Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5822)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- Georg Büchner: Leonce and Lena (English)Document18 pagesGeorg Büchner: Leonce and Lena (English)Tímea Tulik100% (2)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Public Relation in HospitalDocument6 pagesPublic Relation in HospitalAnusha Verghese80% (5)
- How-the-COVID-19-crisis-may-affect-electronic Payments-In-AfricaDocument11 pagesHow-the-COVID-19-crisis-may-affect-electronic Payments-In-AfricabasseyNo ratings yet
- Macroeconomic Impact of Ai Technical Report Feb 18Document78 pagesMacroeconomic Impact of Ai Technical Report Feb 18basseyNo ratings yet
- From RPA To DPA: A Strategic Approach To Automation: November 2018Document8 pagesFrom RPA To DPA: A Strategic Approach To Automation: November 2018basseyNo ratings yet
- March 29, 2020: Nigeria Mobility ChangesDocument3 pagesMarch 29, 2020: Nigeria Mobility ChangesbasseyNo ratings yet
- MGI The Age of Analytics Full Report PDFDocument136 pagesMGI The Age of Analytics Full Report PDFharvardmedical99No ratings yet
- BI+Trends+++Strategies Sept+2012Document12 pagesBI+Trends+++Strategies Sept+2012basseyNo ratings yet
- Algebra. Level 6. Equations. Solving Linear Equations (C)Document1 pageAlgebra. Level 6. Equations. Solving Linear Equations (C)George MorianopoulosNo ratings yet
- Parts of The 1987 ConstitutionDocument6 pagesParts of The 1987 ConstitutionDESA GALE MARASIGANNo ratings yet
- Hoja de Vida Actividad Nº4-Gestion de Mercados-ResueltaDocument3 pagesHoja de Vida Actividad Nº4-Gestion de Mercados-ResueltaSebastian andres Argote gonzaLezNo ratings yet
- Dr. Annu June 2019Document6 pagesDr. Annu June 2019AnnuNo ratings yet
- A2Document33 pagesA2Anmol GoswamiNo ratings yet
- International Finance MGT Vs Domestic Fin MGTDocument5 pagesInternational Finance MGT Vs Domestic Fin MGTabhishek_das_14100% (2)
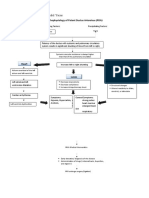
- Pathophysiology of Patent Ductus Arteroisus (PDA)Document2 pagesPathophysiology of Patent Ductus Arteroisus (PDA)Rodel Yacas100% (1)
- The Role of Humanity For Human LifeDocument102 pagesThe Role of Humanity For Human LifeMinhh TríNo ratings yet
- Ed350 The Apple of My EyeDocument27 pagesEd350 The Apple of My Eyeapi-260448295No ratings yet
- Vishnu - Reflections - Miyamoto Musashi - 21 Precepts For Attaining EnlightenmentDocument3 pagesVishnu - Reflections - Miyamoto Musashi - 21 Precepts For Attaining EnlightenmentGokula SwamiNo ratings yet
- DL-6101 - Criminal Procedure CodeDocument257 pagesDL-6101 - Criminal Procedure CodeTiki TakaNo ratings yet
- Research ProposalDocument14 pagesResearch ProposalNiizamUddinBhuiyanNo ratings yet
- Dka AlgorithmDocument1 pageDka AlgorithmAbhinav AggarwalNo ratings yet
- Editing TextDocument4 pagesEditing TextA R ShamimNo ratings yet
- Matrix 210 25-Pin Models Software Configuration Parameter GuideDocument161 pagesMatrix 210 25-Pin Models Software Configuration Parameter GuideFiliArNo ratings yet
- Writing A Research ReportDocument22 pagesWriting A Research ReportFira Abelia100% (1)
- Take-Home Final Examination Part B September 2021 SemesterDocument3 pagesTake-Home Final Examination Part B September 2021 SemesterRizana HamsadeenNo ratings yet
- Appointment, Removal and Resignation of AuditorsDocument3 pagesAppointment, Removal and Resignation of AuditorsAsad Ehsan Warraich100% (1)
- John Dewey's The Child and The Curriculum by Phillips 1998Document13 pagesJohn Dewey's The Child and The Curriculum by Phillips 1998Kangdon LeeNo ratings yet
- Obw PocahontasDocument11 pagesObw PocahontasDavid ValenzNo ratings yet
- Determinacon de La DVO Una Revision Actualizada PDFDocument18 pagesDeterminacon de La DVO Una Revision Actualizada PDFJose Antonio Figuroa AbadoNo ratings yet
- Skillguru French BrochureDocument1 pageSkillguru French BrochureajithkumarakkenaNo ratings yet
- 3.1 School Based Review Contextualization and Implementation of StandardsDocument9 pages3.1 School Based Review Contextualization and Implementation of StandardsOscar Matela100% (1)
- Legend Situ BagenditDocument6 pagesLegend Situ BagenditFaika NabilaNo ratings yet
- Fringe Thought KooksDocument445 pagesFringe Thought KooksPete Kieffer0% (1)
- Department of Serology Covid-19 Antigen Test: Covid 19 Ag Test, Test Name Result Unit Bio. Ref. Range MethodDocument1 pageDepartment of Serology Covid-19 Antigen Test: Covid 19 Ag Test, Test Name Result Unit Bio. Ref. Range MethodPradeep VunnamNo ratings yet
- Work Ancient and Medieval Indian History NotesDocument103 pagesWork Ancient and Medieval Indian History Notesakash kumarNo ratings yet
- 09 English Communicative Ch14 The Bishops Candlesticks QuesDocument3 pages09 English Communicative Ch14 The Bishops Candlesticks QueskrishNo ratings yet