
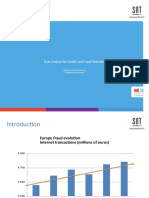
Introduction
Introduction
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Data MiningDocument25 pagesData Miningrishit60% (10)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Homework #6: Student: Mario PerezDocument8 pagesHomework #6: Student: Mario Perezkrishna.setwinNo ratings yet
- Data Lab AnswersDocument7 pagesData Lab AnswersdryzhkoNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Entropy-Based Face Recognition and Spoof Detection For Security ApplicationsDocument18 pagesEntropy-Based Face Recognition and Spoof Detection For Security ApplicationsIvan FadillahNo ratings yet
- Pattern Recognition Letters: Yongbin Gao, Hyo Jong LeeDocument7 pagesPattern Recognition Letters: Yongbin Gao, Hyo Jong LeeIvan FadillahNo ratings yet
- Object Tracking Methods-A ReviewDocument7 pagesObject Tracking Methods-A ReviewIvan FadillahNo ratings yet
- Liveness Detection in Face Recognition Using Deep LearningDocument4 pagesLiveness Detection in Face Recognition Using Deep LearningIvan FadillahNo ratings yet
- CTC Loss FunctionDocument20 pagesCTC Loss FunctionIvan FadillahNo ratings yet
- Face Mask Detection in The Era of The COVID-19: How Can Machine Learning Help The Authorities?Document7 pagesFace Mask Detection in The Era of The COVID-19: How Can Machine Learning Help The Authorities?Ivan FadillahNo ratings yet
- Tkinter TuitorialDocument24 pagesTkinter TuitorialIvan FadillahNo ratings yet
- Frequent Pattern For ClassificationDocument10 pagesFrequent Pattern For ClassificationIvan FadillahNo ratings yet
- Exploring EngineeringDocument4 pagesExploring EngineeringIvan FadillahNo ratings yet
- Tingkat Signifikansi Untuk Uji 1 ArahDocument5 pagesTingkat Signifikansi Untuk Uji 1 ArahIvan FadillahNo ratings yet
- Exam 3Document3 pagesExam 3Ivan FadillahNo ratings yet
- im (x −2) δ ϵ - x −9 - ϵ ⟺ - x−3 - δDocument2 pagesim (x −2) δ ϵ - x −9 - ϵ ⟺ - x−3 - δIvan FadillahNo ratings yet
- Design & Analysis of Algorithms: DR Anwar GhaniDocument31 pagesDesign & Analysis of Algorithms: DR Anwar GhaniMahmood SyedNo ratings yet
- Design and Implementation of Coconut Maturity Prediction System Based On Naïve Bayes Classification Algorithm Using Arduino and A Sound SensorDocument10 pagesDesign and Implementation of Coconut Maturity Prediction System Based On Naïve Bayes Classification Algorithm Using Arduino and A Sound SensorInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Dynamic ErrorDocument7 pagesDynamic ErrorSuvra PattanayakNo ratings yet
- Assignment 1Document4 pagesAssignment 1ng boon janeNo ratings yet
- Cs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - ADocument6 pagesCs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - Avidhya_bineeshNo ratings yet
- Modeling Tea Prices and Their Volatility in KenyaDocument45 pagesModeling Tea Prices and Their Volatility in KenyarobinNo ratings yet
- Competitive Programming RoadmapDocument6 pagesCompetitive Programming RoadmapVikash YadavNo ratings yet
- Algorithm & FlowchartDocument7 pagesAlgorithm & FlowchartAnas ShaikhNo ratings yet
- ShuffleNet An Extremely Efficient Convolutional Neural Network For Mobile-2018Document9 pagesShuffleNet An Extremely Efficient Convolutional Neural Network For Mobile-2018Jorge Velasquez RamosNo ratings yet
- Fire CodeDocument2 pagesFire CodeNabil Magdi HasanNo ratings yet
- Google PageRankDocument22 pagesGoogle PageRankBeat SignerNo ratings yet
- Quiz 3 (Pass - Quiz3) - Attempt ReviewDocument11 pagesQuiz 3 (Pass - Quiz3) - Attempt ReviewHữuNo ratings yet
- Year 7 Autumn 2 Algebraic Notation Mini Assessment A 2Document2 pagesYear 7 Autumn 2 Algebraic Notation Mini Assessment A 2pq6b2md785No ratings yet
- Christian Clason Introduction To Functional AnalysisDocument9 pagesChristian Clason Introduction To Functional Analysisdr.manarabdallaNo ratings yet
- Association Rule MiningDocument34 pagesAssociation Rule MiningAllison CollierNo ratings yet
- ANALYTICS - by - Debdeep GhoshDocument5 pagesANALYTICS - by - Debdeep GhoshDebdeep GhoshNo ratings yet
- Akbari 2013Document5 pagesAkbari 2013andisulviqrahNo ratings yet
- Sinopsis Matematik TeknologiDocument46 pagesSinopsis Matematik TeknologiGardenia JasmineNo ratings yet
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Assignment 2-2.1.2 Pseudocode and FlowchartsDocument3 pagesAssignment 2-2.1.2 Pseudocode and FlowchartsAditya GhoseNo ratings yet
- Programming QuestionsDocument2 pagesProgramming QuestionsANITHARANI KNo ratings yet
- Facial Expression RecognitionDocument4 pagesFacial Expression RecognitionPrasanna PrasannaNo ratings yet
- Thermodynamic EquilibriumDocument118 pagesThermodynamic EquilibriumKishore Kumar100% (1)
- Data Analysis For Credit Card Fraud DetectionDocument23 pagesData Analysis For Credit Card Fraud DetectionAhmad WarrichNo ratings yet
- Credit ScoringDocument26 pagesCredit ScoringjimNo ratings yet
- Damaged Information and The Out-Of-Time-Ordered CorrelatorsDocument5 pagesDamaged Information and The Out-Of-Time-Ordered CorrelatorsANo ratings yet
- Economatrics Final PaperDocument13 pagesEconomatrics Final PaperSanjeewani WarnakulasooriyaNo ratings yet


















































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Data MiningDocument25 pagesData Miningrishit60% (10)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Homework #6: Student: Mario PerezDocument8 pagesHomework #6: Student: Mario Perezkrishna.setwinNo ratings yet
- Data Lab AnswersDocument7 pagesData Lab AnswersdryzhkoNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Entropy-Based Face Recognition and Spoof Detection For Security ApplicationsDocument18 pagesEntropy-Based Face Recognition and Spoof Detection For Security ApplicationsIvan FadillahNo ratings yet
- Pattern Recognition Letters: Yongbin Gao, Hyo Jong LeeDocument7 pagesPattern Recognition Letters: Yongbin Gao, Hyo Jong LeeIvan FadillahNo ratings yet
- Object Tracking Methods-A ReviewDocument7 pagesObject Tracking Methods-A ReviewIvan FadillahNo ratings yet
- Liveness Detection in Face Recognition Using Deep LearningDocument4 pagesLiveness Detection in Face Recognition Using Deep LearningIvan FadillahNo ratings yet
- CTC Loss FunctionDocument20 pagesCTC Loss FunctionIvan FadillahNo ratings yet
- Face Mask Detection in The Era of The COVID-19: How Can Machine Learning Help The Authorities?Document7 pagesFace Mask Detection in The Era of The COVID-19: How Can Machine Learning Help The Authorities?Ivan FadillahNo ratings yet
- Tkinter TuitorialDocument24 pagesTkinter TuitorialIvan FadillahNo ratings yet
- Frequent Pattern For ClassificationDocument10 pagesFrequent Pattern For ClassificationIvan FadillahNo ratings yet
- Exploring EngineeringDocument4 pagesExploring EngineeringIvan FadillahNo ratings yet
- Tingkat Signifikansi Untuk Uji 1 ArahDocument5 pagesTingkat Signifikansi Untuk Uji 1 ArahIvan FadillahNo ratings yet
- Exam 3Document3 pagesExam 3Ivan FadillahNo ratings yet
- im (x −2) δ ϵ - x −9 - ϵ ⟺ - x−3 - δDocument2 pagesim (x −2) δ ϵ - x −9 - ϵ ⟺ - x−3 - δIvan FadillahNo ratings yet
- Design & Analysis of Algorithms: DR Anwar GhaniDocument31 pagesDesign & Analysis of Algorithms: DR Anwar GhaniMahmood SyedNo ratings yet
- Design and Implementation of Coconut Maturity Prediction System Based On Naïve Bayes Classification Algorithm Using Arduino and A Sound SensorDocument10 pagesDesign and Implementation of Coconut Maturity Prediction System Based On Naïve Bayes Classification Algorithm Using Arduino and A Sound SensorInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Dynamic ErrorDocument7 pagesDynamic ErrorSuvra PattanayakNo ratings yet
- Assignment 1Document4 pagesAssignment 1ng boon janeNo ratings yet
- Cs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - ADocument6 pagesCs6702 Graph Theory and Applications Question Bank Unit I Introduction Part - Avidhya_bineeshNo ratings yet
- Modeling Tea Prices and Their Volatility in KenyaDocument45 pagesModeling Tea Prices and Their Volatility in KenyarobinNo ratings yet
- Competitive Programming RoadmapDocument6 pagesCompetitive Programming RoadmapVikash YadavNo ratings yet
- Algorithm & FlowchartDocument7 pagesAlgorithm & FlowchartAnas ShaikhNo ratings yet
- ShuffleNet An Extremely Efficient Convolutional Neural Network For Mobile-2018Document9 pagesShuffleNet An Extremely Efficient Convolutional Neural Network For Mobile-2018Jorge Velasquez RamosNo ratings yet
- Fire CodeDocument2 pagesFire CodeNabil Magdi HasanNo ratings yet
- Google PageRankDocument22 pagesGoogle PageRankBeat SignerNo ratings yet
- Quiz 3 (Pass - Quiz3) - Attempt ReviewDocument11 pagesQuiz 3 (Pass - Quiz3) - Attempt ReviewHữuNo ratings yet
- Year 7 Autumn 2 Algebraic Notation Mini Assessment A 2Document2 pagesYear 7 Autumn 2 Algebraic Notation Mini Assessment A 2pq6b2md785No ratings yet
- Christian Clason Introduction To Functional AnalysisDocument9 pagesChristian Clason Introduction To Functional Analysisdr.manarabdallaNo ratings yet
- Association Rule MiningDocument34 pagesAssociation Rule MiningAllison CollierNo ratings yet
- ANALYTICS - by - Debdeep GhoshDocument5 pagesANALYTICS - by - Debdeep GhoshDebdeep GhoshNo ratings yet
- Akbari 2013Document5 pagesAkbari 2013andisulviqrahNo ratings yet
- Sinopsis Matematik TeknologiDocument46 pagesSinopsis Matematik TeknologiGardenia JasmineNo ratings yet
- 40 Interview Questions Asked at Startups in Machine Learning - Data ScienceDocument33 pages40 Interview Questions Asked at Startups in Machine Learning - Data SciencePallav Anand100% (3)
- Assignment 2-2.1.2 Pseudocode and FlowchartsDocument3 pagesAssignment 2-2.1.2 Pseudocode and FlowchartsAditya GhoseNo ratings yet
- Programming QuestionsDocument2 pagesProgramming QuestionsANITHARANI KNo ratings yet
- Facial Expression RecognitionDocument4 pagesFacial Expression RecognitionPrasanna PrasannaNo ratings yet
- Thermodynamic EquilibriumDocument118 pagesThermodynamic EquilibriumKishore Kumar100% (1)
- Data Analysis For Credit Card Fraud DetectionDocument23 pagesData Analysis For Credit Card Fraud DetectionAhmad WarrichNo ratings yet
- Credit ScoringDocument26 pagesCredit ScoringjimNo ratings yet
- Damaged Information and The Out-Of-Time-Ordered CorrelatorsDocument5 pagesDamaged Information and The Out-Of-Time-Ordered CorrelatorsANo ratings yet
- Economatrics Final PaperDocument13 pagesEconomatrics Final PaperSanjeewani WarnakulasooriyaNo ratings yet