
3-Recursive Parameter Estimation PDF
3-Recursive Parameter Estimation PDF
You might also like
- KTEA Technical and Interpretive ManualDocument690 pagesKTEA Technical and Interpretive ManualVanity Trimble100% (2)
- Time Series SolutionDocument5 pagesTime Series Solutionbehrooz100% (1)
- Wolter Introduction To Variance Estimation PDF PDF ExpertDocument2 pagesWolter Introduction To Variance Estimation PDF PDF ExpertMarta Rodriguez MartinezNo ratings yet
- Post Tender ClarificationDocument3 pagesPost Tender Clarificationsrsureshrajan100% (1)
- Social Learning Theory BANDURADocument2 pagesSocial Learning Theory BANDURAkejuterbang100% (1)
- Error Analysis ManualDocument11 pagesError Analysis ManualPranay Reddy100% (1)
- 1derivacion 2 Ley GalileoDocument10 pages1derivacion 2 Ley GalileoaeeNo ratings yet
- Exp 1 - Error Anaylysis and Graph Drawing - TheoryDocument9 pagesExp 1 - Error Anaylysis and Graph Drawing - Theoryritik12041998No ratings yet
- ArimaDocument4 pagesArimaSofia Lively100% (1)
- EEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsDocument5 pagesEEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsRedwan AhmedNo ratings yet
- Mean Shift Algo 3Document5 pagesMean Shift Algo 3ninnnnnnimoNo ratings yet
- On The Application of Multi-Parameter Extremum Seeking ControlDocument5 pagesOn The Application of Multi-Parameter Extremum Seeking ControlJoseph JoseNo ratings yet
- PerceptronDocument3 pagesPerceptronapi-3814100No ratings yet
- 1 s2.0 S1474667016418835 MainDocument6 pages1 s2.0 S1474667016418835 MainSamir AhmedNo ratings yet
- Financial Applications of Random MatrixDocument18 pagesFinancial Applications of Random Matrixxi yanNo ratings yet
- Univariate Time Series Modelling and ForecastingDocument72 pagesUnivariate Time Series Modelling and Forecastingjamesburden100% (2)
- Abstract Interpretation With Higher-Dimensional Ellipsoids and Conic ExtrapolationDocument19 pagesAbstract Interpretation With Higher-Dimensional Ellipsoids and Conic ExtrapolationWalter HuNo ratings yet
- Exercise 1 (25 Points) : Econometrics IDocument10 pagesExercise 1 (25 Points) : Econometrics IDaniel MarinhoNo ratings yet
- New Trigonometrically Method For Solving Non-Linear Transcendental EquationsDocument7 pagesNew Trigonometrically Method For Solving Non-Linear Transcendental EquationsIJRASETPublicationsNo ratings yet
- Linear Stationary ModelsDocument16 pagesLinear Stationary ModelsKaled AbodeNo ratings yet
- CET Vol69Document6 pagesCET Vol69minh leNo ratings yet
- Finite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationDocument6 pagesFinite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Integer Autoregressive Models With Structural BreaksDocument18 pagesInteger Autoregressive Models With Structural BreaksAkanksha KashikarNo ratings yet
- Algorithms: An Approach To The Dynamics and Control of Uncertain Robot ManipulatorsDocument11 pagesAlgorithms: An Approach To The Dynamics and Control of Uncertain Robot ManipulatorsVikNo ratings yet
- Using Iterative Linear Regression Model To Time Series Models Zouaoui Chikr-el-Mezouar, Mohamed AttouchDocument14 pagesUsing Iterative Linear Regression Model To Time Series Models Zouaoui Chikr-el-Mezouar, Mohamed AttouchFransiscus DheniNo ratings yet
- Attacks On Elliptic Curve Cryptography Implementations in Sage MathDocument12 pagesAttacks On Elliptic Curve Cryptography Implementations in Sage MathInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Duality Between Initial and Terminal Function Problems: Ukwu ChukwunenyeDocument9 pagesDuality Between Initial and Terminal Function Problems: Ukwu ChukwunenyeinventionjournalsNo ratings yet
- ICNAAM 2021 AIP Proceedings Solving Second-Order IVPs Using An Adaptive OptimizedDocument5 pagesICNAAM 2021 AIP Proceedings Solving Second-Order IVPs Using An Adaptive OptimizedhigraNo ratings yet
- Econometrics Chapter 1 UNAVDocument38 pagesEconometrics Chapter 1 UNAVRachael VazquezNo ratings yet
- Global Exponential Stability of Cohen-Grossberg Neural Networks With Time-Varying Delays and ImpulsesDocument5 pagesGlobal Exponential Stability of Cohen-Grossberg Neural Networks With Time-Varying Delays and ImpulseschanezNo ratings yet
- Balanced Scorecard Simulator - A Tool For Stochast PDFDocument8 pagesBalanced Scorecard Simulator - A Tool For Stochast PDFHadi P.No ratings yet
- 1 s2.0 S0022247X24002105 MainDocument17 pages1 s2.0 S0022247X24002105 Mainmosab.backkupNo ratings yet
- Sung2011 Article RobustObserver-basedFuzzyContrDocument8 pagesSung2011 Article RobustObserver-basedFuzzyContrMohammed BenNo ratings yet
- Particle Filter ArticleDocument18 pagesParticle Filter ArticleAndrés CeverisaeNo ratings yet
- Identification and Estimation (Empirical Models) : D T U G T yDocument11 pagesIdentification and Estimation (Empirical Models) : D T U G T yAnonymous JDXbBDBNo ratings yet
- HW 1Document8 pagesHW 1Mahmudul HasanNo ratings yet
- 3 - Control Strategies For Servo Drives - Rev 30-03-2021Document10 pages3 - Control Strategies For Servo Drives - Rev 30-03-2021Euge GalardiNo ratings yet
- Neural Network Time SeriesDocument42 pagesNeural Network Time SeriesboynaduaNo ratings yet
- Data-Based Approach To Feedback-Feedforward Controller Design From Closed-Loop Plant DataDocument6 pagesData-Based Approach To Feedback-Feedforward Controller Design From Closed-Loop Plant DataArif HidayatNo ratings yet
- EstimationDocument16 pagesEstimationfatihaNo ratings yet
- Time Series Lecture Notes-Ch-5Document27 pagesTime Series Lecture Notes-Ch-5yonasante2121No ratings yet
- The Kaplan-Meier Estimate of The Survival FunctionDocument23 pagesThe Kaplan-Meier Estimate of The Survival Functionrodicasept1967No ratings yet
- Model-Free Offline Change-Point Detection Multidimensional Time Series of Arbitrary Nature Via ?-Complexity Simulations and ApplicationsDocument13 pagesModel-Free Offline Change-Point Detection Multidimensional Time Series of Arbitrary Nature Via ?-Complexity Simulations and ApplicationsWong Chiong LiongNo ratings yet
- IASTED Vid Ach Poz SendedForPeerReviewDocument4 pagesIASTED Vid Ach Poz SendedForPeerReviewyolanda.vidalNo ratings yet
- Fast Algorithm For Walsh Hadamard Transform On Sliding WindowsDocument17 pagesFast Algorithm For Walsh Hadamard Transform On Sliding WindowslgaleanocNo ratings yet
- Chap 6Document40 pagesChap 6pranjal meshramNo ratings yet
- Dupiere Discrete ModelDocument14 pagesDupiere Discrete Modelabhiu1991No ratings yet
- Calc 2 Lecture Notes Section 7.2 1 of 8: Yx UxvyDocument8 pagesCalc 2 Lecture Notes Section 7.2 1 of 8: Yx Uxvymasyuki1979No ratings yet
- Modelling and Identification of A Non-Linear Saturated Magnetic Circuit: Theoretical Study and Experimental ResultsDocument14 pagesModelling and Identification of A Non-Linear Saturated Magnetic Circuit: Theoretical Study and Experimental ResultsGustavo LimaNo ratings yet
- Mo 2010Document9 pagesMo 2010ranim najibNo ratings yet
- Introduction To Reliability Theory (Part 2) : Frank CoolenDocument21 pagesIntroduction To Reliability Theory (Part 2) : Frank CoolenRuth SandalaNo ratings yet
- 1 s2.0 S1474667016322078 MainDocument6 pages1 s2.0 S1474667016322078 MainSamir AhmedNo ratings yet
- KDV 3Document23 pagesKDV 3manoj27No ratings yet
- Lecture 01 - Review of FundamentalsDocument6 pagesLecture 01 - Review of FundamentalsCaden LeeNo ratings yet
- Automatic Control III Homework Assignment 3 2015Document4 pagesAutomatic Control III Homework Assignment 3 2015salimNo ratings yet
- Plugin v6 2 11 PDFDocument7 pagesPlugin v6 2 11 PDFesutjiadiNo ratings yet
- The Structure of Determining Matrices For Single-Delay Autonomous Linear Neutral Control SystemsDocument17 pagesThe Structure of Determining Matrices For Single-Delay Autonomous Linear Neutral Control SystemsinventionjournalsNo ratings yet
- Toward A Coherent Monte Carlo Simulation of CVA: Lokman Abbas-Turki, Ayech Bouselmi, Mohammed MikouDocument28 pagesToward A Coherent Monte Carlo Simulation of CVA: Lokman Abbas-Turki, Ayech Bouselmi, Mohammed Mikoutracy powellNo ratings yet
- SmoothingDocument9 pagesSmoothingmimiNo ratings yet
- Radar and AIS Data Fusion For The Needs of The Maritime NavigationDocument4 pagesRadar and AIS Data Fusion For The Needs of The Maritime NavigationRendy AnggaraNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- CIGRÉ 2008 - Corrosive Sulfur in FR3Document8 pagesCIGRÉ 2008 - Corrosive Sulfur in FR3Felipe VargasNo ratings yet
- Educational Management: Anisa Kusuma Wahdati, Achmad Slamet, Noor HudallahDocument9 pagesEducational Management: Anisa Kusuma Wahdati, Achmad Slamet, Noor HudallahNinda Dae PanieNo ratings yet
- Problem Based Learning - Assignment 1Document2 pagesProblem Based Learning - Assignment 1api-315325618No ratings yet
- Análisis de SupervivenciaDocument441 pagesAnálisis de Supervivenciamelimeli106100% (1)
- Data CollectionDocument15 pagesData CollectionElena Beleska100% (1)
- TPDocument16 pagesTPandrewNo ratings yet
- The International Journal of Nuclear Safeguards and Non-ProliferationDocument58 pagesThe International Journal of Nuclear Safeguards and Non-Proliferationtjnevado1No ratings yet
- Philosophy, Culture, and Traditions, Vol 5Document192 pagesPhilosophy, Culture, and Traditions, Vol 5dr_william_sweetNo ratings yet
- Considerations For Business and Risk Managers During The Coronavirus/Covid19 OutbreakDocument19 pagesConsiderations For Business and Risk Managers During The Coronavirus/Covid19 OutbreakChristine MagnayeNo ratings yet
- Conclusion ReportDocument2 pagesConclusion ReportKimNanamiNo ratings yet
- Data Mining: Support Vector Machines Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument12 pagesData Mining: Support Vector Machines Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarYosua SiregarNo ratings yet
- Assessment Tool - Javels BakeryDocument3 pagesAssessment Tool - Javels BakeryAmir VillasNo ratings yet
- (125020218113012) Pengaruh Gaya KepemimpinanTerhadap Disiplin Kerja Anggota Pada POLRES Kediri KotaDocument136 pages(125020218113012) Pengaruh Gaya KepemimpinanTerhadap Disiplin Kerja Anggota Pada POLRES Kediri KotakingsaktiNo ratings yet
- MODULE 2 Measures of Central TendencyDocument8 pagesMODULE 2 Measures of Central TendencyShijiThomasNo ratings yet
- Under Graduat Research TemplatesDocument20 pagesUnder Graduat Research TemplatesKimberly Faura ManlutacNo ratings yet
- EDITED RESEARCH For PublicationDocument11 pagesEDITED RESEARCH For PublicationRICHEL MANGMANGNo ratings yet
- Property Price Prediction Capstone ProjectDocument7 pagesProperty Price Prediction Capstone ProjectAashutosh PandeyNo ratings yet
- Answer All Questions in This Section.: KL SMK Methodist Mathst P1 2015 QaDocument6 pagesAnswer All Questions in This Section.: KL SMK Methodist Mathst P1 2015 QaPeng Peng KekNo ratings yet
- Kasahun New Re Final TO BE PRINTTEDDocument41 pagesKasahun New Re Final TO BE PRINTTEDbahailuNo ratings yet
- Evaluasi Penggunaan Aplikasi Sim-Rs Menggunakan Metode Hot-FitDocument12 pagesEvaluasi Penggunaan Aplikasi Sim-Rs Menggunakan Metode Hot-FitEl-walid 'To' BlaugranaNo ratings yet
- DI - HC Trends 2019 PDFDocument112 pagesDI - HC Trends 2019 PDFClaudia RNo ratings yet
- Unit-Iii: Statistical Estimation Theory Unbiased EstimatesDocument14 pagesUnit-Iii: Statistical Estimation Theory Unbiased EstimatesViru BadbeNo ratings yet
- Architecture Students' Perceptions of Design and Its Transformations Throughout Their EducationDocument96 pagesArchitecture Students' Perceptions of Design and Its Transformations Throughout Their EducationClarisse DoriaNo ratings yet
- Materials Today: Proceedings: Jahnavi Nandish, Jogi Mathew, Rinju GeorgeDocument5 pagesMaterials Today: Proceedings: Jahnavi Nandish, Jogi Mathew, Rinju GeorgeManuela Ospina RiveiraNo ratings yet
- Dirrectory of Appropriate Tech InstitutionsDocument40 pagesDirrectory of Appropriate Tech InstitutionspitufitoNo ratings yet
- MMMMBMBDocument1 pageMMMMBMBanothersomeguyNo ratings yet
- Validity and Reliability of The VO2 Master Pro For Oxygen Consumption andDocument20 pagesValidity and Reliability of The VO2 Master Pro For Oxygen Consumption andnorazmiNo ratings yet









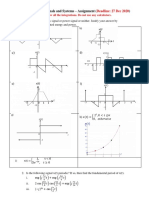

























































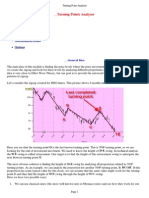





















Download as pdf or txt
You might also like
- KTEA Technical and Interpretive ManualDocument690 pagesKTEA Technical and Interpretive ManualVanity Trimble100% (2)
- Time Series SolutionDocument5 pagesTime Series Solutionbehrooz100% (1)
- Wolter Introduction To Variance Estimation PDF PDF ExpertDocument2 pagesWolter Introduction To Variance Estimation PDF PDF ExpertMarta Rodriguez MartinezNo ratings yet
- Post Tender ClarificationDocument3 pagesPost Tender Clarificationsrsureshrajan100% (1)
- Social Learning Theory BANDURADocument2 pagesSocial Learning Theory BANDURAkejuterbang100% (1)
- Error Analysis ManualDocument11 pagesError Analysis ManualPranay Reddy100% (1)
- 1derivacion 2 Ley GalileoDocument10 pages1derivacion 2 Ley GalileoaeeNo ratings yet
- Exp 1 - Error Anaylysis and Graph Drawing - TheoryDocument9 pagesExp 1 - Error Anaylysis and Graph Drawing - Theoryritik12041998No ratings yet
- ArimaDocument4 pagesArimaSofia Lively100% (1)
- EEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsDocument5 pagesEEE243/ECE243 Signals and Systems - Assignment : Please Show All The Integrations. Do Not Use Any CalculatorsRedwan AhmedNo ratings yet
- Mean Shift Algo 3Document5 pagesMean Shift Algo 3ninnnnnnimoNo ratings yet
- On The Application of Multi-Parameter Extremum Seeking ControlDocument5 pagesOn The Application of Multi-Parameter Extremum Seeking ControlJoseph JoseNo ratings yet
- PerceptronDocument3 pagesPerceptronapi-3814100No ratings yet
- 1 s2.0 S1474667016418835 MainDocument6 pages1 s2.0 S1474667016418835 MainSamir AhmedNo ratings yet
- Financial Applications of Random MatrixDocument18 pagesFinancial Applications of Random Matrixxi yanNo ratings yet
- Univariate Time Series Modelling and ForecastingDocument72 pagesUnivariate Time Series Modelling and Forecastingjamesburden100% (2)
- Abstract Interpretation With Higher-Dimensional Ellipsoids and Conic ExtrapolationDocument19 pagesAbstract Interpretation With Higher-Dimensional Ellipsoids and Conic ExtrapolationWalter HuNo ratings yet
- Exercise 1 (25 Points) : Econometrics IDocument10 pagesExercise 1 (25 Points) : Econometrics IDaniel MarinhoNo ratings yet
- New Trigonometrically Method For Solving Non-Linear Transcendental EquationsDocument7 pagesNew Trigonometrically Method For Solving Non-Linear Transcendental EquationsIJRASETPublicationsNo ratings yet
- Linear Stationary ModelsDocument16 pagesLinear Stationary ModelsKaled AbodeNo ratings yet
- CET Vol69Document6 pagesCET Vol69minh leNo ratings yet
- Finite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationDocument6 pagesFinite and Infinite Generalized Back Ward Q-Derivative Operator On Its ApplicationInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Integer Autoregressive Models With Structural BreaksDocument18 pagesInteger Autoregressive Models With Structural BreaksAkanksha KashikarNo ratings yet
- Algorithms: An Approach To The Dynamics and Control of Uncertain Robot ManipulatorsDocument11 pagesAlgorithms: An Approach To The Dynamics and Control of Uncertain Robot ManipulatorsVikNo ratings yet
- Using Iterative Linear Regression Model To Time Series Models Zouaoui Chikr-el-Mezouar, Mohamed AttouchDocument14 pagesUsing Iterative Linear Regression Model To Time Series Models Zouaoui Chikr-el-Mezouar, Mohamed AttouchFransiscus DheniNo ratings yet
- Attacks On Elliptic Curve Cryptography Implementations in Sage MathDocument12 pagesAttacks On Elliptic Curve Cryptography Implementations in Sage MathInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Duality Between Initial and Terminal Function Problems: Ukwu ChukwunenyeDocument9 pagesDuality Between Initial and Terminal Function Problems: Ukwu ChukwunenyeinventionjournalsNo ratings yet
- ICNAAM 2021 AIP Proceedings Solving Second-Order IVPs Using An Adaptive OptimizedDocument5 pagesICNAAM 2021 AIP Proceedings Solving Second-Order IVPs Using An Adaptive OptimizedhigraNo ratings yet
- Econometrics Chapter 1 UNAVDocument38 pagesEconometrics Chapter 1 UNAVRachael VazquezNo ratings yet
- Global Exponential Stability of Cohen-Grossberg Neural Networks With Time-Varying Delays and ImpulsesDocument5 pagesGlobal Exponential Stability of Cohen-Grossberg Neural Networks With Time-Varying Delays and ImpulseschanezNo ratings yet
- Balanced Scorecard Simulator - A Tool For Stochast PDFDocument8 pagesBalanced Scorecard Simulator - A Tool For Stochast PDFHadi P.No ratings yet
- 1 s2.0 S0022247X24002105 MainDocument17 pages1 s2.0 S0022247X24002105 Mainmosab.backkupNo ratings yet
- Sung2011 Article RobustObserver-basedFuzzyContrDocument8 pagesSung2011 Article RobustObserver-basedFuzzyContrMohammed BenNo ratings yet
- Particle Filter ArticleDocument18 pagesParticle Filter ArticleAndrés CeverisaeNo ratings yet
- Identification and Estimation (Empirical Models) : D T U G T yDocument11 pagesIdentification and Estimation (Empirical Models) : D T U G T yAnonymous JDXbBDBNo ratings yet
- HW 1Document8 pagesHW 1Mahmudul HasanNo ratings yet
- 3 - Control Strategies For Servo Drives - Rev 30-03-2021Document10 pages3 - Control Strategies For Servo Drives - Rev 30-03-2021Euge GalardiNo ratings yet
- Neural Network Time SeriesDocument42 pagesNeural Network Time SeriesboynaduaNo ratings yet
- Data-Based Approach To Feedback-Feedforward Controller Design From Closed-Loop Plant DataDocument6 pagesData-Based Approach To Feedback-Feedforward Controller Design From Closed-Loop Plant DataArif HidayatNo ratings yet
- EstimationDocument16 pagesEstimationfatihaNo ratings yet
- Time Series Lecture Notes-Ch-5Document27 pagesTime Series Lecture Notes-Ch-5yonasante2121No ratings yet
- The Kaplan-Meier Estimate of The Survival FunctionDocument23 pagesThe Kaplan-Meier Estimate of The Survival Functionrodicasept1967No ratings yet
- Model-Free Offline Change-Point Detection Multidimensional Time Series of Arbitrary Nature Via ?-Complexity Simulations and ApplicationsDocument13 pagesModel-Free Offline Change-Point Detection Multidimensional Time Series of Arbitrary Nature Via ?-Complexity Simulations and ApplicationsWong Chiong LiongNo ratings yet
- IASTED Vid Ach Poz SendedForPeerReviewDocument4 pagesIASTED Vid Ach Poz SendedForPeerReviewyolanda.vidalNo ratings yet
- Fast Algorithm For Walsh Hadamard Transform On Sliding WindowsDocument17 pagesFast Algorithm For Walsh Hadamard Transform On Sliding WindowslgaleanocNo ratings yet
- Chap 6Document40 pagesChap 6pranjal meshramNo ratings yet
- Dupiere Discrete ModelDocument14 pagesDupiere Discrete Modelabhiu1991No ratings yet
- Calc 2 Lecture Notes Section 7.2 1 of 8: Yx UxvyDocument8 pagesCalc 2 Lecture Notes Section 7.2 1 of 8: Yx Uxvymasyuki1979No ratings yet
- Modelling and Identification of A Non-Linear Saturated Magnetic Circuit: Theoretical Study and Experimental ResultsDocument14 pagesModelling and Identification of A Non-Linear Saturated Magnetic Circuit: Theoretical Study and Experimental ResultsGustavo LimaNo ratings yet
- Mo 2010Document9 pagesMo 2010ranim najibNo ratings yet
- Introduction To Reliability Theory (Part 2) : Frank CoolenDocument21 pagesIntroduction To Reliability Theory (Part 2) : Frank CoolenRuth SandalaNo ratings yet
- 1 s2.0 S1474667016322078 MainDocument6 pages1 s2.0 S1474667016322078 MainSamir AhmedNo ratings yet
- KDV 3Document23 pagesKDV 3manoj27No ratings yet
- Lecture 01 - Review of FundamentalsDocument6 pagesLecture 01 - Review of FundamentalsCaden LeeNo ratings yet
- Automatic Control III Homework Assignment 3 2015Document4 pagesAutomatic Control III Homework Assignment 3 2015salimNo ratings yet
- Plugin v6 2 11 PDFDocument7 pagesPlugin v6 2 11 PDFesutjiadiNo ratings yet
- The Structure of Determining Matrices For Single-Delay Autonomous Linear Neutral Control SystemsDocument17 pagesThe Structure of Determining Matrices For Single-Delay Autonomous Linear Neutral Control SystemsinventionjournalsNo ratings yet
- Toward A Coherent Monte Carlo Simulation of CVA: Lokman Abbas-Turki, Ayech Bouselmi, Mohammed MikouDocument28 pagesToward A Coherent Monte Carlo Simulation of CVA: Lokman Abbas-Turki, Ayech Bouselmi, Mohammed Mikoutracy powellNo ratings yet
- SmoothingDocument9 pagesSmoothingmimiNo ratings yet
- Radar and AIS Data Fusion For The Needs of The Maritime NavigationDocument4 pagesRadar and AIS Data Fusion For The Needs of The Maritime NavigationRendy AnggaraNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- The Spectral Theory of Toeplitz Operators. (AM-99), Volume 99From EverandThe Spectral Theory of Toeplitz Operators. (AM-99), Volume 99No ratings yet
- Radically Elementary Probability Theory. (AM-117), Volume 117From EverandRadically Elementary Probability Theory. (AM-117), Volume 117Rating: 4 out of 5 stars4/5 (2)
- CIGRÉ 2008 - Corrosive Sulfur in FR3Document8 pagesCIGRÉ 2008 - Corrosive Sulfur in FR3Felipe VargasNo ratings yet
- Educational Management: Anisa Kusuma Wahdati, Achmad Slamet, Noor HudallahDocument9 pagesEducational Management: Anisa Kusuma Wahdati, Achmad Slamet, Noor HudallahNinda Dae PanieNo ratings yet
- Problem Based Learning - Assignment 1Document2 pagesProblem Based Learning - Assignment 1api-315325618No ratings yet
- Análisis de SupervivenciaDocument441 pagesAnálisis de Supervivenciamelimeli106100% (1)
- Data CollectionDocument15 pagesData CollectionElena Beleska100% (1)
- TPDocument16 pagesTPandrewNo ratings yet
- The International Journal of Nuclear Safeguards and Non-ProliferationDocument58 pagesThe International Journal of Nuclear Safeguards and Non-Proliferationtjnevado1No ratings yet
- Philosophy, Culture, and Traditions, Vol 5Document192 pagesPhilosophy, Culture, and Traditions, Vol 5dr_william_sweetNo ratings yet
- Considerations For Business and Risk Managers During The Coronavirus/Covid19 OutbreakDocument19 pagesConsiderations For Business and Risk Managers During The Coronavirus/Covid19 OutbreakChristine MagnayeNo ratings yet
- Conclusion ReportDocument2 pagesConclusion ReportKimNanamiNo ratings yet
- Data Mining: Support Vector Machines Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument12 pagesData Mining: Support Vector Machines Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarYosua SiregarNo ratings yet
- Assessment Tool - Javels BakeryDocument3 pagesAssessment Tool - Javels BakeryAmir VillasNo ratings yet
- (125020218113012) Pengaruh Gaya KepemimpinanTerhadap Disiplin Kerja Anggota Pada POLRES Kediri KotaDocument136 pages(125020218113012) Pengaruh Gaya KepemimpinanTerhadap Disiplin Kerja Anggota Pada POLRES Kediri KotakingsaktiNo ratings yet
- MODULE 2 Measures of Central TendencyDocument8 pagesMODULE 2 Measures of Central TendencyShijiThomasNo ratings yet
- Under Graduat Research TemplatesDocument20 pagesUnder Graduat Research TemplatesKimberly Faura ManlutacNo ratings yet
- EDITED RESEARCH For PublicationDocument11 pagesEDITED RESEARCH For PublicationRICHEL MANGMANGNo ratings yet
- Property Price Prediction Capstone ProjectDocument7 pagesProperty Price Prediction Capstone ProjectAashutosh PandeyNo ratings yet
- Answer All Questions in This Section.: KL SMK Methodist Mathst P1 2015 QaDocument6 pagesAnswer All Questions in This Section.: KL SMK Methodist Mathst P1 2015 QaPeng Peng KekNo ratings yet
- Kasahun New Re Final TO BE PRINTTEDDocument41 pagesKasahun New Re Final TO BE PRINTTEDbahailuNo ratings yet
- Evaluasi Penggunaan Aplikasi Sim-Rs Menggunakan Metode Hot-FitDocument12 pagesEvaluasi Penggunaan Aplikasi Sim-Rs Menggunakan Metode Hot-FitEl-walid 'To' BlaugranaNo ratings yet
- DI - HC Trends 2019 PDFDocument112 pagesDI - HC Trends 2019 PDFClaudia RNo ratings yet
- Unit-Iii: Statistical Estimation Theory Unbiased EstimatesDocument14 pagesUnit-Iii: Statistical Estimation Theory Unbiased EstimatesViru BadbeNo ratings yet
- Architecture Students' Perceptions of Design and Its Transformations Throughout Their EducationDocument96 pagesArchitecture Students' Perceptions of Design and Its Transformations Throughout Their EducationClarisse DoriaNo ratings yet
- Materials Today: Proceedings: Jahnavi Nandish, Jogi Mathew, Rinju GeorgeDocument5 pagesMaterials Today: Proceedings: Jahnavi Nandish, Jogi Mathew, Rinju GeorgeManuela Ospina RiveiraNo ratings yet
- Dirrectory of Appropriate Tech InstitutionsDocument40 pagesDirrectory of Appropriate Tech InstitutionspitufitoNo ratings yet
- MMMMBMBDocument1 pageMMMMBMBanothersomeguyNo ratings yet
- Validity and Reliability of The VO2 Master Pro For Oxygen Consumption andDocument20 pagesValidity and Reliability of The VO2 Master Pro For Oxygen Consumption andnorazmiNo ratings yet