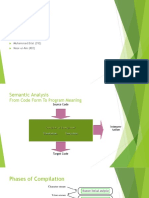
Download as docx, pdf, or txt
You might also like
- Management of Organizational Behavior PDFDocument372 pagesManagement of Organizational Behavior PDFJoao Cesar100% (7)
- Regular Expressions and Its ApplicationsDocument6 pagesRegular Expressions and Its ApplicationsAminaNo ratings yet
- Parsing PDFDocument5 pagesParsing PDFfiraszekiNo ratings yet
- Chapter-1 Introduction To NLPDocument12 pagesChapter-1 Introduction To NLPSruja KoshtiNo ratings yet
- What Is Syntax Analysis?: Syntax Analysis Is A Second Phase of The Compiler Design Process inDocument8 pagesWhat Is Syntax Analysis?: Syntax Analysis Is A Second Phase of The Compiler Design Process inRamna SatarNo ratings yet
- SBG Study NLP Notes From Unit 3Document14 pagesSBG Study NLP Notes From Unit 3KILLSHOT SKJNo ratings yet
- Unit IiiDocument17 pagesUnit IiiAllan RobeyNo ratings yet
- ATFL Assignment 1Document4 pagesATFL Assignment 1Crack TunesNo ratings yet
- NLP IntroDocument9 pagesNLP IntroVinisha ChandnaniNo ratings yet
- 7 Formal Systems and Programming Languages: An IntroductionDocument40 pages7 Formal Systems and Programming Languages: An Introductionrohit_pathak_8No ratings yet
- AI Notes Part-3Document29 pagesAI Notes Part-3Divyanshu PatwalNo ratings yet
- Unit 1Document4 pagesUnit 1Shiv MNo ratings yet
- AI Unit 3 Lecture 2Document8 pagesAI Unit 3 Lecture 2Sunil NagarNo ratings yet
- SPCC Case Study ParserDocument4 pagesSPCC Case Study ParserSohail SayyedNo ratings yet
- NLP Detail 3Document5 pagesNLP Detail 3shahzad sultanNo ratings yet
- NLP Lab ManualDocument16 pagesNLP Lab Manualadarsh24jdpNo ratings yet
- Explain Item Normalization?Document7 pagesExplain Item Normalization?Shushanth munnaNo ratings yet
- Lesson 1: Introducing Regular ExpressionsDocument4 pagesLesson 1: Introducing Regular ExpressionsMe ItsNo ratings yet
- Consituency Vs Dependent GrammarDocument5 pagesConsituency Vs Dependent GrammarNguyen Quynh NganNo ratings yet
- Compiler DesignDocument7 pagesCompiler Designchaitanya518No ratings yet
- CMR University School of Engineering and Technology Department of Cse and ItDocument8 pagesCMR University School of Engineering and Technology Department of Cse and ItSmart WorkNo ratings yet
- Parsing and Parsing Techniques in Compiler ConstructionDocument12 pagesParsing and Parsing Techniques in Compiler ConstructionFranklin okoloNo ratings yet
- Full Text Indexes in PostgresqlDocument37 pagesFull Text Indexes in PostgresqlUbirajara F. SilvaNo ratings yet
- Automata Theory and Compiler Design: Name: Smitha.A Usn: 1Vj21Cs042 Branch: CseDocument9 pagesAutomata Theory and Compiler Design: Name: Smitha.A Usn: 1Vj21Cs042 Branch: CseSmitha.A Smitha.ANo ratings yet
- Compiler Cons NoteDocument5 pagesCompiler Cons NoteTimsonNo ratings yet
- Syntax WikipediaDocument2 pagesSyntax WikipediakevinNo ratings yet
- Contextual Trans Using MachineDocument14 pagesContextual Trans Using MachineArRizka FebyNo ratings yet
- Phases of CompilerDocument9 pagesPhases of Compilerankita3031No ratings yet
- Chapter Five (ISR)Document17 pagesChapter Five (ISR)Wudneh AderawNo ratings yet
- 601.465/665 - Natural Language Processing Assignment 1: Designing Context-Free GrammarsDocument11 pages601.465/665 - Natural Language Processing Assignment 1: Designing Context-Free GrammarsDen ThanhNo ratings yet
- The 7 Basic Functions of Text AnalyticsDocument11 pagesThe 7 Basic Functions of Text AnalyticsZizu ZissouNo ratings yet
- CD Important QuestionsDocument9 pagesCD Important Questionsganesh moorthiNo ratings yet
- Seminar On Natural Language ProcessingDocument21 pagesSeminar On Natural Language ProcessingAman BajajNo ratings yet
- CompilerDocument4 pagesCompilerAshblue GalveNo ratings yet
- Parts of Speech Tagging and Dependency Parsing Using Spacy 1598272753Document9 pagesParts of Speech Tagging and Dependency Parsing Using Spacy 1598272753「瞳」你分享No ratings yet
- YACTDocument25 pagesYACTMassimo PozzoniNo ratings yet
- Lecture NLPDocument38 pagesLecture NLPharpritsingh100% (1)
- NLP-Questions Class 10 AiDocument8 pagesNLP-Questions Class 10 AikritavearnNo ratings yet
- Chapter 3 Compiler DesignDocument42 pagesChapter 3 Compiler Designmishamoamanuel574No ratings yet
- Ss Mini ProjectDocument20 pagesSs Mini ProjectShashidhar ReddyNo ratings yet
- Attribute Grammars - PPLDocument9 pagesAttribute Grammars - PPLalukapellyvijayaNo ratings yet
- Term Paper On Regular ExpressionDocument8 pagesTerm Paper On Regular Expressionafmzmajcevielt100% (1)
- Certificate Declaration: Topic NameDocument16 pagesCertificate Declaration: Topic NameManish ChauhanNo ratings yet
- Describing Syntax and SemanticsDocument8 pagesDescribing Syntax and SemanticsamatNo ratings yet
- Lexing and TokensDocument6 pagesLexing and TokensricardoescuderorrssNo ratings yet
- 2011 Dawson StemmerDocument7 pages2011 Dawson Stemmerkidoseno85No ratings yet
- Programming Language Notes: February 24, 2009 Morgan Mcguire Williams CollegeDocument4 pagesProgramming Language Notes: February 24, 2009 Morgan Mcguire Williams CollegeShahzad MalikNo ratings yet
- 039-Structs and DictsDocument3 pages039-Structs and DictstesterNo ratings yet
- Python Learn Python Regular Expressions FAST The Ultimate Crash Course To Learning The Basics of Python Regular Expressions - (Acodemy)Document127 pagesPython Learn Python Regular Expressions FAST The Ultimate Crash Course To Learning The Basics of Python Regular Expressions - (Acodemy)Anonymous b14XRyNo ratings yet
- Chapter 2 Lexical Analysis (Scanning) EditedDocument46 pagesChapter 2 Lexical Analysis (Scanning) EditedDaniel Bido RasaNo ratings yet
- Artificial Intelligence AssignmentDocument6 pagesArtificial Intelligence Assignmentnatasha ashleeNo ratings yet
- NLP Steps BasicDocument26 pagesNLP Steps BasicMadhuNo ratings yet
- Module 3-CD-NOTESDocument12 pagesModule 3-CD-NOTESlekhanagowda797No ratings yet
- Introduction To Common LispDocument32 pagesIntroduction To Common LispUzmanNo ratings yet
- Group Members: Sohail Memon (429) Abdul Qayoom (350) Rehmatullah (408) Muhammad Bilal (392) Noor-ul-AinDocument15 pagesGroup Members: Sohail Memon (429) Abdul Qayoom (350) Rehmatullah (408) Muhammad Bilal (392) Noor-ul-AinSohail JaffarNo ratings yet
- Telstem:An Unsupervised Telugu Stemmer With Heuristic Improvements and Normalized SignaturesDocument42 pagesTelstem:An Unsupervised Telugu Stemmer With Heuristic Improvements and Normalized SignaturesJanakiram ReddyNo ratings yet
- Regular ExpressionsDocument9 pagesRegular ExpressionsThi HaNo ratings yet
- Natural Language Processing Parsing Techniques:: Unit IVDocument24 pagesNatural Language Processing Parsing Techniques:: Unit IVThumbiko Mkandawire100% (1)
- EL ºobject Oriented EasyLanguage Concepts by Android MarvinDocument75 pagesEL ºobject Oriented EasyLanguage Concepts by Android MarvinfreetradingNo ratings yet
- Practical Web Development with Haskell: Master the Essential Skills to Build Fast and Scalable Web ApplicationsFrom EverandPractical Web Development with Haskell: Master the Essential Skills to Build Fast and Scalable Web ApplicationsNo ratings yet
- Disaster MGTDocument30 pagesDisaster MGTojuNo ratings yet
- How To Write An Energy Drink Production Business PlanDocument13 pagesHow To Write An Energy Drink Production Business PlanojuNo ratings yet
- Disaster 3Document28 pagesDisaster 3ojuNo ratings yet
- Disaster 2Document16 pagesDisaster 2ojuNo ratings yet
- Mobile HealthcareDocument7 pagesMobile HealthcareojuNo ratings yet
- Improving Sustainable Mobile Health Care Promotion - A Novel HybridDocument29 pagesImproving Sustainable Mobile Health Care Promotion - A Novel HybridojuNo ratings yet
- Hybrid Mobile Application Analysis and Guidelines Codex888Document8 pagesHybrid Mobile Application Analysis and Guidelines Codex888ojuNo ratings yet
- Hybrid Mobile 4Document11 pagesHybrid Mobile 4ojuNo ratings yet
- Journal 1Document1 pageJournal 1ojuNo ratings yet
- Doctor-Patient Communication in The E-Health Era: Commentary Open AccessDocument7 pagesDoctor-Patient Communication in The E-Health Era: Commentary Open AccessojuNo ratings yet
- Mobile 20 TechnologyDocument16 pagesMobile 20 TechnologyojuNo ratings yet
- Communication 8Document5 pagesCommunication 8ojuNo ratings yet
- Cahps Section 4 Ways To Approach Qi ProcessDocument22 pagesCahps Section 4 Ways To Approach Qi ProcessojuNo ratings yet
- Benefits of Ionic Framework App DevelopmentDocument3 pagesBenefits of Ionic Framework App DevelopmentojuNo ratings yet
- Chapter 3 WOMEN AND ALCHOL For SendingDocument4 pagesChapter 3 WOMEN AND ALCHOL For SendingNaharia RangirisNo ratings yet
- Lesson Plan Poetry 1Document7 pagesLesson Plan Poetry 1api-681890014No ratings yet
- 88 Present-Perfect-Progressive US Student PDFDocument15 pages88 Present-Perfect-Progressive US Student PDFLeonel Prz Mrtz100% (1)
- Recap Lecture 3: in Different LettersDocument21 pagesRecap Lecture 3: in Different LettersM N RaoNo ratings yet
- Lexical Relations, Derivational Relation and Lexical UniversalsDocument11 pagesLexical Relations, Derivational Relation and Lexical UniversalsMezo. NadoNo ratings yet
- Rubric Deaf Studies Final Assignment Asl Reflection SampleDocument1 pageRubric Deaf Studies Final Assignment Asl Reflection Sampleapi-497283356No ratings yet
- Witness LiteratureDocument7 pagesWitness LiteraturebtucanNo ratings yet
- Countertransference: The Body of The Therapist As A Space For ReflectionDocument18 pagesCountertransference: The Body of The Therapist As A Space For ReflectionRita Gonzaga Gaspar100% (1)
- Management Theory MNGT 310 Summer II 2017 Assignment: Dr. Ofelia PosecionDocument6 pagesManagement Theory MNGT 310 Summer II 2017 Assignment: Dr. Ofelia PosecionAboubakr SoultanNo ratings yet
- How Google Is Remaking Itself As A Machine Learning First CompanyDocument9 pagesHow Google Is Remaking Itself As A Machine Learning First CompanyIñakiAndoneguiNo ratings yet
- Jurus 6 Coordinate Connectors Yang BenarDocument6 pagesJurus 6 Coordinate Connectors Yang BenardayuwijayantiNo ratings yet
- E4E - A - ES - GL - FS Interface - INT - GL - 009 - XCNEC01E - v2.0Document23 pagesE4E - A - ES - GL - FS Interface - INT - GL - 009 - XCNEC01E - v2.0JaimeNo ratings yet
- Sample Lesson Plan For Writing For IELTS Unit 6Document2 pagesSample Lesson Plan For Writing For IELTS Unit 6adnantahirengNo ratings yet
- RRLDocument3 pagesRRLHindi ka NakilalaNo ratings yet
- John Bowlby AND Mary Ainsworth: Attachment TheoryDocument15 pagesJohn Bowlby AND Mary Ainsworth: Attachment TheoryMaurine DollesinNo ratings yet
- PHL 102 Judgment and PropositionDocument7 pagesPHL 102 Judgment and Propositionmelaniem_1No ratings yet
- A Book Review: Qualitative Inquiry & Research Design: Choosing Among Five ApproachesDocument5 pagesA Book Review: Qualitative Inquiry & Research Design: Choosing Among Five ApproachesKichen SewradjNo ratings yet
- Sports and SocializationDocument32 pagesSports and SocializationKMTCLAN0% (1)
- Unit 2 Infancy and Toddler HoodDocument3 pagesUnit 2 Infancy and Toddler HoodNicz Lanz DejzNo ratings yet
- 10 Resource Management Best PracticesDocument3 pages10 Resource Management Best PracticesnerenNo ratings yet
- INFJ-InTP Relationships & Compatibility - Part I - Page 2 of 2 - Personality JunkieDocument2 pagesINFJ-InTP Relationships & Compatibility - Part I - Page 2 of 2 - Personality JunkieadactivatorNo ratings yet
- Organizational Change PlanDocument8 pagesOrganizational Change Planmaha saeedNo ratings yet
- InterferenceDocument34 pagesInterferenceC M Numan AfzalNo ratings yet
- Photosynthesis PracDocument2 pagesPhotosynthesis Pracapi-125467609No ratings yet
- Office Interior DesignDocument1 pageOffice Interior DesignHasanNo ratings yet
- 2018-19 Kramer Pre K Who We AreDocument9 pages2018-19 Kramer Pre K Who We AreKirtika MehtaNo ratings yet
- 01 Introduction To The Library and Information ProfessionsDocument208 pages01 Introduction To The Library and Information ProfessionsJorgivania Lopes100% (1)
- RecommenderSystemsAnIntroduction PDFDocument353 pagesRecommenderSystemsAnIntroduction PDFClebson Cardoso100% (3)
- Brine Shrimp Exp Response To Stimuli SetipDocument24 pagesBrine Shrimp Exp Response To Stimuli SetipenileuqcajNo ratings yet