
Lempel Ziv PDF
Lempel Ziv PDF
You might also like
- Energy Density of Aperiodic SignalsDocument9 pagesEnergy Density of Aperiodic SignalsaavdsNo ratings yet
- Homework For Module 5 : Quiz, 19 QuestionsDocument13 pagesHomework For Module 5 : Quiz, 19 QuestionsJustin Jose P33% (3)
- Rockwell Pricelist PDFDocument1,100 pagesRockwell Pricelist PDFsimbamikeNo ratings yet
- Bert Rowe's-Mercedes-Benz 'A'-Class Info. Mercedes Benz A Class W168 Automatic Transmission :gearboxDocument32 pagesBert Rowe's-Mercedes-Benz 'A'-Class Info. Mercedes Benz A Class W168 Automatic Transmission :gearboxJose Prieto67% (3)
- Outline: - Channel Capacity (Chapter 7) (Week 6)Document35 pagesOutline: - Channel Capacity (Chapter 7) (Week 6)HarshaNo ratings yet
- 1 MergedDocument182 pages1 MergedYash kumarNo ratings yet
- Least Squares: ORE 766 Numerical Methods in Ocean Engineering Instructor: Eva Marie NosalDocument24 pagesLeast Squares: ORE 766 Numerical Methods in Ocean Engineering Instructor: Eva Marie NosalDenis Constantin Ilie-AblachimNo ratings yet
- !!en5 Discrete Signals DTFT TZ v06Document11 pages!!en5 Discrete Signals DTFT TZ v06Marcela DobreNo ratings yet
- Kernel Methods: Dept. Computer Science & Engineering, Shanghai Jiao Tong UniversityDocument29 pagesKernel Methods: Dept. Computer Science & Engineering, Shanghai Jiao Tong UniversityPeter ParkerNo ratings yet
- AdvDSP Lecture1Document43 pagesAdvDSP Lecture1Alireza DabiryNo ratings yet
- RBF Neural NetworkDocument34 pagesRBF Neural NetworkSannan AhmedNo ratings yet
- Revision of Lecture 3: 1st-Order Markov ProcessDocument14 pagesRevision of Lecture 3: 1st-Order Markov ProcesshenkpiepNo ratings yet
- ECE 6151, Spring 2017 Lecture Notes: 1 OutlineDocument7 pagesECE 6151, Spring 2017 Lecture Notes: 1 OutlineLam DinhNo ratings yet
- Lect 3.2 Signal Space Analysis IDocument29 pagesLect 3.2 Signal Space Analysis Imid_cycloneNo ratings yet
- Trigonometric Fourier Series: - OutlineDocument23 pagesTrigonometric Fourier Series: - OutlineBoy KerenzNo ratings yet
- Chapter 4 Probability ReviewDocument20 pagesChapter 4 Probability ReviewŞamil ŞirinNo ratings yet
- Lecture 11Document7 pagesLecture 11mavisXzeref 17No ratings yet
- Fourier TransformDocument77 pagesFourier Transformtextile.km98No ratings yet
- FormalanalysisDocument26 pagesFormalanalysisShoaib ChNo ratings yet
- Statistics Formula Sheet-With TablesDocument5 pagesStatistics Formula Sheet-With TablesAnonymous uMSEZMNo ratings yet
- EE501 Adaptive Filter Design: Instructor: Dr. Farhan KhalidDocument26 pagesEE501 Adaptive Filter Design: Instructor: Dr. Farhan KhalidSana SaadNo ratings yet
- Lecture 6 - Spectrum Estimation PDFDocument47 pagesLecture 6 - Spectrum Estimation PDFMahy Magdy0% (1)
- A-Split Hopkinson Bar Test: - Reminder About Uniaxial Elastic Wave PropagationDocument27 pagesA-Split Hopkinson Bar Test: - Reminder About Uniaxial Elastic Wave Propagationahmadomar89No ratings yet
- Lecture 16 Transient Stability Solutions, Load ModelsDocument47 pagesLecture 16 Transient Stability Solutions, Load ModelsManuelNo ratings yet
- 3008 Lecture5 Random Signal AnalysisDocument16 pages3008 Lecture5 Random Signal AnalysisbalkyderNo ratings yet
- DimensionalityReduction PcaDocument24 pagesDimensionalityReduction PcauchenuangNo ratings yet
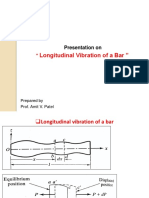
- Longitudinal Vibration of A Bar ": Presentation OnDocument17 pagesLongitudinal Vibration of A Bar ": Presentation OnamitpatelNo ratings yet
- InferenceDocument50 pagesInferencemahdieh.toodehNo ratings yet
- CH 07Document51 pagesCH 07陳浚維No ratings yet
- EE 278B: Random Processes 6 - 1Document16 pagesEE 278B: Random Processes 6 - 1Tahir saeedNo ratings yet
- Lect 06Document32 pagesLect 06Lucky AlamsyahNo ratings yet
- Formulasheet 22-23Document4 pagesFormulasheet 22-23Federico ScatignoNo ratings yet
- Lecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022Document22 pagesLecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022rohit kumarNo ratings yet
- EGR 601 Formulas (v2)Document11 pagesEGR 601 Formulas (v2)Kawser AhmedNo ratings yet
- Look-Up Table: Solving Differential EquationsDocument10 pagesLook-Up Table: Solving Differential EquationsDr. S. DasNo ratings yet
- CurveDocument15 pagesCurveMohammed AlsirajNo ratings yet
- Channel Capacity and The Channel Coding Theorem, Part I: Information Theory 2013Document17 pagesChannel Capacity and The Channel Coding Theorem, Part I: Information Theory 2013Kate bossNo ratings yet
- Vu HPSC2012 02Document25 pagesVu HPSC2012 02Quốc Đông VũNo ratings yet
- 3 Fourier TransformDocument14 pages3 Fourier TransformHoney PhsNo ratings yet
- 5707 11 RNN LSTMDocument128 pages5707 11 RNN LSTMMayank KumarNo ratings yet
- Continuous-Time Systems: Dept. of Electrical and Computer Engineering The University of Texas at AustinDocument24 pagesContinuous-Time Systems: Dept. of Electrical and Computer Engineering The University of Texas at AustinEleazar Sierra EspinozaNo ratings yet
- 4 Spline MethodDocument29 pages4 Spline MethodEmdad HossainNo ratings yet
- FN CH 1Document52 pagesFN CH 1Md. Nurul AlamNo ratings yet
- Me310 5 Regression PDFDocument15 pagesMe310 5 Regression PDFiqbalNo ratings yet
- 6 - Random ProcessDocument14 pages6 - Random Processabd syNo ratings yet
- Fourier Analysis of Discrete Time SignalsDocument11 pagesFourier Analysis of Discrete Time SignalsprathikNo ratings yet
- Chapter 4 SlidesDocument40 pagesChapter 4 Slideskwaleed717No ratings yet
- Signals and SystemDocument13 pagesSignals and SystemraviNo ratings yet
- DSP HandoutsDocument11 pagesDSP HandoutsG A E SATISH KUMARNo ratings yet
- Bit-And Power-Loading: EIT 140, Tom AT Eit - Lth.seDocument26 pagesBit-And Power-Loading: EIT 140, Tom AT Eit - Lth.sedeepa2400No ratings yet
- 6 Random Signal AnalysisDocument16 pages6 Random Signal AnalysisFêyø Õrö MãñNo ratings yet
- 3.2 Convolución GráficaDocument41 pages3.2 Convolución GráficaAlvaro Pardo SandovalNo ratings yet
- Fundamentals For Finite Element MethodDocument34 pagesFundamentals For Finite Element MethodnaderNo ratings yet
- EECS3451 Chapter4Document79 pagesEECS3451 Chapter4nickbekiaris05No ratings yet
- Frequency Domain Repr. and Signal Sampling 1Document61 pagesFrequency Domain Repr. and Signal Sampling 1Rogers Rodri ShayoNo ratings yet
- Z Transform PrimerDocument11 pagesZ Transform Primerveicastaneda14No ratings yet
- EE6340: Information Theory Problem Set 7: I I I I I I I I 1 2 N N NDocument1 pageEE6340: Information Theory Problem Set 7: I I I I I I I I 1 2 N N NSupriya DiwanNo ratings yet
- Finite Impulse Response FiltersDocument24 pagesFinite Impulse Response Filtersboulainine houriaNo ratings yet
- Coding 515Document92 pagesCoding 515essaidi.noureddineNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- High Voltage MOSFETsDocument31 pagesHigh Voltage MOSFETsharendraNo ratings yet
- KABA SL525 Product PresentationDocument22 pagesKABA SL525 Product PresentationAnthony ReedNo ratings yet
- SL 70953 Liebert Gxt5 Lithium Ion 1 3kva I 230v Ups User GuideDocument70 pagesSL 70953 Liebert Gxt5 Lithium Ion 1 3kva I 230v Ups User Guidepetermaroko69No ratings yet
- Asfjh PDFDocument22 pagesAsfjh PDFTzvetan DimitrovNo ratings yet
- Argus Radar System: Installation & Service ManualDocument154 pagesArgus Radar System: Installation & Service ManualNguyễn DanhNo ratings yet
- ContactorDocument10 pagesContactorprimarajNo ratings yet
- Acti 9 iEM3000 - A9MEM3235Document2 pagesActi 9 iEM3000 - A9MEM3235tungNo ratings yet
- M1293-E HATHOR User ManualDocument324 pagesM1293-E HATHOR User ManualDorin Alexandru PărăuNo ratings yet
- Toshiba VRF Commsiioning Sequence PDFDocument4 pagesToshiba VRF Commsiioning Sequence PDFtonylyf100% (1)
- Battery, Charger, Ups System - NewDocument32 pagesBattery, Charger, Ups System - NewDheeraj Kumar PendyalaNo ratings yet
- Ascgroup Scada-Bms TD en v6Document29 pagesAscgroup Scada-Bms TD en v6Jothimanikkam SomasundaramNo ratings yet
- Seminar On Bluetooth and WifiDocument39 pagesSeminar On Bluetooth and WifiSuhel Mulla75% (4)
- Sil MTL4544 - 1Document2 pagesSil MTL4544 - 1Andy Kong King100% (1)
- Chapter 5 - Internal MemoryDocument33 pagesChapter 5 - Internal MemoryHPManchester100% (1)
- E9905G 2-Module In-Circuit Test (ICT) System, I327x Series 6 - KeysightDocument1 pageE9905G 2-Module In-Circuit Test (ICT) System, I327x Series 6 - Keysightpc100xohmNo ratings yet
- Idoc - Pub - Freebitcoin Script Roll 10000 PDFDocument2 pagesIdoc - Pub - Freebitcoin Script Roll 10000 PDFTemuulen MunkhjargalNo ratings yet
- Performance Testing of Different Grounding SystemsDocument8 pagesPerformance Testing of Different Grounding SystemsFernandoCrespoMonNo ratings yet
- Ex2. A 25 MVA, 1l KV, Three-Phase Generator Has A Sub Transient Reactance of 20%. TheDocument4 pagesEx2. A 25 MVA, 1l KV, Three-Phase Generator Has A Sub Transient Reactance of 20%. TheBharath Y KNo ratings yet
- 12 Lighting TechnologyDocument32 pages12 Lighting TechnologyngotiensiNo ratings yet
- SeaCom System Manual Rev 0401Document149 pagesSeaCom System Manual Rev 0401maselo100% (1)
- Catalogo Contactores en Vacio MitsubichiDocument16 pagesCatalogo Contactores en Vacio MitsubichiWalter CataldoNo ratings yet
- 4 RC Phase Shift Oscillator Using TransistorsDocument5 pages4 RC Phase Shift Oscillator Using TransistorsdamasNo ratings yet
- Medium Voltage Dry-Type ManualDocument6 pagesMedium Voltage Dry-Type ManualAjay AbrahamNo ratings yet
- Control 16C/T: Two-Way 6.5" Coaxial Ceiling Loudspeaker Key FeaturesDocument2 pagesControl 16C/T: Two-Way 6.5" Coaxial Ceiling Loudspeaker Key Featuresarij hhNo ratings yet
- 07-08 Panasonic Wall Split BrochureDocument16 pages07-08 Panasonic Wall Split BrochureAravindan MuthuNo ratings yet
- VGA Controller User GuideDocument11 pagesVGA Controller User GuideHoàng Thái SơnNo ratings yet
- Bathy 500 MFDocument58 pagesBathy 500 MFJohn E Cutipa LNo ratings yet
- Pilz-Pss Gm504s Documentation EnglishDocument55 pagesPilz-Pss Gm504s Documentation EnglishLuis angel RamirezNo ratings yet

























































































Download as pdf or txt
You might also like
- Energy Density of Aperiodic SignalsDocument9 pagesEnergy Density of Aperiodic SignalsaavdsNo ratings yet
- Homework For Module 5 : Quiz, 19 QuestionsDocument13 pagesHomework For Module 5 : Quiz, 19 QuestionsJustin Jose P33% (3)
- Rockwell Pricelist PDFDocument1,100 pagesRockwell Pricelist PDFsimbamikeNo ratings yet
- Bert Rowe's-Mercedes-Benz 'A'-Class Info. Mercedes Benz A Class W168 Automatic Transmission :gearboxDocument32 pagesBert Rowe's-Mercedes-Benz 'A'-Class Info. Mercedes Benz A Class W168 Automatic Transmission :gearboxJose Prieto67% (3)
- Outline: - Channel Capacity (Chapter 7) (Week 6)Document35 pagesOutline: - Channel Capacity (Chapter 7) (Week 6)HarshaNo ratings yet
- 1 MergedDocument182 pages1 MergedYash kumarNo ratings yet
- Least Squares: ORE 766 Numerical Methods in Ocean Engineering Instructor: Eva Marie NosalDocument24 pagesLeast Squares: ORE 766 Numerical Methods in Ocean Engineering Instructor: Eva Marie NosalDenis Constantin Ilie-AblachimNo ratings yet
- !!en5 Discrete Signals DTFT TZ v06Document11 pages!!en5 Discrete Signals DTFT TZ v06Marcela DobreNo ratings yet
- Kernel Methods: Dept. Computer Science & Engineering, Shanghai Jiao Tong UniversityDocument29 pagesKernel Methods: Dept. Computer Science & Engineering, Shanghai Jiao Tong UniversityPeter ParkerNo ratings yet
- AdvDSP Lecture1Document43 pagesAdvDSP Lecture1Alireza DabiryNo ratings yet
- RBF Neural NetworkDocument34 pagesRBF Neural NetworkSannan AhmedNo ratings yet
- Revision of Lecture 3: 1st-Order Markov ProcessDocument14 pagesRevision of Lecture 3: 1st-Order Markov ProcesshenkpiepNo ratings yet
- ECE 6151, Spring 2017 Lecture Notes: 1 OutlineDocument7 pagesECE 6151, Spring 2017 Lecture Notes: 1 OutlineLam DinhNo ratings yet
- Lect 3.2 Signal Space Analysis IDocument29 pagesLect 3.2 Signal Space Analysis Imid_cycloneNo ratings yet
- Trigonometric Fourier Series: - OutlineDocument23 pagesTrigonometric Fourier Series: - OutlineBoy KerenzNo ratings yet
- Chapter 4 Probability ReviewDocument20 pagesChapter 4 Probability ReviewŞamil ŞirinNo ratings yet
- Lecture 11Document7 pagesLecture 11mavisXzeref 17No ratings yet
- Fourier TransformDocument77 pagesFourier Transformtextile.km98No ratings yet
- FormalanalysisDocument26 pagesFormalanalysisShoaib ChNo ratings yet
- Statistics Formula Sheet-With TablesDocument5 pagesStatistics Formula Sheet-With TablesAnonymous uMSEZMNo ratings yet
- EE501 Adaptive Filter Design: Instructor: Dr. Farhan KhalidDocument26 pagesEE501 Adaptive Filter Design: Instructor: Dr. Farhan KhalidSana SaadNo ratings yet
- Lecture 6 - Spectrum Estimation PDFDocument47 pagesLecture 6 - Spectrum Estimation PDFMahy Magdy0% (1)
- A-Split Hopkinson Bar Test: - Reminder About Uniaxial Elastic Wave PropagationDocument27 pagesA-Split Hopkinson Bar Test: - Reminder About Uniaxial Elastic Wave Propagationahmadomar89No ratings yet
- Lecture 16 Transient Stability Solutions, Load ModelsDocument47 pagesLecture 16 Transient Stability Solutions, Load ModelsManuelNo ratings yet
- 3008 Lecture5 Random Signal AnalysisDocument16 pages3008 Lecture5 Random Signal AnalysisbalkyderNo ratings yet
- DimensionalityReduction PcaDocument24 pagesDimensionalityReduction PcauchenuangNo ratings yet
- Longitudinal Vibration of A Bar ": Presentation OnDocument17 pagesLongitudinal Vibration of A Bar ": Presentation OnamitpatelNo ratings yet
- InferenceDocument50 pagesInferencemahdieh.toodehNo ratings yet
- CH 07Document51 pagesCH 07陳浚維No ratings yet
- EE 278B: Random Processes 6 - 1Document16 pagesEE 278B: Random Processes 6 - 1Tahir saeedNo ratings yet
- Lect 06Document32 pagesLect 06Lucky AlamsyahNo ratings yet
- Formulasheet 22-23Document4 pagesFormulasheet 22-23Federico ScatignoNo ratings yet
- Lecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022Document22 pagesLecture5 Withleftover TaylorSeries ErrorAnalysis Aug10 2022rohit kumarNo ratings yet
- EGR 601 Formulas (v2)Document11 pagesEGR 601 Formulas (v2)Kawser AhmedNo ratings yet
- Look-Up Table: Solving Differential EquationsDocument10 pagesLook-Up Table: Solving Differential EquationsDr. S. DasNo ratings yet
- CurveDocument15 pagesCurveMohammed AlsirajNo ratings yet
- Channel Capacity and The Channel Coding Theorem, Part I: Information Theory 2013Document17 pagesChannel Capacity and The Channel Coding Theorem, Part I: Information Theory 2013Kate bossNo ratings yet
- Vu HPSC2012 02Document25 pagesVu HPSC2012 02Quốc Đông VũNo ratings yet
- 3 Fourier TransformDocument14 pages3 Fourier TransformHoney PhsNo ratings yet
- 5707 11 RNN LSTMDocument128 pages5707 11 RNN LSTMMayank KumarNo ratings yet
- Continuous-Time Systems: Dept. of Electrical and Computer Engineering The University of Texas at AustinDocument24 pagesContinuous-Time Systems: Dept. of Electrical and Computer Engineering The University of Texas at AustinEleazar Sierra EspinozaNo ratings yet
- 4 Spline MethodDocument29 pages4 Spline MethodEmdad HossainNo ratings yet
- FN CH 1Document52 pagesFN CH 1Md. Nurul AlamNo ratings yet
- Me310 5 Regression PDFDocument15 pagesMe310 5 Regression PDFiqbalNo ratings yet
- 6 - Random ProcessDocument14 pages6 - Random Processabd syNo ratings yet
- Fourier Analysis of Discrete Time SignalsDocument11 pagesFourier Analysis of Discrete Time SignalsprathikNo ratings yet
- Chapter 4 SlidesDocument40 pagesChapter 4 Slideskwaleed717No ratings yet
- Signals and SystemDocument13 pagesSignals and SystemraviNo ratings yet
- DSP HandoutsDocument11 pagesDSP HandoutsG A E SATISH KUMARNo ratings yet
- Bit-And Power-Loading: EIT 140, Tom AT Eit - Lth.seDocument26 pagesBit-And Power-Loading: EIT 140, Tom AT Eit - Lth.sedeepa2400No ratings yet
- 6 Random Signal AnalysisDocument16 pages6 Random Signal AnalysisFêyø Õrö MãñNo ratings yet
- 3.2 Convolución GráficaDocument41 pages3.2 Convolución GráficaAlvaro Pardo SandovalNo ratings yet
- Fundamentals For Finite Element MethodDocument34 pagesFundamentals For Finite Element MethodnaderNo ratings yet
- EECS3451 Chapter4Document79 pagesEECS3451 Chapter4nickbekiaris05No ratings yet
- Frequency Domain Repr. and Signal Sampling 1Document61 pagesFrequency Domain Repr. and Signal Sampling 1Rogers Rodri ShayoNo ratings yet
- Z Transform PrimerDocument11 pagesZ Transform Primerveicastaneda14No ratings yet
- EE6340: Information Theory Problem Set 7: I I I I I I I I 1 2 N N NDocument1 pageEE6340: Information Theory Problem Set 7: I I I I I I I I 1 2 N N NSupriya DiwanNo ratings yet
- Finite Impulse Response FiltersDocument24 pagesFinite Impulse Response Filtersboulainine houriaNo ratings yet
- Coding 515Document92 pagesCoding 515essaidi.noureddineNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- On the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)From EverandOn the Tangent Space to the Space of Algebraic Cycles on a Smooth Algebraic Variety. (AM-157)No ratings yet
- The Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64From EverandThe Equidistribution Theory of Holomorphic Curves. (AM-64), Volume 64No ratings yet
- High Voltage MOSFETsDocument31 pagesHigh Voltage MOSFETsharendraNo ratings yet
- KABA SL525 Product PresentationDocument22 pagesKABA SL525 Product PresentationAnthony ReedNo ratings yet
- SL 70953 Liebert Gxt5 Lithium Ion 1 3kva I 230v Ups User GuideDocument70 pagesSL 70953 Liebert Gxt5 Lithium Ion 1 3kva I 230v Ups User Guidepetermaroko69No ratings yet
- Asfjh PDFDocument22 pagesAsfjh PDFTzvetan DimitrovNo ratings yet
- Argus Radar System: Installation & Service ManualDocument154 pagesArgus Radar System: Installation & Service ManualNguyễn DanhNo ratings yet
- ContactorDocument10 pagesContactorprimarajNo ratings yet
- Acti 9 iEM3000 - A9MEM3235Document2 pagesActi 9 iEM3000 - A9MEM3235tungNo ratings yet
- M1293-E HATHOR User ManualDocument324 pagesM1293-E HATHOR User ManualDorin Alexandru PărăuNo ratings yet
- Toshiba VRF Commsiioning Sequence PDFDocument4 pagesToshiba VRF Commsiioning Sequence PDFtonylyf100% (1)
- Battery, Charger, Ups System - NewDocument32 pagesBattery, Charger, Ups System - NewDheeraj Kumar PendyalaNo ratings yet
- Ascgroup Scada-Bms TD en v6Document29 pagesAscgroup Scada-Bms TD en v6Jothimanikkam SomasundaramNo ratings yet
- Seminar On Bluetooth and WifiDocument39 pagesSeminar On Bluetooth and WifiSuhel Mulla75% (4)
- Sil MTL4544 - 1Document2 pagesSil MTL4544 - 1Andy Kong King100% (1)
- Chapter 5 - Internal MemoryDocument33 pagesChapter 5 - Internal MemoryHPManchester100% (1)
- E9905G 2-Module In-Circuit Test (ICT) System, I327x Series 6 - KeysightDocument1 pageE9905G 2-Module In-Circuit Test (ICT) System, I327x Series 6 - Keysightpc100xohmNo ratings yet
- Idoc - Pub - Freebitcoin Script Roll 10000 PDFDocument2 pagesIdoc - Pub - Freebitcoin Script Roll 10000 PDFTemuulen MunkhjargalNo ratings yet
- Performance Testing of Different Grounding SystemsDocument8 pagesPerformance Testing of Different Grounding SystemsFernandoCrespoMonNo ratings yet
- Ex2. A 25 MVA, 1l KV, Three-Phase Generator Has A Sub Transient Reactance of 20%. TheDocument4 pagesEx2. A 25 MVA, 1l KV, Three-Phase Generator Has A Sub Transient Reactance of 20%. TheBharath Y KNo ratings yet
- 12 Lighting TechnologyDocument32 pages12 Lighting TechnologyngotiensiNo ratings yet
- SeaCom System Manual Rev 0401Document149 pagesSeaCom System Manual Rev 0401maselo100% (1)
- Catalogo Contactores en Vacio MitsubichiDocument16 pagesCatalogo Contactores en Vacio MitsubichiWalter CataldoNo ratings yet
- 4 RC Phase Shift Oscillator Using TransistorsDocument5 pages4 RC Phase Shift Oscillator Using TransistorsdamasNo ratings yet
- Medium Voltage Dry-Type ManualDocument6 pagesMedium Voltage Dry-Type ManualAjay AbrahamNo ratings yet
- Control 16C/T: Two-Way 6.5" Coaxial Ceiling Loudspeaker Key FeaturesDocument2 pagesControl 16C/T: Two-Way 6.5" Coaxial Ceiling Loudspeaker Key Featuresarij hhNo ratings yet
- 07-08 Panasonic Wall Split BrochureDocument16 pages07-08 Panasonic Wall Split BrochureAravindan MuthuNo ratings yet
- VGA Controller User GuideDocument11 pagesVGA Controller User GuideHoàng Thái SơnNo ratings yet
- Bathy 500 MFDocument58 pagesBathy 500 MFJohn E Cutipa LNo ratings yet
- Pilz-Pss Gm504s Documentation EnglishDocument55 pagesPilz-Pss Gm504s Documentation EnglishLuis angel RamirezNo ratings yet