Download as pdf or txt
You might also like
- Issue Trees - The Definitive Guide (+in-Depth Examples) - Crafting CasesDocument147 pagesIssue Trees - The Definitive Guide (+in-Depth Examples) - Crafting CasesShubham Shah100% (1)
- Mastering With Ros: Turlebot3: How To Use Opencv in RosDocument21 pagesMastering With Ros: Turlebot3: How To Use Opencv in RosHusam Abu ZourNo ratings yet
- The Ultimate Barcode Detection GuideDocument33 pagesThe Ultimate Barcode Detection GuiderbermedoNo ratings yet
- Python Face Detection & Opencv Examples Mini-Guide: Face Recognition With Python, in Under 25 Lines of CodeDocument11 pagesPython Face Detection & Opencv Examples Mini-Guide: Face Recognition With Python, in Under 25 Lines of CodeNanduNo ratings yet
- 1.1 Loading Displaying and Saving ImagesDocument5 pages1.1 Loading Displaying and Saving Imagesraslenziadi2k21No ratings yet
- Cartoonify An Image With OpenCV in PythonDocument13 pagesCartoonify An Image With OpenCV in PythonPriyam Singha RoyNo ratings yet
- Panorama StitchingDocument15 pagesPanorama StitchingKedia Rahul100% (1)
- Detecting Malaria With Deep Learning For BeginnersDocument19 pagesDetecting Malaria With Deep Learning For BeginnersSeddik KhamousNo ratings yet
- Raspberry Pi Computer Vision Programming - Sample ChapterDocument23 pagesRaspberry Pi Computer Vision Programming - Sample ChapterPackt Publishing100% (1)
- Vanishing Point: Image Processing - Opencv, Python & C++ By: Rahul KediaDocument19 pagesVanishing Point: Image Processing - Opencv, Python & C++ By: Rahul KediaKedia Rahul100% (1)
- CODE For Ugly Approach To The CLTDocument5 pagesCODE For Ugly Approach To The CLTdharamNo ratings yet
- 3 Interesting Python Projects With Code For Beginners!: Data Science BlogathonDocument7 pages3 Interesting Python Projects With Code For Beginners!: Data Science BlogathonNayana GowdaNo ratings yet
- Photoshop Clone Part-1Document50 pagesPhotoshop Clone Part-1Kedia RahulNo ratings yet
- CartoonifyDocument14 pagesCartoonifyRohit RajNo ratings yet
- Digital Image Processing Lab Manual# 2Document6 pagesDigital Image Processing Lab Manual# 2Washakh Ali Muhammad WaseemNo ratings yet
- An Introduction To P5.Js: A Manual For The Javascript P5.Js Workshop For Creative TechnologyDocument40 pagesAn Introduction To P5.Js: A Manual For The Javascript P5.Js Workshop For Creative TechnologygmconNo ratings yet
- 1.2 Image BasicsDocument10 pages1.2 Image Basicsraslenziadi2k21No ratings yet
- The MagPi Issue 28 enDocument42 pagesThe MagPi Issue 28 enRonald Picon PeláezNo ratings yet
- Lab Manual 6Document8 pagesLab Manual 6Dagmawi AdamNo ratings yet
- Detecting Multiple Bright Spots in An Image With Python and OpenCV - PyImageSearchDocument51 pagesDetecting Multiple Bright Spots in An Image With Python and OpenCV - PyImageSearchZubairNo ratings yet
- Dog - App: 1 Convolutional Neural NetworksDocument25 pagesDog - App: 1 Convolutional Neural NetworksDinar MingalievNo ratings yet
- Actividad 3 Images Computer Vision - Ipynb - ColaboratoryDocument8 pagesActividad 3 Images Computer Vision - Ipynb - ColaboratoryAna VelezNo ratings yet
- CV Assignment 2 RecognitionARDocument5 pagesCV Assignment 2 RecognitionARPaul BrgrNo ratings yet
- Tutorial On Building An Interactive Quiz in HTML5Document21 pagesTutorial On Building An Interactive Quiz in HTML5em100% (1)
- Face Recognition J Up y TerDocument5 pagesFace Recognition J Up y TerSamuel PeoplesNo ratings yet
- GANs in Slanted Land - SolutionDocument17 pagesGANs in Slanted Land - SolutionMiriam Ayala CruzNo ratings yet
- QCBioW21 - IPfM2022F - Workbook - NoviceVersion - Ipynb - ColaboratoryDocument59 pagesQCBioW21 - IPfM2022F - Workbook - NoviceVersion - Ipynb - ColaboratoryTAUHID ALAMNo ratings yet
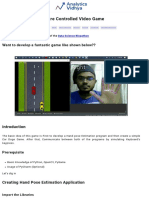
- Gesture Controlled Video Game: Want To Develop A Fantastic Game Like Shown Below??Document7 pagesGesture Controlled Video Game: Want To Develop A Fantastic Game Like Shown Below??ASURNo ratings yet
- Java Image ProcessingDocument15 pagesJava Image ProcessingVijay Kapanipathi RaoNo ratings yet
- Stavens Opencv Optical FlowDocument17 pagesStavens Opencv Optical Flowapi-3709615100% (1)
- Face Recognition With Python, in Under 25 Lines of CodeDocument8 pagesFace Recognition With Python, in Under 25 Lines of CodejlbmdmNo ratings yet
- CV Lab ManualDocument45 pagesCV Lab Manualsincet16No ratings yet
- Image Proccessing Using PythonDocument7 pagesImage Proccessing Using PythonMayank GoyalNo ratings yet
- Proyecto IA2Document14 pagesProyecto IA2Juan José BonillaNo ratings yet
- Project Rapport: Common For All TaskDocument10 pagesProject Rapport: Common For All TaskmaxNo ratings yet
- Exercise 2 Building Convolution Neural NetworkDocument15 pagesExercise 2 Building Convolution Neural NetworkHockhin OoiNo ratings yet
- Cad and Dog 2Document5 pagesCad and Dog 2Muhammad RifaiNo ratings yet
- COMS2003: Application and Analysis of Algorithms II: Niversity of The Itwatersrand OhannesburgDocument3 pagesCOMS2003: Application and Analysis of Algorithms II: Niversity of The Itwatersrand OhannesburgKatneza Katman MohlalaNo ratings yet
- How To Implement RSA in RubyDocument5 pagesHow To Implement RSA in Rubychris_hulbertNo ratings yet
- DP 2Document5 pagesDP 2Nikunj JayasNo ratings yet
- 5visualization and DocumentaionDocument10 pages5visualization and Documentaionaaasim93No ratings yet
- PCV Lab CodesDocument51 pagesPCV Lab Codesanudeep 1No ratings yet
- Interesting Python Project of Gender and Age Detection With OpenCVDocument8 pagesInteresting Python Project of Gender and Age Detection With OpenCVammarNo ratings yet
- QR Code Generation Using Python: 13.import Qrcode 15.img - Save ("Youtubeqr - JPG")Document17 pagesQR Code Generation Using Python: 13.import Qrcode 15.img - Save ("Youtubeqr - JPG")Nidhi AroraNo ratings yet
- Code 1Document18 pagesCode 1Daniyal QureshiNo ratings yet
- University of Management and Technology School of Science and Technology Computer Science DepartmentDocument6 pagesUniversity of Management and Technology School of Science and Technology Computer Science DepartmentAyesha IftikharNo ratings yet
- QMLDocument28 pagesQMLBinod Kumar100% (1)
- NeHe Productions - 2D Texture FontDocument10 pagesNeHe Productions - 2D Texture FontrnspaceNo ratings yet
- Step 1: Set Up Our HTML: A Div With A Nested Element. A Maximum of 2 HTML Tags Are Required For Each Effect!Document10 pagesStep 1: Set Up Our HTML: A Div With A Nested Element. A Maximum of 2 HTML Tags Are Required For Each Effect!Muhammad Rizqi AlzurjaniNo ratings yet
- Decomposing Embedded Images - Loren On The Art of MATLABDocument12 pagesDecomposing Embedded Images - Loren On The Art of MATLABYeni BenNo ratings yet
- Machine Learning With Python - Part-3Document19 pagesMachine Learning With Python - Part-3MustoNo ratings yet
- Sin & Cos - The Programmer's PalsDocument24 pagesSin & Cos - The Programmer's PalsRicardo De Oliveira AlvesNo ratings yet
- Turtle Examples PythonDocument12 pagesTurtle Examples Pythoncally fisherNo ratings yet
- C# Artificial Intelligence (Ai) Programming - A Basic Object Oriented (Oop) Framework For Neural PDFDocument18 pagesC# Artificial Intelligence (Ai) Programming - A Basic Object Oriented (Oop) Framework For Neural PDFjonathanbc25100% (1)
- Augmented Reality - Television With Aruco MarkersDocument14 pagesAugmented Reality - Television With Aruco MarkersKedia Rahul100% (1)
- How To Make An Object Tracking Robot Using Raspberry Pi - Automatic AddisonasdfsdfDocument10 pagesHow To Make An Object Tracking Robot Using Raspberry Pi - Automatic Addisonasdfsdfeshwarp sysargus100% (1)
- P6 - Computer VisionDocument27 pagesP6 - Computer VisionRaul MarianNo ratings yet
- Lab Assignment Subject: CryptographyDocument11 pagesLab Assignment Subject: CryptographyriyaNo ratings yet
- Learn Python through Nursery Rhymes and Fairy Tales: Classic Stories Translated into Python Programs (Coding for Kids and Beginners)From EverandLearn Python through Nursery Rhymes and Fairy Tales: Classic Stories Translated into Python Programs (Coding for Kids and Beginners)Rating: 5 out of 5 stars5/5 (1)
- C.S. Sharma and Kamlesh Purohit - Theory of Mechanisms and Machines-PHI Learning Private Limited (2006)Document723 pagesC.S. Sharma and Kamlesh Purohit - Theory of Mechanisms and Machines-PHI Learning Private Limited (2006)tp coephNo ratings yet
- MC Practicals 2Document12 pagesMC Practicals 2Adi AdnanNo ratings yet
- Tabelas Roscas TrapezoidaisDocument49 pagesTabelas Roscas TrapezoidaisDesenvolvimento MHNo ratings yet
- Internship 2021Document25 pagesInternship 2021PRAGYA CHANSORIYANo ratings yet
- Teachers' Classroom Assessment PracticesDocument12 pagesTeachers' Classroom Assessment PracticesDaniel BarnesNo ratings yet
- Accelerated Construction of Urban Intersections With Portlandcement Concrete Pavement (PCCP)Document3 pagesAccelerated Construction of Urban Intersections With Portlandcement Concrete Pavement (PCCP)A-16 RUSHALINo ratings yet
- DB Broadcast PM300 ManualDocument108 pagesDB Broadcast PM300 Manualfransferdinand2001100% (1)
- TBG Catalog Vol 6Document64 pagesTBG Catalog Vol 6GeorgeNo ratings yet
- The Advantages of Fiedler's Contingency ModelDocument10 pagesThe Advantages of Fiedler's Contingency ModelAnwar LaskarNo ratings yet
- Case Study 148 169Document22 pagesCase Study 148 169Vonn GuintoNo ratings yet
- Hazcom ToolsDocument25 pagesHazcom ToolsAbdul hayeeNo ratings yet
- Safety Rules and Laboratory Equipment: Experiment 1Document5 pagesSafety Rules and Laboratory Equipment: Experiment 1ricardojosecortinaNo ratings yet
- Safety Matrix Master - Rev 1Document5 pagesSafety Matrix Master - Rev 1praagthishNo ratings yet
- Apollo Valves: 94A / 95A SeriesDocument1 pageApollo Valves: 94A / 95A Seriesmaruthappan sundaramNo ratings yet
- Xu and Zhang (2009) (ASCE) GT.1943-5606 - Dam BreachDocument14 pagesXu and Zhang (2009) (ASCE) GT.1943-5606 - Dam BreachCharumitra YadavNo ratings yet
- Visible ThinkingDocument4 pagesVisible ThinkinginterianobersabeNo ratings yet
- NK 3 Final With DataDocument20 pagesNK 3 Final With DataАлексейNo ratings yet
- Revision On Unit 1,2 First Secondry (Hello)Document11 pagesRevision On Unit 1,2 First Secondry (Hello)Vivian GendyNo ratings yet
- ISA75X75X8 X 765: Asset Development Plan 1 (ADP-1)Document1 pageISA75X75X8 X 765: Asset Development Plan 1 (ADP-1)Tamil Arasu SNo ratings yet
- Pineal Gland A Spiritual Third Eye An OdDocument4 pagesPineal Gland A Spiritual Third Eye An OdAsli Melek DoenerNo ratings yet
- DLP in IctDocument3 pagesDLP in Ictreyna.sazon001No ratings yet
- 5S (Methodology) : 5S Is The Name of A Workplace Organization Methodology That Uses A List of FiveDocument3 pages5S (Methodology) : 5S Is The Name of A Workplace Organization Methodology That Uses A List of FiveRoberto DiyNo ratings yet
- Genetic Mutation LAB SHEET REVISEDDocument2 pagesGenetic Mutation LAB SHEET REVISEDyusufoyololaNo ratings yet
- How To Read A Dji Terra Quality ReportDocument10 pagesHow To Read A Dji Terra Quality ReportRazvan Julian PetrescuNo ratings yet
- Adu Gloria WorkDocument68 pagesAdu Gloria WorkAiman UsmanNo ratings yet
- ABB Unit Trip EMAX PR112-PD PDFDocument27 pagesABB Unit Trip EMAX PR112-PD PDFPedro MartinsNo ratings yet
- Crowd Behavior, Crowd Control, and The Use of Non-Lethal WeaponsDocument48 pagesCrowd Behavior, Crowd Control, and The Use of Non-Lethal WeaponsHussainNo ratings yet
- Ammunition Series PDFDocument53 pagesAmmunition Series PDFsorinartistuNo ratings yet
- ASSIGNMENT 1 FinalsDocument2 pagesASSIGNMENT 1 FinalsAnne Dela CruzNo ratings yet