Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5820)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Practical Signal PDFDocument486 pagesPractical Signal PDFSakthivel Ganesan100% (3)
- LogisticsDocument13 pagesLogisticsKiyan RoyNo ratings yet
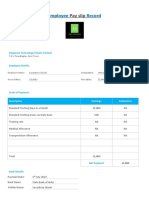
- Employee PaySlip RecordDocument2 pagesEmployee PaySlip RecordKiyan RoyNo ratings yet
- hw3 SolDocument14 pageshw3 SolKiyan RoyNo ratings yet
- PP 03 SolnDocument13 pagesPP 03 SolnKiyan RoyNo ratings yet
- PracticeDocument77 pagesPracticeKiyan RoyNo ratings yet
- Digital Marketing Checklist 2018 PDFDocument1 pageDigital Marketing Checklist 2018 PDFKiyan RoyNo ratings yet
- Free SEO Audit ReportDocument8 pagesFree SEO Audit ReportKiyan RoyNo ratings yet
- Marketing AssignmentDocument18 pagesMarketing AssignmentKiyan RoyNo ratings yet
- MGT301 Assessment 1 and Marking CriteriaDocument2 pagesMGT301 Assessment 1 and Marking CriteriaKiyan RoyNo ratings yet
- Sets RelationsDocument8 pagesSets RelationsMir Musaib NabiNo ratings yet
- Maximum Clique ProblemDocument28 pagesMaximum Clique ProblemJohnson CordeiroNo ratings yet
- The Educational Use of WhatsAppDocument15 pagesThe Educational Use of WhatsAppSabinaNo ratings yet
- Worksheet 3 Math Class 7Document4 pagesWorksheet 3 Math Class 7aftabNo ratings yet
- CVEN 2401 Workshop Wk4 SolutionsDocument6 pagesCVEN 2401 Workshop Wk4 SolutionsMichael BoutsalisNo ratings yet
- Latihan AlgebraDocument4 pagesLatihan AlgebraNicholas LauNo ratings yet
- Isometric DrawingsDocument27 pagesIsometric DrawingsMichael Martinez100% (1)
- 2023 CMI MSC Data Science Mock TestDocument10 pages2023 CMI MSC Data Science Mock TestPriti PramanickNo ratings yet
- Sciography by Radi PuckettDocument112 pagesSciography by Radi PuckettRitesBera100% (1)
- Question Paper Code: 3098: B.A./B.Sc. (Part-III) Examination, 2018Document4 pagesQuestion Paper Code: 3098: B.A./B.Sc. (Part-III) Examination, 2018ShivamNo ratings yet
- Weave Damage V 5Document37 pagesWeave Damage V 5eric654256No ratings yet
- LnglesDocument10 pagesLnglesAdrihanaPaladinesNo ratings yet
- CH 04Document126 pagesCH 04Tommy CunninghamNo ratings yet
- Year 8 Autumn Foundation ADocument20 pagesYear 8 Autumn Foundation AspamiplviewNo ratings yet
- LC42 45a 1 9Document8 pagesLC42 45a 1 9Joan B. BascoNo ratings yet
- Exam ReviewDocument10 pagesExam ReviewWilson ZhangNo ratings yet
- MMW Sample OBE Syllabus RevisedDocument9 pagesMMW Sample OBE Syllabus Revisedkim aeongNo ratings yet
- ULO 1d (Differentiation of Algebraic Functions)Document6 pagesULO 1d (Differentiation of Algebraic Functions)Ellen Mae PensonaNo ratings yet
- Solutionstoselectedexercises: I "11-Awodey-Sol" - 2010/2/19 - 7:30 - Page 279 - #1 I IDocument24 pagesSolutionstoselectedexercises: I "11-Awodey-Sol" - 2010/2/19 - 7:30 - Page 279 - #1 I IlopezmegoNo ratings yet
- 3 1 Yr 7 Fractions TestDocument5 pages3 1 Yr 7 Fractions Testapi-374589174No ratings yet
- Architectural GeometryDocument22 pagesArchitectural GeometryazteckNo ratings yet
- Scan 12 Feb 2024 Scan Feb 55Document17 pagesScan 12 Feb 2024 Scan Feb 55viditganna3434No ratings yet
- Grade 4 Unit 3 Tool 1Document3 pagesGrade 4 Unit 3 Tool 1api-448651856No ratings yet
- SS Notes - VMTWDocument67 pagesSS Notes - VMTWNarendra GaliNo ratings yet
- McFarland - A Standard Kinematic Model For Flight Simulation at NASA-Ames - NASA CR 2497Document53 pagesMcFarland - A Standard Kinematic Model For Flight Simulation at NASA-Ames - NASA CR 2497x-loganNo ratings yet
- Uok PetroleumDocument1 pageUok PetroleumAvericl H n v ejkeNo ratings yet
- Cayle y Hamilton SystemsDocument15 pagesCayle y Hamilton SystemsPrantik Adhar SamantaNo ratings yet
- Forced Convection Over A Flat Plate by Finite Difference MethodDocument5 pagesForced Convection Over A Flat Plate by Finite Difference MethodNihanth WagmiNo ratings yet
- Lic Aao Sbi Po Simplification Approximation Questions - PDF 42Document12 pagesLic Aao Sbi Po Simplification Approximation Questions - PDF 42KomalNo ratings yet