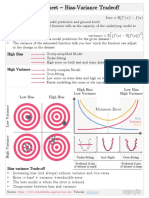
Download as pdf or txt
You might also like
- Machine Learning Week 2 CourseraDocument4 pagesMachine Learning Week 2 CourseraHương Đặng100% (1)
- Machine Learning Cheat Sheet PDFDocument15 pagesMachine Learning Cheat Sheet PDFgalagrandNo ratings yet
- Deployment: Cheat Sheet: Machine Learning With KNIME Analytics PlatformDocument2 pagesDeployment: Cheat Sheet: Machine Learning With KNIME Analytics PlatformIzan IzwanNo ratings yet
- Docs Slides Lecture11Document18 pagesDocs Slides Lecture11Irham DodotNo ratings yet
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- Rapid MinerDocument11 pagesRapid MinerNeha BhuptaniNo ratings yet
- Marketing Mix v5Document38 pagesMarketing Mix v5caldevilla515No ratings yet
- At The Forefront of Smart Data Marketing: ISSUE No.2 - 2019Document60 pagesAt The Forefront of Smart Data Marketing: ISSUE No.2 - 2019kekeNo ratings yet
- Error Control Systems For Digital Communication and Storage (Stephen B. Wicker)Document268 pagesError Control Systems For Digital Communication and Storage (Stephen B. Wicker)sirapu100% (3)
- Rapid Minder AssignmentDocument38 pagesRapid Minder AssignmentGiani SuhikmatNo ratings yet
- 1 - Intro To Machine LearningDocument20 pages1 - Intro To Machine Learningtariq1982100% (1)
- 1 Linear Regression With One VariableDocument49 pages1 Linear Regression With One VariableRamon LinsNo ratings yet
- K Means R and Rapid Miner Patient and Mall Case StudyDocument80 pagesK Means R and Rapid Miner Patient and Mall Case StudyArjun KhoslaNo ratings yet
- ML CheatsheetDocument1 pageML Cheatsheetfrancoisroyer7709No ratings yet
- Machine Learning Andrew NG Week 6 Quiz 1Document8 pagesMachine Learning Andrew NG Week 6 Quiz 1Hương ĐặngNo ratings yet
- Machine Learning Coursera All Exercies PDFDocument117 pagesMachine Learning Coursera All Exercies PDFsudheer1044No ratings yet
- Assignment No1 - ModifiedDocument22 pagesAssignment No1 - ModifiedMukhtar AhmedNo ratings yet
- Machine Learning Andrew NG Week 5 Quiz 1Document3 pagesMachine Learning Andrew NG Week 5 Quiz 1Hương ĐặngNo ratings yet
- Fundamentals of Statistics For Data ScienceDocument23 pagesFundamentals of Statistics For Data ScienceNelsonNo ratings yet
- HTML Color Codes PDFDocument12 pagesHTML Color Codes PDFAungKyawOoNo ratings yet
- Machine Learning Interview QuestionsDocument41 pagesMachine Learning Interview QuestionsChirag JainNo ratings yet
- SAS PresentationDocument49 pagesSAS PresentationVarun JainNo ratings yet
- Total Listing Machine LearningDocument114 pagesTotal Listing Machine LearningThanh Stephen100% (1)
- Machine-Learning Classification Techniques For Stocks (Ensemble Methodology)Document292 pagesMachine-Learning Classification Techniques For Stocks (Ensemble Methodology)hacheemasterNo ratings yet
- Model Perf Cheat SheetDocument2 pagesModel Perf Cheat SheetvinodhewardsNo ratings yet
- Data Mining - A Tutorial-Based Primer, Second Edition PDFDocument530 pagesData Mining - A Tutorial-Based Primer, Second Edition PDFKaustubh KshetrapalNo ratings yet
- The RCMDR GuideDocument93 pagesThe RCMDR GuideJavier GuerreroNo ratings yet
- Modul Data Science 1Document12 pagesModul Data Science 1william yohanesNo ratings yet
- Machine Learning Resource GuideDocument11 pagesMachine Learning Resource Guidejsm789No ratings yet
- Essential Machine Learning Interview Questions and AnswersDocument15 pagesEssential Machine Learning Interview Questions and AnswersAbiNo ratings yet
- Ggplot 2Document48 pagesGgplot 2Roger Basso BrusaNo ratings yet
- Support Vector Machine-Based Prediction System For A Football Match ResultDocument6 pagesSupport Vector Machine-Based Prediction System For A Football Match ResultIOSRjournalNo ratings yet
- Mastering Unlabeled Data Meap v06Document352 pagesMastering Unlabeled Data Meap v06Chetan ChaudhariNo ratings yet
- Untitled5 - Jupyter NotebookDocument11 pagesUntitled5 - Jupyter NotebookGupta Anacoolz100% (2)
- Ensemble Learning: Wisdom of The CrowdDocument12 pagesEnsemble Learning: Wisdom of The CrowdRavi Verma100% (1)
- How To Use LeetCode For Data Science SQL Interviews - StrataScratchDocument1 pageHow To Use LeetCode For Data Science SQL Interviews - StrataScratchyoshikis sanoNo ratings yet
- 2 Forecast AccuracyDocument26 pages2 Forecast Accuracynatalie clyde matesNo ratings yet
- Stock Market Analysis ProjectDocument23 pagesStock Market Analysis ProjectrajasekharNo ratings yet
- 000+ +curriculum+ +Complete+Data+Science+and+Machine+Learning+Using+PythonDocument10 pages000+ +curriculum+ +Complete+Data+Science+and+Machine+Learning+Using+PythonVishal MudgalNo ratings yet
- Data Science Theory: Analysis and AnalyticsDocument14 pagesData Science Theory: Analysis and AnalyticsNonameforeverNo ratings yet
- Tutorial Rapid Miner Life Insurance Promotion PDFDocument11 pagesTutorial Rapid Miner Life Insurance Promotion PDFAnonymous atrs1INo ratings yet
- Chat GPT2Document1 pageChat GPT2mklitabeNo ratings yet
- Data Science Course AgendaDocument29 pagesData Science Course AgendaDev RajNo ratings yet
- A Tutorial On: Linguistic Data AnalysisDocument99 pagesA Tutorial On: Linguistic Data AnalysisAbhishekNo ratings yet
- Chapter 5Document58 pagesChapter 5Shible SheikhNo ratings yet
- School of Data Science and Forecasting: M.B.A. (Business Analytics)Document2 pagesSchool of Data Science and Forecasting: M.B.A. (Business Analytics)Purvi MajokaNo ratings yet
- Entry Level Data Scientist ResumeDocument1 pageEntry Level Data Scientist ResumeZefanya SimamoraNo ratings yet
- Data Mining - An OverviewDocument40 pagesData Mining - An OverviewShyamBhattNo ratings yet
- Linear Regression With Gradient DescentDocument8 pagesLinear Regression With Gradient DescentGautam Kumar100% (1)
- Beginners Guide To Data Science - A Twics Guide 1Document41 pagesBeginners Guide To Data Science - A Twics Guide 1Jeffin VargheseNo ratings yet
- Ensemble Methods - Bagging, Boosting and Stacking - Towards Data Science PDFDocument37 pagesEnsemble Methods - Bagging, Boosting and Stacking - Towards Data Science PDFcidsantNo ratings yet
- Sas AnalyticsDocument35 pagesSas AnalyticsprakashnethaNo ratings yet
- Understanding DBSCAN Algorithm and Implementation From Scratch - by Andrewngai - Towards Data ScienceDocument10 pagesUnderstanding DBSCAN Algorithm and Implementation From Scratch - by Andrewngai - Towards Data ScienceeimisjaneisiNo ratings yet
- Dive Into Deep LearningDocument60 pagesDive Into Deep LearningPaul Vikash K MNo ratings yet
- Ggplot2 Elegant Graphics For Data Analysis (2016, Springer) PDFDocument281 pagesGgplot2 Elegant Graphics For Data Analysis (2016, Springer) PDFmjhgoemcapetulktuNo ratings yet
- Understanding Random ForestDocument12 pagesUnderstanding Random ForestBS GNo ratings yet
- Government PoliciesDocument32 pagesGovernment PoliciesJesicca DeviyantiNo ratings yet
- SQLDocument98 pagesSQLRohit GhaiNo ratings yet
- 30 Frequently Asked Deep Learning Interview Questions and AnswersDocument28 pages30 Frequently Asked Deep Learning Interview Questions and AnswersKhirod Behera100% (1)
- Introduction to Machine Learning in the Cloud with Python: Concepts and PracticesFrom EverandIntroduction to Machine Learning in the Cloud with Python: Concepts and PracticesNo ratings yet
- Machine Learning FondamentalsDocument9 pagesMachine Learning Fondamentalsjemai.mohamedazeNo ratings yet
- Newton-Raphson Method of Solving A Nonlinear Equation: After Reading This Chapter, You Should Be Able ToDocument10 pagesNewton-Raphson Method of Solving A Nonlinear Equation: After Reading This Chapter, You Should Be Able TocoolbksNo ratings yet
- An Introduction To Formal Language Theory That Integrates Experimentation and Proof - Allen StoughtonDocument288 pagesAn Introduction To Formal Language Theory That Integrates Experimentation and Proof - Allen Stoughtonapi-26345612No ratings yet
- Data Structure: by Prof - Manikandan QMC College, MedavakkamDocument11 pagesData Structure: by Prof - Manikandan QMC College, MedavakkamProf.ManikandanNo ratings yet
- Bmte 144Document12 pagesBmte 144akashdhurde2880No ratings yet
- Data Types: Variable Names, Sizes, Constants and DeclarationsDocument18 pagesData Types: Variable Names, Sizes, Constants and DeclarationsKARTIK KUMAR GOYALNo ratings yet
- Quiz 2 SolutionsDocument6 pagesQuiz 2 SolutionsAmreshAmanNo ratings yet
- Segment-6 Discrete Fourier Transform (DFT) & Fast Fourier Transform (FFT)Document32 pagesSegment-6 Discrete Fourier Transform (DFT) & Fast Fourier Transform (FFT)mghabirNo ratings yet
- Can Schönhage Multiplication Speed Up The RSA Encryption or Decryption?Document45 pagesCan Schönhage Multiplication Speed Up The RSA Encryption or Decryption?Quyền NguyễnNo ratings yet
- Book NumericalDocument388 pagesBook NumericalSirotnikov100% (1)
- Daa Manual PDFDocument60 pagesDaa Manual PDFTrishla BhandariNo ratings yet
- Midterm Scheduling - International University - Sample TestDocument3 pagesMidterm Scheduling - International University - Sample TestDuyen Nguyen Thuy HanhNo ratings yet
- 962 1102 1 PBDocument6 pages962 1102 1 PBS.B ASHIRBADNo ratings yet
- Introduction To Data Structures and Algorithms AnalysisDocument16 pagesIntroduction To Data Structures and Algorithms AnalysisYihune NegesseNo ratings yet
- Association Analysis: Patterns Association Analysis: PatternsDocument30 pagesAssociation Analysis: Patterns Association Analysis: PatternsLưu Hoàng SơnNo ratings yet
- Topic 03 SearchDocument86 pagesTopic 03 SearchS AlshNo ratings yet
- 5.02 - SlopeDocument6 pages5.02 - SlopeZachary StarkNo ratings yet
- Data Compression Question BankDocument3 pagesData Compression Question BankNarasimhareddy MmkNo ratings yet
- Mock Test in Cmpe 1Document3 pagesMock Test in Cmpe 1waigneveraNo ratings yet
- Data StructuresDocument613 pagesData StructuresJai BishnoiNo ratings yet
- Approximation Algorithms PDFDocument59 pagesApproximation Algorithms PDFMr PhiNo ratings yet
- Stiff Differential EquationsDocument6 pagesStiff Differential EquationsamomentcastingNo ratings yet
- Templates in C++ Selection Sort TemplateDocument1 pageTemplates in C++ Selection Sort TemplateFuad Muhammad RaysNo ratings yet
- Algoritma Dan PseudocodeDocument19 pagesAlgoritma Dan Pseudocode116 ProgrammingNo ratings yet
- Fundamental Concepts of Object-Oriented Programming: ClassDocument3 pagesFundamental Concepts of Object-Oriented Programming: ClassShivam SharmaNo ratings yet
- Sapt 5 String Processing Quizz Sect 3 L3Document3 pagesSapt 5 String Processing Quizz Sect 3 L3Bucătari Europeni XBNo ratings yet
- Optimasi Produksi Sepatu Menggunakan Program Linier Multi: Objective FuzzyDocument7 pagesOptimasi Produksi Sepatu Menggunakan Program Linier Multi: Objective FuzzyLimatul AzizahNo ratings yet
- CSEC-ASTU Competitive Programming Contest 2021 Problem 93: String CuttingDocument2 pagesCSEC-ASTU Competitive Programming Contest 2021 Problem 93: String CuttingAbraham MekuriaNo ratings yet
- New Approach To Modified Schur-Cohn Criterion For Stability Analysis of A Discrete Time SystemDocument5 pagesNew Approach To Modified Schur-Cohn Criterion For Stability Analysis of A Discrete Time SystemRitesh KeshriNo ratings yet