Download as pdf or txt
You might also like
- Assignment 3 SolutionsDocument7 pagesAssignment 3 SolutionsNengke Lin100% (1)
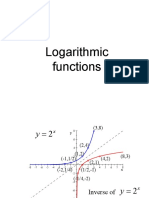
- Log FunctionsDocument13 pagesLog FunctionsAbdul MoizNo ratings yet
- Javascript For C# Developers Module 1: Javascript Basics: Shawn Wildermuth Wilder MindsDocument31 pagesJavascript For C# Developers Module 1: Javascript Basics: Shawn Wildermuth Wilder Mindsedowns100% (1)
- Information Theory and Computing Assignment No. 1: April 10, 2020Document12 pagesInformation Theory and Computing Assignment No. 1: April 10, 2020Abhishek KumarNo ratings yet
- KBATekstra 4Document2 pagesKBATekstra 4g-05288283No ratings yet
- WLP11 LogarithmDocument21 pagesWLP11 Logarithmshellaorocio00No ratings yet
- Log+Sheet+Ex+ 1+Part+B+Solution+Document4 pagesLog+Sheet+Ex+ 1+Part+B+Solution+sumitNo ratings yet
- Topic 4 - Log Part 2 - 006Document3 pagesTopic 4 - Log Part 2 - 006Ing Ding LonNo ratings yet
- Ejercicio 5Document1 pageEjercicio 5Claudio CanoNo ratings yet
- Ejercicio 5Document1 pageEjercicio 5Claudio CanoNo ratings yet
- 3.07 Logarithmic Equations - WorksheetDocument1 page3.07 Logarithmic Equations - Worksheetnehashiju1No ratings yet
- LOGARITHMSDocument5 pagesLOGARITHMSKaterin Vargas tacuñaNo ratings yet
- Activity Sheet In: General MathematiDocument10 pagesActivity Sheet In: General MathematiRevanVilladozNo ratings yet
- JPWP Mark Scheme SPM 2008 Trial Add Maths P1Document6 pagesJPWP Mark Scheme SPM 2008 Trial Add Maths P1tan_wooichoongNo ratings yet
- College Algebra - SampleasdaDocument25 pagesCollege Algebra - SampleasdaAbchoNo ratings yet
- HKDSE Mathematics Logarithms Function Class Practice: y 2 y X y Log X y X y 3Document10 pagesHKDSE Mathematics Logarithms Function Class Practice: y 2 y X y Log X y X y 3陳大明No ratings yet
- G11 Exercises LogarithmicFunctionDocument4 pagesG11 Exercises LogarithmicFunctionBimBel PolimNo ratings yet
- Exponents Logarithms SolDocument4 pagesExponents Logarithms SolwliNo ratings yet
- Laws of LogarithmsDocument3 pagesLaws of LogarithmsAnnie FreebiesNo ratings yet
- (KEY) M114 Hw20 - Completion (No Graded)Document2 pages(KEY) M114 Hw20 - Completion (No Graded)citokristenNo ratings yet
- Equations With LogarithmsDocument1 pageEquations With LogarithmsMaria GonzalezNo ratings yet
- Exercises - LogarithmicFunction - With SolutionDocument12 pagesExercises - LogarithmicFunction - With Solutionpau miquelNo ratings yet
- Y y y y y y y y y Y: y y y yDocument9 pagesY y y y y y y y y Y: y y y ysamNo ratings yet
- Worksheet: Logarithmic FunctionDocument12 pagesWorksheet: Logarithmic FunctionhazwaniNo ratings yet
- Tutorial For Basic MathematicsDocument126 pagesTutorial For Basic MathematicsBajirao JetithorNo ratings yet
- Ecuatii Exponentiale Si LogaritmiceDocument2 pagesEcuatii Exponentiale Si LogaritmiceGabrielaNo ratings yet
- Ecuaciones Cuando La Variable Esta Como ExponenteDocument4 pagesEcuaciones Cuando La Variable Esta Como ExponenteikarosNo ratings yet
- 1819F4T1M1MSDocument12 pages1819F4T1M1MSLUI ansonNo ratings yet
- Transform The FFDocument6 pagesTransform The FFKristan Glen PulidoNo ratings yet
- بنكDocument8 pagesبنكMahmoud ElagwanyNo ratings yet
- Changing The Base of LogarithmsDocument5 pagesChanging The Base of LogarithmsEHANo ratings yet
- Exam Equations - Solution. 4ºesoDocument3 pagesExam Equations - Solution. 4ºesolauralNo ratings yet
- Lap11 Logarithm ContinuationDocument9 pagesLap11 Logarithm ContinuationGabs KatipunanNo ratings yet
- Lecture 19Document25 pagesLecture 19utpNo ratings yet
- Logaritmos y ExponencialesDocument20 pagesLogaritmos y ExponencialesYoussra BenacherNo ratings yet
- Examen de Matematica AplicadaDocument14 pagesExamen de Matematica AplicadaEli GonzalezNo ratings yet
- Addmath SPM ExerciseDocument3 pagesAddmath SPM ExerciseAspen ChoongNo ratings yet
- Exercise 3E: 1 Log LogDocument2 pagesExercise 3E: 1 Log LogKaif HasanNo ratings yet
- Theta Logs, Radicals & Exponents MAΘ National Convention 2018Document4 pagesTheta Logs, Radicals & Exponents MAΘ National Convention 2018Simon SiregarNo ratings yet
- Lesson 8 Teacher's Guide Equations Involving Logarithms: ObjectiveDocument6 pagesLesson 8 Teacher's Guide Equations Involving Logarithms: ObjectiveАрхи́пNo ratings yet
- Logaritmos - Ejercicios 2Document1 pageLogaritmos - Ejercicios 2Christian Ricardo Calderon SorianoNo ratings yet
- General Mathematics: Jelvis PelayoDocument30 pagesGeneral Mathematics: Jelvis PelayoJenna Alyssa BaligatNo ratings yet
- Soal Dan Penyelesaian Ujian AljabarDocument7 pagesSoal Dan Penyelesaian Ujian Aljabarerbi.syaputraNo ratings yet
- Logarithmic FunctionsDocument32 pagesLogarithmic FunctionsNiño Ryan ErminoNo ratings yet
- Logar I ThemDocument3 pagesLogar I Themjayonline_4uNo ratings yet
- 4B Ch7 Test Answers Multiple Choice Questions (5 Marks)Document5 pages4B Ch7 Test Answers Multiple Choice Questions (5 Marks)NicoleNo ratings yet
- CALCULO EJERCICIO 1 y 2Document2 pagesCALCULO EJERCICIO 1 y 2Warrtriorh GuillermoNo ratings yet
- X X DX +2 X DX 5 DX X dx+2 X DX 5 DX: 1. Tipo 1 - Integrales InmediatasDocument4 pagesX X DX +2 X DX 5 DX X dx+2 X DX 5 DX: 1. Tipo 1 - Integrales InmediatasEdwin HernandezNo ratings yet
- H M Sè L Garýt: ÞNH NghüaDocument15 pagesH M Sè L Garýt: ÞNH NghüalvminhtrietNo ratings yet
- Lesson 6-Differentiation of Logarithmic and Exponential Functions FunctionsDocument30 pagesLesson 6-Differentiation of Logarithmic and Exponential Functions FunctionsRegie SalasNo ratings yet
- Ejercicios en ClaseDocument8 pagesEjercicios en ClaseVane ArroyoNo ratings yet
- Simplificación y Ecuaciones LogarítmicasDocument1 pageSimplificación y Ecuaciones LogarítmicasTasa PapelNo ratings yet
- Exercises LogarithmicFunctionDocument3 pagesExercises LogarithmicFunctionChitrakshi SinghNo ratings yet
- Exercises LogarithmicFunctionDocument12 pagesExercises LogarithmicFunctionwongchiinglamNo ratings yet
- A Level Pure Seminar Solutions 2018Document27 pagesA Level Pure Seminar Solutions 2018Ainebyoona ChriscentNo ratings yet
- Med 6.4Document1 pageMed 6.4dragosNo ratings yet
- 121 Exam 2 SolutionDocument4 pages121 Exam 2 SolutionАрхи́пNo ratings yet
- (Done) Q2 - GenMath TEST YOURSELF WEEK 9-10Document4 pages(Done) Q2 - GenMath TEST YOURSELF WEEK 9-10aespa karinaNo ratings yet
- Integration SolutionDocument4 pagesIntegration SolutionÐhammaþriyaKamßleNo ratings yet
- Solutions To Most of The Practice Diploma Problems:: X X X XXXDocument2 pagesSolutions To Most of The Practice Diploma Problems:: X X X XXXMichael BesplugNo ratings yet
- Mabe Exam 13 2 19-SolDocument8 pagesMabe Exam 13 2 19-SolNikola PilašNo ratings yet
- Test Bank for Precalculus: Functions & GraphsFrom EverandTest Bank for Precalculus: Functions & GraphsRating: 5 out of 5 stars5/5 (1)
- Markov Process: Properties, Analysis and Applications: Ajay KumarDocument113 pagesMarkov Process: Properties, Analysis and Applications: Ajay KumarAbhishek KumarNo ratings yet
- Markov Process: Properties, Analysis and Applications: Ajay KumarDocument113 pagesMarkov Process: Properties, Analysis and Applications: Ajay KumarAbhishek KumarNo ratings yet
- L3 - Wireless Communication PDFDocument76 pagesL3 - Wireless Communication PDFAbhishek KumarNo ratings yet
- Information Theory and Computing Assignment No. 1: April 10, 2020Document12 pagesInformation Theory and Computing Assignment No. 1: April 10, 2020Abhishek KumarNo ratings yet
- L2wireless Communication PDFDocument40 pagesL2wireless Communication PDFAbhishek KumarNo ratings yet
- Part One - 40 Part Two - 60Document5 pagesPart One - 40 Part Two - 60Abhishek KumarNo ratings yet
- Four ProbeDocument14 pagesFour ProbeAbhishek KumarNo ratings yet
- BADASS Tutorial Karnaugh MapsDocument16 pagesBADASS Tutorial Karnaugh MapsdjpsychoscientzNo ratings yet
- Sequential SearchDocument1 pageSequential SearchNessie Jeine PuriNo ratings yet
- Course Plan Design and Analysis of AlgorithmDocument2 pagesCourse Plan Design and Analysis of AlgorithmPratyush RanjanNo ratings yet
- CS301 Collection of Old PapersDocument113 pagesCS301 Collection of Old Paperscs619finalproject.com100% (2)
- Untitled2.ipynb - ColaboratoryDocument4 pagesUntitled2.ipynb - ColaboratoryudayNo ratings yet
- CSI3104 S2011 Midterm1 SolnDocument7 pagesCSI3104 S2011 Midterm1 SolnQuinn JacksonNo ratings yet
- Data Structures Unit 4Document179 pagesData Structures Unit 4tanuja rajputNo ratings yet
- 10 Reducibility and NP CompletenessDocument100 pages10 Reducibility and NP Completenessdipanjali chavareNo ratings yet
- Arithmetic Operations On Images Using (Bitwise Operations On Binary Images)Document7 pagesArithmetic Operations On Images Using (Bitwise Operations On Binary Images)s sNo ratings yet
- Reference Books:: Artificial IntelligenceDocument3 pagesReference Books:: Artificial IntelligenceAnila YasmeenNo ratings yet
- C Programming Exercises - For Loop - W3resourceDocument1 pageC Programming Exercises - For Loop - W3resourceRISHITHA LELLANo ratings yet
- Wyndor: Product Mix ProblemDocument38 pagesWyndor: Product Mix ProblemHassan FarroukhNo ratings yet
- Scoa-Question Bank PDFDocument8 pagesScoa-Question Bank PDFvishal borateNo ratings yet
- SVM Scribe NotesDocument16 pagesSVM Scribe NotesRishab KumarNo ratings yet
- A. Special Functions and Graph TheoryDocument1 pageA. Special Functions and Graph TheorysansureNo ratings yet
- Exercise Ready To PSPM, Matriculation (Science Computer)Document7 pagesExercise Ready To PSPM, Matriculation (Science Computer)amrhkmh100% (1)
- To Check Whether String Belongs To A Grammar or Not: AlgorithmDocument34 pagesTo Check Whether String Belongs To A Grammar or Not: AlgorithmHisham KhanNo ratings yet
- Question Bank - Machine LearningDocument4 pagesQuestion Bank - Machine LearningSonali DalviNo ratings yet
- Chapter 3 Parallel and Pipelined Processing: 1 ECE734 VLSI Arrays For Digital Signal ProcessingDocument13 pagesChapter 3 Parallel and Pipelined Processing: 1 ECE734 VLSI Arrays For Digital Signal ProcessingM Madan GopalNo ratings yet
- Uninformed Search: (Based On Slides by Stuart Russell, Dan Weld, Oren Etzioni, Henry Kautz, and Other UW-AI Faculty)Document28 pagesUninformed Search: (Based On Slides by Stuart Russell, Dan Weld, Oren Etzioni, Henry Kautz, and Other UW-AI Faculty)Arun KashyapNo ratings yet
- Applied Mathematics Letters: Kexiang XuDocument5 pagesApplied Mathematics Letters: Kexiang XuThiago FroisNo ratings yet
- Rules of Replacement Final PrintDocument4 pagesRules of Replacement Final PrintJhang Gheung Dee SaripNo ratings yet
- Rue ÊubjeiebDocument26 pagesRue ÊubjeiebNguyễn Danh HùngNo ratings yet
- 1.3. Consider The Bond-Portfolio Problem Formulated in Section 1.3. Reformulate The ProblemDocument4 pages1.3. Consider The Bond-Portfolio Problem Formulated in Section 1.3. Reformulate The ProblemVIKRAM KUMARNo ratings yet
- Matrix-Chain Multiplication: - Suppose We Have A Sequence or Chain A, A,, A of N Matrices To Be MultipliedDocument15 pagesMatrix-Chain Multiplication: - Suppose We Have A Sequence or Chain A, A,, A of N Matrices To Be Multipliedrosev15No ratings yet
- Factoring & Intercept Form - Graphing Parabolas: Solve Each Equation by FactoringDocument6 pagesFactoring & Intercept Form - Graphing Parabolas: Solve Each Equation by FactoringAriana CalixtoNo ratings yet
- K L University Freshman Engineering Department: A Project Based Lab Report OnDocument29 pagesK L University Freshman Engineering Department: A Project Based Lab Report OnMohammed Yaseen Junaid 04No ratings yet
- I C A V L C D A H.264 MDocument1 pageI C A V L C D A H.264 MRAJASHEKHAR B SOMASAGARNo ratings yet