
Topic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)
Topic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)
You might also like
- Dimitra Fimi. Tolkien, Race and Cultural History From Fairies ToDocument4 pagesDimitra Fimi. Tolkien, Race and Cultural History From Fairies Tomadeehamaqbool736250% (4)
- Python Matplotlib Data VisualizationDocument32 pagesPython Matplotlib Data VisualizationLakshit ManraoNo ratings yet
- Ravengro Expanded CompleteDocument10 pagesRavengro Expanded Completeitsme5616No ratings yet
- Stocks Data Analysis and Visualization Using Python AssignmentDocument4 pagesStocks Data Analysis and Visualization Using Python Assignmentbug myweeksNo ratings yet
- SAP BW Business Blueprint Step by Step GuideDocument33 pagesSAP BW Business Blueprint Step by Step Guidekavya.nori0% (1)
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- Deep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - CookbookDocument27 pagesDeep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - Cookbookmahmoudahmed.rtaNo ratings yet
- Unit10 QB VHADocument36 pagesUnit10 QB VHAdaku5246No ratings yet
- Reading+6+ +Data+Visualization+CustomizationDocument30 pagesReading+6+ +Data+Visualization+CustomizationlussyNo ratings yet
- Unit10 - QB - Solution - Jupyter NotebookDocument33 pagesUnit10 - QB - Solution - Jupyter Notebookdaku5246No ratings yet
- CSC 335 Test 2 Review Sheet Followed by Practice TestDocument10 pagesCSC 335 Test 2 Review Sheet Followed by Practice Testtrass infotekNo ratings yet
- Linear Regression PDFDocument16 pagesLinear Regression PDFapi-540582672100% (1)
- Class 12 Informatics ProjectDocument16 pagesClass 12 Informatics ProjectJoshuaNo ratings yet
- Pair Trade For MatlabDocument4 pagesPair Trade For MatlabNukul SukuprakarnNo ratings yet
- Python Pandas MatplotDocument15 pagesPython Pandas MatplotRafay FarooqNo ratings yet
- LSTM Stock PredictionDocument38 pagesLSTM Stock PredictionKetan Ingale100% (1)
- Ch-4 Plotting Data Using MatplotlibDocument32 pagesCh-4 Plotting Data Using Matplotlibseemabhatia392No ratings yet
- Knitr ManualDocument11 pagesKnitr ManualRobin C DSNo ratings yet
- BDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Document10 pagesBDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Saleh ZulNo ratings yet
- Dynamic Memory Allocation and Dynamic Structures: Full ProgramDocument6 pagesDynamic Memory Allocation and Dynamic Structures: Full ProgramAntônio Eduardo CarvalhoNo ratings yet
- Dav Exp8 56Document4 pagesDav Exp8 56godizlatanNo ratings yet
- New Text DocumentDocument10 pagesNew Text DocumentdustboyNo ratings yet
- 5 Advanced Features of Pandas and How To Use ThemDocument10 pages5 Advanced Features of Pandas and How To Use ThemFecodNo ratings yet
- Linear Regression PTDocument16 pagesLinear Regression PTapi-540907926100% (1)
- Worksheet-1 (Python)Document9 pagesWorksheet-1 (Python)rizwana fathimaNo ratings yet
- Coding IntroductionDocument46 pagesCoding Introductionlijiayi2023666No ratings yet
- CS 103 Lab 8 - Stay Classy CS103: 4.1 (10 PTS.) Finishing The Implementation of WarDocument3 pagesCS 103 Lab 8 - Stay Classy CS103: 4.1 (10 PTS.) Finishing The Implementation of WarRahul Ranjan PradhanNo ratings yet
- Assignment 4 On Visualization On Graph With SolutionDocument14 pagesAssignment 4 On Visualization On Graph With Solutionvikas_2No ratings yet
- PythDocument38 pagesPythMinal JoshiNo ratings yet
- MatplotlibDocument7 pagesMatplotlibdbqatest001No ratings yet
- Advanced Stock Price Prediction Using Machine Learning and Time Series Analysis - by Nickolas Discolll - Dec, 2023 - MediumDocument38 pagesAdvanced Stock Price Prediction Using Machine Learning and Time Series Analysis - by Nickolas Discolll - Dec, 2023 - MediumchristhloNo ratings yet
- Knitr ManualDocument11 pagesKnitr ManualNonameNo ratings yet
- Advanced Recommender Systems With PythonDocument13 pagesAdvanced Recommender Systems With PythonFabian HafnerNo ratings yet
- MultigraphDocument4 pagesMultigraphkaivannshahNo ratings yet
- Plot Per Columns Features Kde or Normal Distribution Seaborn in DetailsDocument272 pagesPlot Per Columns Features Kde or Normal Distribution Seaborn in Detailsyousef shabanNo ratings yet
- Python CodeDocument7 pagesPython CodeGnan ShettyNo ratings yet
- Lab Manual: Multimedia Application DevelopmentDocument28 pagesLab Manual: Multimedia Application Developmentroja1901No ratings yet
- QB - 22ADS35 (Python For Data Science)Document6 pagesQB - 22ADS35 (Python For Data Science)Arvind ASNo ratings yet
- Stock AnalyzerDocument38 pagesStock AnalyzerEmon KabirNo ratings yet
- Seaweed 2 WorkbookDocument42 pagesSeaweed 2 WorkbookAnouar El HajiNo ratings yet
- Hands On Seaborn?Document57 pagesHands On Seaborn?pratik choudhariNo ratings yet
- Lesson2 DataframeDocument4 pagesLesson2 DataframeGustavo MartinoNo ratings yet
- Chapter 3Document51 pagesChapter 3Ingle AshwiniNo ratings yet
- HTML CodeDocument1 pageHTML CodeNavkaran SinghNo ratings yet
- Accessing and Working With Statsbomb Data in RDocument27 pagesAccessing and Working With Statsbomb Data in RTewfic SeidNo ratings yet
- Seaborne LibraryDocument65 pagesSeaborne LibraryRajaNo ratings yet
- Lesson3 AestheticsDocument3 pagesLesson3 AestheticsDikshaMantraNo ratings yet
- TDDB84 DesignPatterns Exam 2005 10 15 PDFDocument6 pagesTDDB84 DesignPatterns Exam 2005 10 15 PDFponniNo ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- Bqplot Documentation: Release 0.10.0Document97 pagesBqplot Documentation: Release 0.10.0Swastik MishraNo ratings yet
- Pierian Data - Python For Finance & Algorithmic Trading Course NotesDocument11 pagesPierian Data - Python For Finance & Algorithmic Trading Course NotesIshan SaneNo ratings yet
- CS211 Fall 2002 P4Document7 pagesCS211 Fall 2002 P4Nikhil VarandaniNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Atariarcade SDK Quick-Start GuideDocument8 pagesAtariarcade SDK Quick-Start GuideJuan P Arbeláez RNo ratings yet
- Let Your Data SPEAK: 1.1 What Can Visualization Be Used For?Document8 pagesLet Your Data SPEAK: 1.1 What Can Visualization Be Used For?Nelson LozanoNo ratings yet
- FALLSEM2021-22 MAT2001 ELA VL2021220102174 Reference Material III 03-Aug-2021 Basic Graphics in RDocument15 pagesFALLSEM2021-22 MAT2001 ELA VL2021220102174 Reference Material III 03-Aug-2021 Basic Graphics in RAswin MMNo ratings yet
- Reporting ToolsDocument30 pagesReporting ToolsEmon KabirNo ratings yet
- Week 4 Project - Adversarial Search and Games - CSMMDocument9 pagesWeek 4 Project - Adversarial Search and Games - CSMMRaj kumar manepallyNo ratings yet
- Dungeon Siege Game GuideDocument21 pagesDungeon Siege Game GuideJesse StillNo ratings yet
- Dash IntroDocument18 pagesDash IntroTan ChNo ratings yet
- Introduction To Data Visualization in PythonDocument16 pagesIntroduction To Data Visualization in PythonudayNo ratings yet
- SpectreRF Matlab ToolboxDocument20 pagesSpectreRF Matlab ToolboxluminedinburghNo ratings yet
- Introduction to Video Game Engine Development: Learn to Design, Implement, and Use a Cross-Platform 2D Game EngineFrom EverandIntroduction to Video Game Engine Development: Learn to Design, Implement, and Use a Cross-Platform 2D Game EngineNo ratings yet
- Thameslink Route Map gg433g34g34gDocument44 pagesThameslink Route Map gg433g34g34grastamanrmNo ratings yet
- Topic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)Document25 pagesTopic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)rastamanrmNo ratings yet
- A Tour of The Oil Industry - KaggleDocument19 pagesA Tour of The Oil Industry - KagglerastamanrmNo ratings yet
- The Simulation and Analysis of Sand Erosion For Base Management PracticesDocument7 pagesThe Simulation and Analysis of Sand Erosion For Base Management PracticesrastamanrmNo ratings yet
- Kekra-01 220119Document8 pagesKekra-01 220119rastamanrmNo ratings yet
- DocumentgagaDocument6 pagesDocumentgagarastamanrmNo ratings yet
- 3005-G016 Transport Processes Problem Sheet 2012Document1 page3005-G016 Transport Processes Problem Sheet 2012rastamanrmNo ratings yet
- OkoDocument1 pageOkorastamanrmNo ratings yet
- Chemical Engineering ObjectiveDocument3 pagesChemical Engineering ObjectiverastamanrmNo ratings yet
- Modern Science and Vedic Science: by David Frawley (Vamadeva Shastri)Document8 pagesModern Science and Vedic Science: by David Frawley (Vamadeva Shastri)swami1423No ratings yet
- Chantika Putri: Junior AssociateDocument2 pagesChantika Putri: Junior AssociateParrjiyaklagaran tegesanNo ratings yet
- Commissioning Guide Integration Manual ZTEDocument75 pagesCommissioning Guide Integration Manual ZTEDavid MdevaNo ratings yet
- Famous Letters of Mahatma GandhiDocument146 pagesFamous Letters of Mahatma Gandhivishalnaidu2010No ratings yet
- Skip Morris Trout Fly Proportion ChartDocument3 pagesSkip Morris Trout Fly Proportion ChartScottDT1100% (1)
- Mas PrelimsDocument8 pagesMas PrelimsChristopher NogotNo ratings yet
- Valley Winery Case StudyDocument15 pagesValley Winery Case Studysarakhan0622No ratings yet
- Annexure ADocument1 pageAnnexure Atoocool_sashi100% (2)
- Book Decade SDocument555 pagesBook Decade STrey MaklerNo ratings yet
- CoC7 PC Sheet - Auto-Fill - Dark Ages - Standard - GreyscaleDocument3 pagesCoC7 PC Sheet - Auto-Fill - Dark Ages - Standard - GreyscaleClaudio da Silva Lima100% (1)
- Application of Geomatry in BusinessDocument23 pagesApplication of Geomatry in BusinessSoummo ChakmaNo ratings yet
- 01 Diabetes Mellitus Type2Document39 pages01 Diabetes Mellitus Type2Che HaniffNo ratings yet
- FLIRT Electrical Low-Floor Multiple-Unit Trains: For Železnice Srbije - Serbia's National Railway CompanyDocument2 pagesFLIRT Electrical Low-Floor Multiple-Unit Trains: For Železnice Srbije - Serbia's National Railway CompanyНикола ПетровићNo ratings yet
- 2018 MKTG Syllabus ValentiniDocument6 pages2018 MKTG Syllabus ValentiniJudeNo ratings yet
- Kemaro Island StoryDocument2 pagesKemaro Island StoryIstikomah Suci Lestari100% (1)
- Le CorbusierDocument21 pagesLe CorbusierAbhishek GandhiNo ratings yet
- The Saddest Day of My Life 2. The Saddest Day of My LifeDocument1 pageThe Saddest Day of My Life 2. The Saddest Day of My LifeAnnjen MuliNo ratings yet
- 01.worksheet-1 U1Document1 page01.worksheet-1 U1Jose Manuel AlcantaraNo ratings yet
- Maggi GorengDocument3 pagesMaggi GorengLeong KmNo ratings yet
- Chinchilla Cookie Recipe - LY ChinchillasDocument5 pagesChinchilla Cookie Recipe - LY ChinchillasSandy B GuzmánNo ratings yet
- OIPD in LinguisticsDocument7 pagesOIPD in LinguisticsBela AtthynaNo ratings yet
- A Study On Adoption of Digital Payment Through Mobile Payment Application With Reference To Gujarat StateDocument6 pagesA Study On Adoption of Digital Payment Through Mobile Payment Application With Reference To Gujarat StateEditor IJTSRDNo ratings yet
- Examiner Application FormDocument5 pagesExaminer Application FormKcaj WongNo ratings yet
- 09 Samss 107Document11 pages09 Samss 107YOUSUF KHANNo ratings yet
- Pe 3 First QuizDocument1 pagePe 3 First QuizLoremer Delos Santos LiboonNo ratings yet
- Annuncicom 100Document2 pagesAnnuncicom 100RamtelNo ratings yet
- UntitledDocument11 pagesUntitledNandoNo ratings yet



























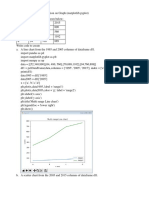






































































Download as pdf or txt
You might also like
- Dimitra Fimi. Tolkien, Race and Cultural History From Fairies ToDocument4 pagesDimitra Fimi. Tolkien, Race and Cultural History From Fairies Tomadeehamaqbool736250% (4)
- Python Matplotlib Data VisualizationDocument32 pagesPython Matplotlib Data VisualizationLakshit ManraoNo ratings yet
- Ravengro Expanded CompleteDocument10 pagesRavengro Expanded Completeitsme5616No ratings yet
- Stocks Data Analysis and Visualization Using Python AssignmentDocument4 pagesStocks Data Analysis and Visualization Using Python Assignmentbug myweeksNo ratings yet
- SAP BW Business Blueprint Step by Step GuideDocument33 pagesSAP BW Business Blueprint Step by Step Guidekavya.nori0% (1)
- Stock AnalysisDocument16 pagesStock AnalysisAbhisek KeshariNo ratings yet
- Deep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - CookbookDocument27 pagesDeep Learning For Predictive Maintenance - Artificial - Intelligence - For - Iot - Cookbookmahmoudahmed.rtaNo ratings yet
- Unit10 QB VHADocument36 pagesUnit10 QB VHAdaku5246No ratings yet
- Reading+6+ +Data+Visualization+CustomizationDocument30 pagesReading+6+ +Data+Visualization+CustomizationlussyNo ratings yet
- Unit10 - QB - Solution - Jupyter NotebookDocument33 pagesUnit10 - QB - Solution - Jupyter Notebookdaku5246No ratings yet
- CSC 335 Test 2 Review Sheet Followed by Practice TestDocument10 pagesCSC 335 Test 2 Review Sheet Followed by Practice Testtrass infotekNo ratings yet
- Linear Regression PDFDocument16 pagesLinear Regression PDFapi-540582672100% (1)
- Class 12 Informatics ProjectDocument16 pagesClass 12 Informatics ProjectJoshuaNo ratings yet
- Pair Trade For MatlabDocument4 pagesPair Trade For MatlabNukul SukuprakarnNo ratings yet
- Python Pandas MatplotDocument15 pagesPython Pandas MatplotRafay FarooqNo ratings yet
- LSTM Stock PredictionDocument38 pagesLSTM Stock PredictionKetan Ingale100% (1)
- Ch-4 Plotting Data Using MatplotlibDocument32 pagesCh-4 Plotting Data Using Matplotlibseemabhatia392No ratings yet
- Knitr ManualDocument11 pagesKnitr ManualRobin C DSNo ratings yet
- BDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Document10 pagesBDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Saleh ZulNo ratings yet
- Dynamic Memory Allocation and Dynamic Structures: Full ProgramDocument6 pagesDynamic Memory Allocation and Dynamic Structures: Full ProgramAntônio Eduardo CarvalhoNo ratings yet
- Dav Exp8 56Document4 pagesDav Exp8 56godizlatanNo ratings yet
- New Text DocumentDocument10 pagesNew Text DocumentdustboyNo ratings yet
- 5 Advanced Features of Pandas and How To Use ThemDocument10 pages5 Advanced Features of Pandas and How To Use ThemFecodNo ratings yet
- Linear Regression PTDocument16 pagesLinear Regression PTapi-540907926100% (1)
- Worksheet-1 (Python)Document9 pagesWorksheet-1 (Python)rizwana fathimaNo ratings yet
- Coding IntroductionDocument46 pagesCoding Introductionlijiayi2023666No ratings yet
- CS 103 Lab 8 - Stay Classy CS103: 4.1 (10 PTS.) Finishing The Implementation of WarDocument3 pagesCS 103 Lab 8 - Stay Classy CS103: 4.1 (10 PTS.) Finishing The Implementation of WarRahul Ranjan PradhanNo ratings yet
- Assignment 4 On Visualization On Graph With SolutionDocument14 pagesAssignment 4 On Visualization On Graph With Solutionvikas_2No ratings yet
- PythDocument38 pagesPythMinal JoshiNo ratings yet
- MatplotlibDocument7 pagesMatplotlibdbqatest001No ratings yet
- Advanced Stock Price Prediction Using Machine Learning and Time Series Analysis - by Nickolas Discolll - Dec, 2023 - MediumDocument38 pagesAdvanced Stock Price Prediction Using Machine Learning and Time Series Analysis - by Nickolas Discolll - Dec, 2023 - MediumchristhloNo ratings yet
- Knitr ManualDocument11 pagesKnitr ManualNonameNo ratings yet
- Advanced Recommender Systems With PythonDocument13 pagesAdvanced Recommender Systems With PythonFabian HafnerNo ratings yet
- MultigraphDocument4 pagesMultigraphkaivannshahNo ratings yet
- Plot Per Columns Features Kde or Normal Distribution Seaborn in DetailsDocument272 pagesPlot Per Columns Features Kde or Normal Distribution Seaborn in Detailsyousef shabanNo ratings yet
- Python CodeDocument7 pagesPython CodeGnan ShettyNo ratings yet
- Lab Manual: Multimedia Application DevelopmentDocument28 pagesLab Manual: Multimedia Application Developmentroja1901No ratings yet
- QB - 22ADS35 (Python For Data Science)Document6 pagesQB - 22ADS35 (Python For Data Science)Arvind ASNo ratings yet
- Stock AnalyzerDocument38 pagesStock AnalyzerEmon KabirNo ratings yet
- Seaweed 2 WorkbookDocument42 pagesSeaweed 2 WorkbookAnouar El HajiNo ratings yet
- Hands On Seaborn?Document57 pagesHands On Seaborn?pratik choudhariNo ratings yet
- Lesson2 DataframeDocument4 pagesLesson2 DataframeGustavo MartinoNo ratings yet
- Chapter 3Document51 pagesChapter 3Ingle AshwiniNo ratings yet
- HTML CodeDocument1 pageHTML CodeNavkaran SinghNo ratings yet
- Accessing and Working With Statsbomb Data in RDocument27 pagesAccessing and Working With Statsbomb Data in RTewfic SeidNo ratings yet
- Seaborne LibraryDocument65 pagesSeaborne LibraryRajaNo ratings yet
- Lesson3 AestheticsDocument3 pagesLesson3 AestheticsDikshaMantraNo ratings yet
- TDDB84 DesignPatterns Exam 2005 10 15 PDFDocument6 pagesTDDB84 DesignPatterns Exam 2005 10 15 PDFponniNo ratings yet
- Financial Analytics With PythonDocument40 pagesFinancial Analytics With PythonHarshit Singh100% (1)
- Bqplot Documentation: Release 0.10.0Document97 pagesBqplot Documentation: Release 0.10.0Swastik MishraNo ratings yet
- Pierian Data - Python For Finance & Algorithmic Trading Course NotesDocument11 pagesPierian Data - Python For Finance & Algorithmic Trading Course NotesIshan SaneNo ratings yet
- CS211 Fall 2002 P4Document7 pagesCS211 Fall 2002 P4Nikhil VarandaniNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Atariarcade SDK Quick-Start GuideDocument8 pagesAtariarcade SDK Quick-Start GuideJuan P Arbeláez RNo ratings yet
- Let Your Data SPEAK: 1.1 What Can Visualization Be Used For?Document8 pagesLet Your Data SPEAK: 1.1 What Can Visualization Be Used For?Nelson LozanoNo ratings yet
- FALLSEM2021-22 MAT2001 ELA VL2021220102174 Reference Material III 03-Aug-2021 Basic Graphics in RDocument15 pagesFALLSEM2021-22 MAT2001 ELA VL2021220102174 Reference Material III 03-Aug-2021 Basic Graphics in RAswin MMNo ratings yet
- Reporting ToolsDocument30 pagesReporting ToolsEmon KabirNo ratings yet
- Week 4 Project - Adversarial Search and Games - CSMMDocument9 pagesWeek 4 Project - Adversarial Search and Games - CSMMRaj kumar manepallyNo ratings yet
- Dungeon Siege Game GuideDocument21 pagesDungeon Siege Game GuideJesse StillNo ratings yet
- Dash IntroDocument18 pagesDash IntroTan ChNo ratings yet
- Introduction To Data Visualization in PythonDocument16 pagesIntroduction To Data Visualization in PythonudayNo ratings yet
- SpectreRF Matlab ToolboxDocument20 pagesSpectreRF Matlab ToolboxluminedinburghNo ratings yet
- Introduction to Video Game Engine Development: Learn to Design, Implement, and Use a Cross-Platform 2D Game EngineFrom EverandIntroduction to Video Game Engine Development: Learn to Design, Implement, and Use a Cross-Platform 2D Game EngineNo ratings yet
- Thameslink Route Map gg433g34g34gDocument44 pagesThameslink Route Map gg433g34g34grastamanrmNo ratings yet
- Topic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)Document25 pagesTopic 2. Visual Data Analysis in Python: Mlcourse - Ai (Https://mlcourse - Ai)rastamanrmNo ratings yet
- A Tour of The Oil Industry - KaggleDocument19 pagesA Tour of The Oil Industry - KagglerastamanrmNo ratings yet
- The Simulation and Analysis of Sand Erosion For Base Management PracticesDocument7 pagesThe Simulation and Analysis of Sand Erosion For Base Management PracticesrastamanrmNo ratings yet
- Kekra-01 220119Document8 pagesKekra-01 220119rastamanrmNo ratings yet
- DocumentgagaDocument6 pagesDocumentgagarastamanrmNo ratings yet
- 3005-G016 Transport Processes Problem Sheet 2012Document1 page3005-G016 Transport Processes Problem Sheet 2012rastamanrmNo ratings yet
- OkoDocument1 pageOkorastamanrmNo ratings yet
- Chemical Engineering ObjectiveDocument3 pagesChemical Engineering ObjectiverastamanrmNo ratings yet
- Modern Science and Vedic Science: by David Frawley (Vamadeva Shastri)Document8 pagesModern Science and Vedic Science: by David Frawley (Vamadeva Shastri)swami1423No ratings yet
- Chantika Putri: Junior AssociateDocument2 pagesChantika Putri: Junior AssociateParrjiyaklagaran tegesanNo ratings yet
- Commissioning Guide Integration Manual ZTEDocument75 pagesCommissioning Guide Integration Manual ZTEDavid MdevaNo ratings yet
- Famous Letters of Mahatma GandhiDocument146 pagesFamous Letters of Mahatma Gandhivishalnaidu2010No ratings yet
- Skip Morris Trout Fly Proportion ChartDocument3 pagesSkip Morris Trout Fly Proportion ChartScottDT1100% (1)
- Mas PrelimsDocument8 pagesMas PrelimsChristopher NogotNo ratings yet
- Valley Winery Case StudyDocument15 pagesValley Winery Case Studysarakhan0622No ratings yet
- Annexure ADocument1 pageAnnexure Atoocool_sashi100% (2)
- Book Decade SDocument555 pagesBook Decade STrey MaklerNo ratings yet
- CoC7 PC Sheet - Auto-Fill - Dark Ages - Standard - GreyscaleDocument3 pagesCoC7 PC Sheet - Auto-Fill - Dark Ages - Standard - GreyscaleClaudio da Silva Lima100% (1)
- Application of Geomatry in BusinessDocument23 pagesApplication of Geomatry in BusinessSoummo ChakmaNo ratings yet
- 01 Diabetes Mellitus Type2Document39 pages01 Diabetes Mellitus Type2Che HaniffNo ratings yet
- FLIRT Electrical Low-Floor Multiple-Unit Trains: For Železnice Srbije - Serbia's National Railway CompanyDocument2 pagesFLIRT Electrical Low-Floor Multiple-Unit Trains: For Železnice Srbije - Serbia's National Railway CompanyНикола ПетровићNo ratings yet
- 2018 MKTG Syllabus ValentiniDocument6 pages2018 MKTG Syllabus ValentiniJudeNo ratings yet
- Kemaro Island StoryDocument2 pagesKemaro Island StoryIstikomah Suci Lestari100% (1)
- Le CorbusierDocument21 pagesLe CorbusierAbhishek GandhiNo ratings yet
- The Saddest Day of My Life 2. The Saddest Day of My LifeDocument1 pageThe Saddest Day of My Life 2. The Saddest Day of My LifeAnnjen MuliNo ratings yet
- 01.worksheet-1 U1Document1 page01.worksheet-1 U1Jose Manuel AlcantaraNo ratings yet
- Maggi GorengDocument3 pagesMaggi GorengLeong KmNo ratings yet
- Chinchilla Cookie Recipe - LY ChinchillasDocument5 pagesChinchilla Cookie Recipe - LY ChinchillasSandy B GuzmánNo ratings yet
- OIPD in LinguisticsDocument7 pagesOIPD in LinguisticsBela AtthynaNo ratings yet
- A Study On Adoption of Digital Payment Through Mobile Payment Application With Reference To Gujarat StateDocument6 pagesA Study On Adoption of Digital Payment Through Mobile Payment Application With Reference To Gujarat StateEditor IJTSRDNo ratings yet
- Examiner Application FormDocument5 pagesExaminer Application FormKcaj WongNo ratings yet
- 09 Samss 107Document11 pages09 Samss 107YOUSUF KHANNo ratings yet
- Pe 3 First QuizDocument1 pagePe 3 First QuizLoremer Delos Santos LiboonNo ratings yet
- Annuncicom 100Document2 pagesAnnuncicom 100RamtelNo ratings yet
- UntitledDocument11 pagesUntitledNandoNo ratings yet