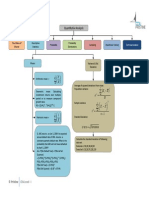
Download as pdf or txt
You might also like
- Data Mining Classification: Alternative TechniquesDocument15 pagesData Mining Classification: Alternative TechniquesYosua SiregarNo ratings yet
- Coursera Course02Module03AssignmentDocument7 pagesCoursera Course02Module03AssignmentZain Ul Haq0% (2)
- Lean Six Sigma Black Belt Mock ExamDocument26 pagesLean Six Sigma Black Belt Mock ExamAnonymous G5vlroDv100% (1)
- PR January20 05 PDFDocument24 pagesPR January20 05 PDFNadia AnjumNo ratings yet
- Lecture 5-Naïve BayesDocument26 pagesLecture 5-Naïve BayesNada ShaabanNo ratings yet
- ML Lec 15 Naive BayesDocument16 pagesML Lec 15 Naive Bayesfake TigerNo ratings yet
- Implementasi Naive BayesDocument23 pagesImplementasi Naive BayesAdrianov DeltaNo ratings yet
- BayesDocument10 pagesBayeschristianNo ratings yet
- Outcome4 Naive BayesDocument39 pagesOutcome4 Naive BayesBNo ratings yet
- Classification With NaiveBayesDocument19 pagesClassification With NaiveBayesAjay KorimilliNo ratings yet
- 6 - Naive BayesDocument26 pages6 - Naive BayesHadiNo ratings yet
- 20210913115710D3708 - Session 09-12 Bayes ClassifierDocument30 pages20210913115710D3708 - Session 09-12 Bayes ClassifierAnthony HarjantoNo ratings yet
- Chap4 Naive BayesDocument19 pagesChap4 Naive BayesTejas MhaiskarNo ratings yet
- Classification and RegressionDocument15 pagesClassification and RegressionBhagirath PrajapatiNo ratings yet
- Bayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument26 pagesBayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarYến NghĩaNo ratings yet
- Statistics 202: Statistical Aspects of Data Mining Professor Rajan PatelDocument47 pagesStatistics 202: Statistical Aspects of Data Mining Professor Rajan PatelBao GanNo ratings yet
- Bayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument17 pagesBayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarCSSCTube FCITubeNo ratings yet
- Naive Bayesian ClassifiersDocument3 pagesNaive Bayesian ClassifiersAnand satputeNo ratings yet
- Bayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarDocument26 pagesBayesian Classifiers Introduction To Data Mining, 2 Edition by Tan, Steinbach, Karpatne, KumarAbhishek Kumar TiwariNo ratings yet
- Bays Classifier (Machine Learning)Document16 pagesBays Classifier (Machine Learning)Suman KunduNo ratings yet
- Lecture - Naive BayesianDocument21 pagesLecture - Naive BayesianMahmoud ElnahasNo ratings yet
- Lecture 5 Bayesian ClassificationDocument16 pagesLecture 5 Bayesian ClassificationAhsan AsimNo ratings yet
- Probability Review: Dr. Kaushik DebDocument33 pagesProbability Review: Dr. Kaushik DebAfsana RahmanNo ratings yet
- Naïve Bayes Classifier: Ke ChenDocument19 pagesNaïve Bayes Classifier: Ke ChenAlimushwan AdnanNo ratings yet
- Classification (Naive Bayes)Document40 pagesClassification (Naive Bayes)Mahad GulNo ratings yet
- ISI Mathematical Talent Reward Programme 2019Document3 pagesISI Mathematical Talent Reward Programme 2019ElevenPlus ParentsNo ratings yet
- Naive BayesDocument9 pagesNaive Bayesahmadmanhal673No ratings yet
- K - Nearest Neighbours Classifier / RegressorDocument35 pagesK - Nearest Neighbours Classifier / RegressorSmitNo ratings yet
- Naive BayesDocument19 pagesNaive BayesFeliMeierNo ratings yet
- 04 Bayes Classification RuleDocument46 pages04 Bayes Classification RuleMostafa MohamedNo ratings yet
- Decision Tree MethodsDocument34 pagesDecision Tree Methodsjemal yahyaaNo ratings yet
- Machine Learning ConceptsDocument68 pagesMachine Learning Conceptsvedangtripathi45No ratings yet
- Introduction To Belief Networks: David BarberDocument20 pagesIntroduction To Belief Networks: David BarberPissOfferyNo ratings yet
- (2,2) (3,3) (4, 4G, 5) (6.6) Pie & - Alal 6: Bo 2 Ug & BG 6 N (S/ 36Document2 pages(2,2) (3,3) (4, 4G, 5) (6.6) Pie & - Alal 6: Bo 2 Ug & BG 6 N (S/ 36Nathan BittnerNo ratings yet
- Unit-4 DWDMDocument10 pagesUnit-4 DWDMSeerapu RameshNo ratings yet
- ML Lecture#5Document65 pagesML Lecture#5muhammadhzrizwan2002No ratings yet
- Species Tree Inference Using Svdquartets: Laura KubatkoDocument10 pagesSpecies Tree Inference Using Svdquartets: Laura KubatkoKevin I. SanchezNo ratings yet
- Probability CheatsheetDocument8 pagesProbability CheatsheetRohit MahajanNo ratings yet
- Week 4 Part 1 ClassificationDocument71 pagesWeek 4 Part 1 ClassificationMichael ZewdieNo ratings yet
- Naïve Bayes Classifier: Adopted From Slides by Ke Chen From University of Manchester and Yangqiu Song From MsraDocument25 pagesNaïve Bayes Classifier: Adopted From Slides by Ke Chen From University of Manchester and Yangqiu Song From MsraJitendra KingNo ratings yet
- 1 - Basic Probability p1 - Lec. 1Document13 pages1 - Basic Probability p1 - Lec. 1Ahmad Yassien El GamalNo ratings yet
- Naive Ba YesDocument28 pagesNaive Ba Yesarjuntho630No ratings yet
- Bayesian Networks 2011-01-02Document106 pagesBayesian Networks 2011-01-02vctwmsmeNo ratings yet
- Naive Bayes Classifier: K M M I I MDocument16 pagesNaive Bayes Classifier: K M M I I MVirgiawan Huda AkbarNo ratings yet
- NotesDocument6 pagesNotesbooxlNo ratings yet
- Bayes' Rule and Law of Total Probability: C C C C C 1 2 3Document8 pagesBayes' Rule and Law of Total Probability: C C C C C 1 2 3Adel NizamutdinovNo ratings yet
- Student User Guide V 1.1Document24 pagesStudent User Guide V 1.1Madiha UroojNo ratings yet
- Statistics Homework Sample 3Document8 pagesStatistics Homework Sample 3Jack ClarkNo ratings yet
- AI 19 Bayes Nets IV SamplingDocument29 pagesAI 19 Bayes Nets IV Samplinghumanbody22No ratings yet
- Quantitative Analysis: CFA Level - IDocument4 pagesQuantitative Analysis: CFA Level - IWin GungadinNo ratings yet
- Naïve Bayes Classifier: Ke ChenDocument18 pagesNaïve Bayes Classifier: Ke ChenMadhura PrakashNo ratings yet
- Probability TheoryDocument58 pagesProbability TheoryEvelynNo ratings yet
- Form Prob MATHSDocument80 pagesForm Prob MATHSOdrie TambeNo ratings yet
- Chapter 4:supervised LearningDocument34 pagesChapter 4:supervised Learning01fe20bcs181No ratings yet
- BDocument4 pagesBJyp Son NgangomNo ratings yet
- Assignment2 SolutionDocument5 pagesAssignment2 SolutionMiranda WongNo ratings yet
- EC994 Naive BayesDocument15 pagesEC994 Naive BayesMatthew DCostaNo ratings yet
- Naïve Bayes Classifier: Ke ChenDocument18 pagesNaïve Bayes Classifier: Ke ChenSgsksbskxvxkNo ratings yet
- Probability Theory AIDocument16 pagesProbability Theory AIvepowo LandryNo ratings yet
- Quiz 2Document2 pagesQuiz 2Sam MektoNo ratings yet
- Quiz 3 KeyDocument6 pagesQuiz 3 KeyTigabu YayaNo ratings yet
- Lecture19 & 20 - Xen - ArchitectureDocument16 pagesLecture19 & 20 - Xen - ArchitectureZain Ul HaqNo ratings yet
- Support Vector MachinesDocument26 pagesSupport Vector MachinesZain Ul HaqNo ratings yet
- Pattern Recognition: Muhammad Atif Tahir, Josef Kittler, Fei YanDocument13 pagesPattern Recognition: Muhammad Atif Tahir, Josef Kittler, Fei YanZain Ul HaqNo ratings yet
- Segmentation, Targeting and PositioningDocument26 pagesSegmentation, Targeting and PositioningZain Ul HaqNo ratings yet
- NLTK CLCDocument6 pagesNLTK CLCK60 Lương Đức VinhNo ratings yet
- CH 3 Probability TheoryDocument14 pagesCH 3 Probability TheoryPoint BlankNo ratings yet
- Exercises For Discrete DistributionsDocument6 pagesExercises For Discrete DistributionsTran Pham Quoc ThuyNo ratings yet
- CHAPTER 6 Continuous ProbabilityDocument3 pagesCHAPTER 6 Continuous ProbabilityPark MinaNo ratings yet
- Solutions Chapter 10Document7 pagesSolutions Chapter 10Nama SahajaNo ratings yet
- LinearRegression1 210720 171800Document41 pagesLinearRegression1 210720 171800Nehal JambhulkarNo ratings yet
- 103 April 2003 QuestionDocument8 pages103 April 2003 QuestionKanika KanodiaNo ratings yet
- Chapter 4 Regression AnalysisDocument70 pagesChapter 4 Regression AnalysisMrk KhanNo ratings yet
- x=rcosθ y=rsinθ r = x + y θ = tan y xDocument1 pagex=rcosθ y=rsinθ r = x + y θ = tan y xmarkosNo ratings yet
- Binomial Probability (Basic) (Article) - Khan AcademyDocument20 pagesBinomial Probability (Basic) (Article) - Khan Academyabel mahendraNo ratings yet
- Mathematics For Informatics 4a: The Story of The Film So Far..Document6 pagesMathematics For Informatics 4a: The Story of The Film So Far..marudhu14No ratings yet
- 2022 1 PyE Gilda - Ps17001413.conjuntasDocument4 pages2022 1 PyE Gilda - Ps17001413.conjuntasJulioNo ratings yet
- Psychometric Properties of The Motor Diagnostics in The German Football Talent Identification and Development ProgrammeDocument16 pagesPsychometric Properties of The Motor Diagnostics in The German Football Talent Identification and Development ProgrammeEsteban LopezNo ratings yet
- Outlier: Occurrence and CausesDocument6 pagesOutlier: Occurrence and CausesTangguh WicaksonoNo ratings yet
- Advance Stats Project ParijatDocument18 pagesAdvance Stats Project ParijatPARIJAT DEVNo ratings yet
- STAB22 Lecture's NotesDocument64 pagesSTAB22 Lecture's Notesisabella brantonNo ratings yet
- Stochastic Process Simulation in MatlabDocument17 pagesStochastic Process Simulation in MatlabsalvaNo ratings yet
- Meilani Ferdinan PDFDocument11 pagesMeilani Ferdinan PDFhilmyNo ratings yet
- Newbold Chapter 7Document62 pagesNewbold Chapter 7AshutoshNo ratings yet
- Ch13 Multiple RegresDocument46 pagesCh13 Multiple RegresGetachew MulatNo ratings yet
- EC 203 Final Exam Assessment Question S1 2020 - s11158595Document14 pagesEC 203 Final Exam Assessment Question S1 2020 - s11158595Olly TainaNo ratings yet
- Shapiro-Wilk Test Calculator Normality Calculator, Q-Q Plot 2Document1 pageShapiro-Wilk Test Calculator Normality Calculator, Q-Q Plot 2FALAH FADHILAH KIAYINo ratings yet
- III-Discrete DistributionsDocument46 pagesIII-Discrete DistributionsΙσηνα ΑνησιNo ratings yet
- Regression: Variables Entered/RemovedDocument4 pagesRegression: Variables Entered/RemovedMawar MerahNo ratings yet
- VaR Estimation Using GANs - 1553122463Document23 pagesVaR Estimation Using GANs - 1553122463StepanKalikaNo ratings yet
- Applied Econometrics ModuleDocument142 pagesApplied Econometrics ModuleNeway Alem100% (1)
- 2011 Mathematics HCI Prelim Paper 2Document5 pages2011 Mathematics HCI Prelim Paper 2ShaphynaNo ratings yet
- Co Relation and RegrationDocument2 pagesCo Relation and Regrationwgl.joshiNo ratings yet
- PDF Statistics For Business Economics David Ray Anderson Ebook Full ChapterDocument53 pagesPDF Statistics For Business Economics David Ray Anderson Ebook Full Chapterelizabeth.lloyd618100% (1)