Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- MIT6 041SCF13 Assn01Document3 pagesMIT6 041SCF13 Assn01slow danceNo ratings yet
- Frac l09 XfemDocument58 pagesFrac l09 Xfemchingon987No ratings yet
- Lecture Notes - Recurrent Neural NetworksDocument11 pagesLecture Notes - Recurrent Neural NetworksBhavin PanchalNo ratings yet
- Kat Level - Ii Syllabus19-20Document1 pageKat Level - Ii Syllabus19-20Bhavin PanchalNo ratings yet
- Patanjali Assignment - BHPDocument2 pagesPatanjali Assignment - BHPBhavin PanchalNo ratings yet
- My Learning Diary 18-June 2017 BPPDocument1 pageMy Learning Diary 18-June 2017 BPPBhavin PanchalNo ratings yet
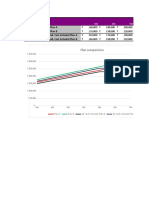
- Scenario Summary: Plan ComparisionDocument5 pagesScenario Summary: Plan ComparisionBhavin PanchalNo ratings yet
- SM 025 - Integration SoalanDocument9 pagesSM 025 - Integration SoalansharuNo ratings yet
- Automatic Control Systems I e LearningDocument9 pagesAutomatic Control Systems I e LearningAlfred K ChilufyaNo ratings yet
- 2017 Fall ME501 06 VectorCalculusDocument95 pages2017 Fall ME501 06 VectorCalculusAfaq AhmedNo ratings yet
- The Saw FunctionDocument4 pagesThe Saw FunctionAleksandar CiricNo ratings yet
- Complex FunctionsDocument102 pagesComplex FunctionsRajesh100% (1)
- Arbaminch University: Collage of Natural SicenceDocument7 pagesArbaminch University: Collage of Natural Sicencebereket simonNo ratings yet
- Warm Up Lesson Presentation Lesson QuizDocument34 pagesWarm Up Lesson Presentation Lesson QuizLaundryhouseby MercyNo ratings yet
- Exam of Discrete Event Systems - 29.04.2013Document2 pagesExam of Discrete Event Systems - 29.04.2013shah4190No ratings yet
- Complex AlgebraDocument8 pagesComplex Algebramahek19579328100% (1)
- Lesson Proper - Module 5: Definite IntegralDocument25 pagesLesson Proper - Module 5: Definite IntegralJack NapierNo ratings yet
- Actividad en Clase 24 - MA2009-2, Spring 2020 - WebAssignDocument8 pagesActividad en Clase 24 - MA2009-2, Spring 2020 - WebAssignDanielMalpicaCuevasNo ratings yet
- Lesson 3.1 - Integration by PartsDocument27 pagesLesson 3.1 - Integration by PartsChristine TenorioNo ratings yet
- CE 579 Lecture 2 Stability-DesignDocument17 pagesCE 579 Lecture 2 Stability-DesignbsitlerNo ratings yet
- Process Capability Study 1500Document6 pagesProcess Capability Study 1500Siddhesh ManeNo ratings yet
- Algorithms: Complexity of Recursive AlgorithmsDocument14 pagesAlgorithms: Complexity of Recursive AlgorithmsNikhil SamantNo ratings yet
- MIT15 053S13 Lec12 PDFDocument60 pagesMIT15 053S13 Lec12 PDFShashank SinglaNo ratings yet
- PSUnit I Lesson 4 Computing The Variance of A Discrete Probability DistributionDocument24 pagesPSUnit I Lesson 4 Computing The Variance of A Discrete Probability DistributionJaneth Marcelino50% (2)
- Chapter 2 (Differentiation)Document47 pagesChapter 2 (Differentiation)Lu Xin XuanNo ratings yet
- 19fall2400syllabus 0508Document3 pages19fall2400syllabus 0508Brendon RseenbumeNo ratings yet
- 3is Q4 Week 1 Module 6Document27 pages3is Q4 Week 1 Module 6yanyanoligo0902No ratings yet
- STATS 200: Introduction To Statistical Inference: Lecture 1: Course Introduction and PollingDocument35 pagesSTATS 200: Introduction To Statistical Inference: Lecture 1: Course Introduction and PollingJovan SsenkandwaNo ratings yet
- C 1224Document2 pagesC 1224SuryoNo ratings yet
- G EngcoursesDocument61 pagesG EngcourseskractheworldNo ratings yet
- Diff Equ1718 Sem 1Document9 pagesDiff Equ1718 Sem 1Rosman IshakNo ratings yet
- Add Maths Year 10Document18 pagesAdd Maths Year 10Yenny TigaNo ratings yet
- Pitri TTG TpackDocument11 pagesPitri TTG TpackWahyudha TriNo ratings yet
- S R K Iyengar, R K Jain Numerical PDFDocument328 pagesS R K Iyengar, R K Jain Numerical PDFJaishuNo ratings yet
- Acid-Base TitrationsDocument27 pagesAcid-Base TitrationsNick RubioNo ratings yet