiver Installation Instructions: ContentJefersom RodriguesNo ratings yet
- Construction and Working Principle of Transformers, ItsDocument12 pagesConstruction and Working Principle of Transformers, ItsSandeep Joshi100% (1)
- The Concept of Common Heritage of Mankind and The Genetic Resources of The Seabed Beyond The Limits of National JurisdictionDocument14 pagesThe Concept of Common Heritage of Mankind and The Genetic Resources of The Seabed Beyond The Limits of National JurisdictionPRIYANSHU KUMARNo ratings yet
- Introduction To Social Media Awareness 1Document5 pagesIntroduction To Social Media Awareness 1Dhruv SinghNo ratings yet
- Mg236b Rfid KeypadDocument4 pagesMg236b Rfid KeypadGunther FreyNo ratings yet
- SW 500Document28 pagesSW 500Sujit KumarNo ratings yet
- i30-Drive-N-Limited-EditioN-Product BulletinDocument2 pagesi30-Drive-N-Limited-EditioN-Product BulletinYaxuan ZhuNo ratings yet
- Ascension 2014 01Document14 pagesAscension 2014 01José SmitNo ratings yet
- Oops QuesBankDocument20 pagesOops QuesBanksantoshsugur628No ratings yet
- Catalog IDSI 3Document186 pagesCatalog IDSI 3Adrian OprisanNo ratings yet
- FOR Approval Specification: Title 32.0" Wuxga TFT LCDDocument36 pagesFOR Approval Specification: Title 32.0" Wuxga TFT LCDСергій НестеровичNo ratings yet
- Handbook of Practical Electrical Design, 3rd Edition: IEEE Electrical Insulation Magazine December 1999Document2 pagesHandbook of Practical Electrical Design, 3rd Edition: IEEE Electrical Insulation Magazine December 1999James FitzGeraldNo ratings yet
- Sana Younas UpdatedDocument4 pagesSana Younas Updatedsana qamarNo ratings yet
- Standard Costing and Variance AnalysisDocument2 pagesStandard Costing and Variance AnalysisMISRET 2018 IEI JSCNo ratings yet
- The Case Study of OliviaDocument2 pagesThe Case Study of Oliviabilly bongNo ratings yet
- Hold Time Studies 1661741387Document8 pagesHold Time Studies 1661741387Cyclone Pharmaceuticals Pvt Ltd PuneNo ratings yet
- CAMLIFE 2023 ProspectusDocument16 pagesCAMLIFE 2023 Prospectusboydilinh012No ratings yet
- PWI Series Indicators: User ManualDocument99 pagesPWI Series Indicators: User ManualHussein Beqai100% (1)
- DRRR Module 8 Concept of Disaster Risk Reduction and ManagementDocument22 pagesDRRR Module 8 Concept of Disaster Risk Reduction and ManagementJodie CabreraNo ratings yet
- Violet Cough SyrupDocument16 pagesViolet Cough SyrupMrBond666No ratings yet
- Orlando 2022Document15 pagesOrlando 2022ĐazzlerOnYtNo ratings yet
- DOC-01-031 - AFP-3030 Installation Manual (AUS) Rev ADocument52 pagesDOC-01-031 - AFP-3030 Installation Manual (AUS) Rev AMohamed RafihNo ratings yet
- U3A5 Practitioner's Handbook Organizing ChartDocument3 pagesU3A5 Practitioner's Handbook Organizing Chartkael9010 kael9010No ratings yet
- Regional Memorandum No. 550 s.2018 - 0001 PDFDocument10 pagesRegional Memorandum No. 550 s.2018 - 0001 PDFKayceej Perez100% (1)
- Mystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607Document14 pagesMystical Kashmir Vacation - With Houseboat Stay (14!04!2023T20 - 50) - QuoteId-25446607time delhiNo ratings yet
- An Overview of The Research of Psychological Entitlement. Definitions and Conceptual CharacteristicsDocument13 pagesAn Overview of The Research of Psychological Entitlement. Definitions and Conceptual CharacteristicsFarah AniaNo ratings yet
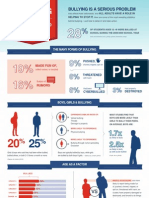
- What You Need To Know InfographicDocument1 pageWhat You Need To Know InfographicBitcoDavidNo ratings yet
- Format For CompilationDocument3 pagesFormat For CompilationPrincess Mia CristobalNo ratings yet
- Year 5 Maths Day 2 Two Way TablesDocument5 pagesYear 5 Maths Day 2 Two Way TablesvkumarNo ratings yet