
Hill Climbing Search-1
Hill Climbing Search-1
You might also like
- Precalculus Mathematics For Calculus 7th Edition Stewart Redlin Watson Test BankDocument41 pagesPrecalculus Mathematics For Calculus 7th Edition Stewart Redlin Watson Test Bankpaul97% (29)
- 151 Exam 1 Review AU10Document3 pages151 Exam 1 Review AU10Nathan W. SerafiniNo ratings yet
- Alg1 08 Student JournalDocument31 pagesAlg1 08 Student Journalapi-355730898No ratings yet
- Fin118 Unit 3Document27 pagesFin118 Unit 3ayadi_ezer6795No ratings yet
- X +32 To Find The Temperature in Fahrenheit If It Is 5 Degrees CelsiusDocument3 pagesX +32 To Find The Temperature in Fahrenheit If It Is 5 Degrees CelsiuswilliammezaNo ratings yet
- Chapitre 2Document80 pagesChapitre 2Chaima BelhediNo ratings yet
- How To Classify DiscontinuitiesDocument23 pagesHow To Classify Discontinuitiesmohammed hassanNo ratings yet
- Gen MathDocument8 pagesGen MathHershell ContaNo ratings yet
- Applications of DerivativesDocument10 pagesApplications of DerivativesRana JahanzaibNo ratings yet
- Basic Calculus: Quarter 1 - Module 3Document20 pagesBasic Calculus: Quarter 1 - Module 3Angelie Limbago CagasNo ratings yet
- Read and Answer Each Item Carefully, Follow Every InstructionDocument2 pagesRead and Answer Each Item Carefully, Follow Every InstructionJerwin GritNo ratings yet
- Instant Download PDF Thomas Calculus 13th Edition Thomas Solutions Manual Full ChapterDocument114 pagesInstant Download PDF Thomas Calculus 13th Edition Thomas Solutions Manual Full Chapterjemuelsadgir100% (3)
- NM Lab Report 2 (18-EE-095 & 141)Document6 pagesNM Lab Report 2 (18-EE-095 & 141)Ratas KhanNo ratings yet
- 2012-11-19 Constant Multiple and Addition Rules For DerivativesDocument6 pages2012-11-19 Constant Multiple and Addition Rules For DerivativessamjshahNo ratings yet
- General Mathematics Performance Task - Q1 - W1-W4Document5 pagesGeneral Mathematics Performance Task - Q1 - W1-W4Rhoda May Bermejo TrompetaNo ratings yet
- Exam 2 Review MATHDocument3 pagesExam 2 Review MATHwilliammezaNo ratings yet
- Summative Test in General MathematicsDocument3 pagesSummative Test in General MathematicsEmelyn V. Cudapas100% (2)
- Flow MapDocument6 pagesFlow MapMonica RiveraNo ratings yet
- Grade 11 Gen. Math Modules W1-3Document19 pagesGrade 11 Gen. Math Modules W1-3Encluna Lindon JayNo ratings yet
- General Math SHS Module 1Document12 pagesGeneral Math SHS Module 1Kristian IanNo ratings yet
- Test Bank For Precalculus Mathematics For Calculus 7Th Edition Stewart Redlin Watson 1305071751 9781305071759 Full Chapter PDFDocument36 pagesTest Bank For Precalculus Mathematics For Calculus 7Th Edition Stewart Redlin Watson 1305071751 9781305071759 Full Chapter PDFrobert.huff822100% (12)
- 1asn SLNDocument2 pages1asn SLNDaniel OhNo ratings yet
- E-6 Curve Sketching Summary: Example 1 Complete The 8 Steps To Sketch The Graph of F (X) XDocument6 pagesE-6 Curve Sketching Summary: Example 1 Complete The 8 Steps To Sketch The Graph of F (X) XMart TialNo ratings yet
- Math T 2Document13 pagesMath T 2Sarman TamilselvanNo ratings yet
- 2012-02-15 Shape of A Graph, IntroductionDocument8 pages2012-02-15 Shape of A Graph, IntroductionSam Shah100% (1)
- Learning Module: Malasiqui Catholic School, IncDocument11 pagesLearning Module: Malasiqui Catholic School, IncAnazthazia AshannaNo ratings yet
- 4th Quarter-PBADocument12 pages4th Quarter-PBAerinclareburkeNo ratings yet
- Chapter Test FunctionsDocument8 pagesChapter Test FunctionsRanns Meldrik SantosNo ratings yet
- Basic Calculus Week 1Document42 pagesBasic Calculus Week 1Princess DeramasNo ratings yet
- STK121 SUT 1.2.2 Derivative 4-Step (2021)Document14 pagesSTK121 SUT 1.2.2 Derivative 4-Step (2021)winesession101No ratings yet
- CALCULUS & ANALYTIAL GEOMETRY Chapter#02Document23 pagesCALCULUS & ANALYTIAL GEOMETRY Chapter#02syeda zainabNo ratings yet
- TRIAL MODE: Practice Exercises Activity 1: Understanding One-To-One FunctionsDocument9 pagesTRIAL MODE: Practice Exercises Activity 1: Understanding One-To-One FunctionselleeNo ratings yet
- Calculus & Analytial Geometry Chapter#02Document23 pagesCalculus & Analytial Geometry Chapter#02syeda zainabNo ratings yet
- Math 203 Quiz I Fall 2018-19 v1 2Document7 pagesMath 203 Quiz I Fall 2018-19 v1 2k2ykbg4t4sNo ratings yet
- PROBLEM SET General MathematicsDocument18 pagesPROBLEM SET General Mathematicsallyn jhonNo ratings yet
- Exs PDFDocument8 pagesExs PDFHenry DunaNo ratings yet
- Gen MathDocument7 pagesGen MathLaiza baldado TagacNo ratings yet
- Graphing Quadratic Functions 5Document3 pagesGraphing Quadratic Functions 5Ricardo GarciaNo ratings yet
- 8 Shape of Graphs-To-PostDocument4 pages8 Shape of Graphs-To-Postsamantha davidsonNo ratings yet
- Lesson-4 STATISTICS AND PROBABILITYDocument25 pagesLesson-4 STATISTICS AND PROBABILITYMishe AlmedillaNo ratings yet
- 3-Linear Equations Examples With Solutions PDF Notes For All ExamsDocument7 pages3-Linear Equations Examples With Solutions PDF Notes For All ExamsWork SpaceNo ratings yet
- Section 2.2 Quadratic FunctionsDocument30 pagesSection 2.2 Quadratic FunctionsdavogezuNo ratings yet
- Graphing Exponential Funtion and TransformationDocument72 pagesGraphing Exponential Funtion and TransformationSyril Gabrielle BelaguinNo ratings yet
- Kami Export - Johanna Martinez - Int 3 4.6 ExplorationDocument2 pagesKami Export - Johanna Martinez - Int 3 4.6 ExplorationJohanna MartinezNo ratings yet
- A4 LinearEquations BP 9 22 14Document5 pagesA4 LinearEquations BP 9 22 14Rey Xander Capio100% (1)
- Dwnload Full Precalculus Graphical Numerical Algebraic 8th Edition Demana Solutions Manual PDFDocument30 pagesDwnload Full Precalculus Graphical Numerical Algebraic 8th Edition Demana Solutions Manual PDFunpickspermicus8d100% (10)
- Lesson Plan in Statistics and ProbabilityDocument2 pagesLesson Plan in Statistics and Probabilitynovellie gantalaNo ratings yet
- Problem Set 8 Solutions PDFDocument21 pagesProblem Set 8 Solutions PDFfrancis_tsk1No ratings yet
- 4ACh02 (Functions and Graphs)Document31 pages4ACh02 (Functions and Graphs)api-19856023No ratings yet
- Supplement111 112Document31 pagesSupplement111 112okolieperpetuaNo ratings yet
- GM - W1-4 (Activity)Document11 pagesGM - W1-4 (Activity)Jhezza Mae Coraza TeroNo ratings yet
- 28 Continuity & Diffrentiability Part 1 of 1Document23 pages28 Continuity & Diffrentiability Part 1 of 1Mehul JainNo ratings yet
- Math 151-016 Exam2 Graf Fa14 UmbcDocument8 pagesMath 151-016 Exam2 Graf Fa14 UmbcUMBCCalculusNo ratings yet
- 2.2 A2 2017 Unit 2-2 WS Packet LG PDFDocument37 pages2.2 A2 2017 Unit 2-2 WS Packet LG PDFAngelicaNo ratings yet
- Bisection Method: Laboratory Activity No. 4Document13 pagesBisection Method: Laboratory Activity No. 4JOSEFCARLMIKHAIL GEMINIANONo ratings yet
- EgricizimiDocument13 pagesEgricizimiBarış DuranNo ratings yet
- Lesson 4.2 Exponential Function of The Form A Greater Than 0.Document3 pagesLesson 4.2 Exponential Function of The Form A Greater Than 0.Midoriya IzukuNo ratings yet
- Lecture 04Document4 pagesLecture 04Marwa QuadoosNo ratings yet
- Exam Set 1Document3 pagesExam Set 1jjgjocsonNo ratings yet
- Differentiation (Calculus) Mathematics Question BankFrom EverandDifferentiation (Calculus) Mathematics Question BankRating: 4 out of 5 stars4/5 (1)
- Cloud Computing IIDocument6 pagesCloud Computing IIGauravNo ratings yet
- Lecture 1 (Notes) : Confusion & DiffusionDocument5 pagesLecture 1 (Notes) : Confusion & DiffusionGauravNo ratings yet
- BSC III CS Paper II ComputerNetworks 2011 PDFDocument4 pagesBSC III CS Paper II ComputerNetworks 2011 PDFGauravNo ratings yet
- Best First SearchDocument5 pagesBest First SearchGauravNo ratings yet
- Assignment On Unit I and IIDocument1 pageAssignment On Unit I and IIGauravNo ratings yet
- Testbank Financial Management Finance 301Document60 pagesTestbank Financial Management Finance 301منیر ساداتNo ratings yet
- SPM Biology NotesDocument32 pagesSPM Biology NotesAin Fza0% (1)
- Somalia's Federal Parliament Elects Speakers, Deputy SpeakersDocument3 pagesSomalia's Federal Parliament Elects Speakers, Deputy SpeakersAMISOM Public Information ServicesNo ratings yet
- Round Shapes and Square Shapes Representation of ShapesDocument8 pagesRound Shapes and Square Shapes Representation of ShapeselmoNo ratings yet
- Raz Lf35 WhereiscubDocument12 pagesRaz Lf35 WhereiscubHà Lê ThuNo ratings yet
- International Trade LawDocument30 pagesInternational Trade LawVeer Vikram SinghNo ratings yet
- Admiralty LawDocument576 pagesAdmiralty LawRihardsNo ratings yet
- Presentation Anisa AgitaDocument15 pagesPresentation Anisa AgitaJhangir DesfrandantaNo ratings yet
- Manaloto Vs VelosoDocument11 pagesManaloto Vs VelosocessyJDNo ratings yet
- Aditing II Q From CH 3,4,5Document2 pagesAditing II Q From CH 3,4,5samuel debebeNo ratings yet
- UntitledDocument68 pagesUntitledoutdash2No ratings yet
- Like Father Like SonDocument8 pagesLike Father Like Sonnisemononamae7990No ratings yet
- The Marketing Management Process: Mcgraw-Hill/IrwinDocument37 pagesThe Marketing Management Process: Mcgraw-Hill/Irwinmuhammad yusufNo ratings yet
- Fairchild V.glenhaven Funeral Services LTDDocument9 pagesFairchild V.glenhaven Funeral Services LTDSwastik SinghNo ratings yet
- Author Literally Writes The Book On Band NerdsDocument3 pagesAuthor Literally Writes The Book On Band NerdsPR.comNo ratings yet
- Stat 1010Document205 pagesStat 1010Jazz Jhasveer0% (1)
- Chapter 2-Ethics Matters: Understanding The Ethics of Public SpeakingDocument40 pagesChapter 2-Ethics Matters: Understanding The Ethics of Public Speakingshenny sitindjakNo ratings yet
- Auditing Quiz - Accepting The Engagement and Planning The AuditDocument11 pagesAuditing Quiz - Accepting The Engagement and Planning The AuditMarie Lichelle AureusNo ratings yet
- Maggi - Marketing ManagementDocument26 pagesMaggi - Marketing ManagementAyushBisht100% (2)
- Understanding The Parables of JesusDocument7 pagesUnderstanding The Parables of JesusRaul PostranoNo ratings yet
- Senior Manager Sales CPG in USA Resume T Gill FuquaDocument3 pagesSenior Manager Sales CPG in USA Resume T Gill FuquaTGillFuquaNo ratings yet
- La Tolérance Et Ses Limites: Un Problème Pour L'ÉducateurDocument7 pagesLa Tolérance Et Ses Limites: Un Problème Pour L'ÉducateurFatima EL FasihiNo ratings yet
- Acquaintance Party - MessageDocument3 pagesAcquaintance Party - MessageMerly RepunteNo ratings yet
- Mathematics As A Tool: Data ManagementDocument29 pagesMathematics As A Tool: Data ManagementJayson Delos SantosNo ratings yet
- Principles 1Document13 pagesPrinciples 1RicaNo ratings yet
- The Seed of The Banyan TreeDocument3 pagesThe Seed of The Banyan Treejuan pablo mejiaNo ratings yet
- Self Assessment Sheet by VendorDocument60 pagesSelf Assessment Sheet by VendorAjayNo ratings yet
- A Feasibility Study in Manufacturing of Pro-TechDocument44 pagesA Feasibility Study in Manufacturing of Pro-TechXyRen GremoryNo ratings yet
- Index Construction MethodologyDocument6 pagesIndex Construction MethodologyBadhandasNo ratings yet
- Arduino Cheat SheetDocument1 pageArduino Cheat SheetCristian A. TisseraNo ratings yet
























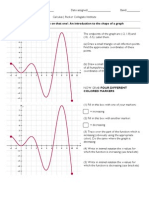


















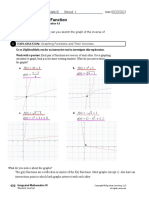




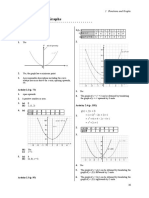














































Download as pdf or txt
You might also like
- Precalculus Mathematics For Calculus 7th Edition Stewart Redlin Watson Test BankDocument41 pagesPrecalculus Mathematics For Calculus 7th Edition Stewart Redlin Watson Test Bankpaul97% (29)
- 151 Exam 1 Review AU10Document3 pages151 Exam 1 Review AU10Nathan W. SerafiniNo ratings yet
- Alg1 08 Student JournalDocument31 pagesAlg1 08 Student Journalapi-355730898No ratings yet
- Fin118 Unit 3Document27 pagesFin118 Unit 3ayadi_ezer6795No ratings yet
- X +32 To Find The Temperature in Fahrenheit If It Is 5 Degrees CelsiusDocument3 pagesX +32 To Find The Temperature in Fahrenheit If It Is 5 Degrees CelsiuswilliammezaNo ratings yet
- Chapitre 2Document80 pagesChapitre 2Chaima BelhediNo ratings yet
- How To Classify DiscontinuitiesDocument23 pagesHow To Classify Discontinuitiesmohammed hassanNo ratings yet
- Gen MathDocument8 pagesGen MathHershell ContaNo ratings yet
- Applications of DerivativesDocument10 pagesApplications of DerivativesRana JahanzaibNo ratings yet
- Basic Calculus: Quarter 1 - Module 3Document20 pagesBasic Calculus: Quarter 1 - Module 3Angelie Limbago CagasNo ratings yet
- Read and Answer Each Item Carefully, Follow Every InstructionDocument2 pagesRead and Answer Each Item Carefully, Follow Every InstructionJerwin GritNo ratings yet
- Instant Download PDF Thomas Calculus 13th Edition Thomas Solutions Manual Full ChapterDocument114 pagesInstant Download PDF Thomas Calculus 13th Edition Thomas Solutions Manual Full Chapterjemuelsadgir100% (3)
- NM Lab Report 2 (18-EE-095 & 141)Document6 pagesNM Lab Report 2 (18-EE-095 & 141)Ratas KhanNo ratings yet
- 2012-11-19 Constant Multiple and Addition Rules For DerivativesDocument6 pages2012-11-19 Constant Multiple and Addition Rules For DerivativessamjshahNo ratings yet
- General Mathematics Performance Task - Q1 - W1-W4Document5 pagesGeneral Mathematics Performance Task - Q1 - W1-W4Rhoda May Bermejo TrompetaNo ratings yet
- Exam 2 Review MATHDocument3 pagesExam 2 Review MATHwilliammezaNo ratings yet
- Summative Test in General MathematicsDocument3 pagesSummative Test in General MathematicsEmelyn V. Cudapas100% (2)
- Flow MapDocument6 pagesFlow MapMonica RiveraNo ratings yet
- Grade 11 Gen. Math Modules W1-3Document19 pagesGrade 11 Gen. Math Modules W1-3Encluna Lindon JayNo ratings yet
- General Math SHS Module 1Document12 pagesGeneral Math SHS Module 1Kristian IanNo ratings yet
- Test Bank For Precalculus Mathematics For Calculus 7Th Edition Stewart Redlin Watson 1305071751 9781305071759 Full Chapter PDFDocument36 pagesTest Bank For Precalculus Mathematics For Calculus 7Th Edition Stewart Redlin Watson 1305071751 9781305071759 Full Chapter PDFrobert.huff822100% (12)
- 1asn SLNDocument2 pages1asn SLNDaniel OhNo ratings yet
- E-6 Curve Sketching Summary: Example 1 Complete The 8 Steps To Sketch The Graph of F (X) XDocument6 pagesE-6 Curve Sketching Summary: Example 1 Complete The 8 Steps To Sketch The Graph of F (X) XMart TialNo ratings yet
- Math T 2Document13 pagesMath T 2Sarman TamilselvanNo ratings yet
- 2012-02-15 Shape of A Graph, IntroductionDocument8 pages2012-02-15 Shape of A Graph, IntroductionSam Shah100% (1)
- Learning Module: Malasiqui Catholic School, IncDocument11 pagesLearning Module: Malasiqui Catholic School, IncAnazthazia AshannaNo ratings yet
- 4th Quarter-PBADocument12 pages4th Quarter-PBAerinclareburkeNo ratings yet
- Chapter Test FunctionsDocument8 pagesChapter Test FunctionsRanns Meldrik SantosNo ratings yet
- Basic Calculus Week 1Document42 pagesBasic Calculus Week 1Princess DeramasNo ratings yet
- STK121 SUT 1.2.2 Derivative 4-Step (2021)Document14 pagesSTK121 SUT 1.2.2 Derivative 4-Step (2021)winesession101No ratings yet
- CALCULUS & ANALYTIAL GEOMETRY Chapter#02Document23 pagesCALCULUS & ANALYTIAL GEOMETRY Chapter#02syeda zainabNo ratings yet
- TRIAL MODE: Practice Exercises Activity 1: Understanding One-To-One FunctionsDocument9 pagesTRIAL MODE: Practice Exercises Activity 1: Understanding One-To-One FunctionselleeNo ratings yet
- Calculus & Analytial Geometry Chapter#02Document23 pagesCalculus & Analytial Geometry Chapter#02syeda zainabNo ratings yet
- Math 203 Quiz I Fall 2018-19 v1 2Document7 pagesMath 203 Quiz I Fall 2018-19 v1 2k2ykbg4t4sNo ratings yet
- PROBLEM SET General MathematicsDocument18 pagesPROBLEM SET General Mathematicsallyn jhonNo ratings yet
- Exs PDFDocument8 pagesExs PDFHenry DunaNo ratings yet
- Gen MathDocument7 pagesGen MathLaiza baldado TagacNo ratings yet
- Graphing Quadratic Functions 5Document3 pagesGraphing Quadratic Functions 5Ricardo GarciaNo ratings yet
- 8 Shape of Graphs-To-PostDocument4 pages8 Shape of Graphs-To-Postsamantha davidsonNo ratings yet
- Lesson-4 STATISTICS AND PROBABILITYDocument25 pagesLesson-4 STATISTICS AND PROBABILITYMishe AlmedillaNo ratings yet
- 3-Linear Equations Examples With Solutions PDF Notes For All ExamsDocument7 pages3-Linear Equations Examples With Solutions PDF Notes For All ExamsWork SpaceNo ratings yet
- Section 2.2 Quadratic FunctionsDocument30 pagesSection 2.2 Quadratic FunctionsdavogezuNo ratings yet
- Graphing Exponential Funtion and TransformationDocument72 pagesGraphing Exponential Funtion and TransformationSyril Gabrielle BelaguinNo ratings yet
- Kami Export - Johanna Martinez - Int 3 4.6 ExplorationDocument2 pagesKami Export - Johanna Martinez - Int 3 4.6 ExplorationJohanna MartinezNo ratings yet
- A4 LinearEquations BP 9 22 14Document5 pagesA4 LinearEquations BP 9 22 14Rey Xander Capio100% (1)
- Dwnload Full Precalculus Graphical Numerical Algebraic 8th Edition Demana Solutions Manual PDFDocument30 pagesDwnload Full Precalculus Graphical Numerical Algebraic 8th Edition Demana Solutions Manual PDFunpickspermicus8d100% (10)
- Lesson Plan in Statistics and ProbabilityDocument2 pagesLesson Plan in Statistics and Probabilitynovellie gantalaNo ratings yet
- Problem Set 8 Solutions PDFDocument21 pagesProblem Set 8 Solutions PDFfrancis_tsk1No ratings yet
- 4ACh02 (Functions and Graphs)Document31 pages4ACh02 (Functions and Graphs)api-19856023No ratings yet
- Supplement111 112Document31 pagesSupplement111 112okolieperpetuaNo ratings yet
- GM - W1-4 (Activity)Document11 pagesGM - W1-4 (Activity)Jhezza Mae Coraza TeroNo ratings yet
- 28 Continuity & Diffrentiability Part 1 of 1Document23 pages28 Continuity & Diffrentiability Part 1 of 1Mehul JainNo ratings yet
- Math 151-016 Exam2 Graf Fa14 UmbcDocument8 pagesMath 151-016 Exam2 Graf Fa14 UmbcUMBCCalculusNo ratings yet
- 2.2 A2 2017 Unit 2-2 WS Packet LG PDFDocument37 pages2.2 A2 2017 Unit 2-2 WS Packet LG PDFAngelicaNo ratings yet
- Bisection Method: Laboratory Activity No. 4Document13 pagesBisection Method: Laboratory Activity No. 4JOSEFCARLMIKHAIL GEMINIANONo ratings yet
- EgricizimiDocument13 pagesEgricizimiBarış DuranNo ratings yet
- Lesson 4.2 Exponential Function of The Form A Greater Than 0.Document3 pagesLesson 4.2 Exponential Function of The Form A Greater Than 0.Midoriya IzukuNo ratings yet
- Lecture 04Document4 pagesLecture 04Marwa QuadoosNo ratings yet
- Exam Set 1Document3 pagesExam Set 1jjgjocsonNo ratings yet
- Differentiation (Calculus) Mathematics Question BankFrom EverandDifferentiation (Calculus) Mathematics Question BankRating: 4 out of 5 stars4/5 (1)
- Cloud Computing IIDocument6 pagesCloud Computing IIGauravNo ratings yet
- Lecture 1 (Notes) : Confusion & DiffusionDocument5 pagesLecture 1 (Notes) : Confusion & DiffusionGauravNo ratings yet
- BSC III CS Paper II ComputerNetworks 2011 PDFDocument4 pagesBSC III CS Paper II ComputerNetworks 2011 PDFGauravNo ratings yet
- Best First SearchDocument5 pagesBest First SearchGauravNo ratings yet
- Assignment On Unit I and IIDocument1 pageAssignment On Unit I and IIGauravNo ratings yet
- Testbank Financial Management Finance 301Document60 pagesTestbank Financial Management Finance 301منیر ساداتNo ratings yet
- SPM Biology NotesDocument32 pagesSPM Biology NotesAin Fza0% (1)
- Somalia's Federal Parliament Elects Speakers, Deputy SpeakersDocument3 pagesSomalia's Federal Parliament Elects Speakers, Deputy SpeakersAMISOM Public Information ServicesNo ratings yet
- Round Shapes and Square Shapes Representation of ShapesDocument8 pagesRound Shapes and Square Shapes Representation of ShapeselmoNo ratings yet
- Raz Lf35 WhereiscubDocument12 pagesRaz Lf35 WhereiscubHà Lê ThuNo ratings yet
- International Trade LawDocument30 pagesInternational Trade LawVeer Vikram SinghNo ratings yet
- Admiralty LawDocument576 pagesAdmiralty LawRihardsNo ratings yet
- Presentation Anisa AgitaDocument15 pagesPresentation Anisa AgitaJhangir DesfrandantaNo ratings yet
- Manaloto Vs VelosoDocument11 pagesManaloto Vs VelosocessyJDNo ratings yet
- Aditing II Q From CH 3,4,5Document2 pagesAditing II Q From CH 3,4,5samuel debebeNo ratings yet
- UntitledDocument68 pagesUntitledoutdash2No ratings yet
- Like Father Like SonDocument8 pagesLike Father Like Sonnisemononamae7990No ratings yet
- The Marketing Management Process: Mcgraw-Hill/IrwinDocument37 pagesThe Marketing Management Process: Mcgraw-Hill/Irwinmuhammad yusufNo ratings yet
- Fairchild V.glenhaven Funeral Services LTDDocument9 pagesFairchild V.glenhaven Funeral Services LTDSwastik SinghNo ratings yet
- Author Literally Writes The Book On Band NerdsDocument3 pagesAuthor Literally Writes The Book On Band NerdsPR.comNo ratings yet
- Stat 1010Document205 pagesStat 1010Jazz Jhasveer0% (1)
- Chapter 2-Ethics Matters: Understanding The Ethics of Public SpeakingDocument40 pagesChapter 2-Ethics Matters: Understanding The Ethics of Public Speakingshenny sitindjakNo ratings yet
- Auditing Quiz - Accepting The Engagement and Planning The AuditDocument11 pagesAuditing Quiz - Accepting The Engagement and Planning The AuditMarie Lichelle AureusNo ratings yet
- Maggi - Marketing ManagementDocument26 pagesMaggi - Marketing ManagementAyushBisht100% (2)
- Understanding The Parables of JesusDocument7 pagesUnderstanding The Parables of JesusRaul PostranoNo ratings yet
- Senior Manager Sales CPG in USA Resume T Gill FuquaDocument3 pagesSenior Manager Sales CPG in USA Resume T Gill FuquaTGillFuquaNo ratings yet
- La Tolérance Et Ses Limites: Un Problème Pour L'ÉducateurDocument7 pagesLa Tolérance Et Ses Limites: Un Problème Pour L'ÉducateurFatima EL FasihiNo ratings yet
- Acquaintance Party - MessageDocument3 pagesAcquaintance Party - MessageMerly RepunteNo ratings yet
- Mathematics As A Tool: Data ManagementDocument29 pagesMathematics As A Tool: Data ManagementJayson Delos SantosNo ratings yet
- Principles 1Document13 pagesPrinciples 1RicaNo ratings yet
- The Seed of The Banyan TreeDocument3 pagesThe Seed of The Banyan Treejuan pablo mejiaNo ratings yet
- Self Assessment Sheet by VendorDocument60 pagesSelf Assessment Sheet by VendorAjayNo ratings yet
- A Feasibility Study in Manufacturing of Pro-TechDocument44 pagesA Feasibility Study in Manufacturing of Pro-TechXyRen GremoryNo ratings yet
- Index Construction MethodologyDocument6 pagesIndex Construction MethodologyBadhandasNo ratings yet
- Arduino Cheat SheetDocument1 pageArduino Cheat SheetCristian A. TisseraNo ratings yet