
Stat 211 Trivia
Stat 211 Trivia
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- MPH Entrance Examination With AnswersDocument42 pagesMPH Entrance Examination With Answersahmedhaji_sadik94% (88)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Black Church Leaders Attitudes About Seeking Mental Health Services - Role of Religiosity and SpiritualityDocument12 pagesBlack Church Leaders Attitudes About Seeking Mental Health Services - Role of Religiosity and SpiritualitymizbigspendaNo ratings yet
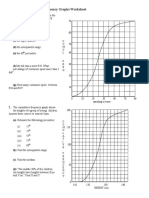
- Cumulative Frequency Graphs WorksheetDocument1 pageCumulative Frequency Graphs WorksheetKOK SHING GANNo ratings yet
- Representation of Data - 1.1.5Document3 pagesRepresentation of Data - 1.1.5KOK SHING GANNo ratings yet
- Representation of Data - 1.1.4Document6 pagesRepresentation of Data - 1.1.4KOK SHING GANNo ratings yet
- Representation of Data - 1.1.2Document5 pagesRepresentation of Data - 1.1.2KOK SHING GANNo ratings yet
- Understanding Your Situational Judgement Test (SJT) Score: SJT As A Measure of Meeting The Person SpecificationDocument3 pagesUnderstanding Your Situational Judgement Test (SJT) Score: SJT As A Measure of Meeting The Person SpecificationPaola AbreuNo ratings yet
- Statistics 110, Lecture Notes - Cedar Crest CollegeDocument111 pagesStatistics 110, Lecture Notes - Cedar Crest CollegeLuis CamachoNo ratings yet
- Practical - 02Document4 pagesPractical - 02pratyakshdewan.duNo ratings yet
- Data Analysis Stats 2Document13 pagesData Analysis Stats 2Sagar GichkiNo ratings yet
- IB - Biology 2009 Syllabus (Almost Complete Set of Notes)Document117 pagesIB - Biology 2009 Syllabus (Almost Complete Set of Notes)Cristen100% (24)
- Tutorial Sheets EsDocument24 pagesTutorial Sheets EsAthinaNo ratings yet
- Asphalt PlantDocument36 pagesAsphalt PlantSinan İcik100% (2)
- 2 - Some AP Practice HWDocument3 pages2 - Some AP Practice HWhshshdhdNo ratings yet
- Xydes Et Al. - Behavioral Characterization Using An AUVDocument12 pagesXydes Et Al. - Behavioral Characterization Using An AUVFadella VilutamaNo ratings yet
- Assessment of The Effects of Smoking and Consuming Gutka (Smokeless Tobacco) On Selected Hematological and Biochemical Parameters: A Study On Healthy Adult Males of Hazaribag, JharkhandDocument7 pagesAssessment of The Effects of Smoking and Consuming Gutka (Smokeless Tobacco) On Selected Hematological and Biochemical Parameters: A Study On Healthy Adult Males of Hazaribag, Jharkhanddhruv6RNo ratings yet
- Ex-Post Evaluations of Demand Forecast Accuracy: A Literature ReviewDocument19 pagesEx-Post Evaluations of Demand Forecast Accuracy: A Literature ReviewYaswitha SadhuNo ratings yet
- Unit 3 Booklet JUNE 2021Document233 pagesUnit 3 Booklet JUNE 2021rohitNo ratings yet
- Basic Statistics Class ActivitiesDocument22 pagesBasic Statistics Class ActivitiesChona ZamoraNo ratings yet
- PFM3063 - Advanced Financial Management Quiz 2 and 3 (Dec 2023)Document5 pagesPFM3063 - Advanced Financial Management Quiz 2 and 3 (Dec 2023)Putri YaniNo ratings yet
- Survey Adjustment NotesDocument7 pagesSurvey Adjustment NotesF1031 Hariz HilmiNo ratings yet
- ENVI Tutorial: Classification MethodsDocument16 pagesENVI Tutorial: Classification MethodsppinedabNo ratings yet
- Sta 2023Document5 pagesSta 2023Chrystelle CharlierNo ratings yet
- Chap 12Document83 pagesChap 12HoNestLiAr100% (1)
- CHAPTER3 StatisticDocument40 pagesCHAPTER3 StatisticKhairul NidzamNo ratings yet
- ECO172Document12 pagesECO172Anonymous oXZZWHmDDCNo ratings yet
- Probability and Statistical MethodDocument4 pagesProbability and Statistical MethodDhana JayanNo ratings yet
- Hypothesis Testing 23.09.2023Document157 pagesHypothesis Testing 23.09.2023Sakshi ChauhanNo ratings yet
- Testing The Difference - T Test ExplainedDocument17 pagesTesting The Difference - T Test ExplainedMary Mae PontillasNo ratings yet
- Pedagogy 1 TromboneDocument16 pagesPedagogy 1 Tromboneapi-425535066No ratings yet
- The Development of Allowable Fatigue Stresses in API RP2A: Parameter (Denoted G) Defining TructuralDocument11 pagesThe Development of Allowable Fatigue Stresses in API RP2A: Parameter (Denoted G) Defining TructuralcmkohNo ratings yet
- Statistics 101. Elementary Statistics Problem Set 2: Semester 1Document2 pagesStatistics 101. Elementary Statistics Problem Set 2: Semester 1BuiHopeNo ratings yet
- Final Examination Puerto Galera National High School - San Isidro ExtensionDocument4 pagesFinal Examination Puerto Galera National High School - San Isidro ExtensionJennifer MagangoNo ratings yet
- The Effects of Symmetrical and Asymmetrical Social Interaction On Children's Logical Inferences - Roazzi & Bryant, 1998Document7 pagesThe Effects of Symmetrical and Asymmetrical Social Interaction On Children's Logical Inferences - Roazzi & Bryant, 1998Antonio RoazziNo ratings yet










































































Download as docx, pdf, or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- MPH Entrance Examination With AnswersDocument42 pagesMPH Entrance Examination With Answersahmedhaji_sadik94% (88)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Black Church Leaders Attitudes About Seeking Mental Health Services - Role of Religiosity and SpiritualityDocument12 pagesBlack Church Leaders Attitudes About Seeking Mental Health Services - Role of Religiosity and SpiritualitymizbigspendaNo ratings yet
- Cumulative Frequency Graphs WorksheetDocument1 pageCumulative Frequency Graphs WorksheetKOK SHING GANNo ratings yet
- Representation of Data - 1.1.5Document3 pagesRepresentation of Data - 1.1.5KOK SHING GANNo ratings yet
- Representation of Data - 1.1.4Document6 pagesRepresentation of Data - 1.1.4KOK SHING GANNo ratings yet
- Representation of Data - 1.1.2Document5 pagesRepresentation of Data - 1.1.2KOK SHING GANNo ratings yet
- Understanding Your Situational Judgement Test (SJT) Score: SJT As A Measure of Meeting The Person SpecificationDocument3 pagesUnderstanding Your Situational Judgement Test (SJT) Score: SJT As A Measure of Meeting The Person SpecificationPaola AbreuNo ratings yet
- Statistics 110, Lecture Notes - Cedar Crest CollegeDocument111 pagesStatistics 110, Lecture Notes - Cedar Crest CollegeLuis CamachoNo ratings yet
- Practical - 02Document4 pagesPractical - 02pratyakshdewan.duNo ratings yet
- Data Analysis Stats 2Document13 pagesData Analysis Stats 2Sagar GichkiNo ratings yet
- IB - Biology 2009 Syllabus (Almost Complete Set of Notes)Document117 pagesIB - Biology 2009 Syllabus (Almost Complete Set of Notes)Cristen100% (24)
- Tutorial Sheets EsDocument24 pagesTutorial Sheets EsAthinaNo ratings yet
- Asphalt PlantDocument36 pagesAsphalt PlantSinan İcik100% (2)
- 2 - Some AP Practice HWDocument3 pages2 - Some AP Practice HWhshshdhdNo ratings yet
- Xydes Et Al. - Behavioral Characterization Using An AUVDocument12 pagesXydes Et Al. - Behavioral Characterization Using An AUVFadella VilutamaNo ratings yet
- Assessment of The Effects of Smoking and Consuming Gutka (Smokeless Tobacco) On Selected Hematological and Biochemical Parameters: A Study On Healthy Adult Males of Hazaribag, JharkhandDocument7 pagesAssessment of The Effects of Smoking and Consuming Gutka (Smokeless Tobacco) On Selected Hematological and Biochemical Parameters: A Study On Healthy Adult Males of Hazaribag, Jharkhanddhruv6RNo ratings yet
- Ex-Post Evaluations of Demand Forecast Accuracy: A Literature ReviewDocument19 pagesEx-Post Evaluations of Demand Forecast Accuracy: A Literature ReviewYaswitha SadhuNo ratings yet
- Unit 3 Booklet JUNE 2021Document233 pagesUnit 3 Booklet JUNE 2021rohitNo ratings yet
- Basic Statistics Class ActivitiesDocument22 pagesBasic Statistics Class ActivitiesChona ZamoraNo ratings yet
- PFM3063 - Advanced Financial Management Quiz 2 and 3 (Dec 2023)Document5 pagesPFM3063 - Advanced Financial Management Quiz 2 and 3 (Dec 2023)Putri YaniNo ratings yet
- Survey Adjustment NotesDocument7 pagesSurvey Adjustment NotesF1031 Hariz HilmiNo ratings yet
- ENVI Tutorial: Classification MethodsDocument16 pagesENVI Tutorial: Classification MethodsppinedabNo ratings yet
- Sta 2023Document5 pagesSta 2023Chrystelle CharlierNo ratings yet
- Chap 12Document83 pagesChap 12HoNestLiAr100% (1)
- CHAPTER3 StatisticDocument40 pagesCHAPTER3 StatisticKhairul NidzamNo ratings yet
- ECO172Document12 pagesECO172Anonymous oXZZWHmDDCNo ratings yet
- Probability and Statistical MethodDocument4 pagesProbability and Statistical MethodDhana JayanNo ratings yet
- Hypothesis Testing 23.09.2023Document157 pagesHypothesis Testing 23.09.2023Sakshi ChauhanNo ratings yet
- Testing The Difference - T Test ExplainedDocument17 pagesTesting The Difference - T Test ExplainedMary Mae PontillasNo ratings yet
- Pedagogy 1 TromboneDocument16 pagesPedagogy 1 Tromboneapi-425535066No ratings yet
- The Development of Allowable Fatigue Stresses in API RP2A: Parameter (Denoted G) Defining TructuralDocument11 pagesThe Development of Allowable Fatigue Stresses in API RP2A: Parameter (Denoted G) Defining TructuralcmkohNo ratings yet
- Statistics 101. Elementary Statistics Problem Set 2: Semester 1Document2 pagesStatistics 101. Elementary Statistics Problem Set 2: Semester 1BuiHopeNo ratings yet
- Final Examination Puerto Galera National High School - San Isidro ExtensionDocument4 pagesFinal Examination Puerto Galera National High School - San Isidro ExtensionJennifer MagangoNo ratings yet
- The Effects of Symmetrical and Asymmetrical Social Interaction On Children's Logical Inferences - Roazzi & Bryant, 1998Document7 pagesThe Effects of Symmetrical and Asymmetrical Social Interaction On Children's Logical Inferences - Roazzi & Bryant, 1998Antonio RoazziNo ratings yet