Download as docx, pdf, or txt
You might also like
- TIPERs Sensemaking Tasks For Introductory Physics 1st Edition Hieggelke Solutions Manual PDFDocument66 pagesTIPERs Sensemaking Tasks For Introductory Physics 1st Edition Hieggelke Solutions Manual PDFa50157970775% (4)
- SMDM Project Report - Shubham Bakshi - 07.05.2023Document23 pagesSMDM Project Report - Shubham Bakshi - 07.05.2023Abhishek Arya0% (1)
- Data Mining Cup 2010 ReportDocument7 pagesData Mining Cup 2010 ReportPutu Yunia SaputraNo ratings yet
- ISM Assignment 2Document48 pagesISM Assignment 2sridevi04No ratings yet
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- FRA Milestone1 - MaminulislamDocument23 pagesFRA Milestone1 - MaminulislamMaminul Islam100% (4)
- Australian Standard: Design Charts For Water Supply and SewerageDocument8 pagesAustralian Standard: Design Charts For Water Supply and Sewerageqt11250% (1)
- 7451 - Summative Assessment MemorandumDocument15 pages7451 - Summative Assessment MemorandumForbet100% (1)
- DM Gopala Satish Kumar Business Report G8 DSBADocument26 pagesDM Gopala Satish Kumar Business Report G8 DSBASatish Kumar100% (2)
- Jmp004 Film On The RocksDocument9 pagesJmp004 Film On The RocksDIPTASHREE MONDALNo ratings yet
- Measurement and Scaling: UNIT:03Document36 pagesMeasurement and Scaling: UNIT:03Nishant JoshiNo ratings yet
- Data Mining - Classification Using Frequent PatternDocument8 pagesData Mining - Classification Using Frequent PatternwindaNo ratings yet
- Assignment ProblemsDocument7 pagesAssignment ProblemsHari HaranNo ratings yet
- Ryff's Six-Factor Model of Psychological Well-BeingDocument7 pagesRyff's Six-Factor Model of Psychological Well-BeingYogi Sastrawan100% (1)
- Group Assignment - AS GRP 5 PDFDocument37 pagesGroup Assignment - AS GRP 5 PDFprabu2125No ratings yet
- 7B-Data - Handling - and - BI - 21 Part 2Document12 pages7B-Data - Handling - and - BI - 21 Part 2catalina doogaruNo ratings yet
- 14 - Chapter 5Document30 pages14 - Chapter 5Harpreet KaurNo ratings yet
- g9 s2 PblreportDocument13 pagesg9 s2 PblreportAwang Ali Zainul Abidin Bin Awang Ali RahmanNo ratings yet
- Britannia Industry IntroductionDocument7 pagesBritannia Industry Introductiontarun0% (1)
- Assignment 1 SOLUTIONDocument11 pagesAssignment 1 SOLUTIONSubash AdhikariNo ratings yet
- Paper Aasec 2018 - RibangunDocument3 pagesPaper Aasec 2018 - Ribangunirwan wijayantoNo ratings yet
- Data Mining Project DSBA PCA Report FinalDocument21 pagesData Mining Project DSBA PCA Report Finalindraneel120No ratings yet
- Project - Finance and Risk Assessment: Submitted By: Navendu MishraDocument18 pagesProject - Finance and Risk Assessment: Submitted By: Navendu MishraAbhishekNo ratings yet
- Factor Analysis T. RamayahDocument29 pagesFactor Analysis T. RamayahAmir AlazhariyNo ratings yet
- Chap10 SPSSDocument8 pagesChap10 SPSSdrNo ratings yet
- Business Analytics Assignment-SajithaDocument17 pagesBusiness Analytics Assignment-SajithaSajitha NairNo ratings yet
- Q3 W1 An Introduction To Data Processing and Univariate Statistical TreatmentDocument7 pagesQ3 W1 An Introduction To Data Processing and Univariate Statistical Treatmentkaii cutieNo ratings yet
- NSE ProjectDocument11 pagesNSE ProjectShahana FathimaNo ratings yet
- Bharti 2023 BP 6853CDocument17 pagesBharti 2023 BP 6853CmonaranjansharmaNo ratings yet
- Diabetes Classification ReportDocument17 pagesDiabetes Classification Reportmaishop1509No ratings yet
- Business Report: by Sreenath RadhakrishnanDocument26 pagesBusiness Report: by Sreenath RadhakrishnanSonal SinghNo ratings yet
- Project 2 Factor Hair Revised Case StudyDocument25 pagesProject 2 Factor Hair Revised Case StudyrishitNo ratings yet
- Lim Final Revised For JAR Scale PresentationDocument23 pagesLim Final Revised For JAR Scale PresentationAbe LimNo ratings yet
- Yola Tugas Halaman 15Document56 pagesYola Tugas Halaman 15Halimah Dwi YolandaNo ratings yet
- Factor Analysis: Presented By: Gurvinder KaurDocument37 pagesFactor Analysis: Presented By: Gurvinder Kaurgurvinder12No ratings yet
- PE20 XiaoXuanFeng FinalDocument43 pagesPE20 XiaoXuanFeng FinalXiao Xuan FengNo ratings yet
- Data MiningDocument34 pagesData MiningShreyaPrakashNo ratings yet
- Lec 17 - Principal Component Analysis PDFDocument30 pagesLec 17 - Principal Component Analysis PDFmuhammad sami ullah khanNo ratings yet
- Gold Rate PredictionDocument8 pagesGold Rate Predictionreshmakr.learnNo ratings yet
- SIA Romney Ch06Document22 pagesSIA Romney Ch06Dewi SartikaNo ratings yet
- How To Key in Data Into SPSSDocument18 pagesHow To Key in Data Into SPSSnurul aidielaNo ratings yet
- Factor Analysis Introduction: Karak Tea Whitener: The Use of Factor AnalysisDocument9 pagesFactor Analysis Introduction: Karak Tea Whitener: The Use of Factor AnalysisMustafa AsadNo ratings yet
- Fnal+Report Advance+StatisticsDocument44 pagesFnal+Report Advance+StatisticsPranav Viswanathan100% (1)
- Introduction To Data Cleaning and Bias in AnalysisDocument35 pagesIntroduction To Data Cleaning and Bias in AnalysisJunjie GohNo ratings yet
- L11 - Exploring Assumptions of ParametricDocument19 pagesL11 - Exploring Assumptions of ParametricRamesh GNo ratings yet
- Principal Components AnalysisDocument59 pagesPrincipal Components AnalysisIbrar BangashNo ratings yet
- 7.1. Topic 7. Part 1Document36 pages7.1. Topic 7. Part 1Ipek SenNo ratings yet
- Midterm Data MiningDocument18 pagesMidterm Data MiningMai Xuân ĐạtNo ratings yet
- Factor Analysis: Dr. R. RavananDocument22 pagesFactor Analysis: Dr. R. Ravananajay kalangiNo ratings yet
- Restaurant Recommendation1Document5 pagesRestaurant Recommendation1César Leonardo Orosco BarbozaNo ratings yet
- Research MethodologyDocument7 pagesResearch Methodologysteven280893No ratings yet
- FRA Milestone 1Document33 pagesFRA Milestone 1Nitya BalakrishnanNo ratings yet
- Lapse TeamDocument28 pagesLapse TeamLaura StephanieNo ratings yet
- MGMT 2605 - Avacado CaseDocument4 pagesMGMT 2605 - Avacado CaseLiam PankratzNo ratings yet
- Project Report - Data MiningDocument52 pagesProject Report - Data MiningRuhee's KitchenNo ratings yet
- Factor AnalysisDocument47 pagesFactor AnalysisPunit N DenaniNo ratings yet
- Workshop3 Bangert Factor Analysis Tutorial and ExSurvey ItemsDocument13 pagesWorkshop3 Bangert Factor Analysis Tutorial and ExSurvey ItemsSugan PragasamNo ratings yet
- 01 Intro Linier ProgrammingDocument25 pages01 Intro Linier ProgrammingwatriNo ratings yet
- Market Research ToolsDocument24 pagesMarket Research Toolskumarankit007No ratings yet
- A Synopsis For The PBLDocument16 pagesA Synopsis For The PBLkamalNo ratings yet
- MA NotesDocument31 pagesMA NotesSiddharth AroraNo ratings yet
- FRA Milestone 1Document33 pagesFRA Milestone 1Nitya BalakrishnanNo ratings yet
- Consumer and Sensory Evaluation Techniques: How to Sense Successful ProductsFrom EverandConsumer and Sensory Evaluation Techniques: How to Sense Successful ProductsNo ratings yet
- HT TP: //qpa Pe R.W But .Ac .In: Data Compression & CryptographyDocument7 pagesHT TP: //qpa Pe R.W But .Ac .In: Data Compression & CryptographyDuma DumaiNo ratings yet
- A Computational Approach To Holomorphic Dynamics - Kanak DhotreDocument32 pagesA Computational Approach To Holomorphic Dynamics - Kanak DhotreKanak DhotreNo ratings yet
- 동역학12 PDFDocument13 pages동역학12 PDF엄석현No ratings yet
- Lec MatlabDocument110 pagesLec MatlabreprezentNo ratings yet
- Timing Optimization Through Clock Skew Scheduling - Ivan S.kourtev, Baris Taskin, Eby G. FriedmanDocument274 pagesTiming Optimization Through Clock Skew Scheduling - Ivan S.kourtev, Baris Taskin, Eby G. FriedmanAnonymous VG6Zat1o100% (1)
- Aarohi Maths TestDocument4 pagesAarohi Maths TestKratgya GuptaNo ratings yet
- KSSR Mathematics Year 4Document22 pagesKSSR Mathematics Year 4Suganthi SupaiahNo ratings yet
- ACI Structural JournalDocument10 pagesACI Structural JournalAbdifatah HassanNo ratings yet
- Ps As Icse STD 10 Math LocusDocument5 pagesPs As Icse STD 10 Math Locuspravingosavi1011_578No ratings yet
- 2nd Grade Art Lesson OrgDocument6 pages2nd Grade Art Lesson Orgapi-288691585No ratings yet
- Steady-State Optimization Operation of The West-East Gas PipelineDocument15 pagesSteady-State Optimization Operation of The West-East Gas PipelinesamandondonNo ratings yet
- Management Information System MCQ'SDocument16 pagesManagement Information System MCQ'SGuruKPO100% (9)
- G11 - Motion in CircleDocument34 pagesG11 - Motion in CircleNi Luh Divanian Darsana PutriNo ratings yet
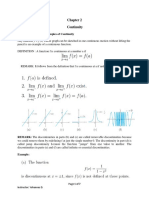
- Continuity: 2.1. Definition and Examples of ContinuityDocument7 pagesContinuity: 2.1. Definition and Examples of ContinuityBelew BelewNo ratings yet
- Rna MaterialDocument147 pagesRna MaterialShivani SaxenaNo ratings yet
- (Springer Series in Materials Science 200) Ilya V. Shadrivov, Mikhail Lapine, Yuri S. Kivshar (Eds.) - Nonlinear, Tunable and Active Metamaterials-Springer International Publishing (2015) PDFDocument333 pages(Springer Series in Materials Science 200) Ilya V. Shadrivov, Mikhail Lapine, Yuri S. Kivshar (Eds.) - Nonlinear, Tunable and Active Metamaterials-Springer International Publishing (2015) PDFDebidas KunduNo ratings yet
- Configuration of Fibers in Staple YarnDocument8 pagesConfiguration of Fibers in Staple YarnTuan Nguyen MinhNo ratings yet
- Manual Book Software GAD Geiger AdaptiveDocument6 pagesManual Book Software GAD Geiger AdaptiveEmi UlfianaNo ratings yet
- 2014wmi Final Us-Q2-1Document4 pages2014wmi Final Us-Q2-1herryhr100% (2)
- 20BCS2334 Jitesh KumarDocument4 pages20BCS2334 Jitesh KumarjiteshkumardjNo ratings yet
- BCOM 3rd and 4th Sem Syallbus NEPDocument37 pagesBCOM 3rd and 4th Sem Syallbus NEPgfgcw yadgirNo ratings yet
- IA PresentationDocument8 pagesIA PresentationLily OweinehNo ratings yet
- A CROSS-CULTURAL STUDY ON WEATHER PROVERBS IN ENGLISH AND VIETNAMESE. Đỗ Thị Minh Ngọc. QHF.1.2006Document110 pagesA CROSS-CULTURAL STUDY ON WEATHER PROVERBS IN ENGLISH AND VIETNAMESE. Đỗ Thị Minh Ngọc. QHF.1.2006Kavic100% (4)
- Series Quesions For IQDocument2 pagesSeries Quesions For IQkanaya khanNo ratings yet
- Quartile DeviationDocument5 pagesQuartile DeviationJoezerk Jhon BielNo ratings yet
- Connectedness Among The Pixels at The Product Digital TopologyDocument6 pagesConnectedness Among The Pixels at The Product Digital TopologyIJRASETPublicationsNo ratings yet
- Slow Learners Practice QuestionsDocument2 pagesSlow Learners Practice QuestionsVarun KarraNo ratings yet