
Latin Square Method PDF
Latin Square Method PDF
You might also like
- 3rd Quarter Exam in Math (Grade 2)Document3 pages3rd Quarter Exam in Math (Grade 2)Dyna Alonsagay Labindao100% (3)
- 12-13 Spectroscopy LabDocument8 pages12-13 Spectroscopy LabgAARaNo ratings yet
- C++ For Game ProgrammersDocument7 pagesC++ For Game ProgrammersdharmasaputraNo ratings yet
- Handbook of Hypergeometric Integrals PDFDocument160 pagesHandbook of Hypergeometric Integrals PDFYohansli Noya100% (3)
- ABCLX Driver Help: Citect Pty. LimitedDocument56 pagesABCLX Driver Help: Citect Pty. Limitedjoy insideoutNo ratings yet
- Latin Square DesignDocument8 pagesLatin Square DesigncambyckNo ratings yet
- Corrosion Lab ConclusionDocument5 pagesCorrosion Lab ConclusionDiane Iloveyou LeeNo ratings yet
- Objectives: The Nature of MatterDocument31 pagesObjectives: The Nature of MatterGene DacayoNo ratings yet
- Magnetic Properties of Ilmenite, Hematite and Oilsand Minerals After RoastingDocument9 pagesMagnetic Properties of Ilmenite, Hematite and Oilsand Minerals After RoastingBalakrushna PadhiNo ratings yet
- Chemical Periodicity: Marian Franciesca A. Santos Clarissa SomeraDocument4 pagesChemical Periodicity: Marian Franciesca A. Santos Clarissa Someramari_kkkkNo ratings yet
- Lab Report Corrosion-1Document10 pagesLab Report Corrosion-1areniqwardiah_918730100% (1)
- Handbook No.1Document125 pagesHandbook No.1Dhinakar AnnaduraiNo ratings yet
- Magnet Presentation - EMT PhysicsDocument24 pagesMagnet Presentation - EMT PhysicsletsjoyNo ratings yet
- KALORIMETERDocument8 pagesKALORIMETERSeliyaNo ratings yet
- Naming of Ionic CompoundsDocument24 pagesNaming of Ionic CompoundsDr. Ghulam Fareed100% (1)
- Mohs Hardness TestDocument3 pagesMohs Hardness TestSelva KumarNo ratings yet
- Radox TitrationDocument24 pagesRadox TitrationPooja Shinde100% (1)
- Solid-State Chemistry PDFDocument42 pagesSolid-State Chemistry PDFsudipta88No ratings yet
- Atomic BondingDocument18 pagesAtomic Bondingmadalus123No ratings yet
- Unit 1 Matter, Chemical Trends and Bonding: Elearning DDSB Dr. Aslam HaniefDocument63 pagesUnit 1 Matter, Chemical Trends and Bonding: Elearning DDSB Dr. Aslam HaniefSimra Parvez100% (1)
- The Particulate Nature of Matter - MindmapDocument1 pageThe Particulate Nature of Matter - MindmapEllen Koh100% (1)
- TernaryDocument8 pagesTernaryNino Rico LatupanNo ratings yet
- Complexation and Precipitation Reactions and TitrationsDocument53 pagesComplexation and Precipitation Reactions and TitrationsDivya TripathyNo ratings yet
- Topic 7. Double Block Designs: Latin Squares (ST&D 9.10-9.15)Document11 pagesTopic 7. Double Block Designs: Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Latin SquaresDocument65 pagesLatin Squarestoumazi0% (1)
- Latin Square DesignDocument46 pagesLatin Square DesignPonnammal Kuppusamy100% (1)
- Sudoku, Gerechte Designs, Resolutions, Affine Space, Spreads, Reguli, and Hamming CodesDocument31 pagesSudoku, Gerechte Designs, Resolutions, Affine Space, Spreads, Reguli, and Hamming CodesMahmoud NaguibNo ratings yet
- Expected Mean Squares (HZAU)Document11 pagesExpected Mean Squares (HZAU)Teflon SlimNo ratings yet
- 1.1 Experimental Designs I Stat 162 1Document66 pages1.1 Experimental Designs I Stat 162 1hmoody tNo ratings yet
- Trominos Deficient RectanglesDocument11 pagesTrominos Deficient RectanglesMadison CrockerNo ratings yet
- DAE14Document44 pagesDAE14ABHISHEK KUMAR CHAUHANNo ratings yet
- Text Chapter 1Document70 pagesText Chapter 1Kyle FanNo ratings yet
- Ann R16 Unit 2Document16 pagesAnn R16 Unit 2rashbari mNo ratings yet
- Row-Column Designs: 6.1 Double BlockingDocument11 pagesRow-Column Designs: 6.1 Double Blockinggsudhanta1604No ratings yet
- MMW Module 1 - Patterns, Transformation & FractalsDocument17 pagesMMW Module 1 - Patterns, Transformation & Fractalscai8viaNo ratings yet
- Latin Square Design Stat-301&stat-512Document7 pagesLatin Square Design Stat-301&stat-512Raksha SandilyaNo ratings yet
- Using Lattices For Reconstructing StemmaDocument9 pagesUsing Lattices For Reconstructing Stemmafeskalante_549880757No ratings yet
- Laue & Bravis Crystal LatticeDocument18 pagesLaue & Bravis Crystal LatticeRSLNo ratings yet
- Topic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)Document8 pagesTopic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Ejm Lattice DesignsDocument21 pagesEjm Lattice DesignsMaría C. SanabriamNo ratings yet
- American Mathematical Society Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Mathematics of ComputationDocument3 pagesAmerican Mathematical Society Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Mathematics of ComputationDeyvis Anibal Quispe MendozaNo ratings yet
- Ku Assignment 4th Sem 41Document9 pagesKu Assignment 4th Sem 41Rachit KhandelwalNo ratings yet
- Lecture 1Document94 pagesLecture 1jitiw92989No ratings yet
- Time Sereis in RDocument76 pagesTime Sereis in RJaber YassineNo ratings yet
- DMS CH5 Lattices Counting PPT FinalDocument17 pagesDMS CH5 Lattices Counting PPT FinalView PresentNo ratings yet
- Course: General Mathematics and Statistics (6401) Semester: Spring, 2021Document8 pagesCourse: General Mathematics and Statistics (6401) Semester: Spring, 2021Aakashkhan AakashkhanNo ratings yet
- Lecture 1: Latin Squares (Enumeration, Partial, Graphs)Document7 pagesLecture 1: Latin Squares (Enumeration, Partial, Graphs)juan perez arrikitaunNo ratings yet
- Unit 2Document17 pagesUnit 2cooooool1927No ratings yet
- Algebra 2 PortfolioDocument10 pagesAlgebra 2 PortfolioMr. NegreteNo ratings yet
- Grade 9 Math Slo BaseDocument3 pagesGrade 9 Math Slo Baseyusha habibNo ratings yet
- 2.5.5 Crossover Designs For Three or More FormulationsDocument5 pages2.5.5 Crossover Designs For Three or More FormulationsRahayuJaranImoetYukikoNo ratings yet
- 4 Graphs - ApesDocument6 pages4 Graphs - Apesapi-237881098No ratings yet
- Row-Column Designs: January 2001Document10 pagesRow-Column Designs: January 2001Nanmita SinghNo ratings yet
- 254 Exam 1 Practice Problems F2014Document3 pages254 Exam 1 Practice Problems F2014kerbsyNo ratings yet
- Java Programming For BSC It 4th Sem Kuvempu UniversityDocument52 pagesJava Programming For BSC It 4th Sem Kuvempu UniversityUsha Shaw100% (1)
- Using The Slide RuleDocument56 pagesUsing The Slide RuleRafael AlmeidaNo ratings yet
- Spectral Analysis of ScalesDocument392 pagesSpectral Analysis of Scalesrich_cochrane87% (15)
- Ozdamar (2014) - Bootstrapping Correspondence AnalysisDocument11 pagesOzdamar (2014) - Bootstrapping Correspondence AnalysisAhmad HassanNo ratings yet
- Chapter No. 04 Randomized Blocks, Latin Square, and Related Designs - 02 (Presentation)Document38 pagesChapter No. 04 Randomized Blocks, Latin Square, and Related Designs - 02 (Presentation)Sahib Ullah MukhlisNo ratings yet
- Systems of Differential EquationsDocument69 pagesSystems of Differential EquationsPeter Ndung'u100% (1)
- Differential Calculus Application ProblemsDocument23 pagesDifferential Calculus Application ProblemsJeric PonterasNo ratings yet
- Abdi ValentinDocument13 pagesAbdi ValentingiancarlomoronNo ratings yet
- 05PC11 Chapter05Document41 pages05PC11 Chapter05TuyếnĐặng100% (1)
- Brief Review of TensorsDocument15 pagesBrief Review of TensorsG Hernán Chávez LandázuriNo ratings yet
- Vocabulary 03-01-2021Document3 pagesVocabulary 03-01-2021Abro FatimaNo ratings yet
- One Liner Best Notes For One Paper ExamsDocument96 pagesOne Liner Best Notes For One Paper ExamsAbro FatimaNo ratings yet
- Pak Affairs Mcqs World TimesDocument14 pagesPak Affairs Mcqs World TimesAbro FatimaNo ratings yet
- 1styear Full Book Statistics PBDocument249 pages1styear Full Book Statistics PBAbro FatimaNo ratings yet
- 1 Definition of A Scale Parameter: Avd. Matematisk StatistikDocument5 pages1 Definition of A Scale Parameter: Avd. Matematisk StatistikAbro FatimaNo ratings yet
- Lesson 1 - Horizontal CurvesDocument43 pagesLesson 1 - Horizontal CurvesAthena ClubNo ratings yet
- Iit Jee (Links)Document5 pagesIit Jee (Links)Tarun MankadNo ratings yet
- CBC Monitor: Inter-Laboratory Comparison ProgramDocument10 pagesCBC Monitor: Inter-Laboratory Comparison ProgramgeohhhNo ratings yet
- Positive Participants Negative Participants: Mean Mean Mode Mode Median Median Standard Deviation Standard Deviation N NDocument5 pagesPositive Participants Negative Participants: Mean Mean Mode Mode Median Median Standard Deviation Standard Deviation N NThe SpartanNo ratings yet
- DgcaDocument50 pagesDgcaprachatNo ratings yet
- Logic Building QuestionsDocument6 pagesLogic Building Questionssadil6957No ratings yet
- Multiphase FlowsDocument46 pagesMultiphase FlowsAwadh Kapoor100% (2)
- Advanced Model CheckingDocument3 pagesAdvanced Model CheckingJunaid AkramNo ratings yet
- Chapter 07Document22 pagesChapter 07aclivisNo ratings yet
- Crash Course JEE Advanced Sample EbookDocument31 pagesCrash Course JEE Advanced Sample EbookmisostudyNo ratings yet
- MGT201 Chapter 6Document35 pagesMGT201 Chapter 6ImRanSaudNo ratings yet
- Introduction To Numpy - Ipynb - ColaboratoryDocument11 pagesIntroduction To Numpy - Ipynb - ColaboratoryVincent GiangNo ratings yet
- DLL Mathematics 6 q3 w10Document7 pagesDLL Mathematics 6 q3 w10Ramil GalidoNo ratings yet
- Working Notes - Psy Assessment (REVIEW)Document5 pagesWorking Notes - Psy Assessment (REVIEW)Kaye Hyacinth MoslaresNo ratings yet
- Homschfss 2Document44 pagesHomschfss 2Nguyen DuyNo ratings yet
- SDVC34 Series Controller User ManualDocument60 pagesSDVC34 Series Controller User ManualAnderson GonçalvesNo ratings yet
- 2.HCF &LCM2Document22 pages2.HCF &LCM2Arunachalam NarayananNo ratings yet
- Paper NTEa9QhNDocument62 pagesPaper NTEa9QhN熊伟博No ratings yet
- Intermediate Algebra With Applications and Visualization 5th Edition Rockswold Test Bank DownloadDocument63 pagesIntermediate Algebra With Applications and Visualization 5th Edition Rockswold Test Bank DownloadPreston Warfield100% (24)
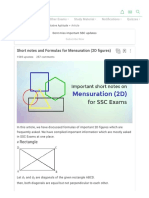
- Short Notes and Formulas For Mensuration (2D Figures)Document11 pagesShort Notes and Formulas For Mensuration (2D Figures)jigneshNo ratings yet
- Instrumentation Lab 09Document9 pagesInstrumentation Lab 09zaib zafarNo ratings yet
- Watzlawick-1967-Some Tentative Axioms of Communication PDFDocument14 pagesWatzlawick-1967-Some Tentative Axioms of Communication PDFSyeikha El FatihNo ratings yet
- KD Kakuro 5x5 v3 s2 b045Document3 pagesKD Kakuro 5x5 v3 s2 b045RADU GABINo ratings yet
- DDD Star HomDocument5 pagesDDD Star HomDumitru D. DRAGHIANo ratings yet
- Studi Perilaku Mahasiswa Arsitektur Terhadap KantinDocument12 pagesStudi Perilaku Mahasiswa Arsitektur Terhadap KantinAdrianjnnkiNo ratings yet
- JavaScript Syntax, Part I - Learn JavaScript Syntax - Introduction Cheatsheet - CodecademyDocument6 pagesJavaScript Syntax, Part I - Learn JavaScript Syntax - Introduction Cheatsheet - Codecademyilias ahmed100% (1)





























































































Download as pdf or txt
You might also like
- 3rd Quarter Exam in Math (Grade 2)Document3 pages3rd Quarter Exam in Math (Grade 2)Dyna Alonsagay Labindao100% (3)
- 12-13 Spectroscopy LabDocument8 pages12-13 Spectroscopy LabgAARaNo ratings yet
- C++ For Game ProgrammersDocument7 pagesC++ For Game ProgrammersdharmasaputraNo ratings yet
- Handbook of Hypergeometric Integrals PDFDocument160 pagesHandbook of Hypergeometric Integrals PDFYohansli Noya100% (3)
- ABCLX Driver Help: Citect Pty. LimitedDocument56 pagesABCLX Driver Help: Citect Pty. Limitedjoy insideoutNo ratings yet
- Latin Square DesignDocument8 pagesLatin Square DesigncambyckNo ratings yet
- Corrosion Lab ConclusionDocument5 pagesCorrosion Lab ConclusionDiane Iloveyou LeeNo ratings yet
- Objectives: The Nature of MatterDocument31 pagesObjectives: The Nature of MatterGene DacayoNo ratings yet
- Magnetic Properties of Ilmenite, Hematite and Oilsand Minerals After RoastingDocument9 pagesMagnetic Properties of Ilmenite, Hematite and Oilsand Minerals After RoastingBalakrushna PadhiNo ratings yet
- Chemical Periodicity: Marian Franciesca A. Santos Clarissa SomeraDocument4 pagesChemical Periodicity: Marian Franciesca A. Santos Clarissa Someramari_kkkkNo ratings yet
- Lab Report Corrosion-1Document10 pagesLab Report Corrosion-1areniqwardiah_918730100% (1)
- Handbook No.1Document125 pagesHandbook No.1Dhinakar AnnaduraiNo ratings yet
- Magnet Presentation - EMT PhysicsDocument24 pagesMagnet Presentation - EMT PhysicsletsjoyNo ratings yet
- KALORIMETERDocument8 pagesKALORIMETERSeliyaNo ratings yet
- Naming of Ionic CompoundsDocument24 pagesNaming of Ionic CompoundsDr. Ghulam Fareed100% (1)
- Mohs Hardness TestDocument3 pagesMohs Hardness TestSelva KumarNo ratings yet
- Radox TitrationDocument24 pagesRadox TitrationPooja Shinde100% (1)
- Solid-State Chemistry PDFDocument42 pagesSolid-State Chemistry PDFsudipta88No ratings yet
- Atomic BondingDocument18 pagesAtomic Bondingmadalus123No ratings yet
- Unit 1 Matter, Chemical Trends and Bonding: Elearning DDSB Dr. Aslam HaniefDocument63 pagesUnit 1 Matter, Chemical Trends and Bonding: Elearning DDSB Dr. Aslam HaniefSimra Parvez100% (1)
- The Particulate Nature of Matter - MindmapDocument1 pageThe Particulate Nature of Matter - MindmapEllen Koh100% (1)
- TernaryDocument8 pagesTernaryNino Rico LatupanNo ratings yet
- Complexation and Precipitation Reactions and TitrationsDocument53 pagesComplexation and Precipitation Reactions and TitrationsDivya TripathyNo ratings yet
- Topic 7. Double Block Designs: Latin Squares (ST&D 9.10-9.15)Document11 pagesTopic 7. Double Block Designs: Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Latin SquaresDocument65 pagesLatin Squarestoumazi0% (1)
- Latin Square DesignDocument46 pagesLatin Square DesignPonnammal Kuppusamy100% (1)
- Sudoku, Gerechte Designs, Resolutions, Affine Space, Spreads, Reguli, and Hamming CodesDocument31 pagesSudoku, Gerechte Designs, Resolutions, Affine Space, Spreads, Reguli, and Hamming CodesMahmoud NaguibNo ratings yet
- Expected Mean Squares (HZAU)Document11 pagesExpected Mean Squares (HZAU)Teflon SlimNo ratings yet
- 1.1 Experimental Designs I Stat 162 1Document66 pages1.1 Experimental Designs I Stat 162 1hmoody tNo ratings yet
- Trominos Deficient RectanglesDocument11 pagesTrominos Deficient RectanglesMadison CrockerNo ratings yet
- DAE14Document44 pagesDAE14ABHISHEK KUMAR CHAUHANNo ratings yet
- Text Chapter 1Document70 pagesText Chapter 1Kyle FanNo ratings yet
- Ann R16 Unit 2Document16 pagesAnn R16 Unit 2rashbari mNo ratings yet
- Row-Column Designs: 6.1 Double BlockingDocument11 pagesRow-Column Designs: 6.1 Double Blockinggsudhanta1604No ratings yet
- MMW Module 1 - Patterns, Transformation & FractalsDocument17 pagesMMW Module 1 - Patterns, Transformation & Fractalscai8viaNo ratings yet
- Latin Square Design Stat-301&stat-512Document7 pagesLatin Square Design Stat-301&stat-512Raksha SandilyaNo ratings yet
- Using Lattices For Reconstructing StemmaDocument9 pagesUsing Lattices For Reconstructing Stemmafeskalante_549880757No ratings yet
- Laue & Bravis Crystal LatticeDocument18 pagesLaue & Bravis Crystal LatticeRSLNo ratings yet
- Topic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)Document8 pagesTopic 7. Double Grouping. Latin Squares (ST&D 9.10-9.15)maleticjNo ratings yet
- Ejm Lattice DesignsDocument21 pagesEjm Lattice DesignsMaría C. SanabriamNo ratings yet
- American Mathematical Society Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Mathematics of ComputationDocument3 pagesAmerican Mathematical Society Is Collaborating With JSTOR To Digitize, Preserve and Extend Access To Mathematics of ComputationDeyvis Anibal Quispe MendozaNo ratings yet
- Ku Assignment 4th Sem 41Document9 pagesKu Assignment 4th Sem 41Rachit KhandelwalNo ratings yet
- Lecture 1Document94 pagesLecture 1jitiw92989No ratings yet
- Time Sereis in RDocument76 pagesTime Sereis in RJaber YassineNo ratings yet
- DMS CH5 Lattices Counting PPT FinalDocument17 pagesDMS CH5 Lattices Counting PPT FinalView PresentNo ratings yet
- Course: General Mathematics and Statistics (6401) Semester: Spring, 2021Document8 pagesCourse: General Mathematics and Statistics (6401) Semester: Spring, 2021Aakashkhan AakashkhanNo ratings yet
- Lecture 1: Latin Squares (Enumeration, Partial, Graphs)Document7 pagesLecture 1: Latin Squares (Enumeration, Partial, Graphs)juan perez arrikitaunNo ratings yet
- Unit 2Document17 pagesUnit 2cooooool1927No ratings yet
- Algebra 2 PortfolioDocument10 pagesAlgebra 2 PortfolioMr. NegreteNo ratings yet
- Grade 9 Math Slo BaseDocument3 pagesGrade 9 Math Slo Baseyusha habibNo ratings yet
- 2.5.5 Crossover Designs For Three or More FormulationsDocument5 pages2.5.5 Crossover Designs For Three or More FormulationsRahayuJaranImoetYukikoNo ratings yet
- 4 Graphs - ApesDocument6 pages4 Graphs - Apesapi-237881098No ratings yet
- Row-Column Designs: January 2001Document10 pagesRow-Column Designs: January 2001Nanmita SinghNo ratings yet
- 254 Exam 1 Practice Problems F2014Document3 pages254 Exam 1 Practice Problems F2014kerbsyNo ratings yet
- Java Programming For BSC It 4th Sem Kuvempu UniversityDocument52 pagesJava Programming For BSC It 4th Sem Kuvempu UniversityUsha Shaw100% (1)
- Using The Slide RuleDocument56 pagesUsing The Slide RuleRafael AlmeidaNo ratings yet
- Spectral Analysis of ScalesDocument392 pagesSpectral Analysis of Scalesrich_cochrane87% (15)
- Ozdamar (2014) - Bootstrapping Correspondence AnalysisDocument11 pagesOzdamar (2014) - Bootstrapping Correspondence AnalysisAhmad HassanNo ratings yet
- Chapter No. 04 Randomized Blocks, Latin Square, and Related Designs - 02 (Presentation)Document38 pagesChapter No. 04 Randomized Blocks, Latin Square, and Related Designs - 02 (Presentation)Sahib Ullah MukhlisNo ratings yet
- Systems of Differential EquationsDocument69 pagesSystems of Differential EquationsPeter Ndung'u100% (1)
- Differential Calculus Application ProblemsDocument23 pagesDifferential Calculus Application ProblemsJeric PonterasNo ratings yet
- Abdi ValentinDocument13 pagesAbdi ValentingiancarlomoronNo ratings yet
- 05PC11 Chapter05Document41 pages05PC11 Chapter05TuyếnĐặng100% (1)
- Brief Review of TensorsDocument15 pagesBrief Review of TensorsG Hernán Chávez LandázuriNo ratings yet
- Vocabulary 03-01-2021Document3 pagesVocabulary 03-01-2021Abro FatimaNo ratings yet
- One Liner Best Notes For One Paper ExamsDocument96 pagesOne Liner Best Notes For One Paper ExamsAbro FatimaNo ratings yet
- Pak Affairs Mcqs World TimesDocument14 pagesPak Affairs Mcqs World TimesAbro FatimaNo ratings yet
- 1styear Full Book Statistics PBDocument249 pages1styear Full Book Statistics PBAbro FatimaNo ratings yet
- 1 Definition of A Scale Parameter: Avd. Matematisk StatistikDocument5 pages1 Definition of A Scale Parameter: Avd. Matematisk StatistikAbro FatimaNo ratings yet
- Lesson 1 - Horizontal CurvesDocument43 pagesLesson 1 - Horizontal CurvesAthena ClubNo ratings yet
- Iit Jee (Links)Document5 pagesIit Jee (Links)Tarun MankadNo ratings yet
- CBC Monitor: Inter-Laboratory Comparison ProgramDocument10 pagesCBC Monitor: Inter-Laboratory Comparison ProgramgeohhhNo ratings yet
- Positive Participants Negative Participants: Mean Mean Mode Mode Median Median Standard Deviation Standard Deviation N NDocument5 pagesPositive Participants Negative Participants: Mean Mean Mode Mode Median Median Standard Deviation Standard Deviation N NThe SpartanNo ratings yet
- DgcaDocument50 pagesDgcaprachatNo ratings yet
- Logic Building QuestionsDocument6 pagesLogic Building Questionssadil6957No ratings yet
- Multiphase FlowsDocument46 pagesMultiphase FlowsAwadh Kapoor100% (2)
- Advanced Model CheckingDocument3 pagesAdvanced Model CheckingJunaid AkramNo ratings yet
- Chapter 07Document22 pagesChapter 07aclivisNo ratings yet
- Crash Course JEE Advanced Sample EbookDocument31 pagesCrash Course JEE Advanced Sample EbookmisostudyNo ratings yet
- MGT201 Chapter 6Document35 pagesMGT201 Chapter 6ImRanSaudNo ratings yet
- Introduction To Numpy - Ipynb - ColaboratoryDocument11 pagesIntroduction To Numpy - Ipynb - ColaboratoryVincent GiangNo ratings yet
- DLL Mathematics 6 q3 w10Document7 pagesDLL Mathematics 6 q3 w10Ramil GalidoNo ratings yet
- Working Notes - Psy Assessment (REVIEW)Document5 pagesWorking Notes - Psy Assessment (REVIEW)Kaye Hyacinth MoslaresNo ratings yet
- Homschfss 2Document44 pagesHomschfss 2Nguyen DuyNo ratings yet
- SDVC34 Series Controller User ManualDocument60 pagesSDVC34 Series Controller User ManualAnderson GonçalvesNo ratings yet
- 2.HCF &LCM2Document22 pages2.HCF &LCM2Arunachalam NarayananNo ratings yet
- Paper NTEa9QhNDocument62 pagesPaper NTEa9QhN熊伟博No ratings yet
- Intermediate Algebra With Applications and Visualization 5th Edition Rockswold Test Bank DownloadDocument63 pagesIntermediate Algebra With Applications and Visualization 5th Edition Rockswold Test Bank DownloadPreston Warfield100% (24)
- Short Notes and Formulas For Mensuration (2D Figures)Document11 pagesShort Notes and Formulas For Mensuration (2D Figures)jigneshNo ratings yet
- Instrumentation Lab 09Document9 pagesInstrumentation Lab 09zaib zafarNo ratings yet
- Watzlawick-1967-Some Tentative Axioms of Communication PDFDocument14 pagesWatzlawick-1967-Some Tentative Axioms of Communication PDFSyeikha El FatihNo ratings yet
- KD Kakuro 5x5 v3 s2 b045Document3 pagesKD Kakuro 5x5 v3 s2 b045RADU GABINo ratings yet
- DDD Star HomDocument5 pagesDDD Star HomDumitru D. DRAGHIANo ratings yet
- Studi Perilaku Mahasiswa Arsitektur Terhadap KantinDocument12 pagesStudi Perilaku Mahasiswa Arsitektur Terhadap KantinAdrianjnnkiNo ratings yet
- JavaScript Syntax, Part I - Learn JavaScript Syntax - Introduction Cheatsheet - CodecademyDocument6 pagesJavaScript Syntax, Part I - Learn JavaScript Syntax - Introduction Cheatsheet - Codecademyilias ahmed100% (1)