
Statistics For Management: Omar Paccagnella
Statistics For Management: Omar Paccagnella
You might also like
- Minitab Engage - Periodic Table of Problem-Solving Methodologies Ebook - ENDocument6 pagesMinitab Engage - Periodic Table of Problem-Solving Methodologies Ebook - ENleticia0% (1)
- VIMS Application Guide (SELD7001)Document114 pagesVIMS Application Guide (SELD7001)Wilson Claveria86% (7)
- MET604 Majid Week-02 Lecture-01Document48 pagesMET604 Majid Week-02 Lecture-01Ehsan HaroonNo ratings yet
- MAT2001-SE Course Materials - Module 3 PDFDocument32 pagesMAT2001-SE Course Materials - Module 3 PDFKiruthiga DeepikaNo ratings yet
- WINSEM2020-21 MAT2001 ETH VL2020210505834 Reference Material I 25-Mar-2021 Module 3 - Correlation and RegressionDocument31 pagesWINSEM2020-21 MAT2001 ETH VL2020210505834 Reference Material I 25-Mar-2021 Module 3 - Correlation and RegressiondeepanshuNo ratings yet
- SpatstatDocument75 pagesSpatstatAgatha AstriseleNo ratings yet
- Chapter 5 Regression AnalysisDocument14 pagesChapter 5 Regression AnalysisLeslie Anne BiteNo ratings yet
- Functional Local Linear Estimate For Functional Relative-Error RegressionDocument20 pagesFunctional Local Linear Estimate For Functional Relative-Error Regressionالشمس اشرقتNo ratings yet
- Iassc Lean Six Sigma Green Belt: Analyse Phase: Course StructureDocument75 pagesIassc Lean Six Sigma Green Belt: Analyse Phase: Course StructureDimitris PapamatthaiakisNo ratings yet
- ML Assignment No. 1: 1.1 TitleDocument8 pagesML Assignment No. 1: 1.1 TitleKirti PhegadeNo ratings yet
- Stochastic Optimization Algorithms For Instrumental Variable Regression With Streaming DataDocument30 pagesStochastic Optimization Algorithms For Instrumental Variable Regression With Streaming DatagamininganelaNo ratings yet
- Chapter Five: Regression and CorrelationDocument12 pagesChapter Five: Regression and Correlationጌታ እኮ ነውNo ratings yet
- Week 10: Basic ConceptDocument11 pagesWeek 10: Basic ConceptmichaelNo ratings yet
- The Effect of Parameter Estimation On X-Bar Control Charts For The Lognormal DistributionDocument16 pagesThe Effect of Parameter Estimation On X-Bar Control Charts For The Lognormal Distributionroshni.t0707No ratings yet
- Cha 6Document8 pagesCha 6Senay HaftuNo ratings yet
- Gakhov Time Series Forecasting With PythonDocument66 pagesGakhov Time Series Forecasting With PythonSadık DelioğluNo ratings yet
- Module 1 Additional NotesDocument7 pagesModule 1 Additional NotesWaqas KhanNo ratings yet
- Statistical Analysis TechniquesDocument11 pagesStatistical Analysis TechniquesSashiNo ratings yet
- Part3. 实用教程 - Practical Regression and ANOVA using RDocument102 pagesPart3. 实用教程 - Practical Regression and ANOVA using Rapi-19919644No ratings yet
- Correlation Regression - 2023Document69 pagesCorrelation Regression - 2023Writabrata BhattacharyaNo ratings yet
- Stat RevisionDocument23 pagesStat Revisiongamingleague777No ratings yet
- ch.3 Part 2Document4 pagesch.3 Part 2Mohamed ZizoNo ratings yet
- Statistical Process Control (SPC)Document66 pagesStatistical Process Control (SPC)Fritz Jay TorreNo ratings yet
- DIT W16 RegressionDocument58 pagesDIT W16 RegressionBill FASSINOUNo ratings yet
- 8 Chapter SummaryDocument3 pages8 Chapter SummaryJob PolvorizaNo ratings yet
- Lecture 1. Part 1-Regression Analysis. Correlation and SLRMDocument44 pagesLecture 1. Part 1-Regression Analysis. Correlation and SLRMRichelle PausangNo ratings yet
- Chapter 14 (14.1 - 14.2)Document22 pagesChapter 14 (14.1 - 14.2)JaydeNo ratings yet
- BPCC-104 EM 2021-22 IHT 7980393936 - WatermarkedDocument12 pagesBPCC-104 EM 2021-22 IHT 7980393936 - Watermarkedtanzeelarahman31No ratings yet
- 1-7 Least-Square RegressionDocument23 pages1-7 Least-Square RegressionRawash Omar100% (1)
- Estimating Demand FunctionDocument45 pagesEstimating Demand FunctionManisha AdliNo ratings yet
- Lecture 05 - Linear RegressionDocument12 pagesLecture 05 - Linear RegressionRamona CirstianNo ratings yet
- An Alternative Approach To AIC and Mallow's CP Statistics Based Relative Influence Measure (RIMs) in Regression Variable SelectionDocument6 pagesAn Alternative Approach To AIC and Mallow's CP Statistics Based Relative Influence Measure (RIMs) in Regression Variable SelectionObulezi OJNo ratings yet
- Chapter 2 Simple Linear RegressionDocument60 pagesChapter 2 Simple Linear RegressionChriss TwhNo ratings yet
- Regression Analysis For Forecasting: Yosef DaryantoDocument36 pagesRegression Analysis For Forecasting: Yosef DaryantoEvan KartikaNo ratings yet
- Correlation and Regression: Libeeth B. GuevarraDocument10 pagesCorrelation and Regression: Libeeth B. GuevarraReanne MedianoNo ratings yet
- Time Series Analysis Using e ViewsDocument131 pagesTime Series Analysis Using e ViewsNabeel Mahdi Aljanabi100% (1)
- PPT 08 - Quantitative Data AnalysisDocument51 pagesPPT 08 - Quantitative Data AnalysisZakaria AliNo ratings yet
- SPC V V IyerDocument85 pagesSPC V V IyerAravind KumarNo ratings yet
- Business Mathematics & StatisticsDocument31 pagesBusiness Mathematics & StatisticszainaliNo ratings yet
- Trends of Rainfall and Rice Yield of Cities in PunjabDocument3 pagesTrends of Rainfall and Rice Yield of Cities in PunjabInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- SOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsDocument113 pagesSOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsCaroline KapilaNo ratings yet
- Lectures 8 9 10Document185 pagesLectures 8 9 10AzmiHafifiNo ratings yet
- Week 5 Empirical - Methods 2Document20 pagesWeek 5 Empirical - Methods 2muller1234No ratings yet
- Agresti Ordinal TutorialDocument75 pagesAgresti Ordinal TutorialKen MatsudaNo ratings yet
- Analyze 01 - Understanding GraphsDocument21 pagesAnalyze 01 - Understanding GraphsSaumya GunawardanaNo ratings yet
- SEEC DiscussionPaper No8Document24 pagesSEEC DiscussionPaper No8Shuchi GoelNo ratings yet
- CHM121 - Module 3 - Evaluation of Analytical DataDocument114 pagesCHM121 - Module 3 - Evaluation of Analytical DataNeil WarrenNo ratings yet
- 0810 4808 PDFDocument25 pages0810 4808 PDFAyush ChopraNo ratings yet
- Unit IiiDocument101 pagesUnit IiiMECH HODNo ratings yet
- Bda 1Document28 pagesBda 1Ikhsan WijayaNo ratings yet
- Executive Summary: Business Statistics 061 - Fp-036 Final ReportDocument35 pagesExecutive Summary: Business Statistics 061 - Fp-036 Final ReportOneway BongNo ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Statistical Analysis: Linear RegressionDocument36 pagesStatistical Analysis: Linear RegressionDafter KhemboNo ratings yet
- 1.10 Simple Linear Regression - AnswersDocument22 pages1.10 Simple Linear Regression - AnswersThe SpectreNo ratings yet
- Fundamentals of Biostatistics: August 2017Document123 pagesFundamentals of Biostatistics: August 2017Velu SamyNo ratings yet
- StefanoIacus PDFDocument128 pagesStefanoIacus PDFmathibettuNo ratings yet
- Linear Regression Analysis. Statistics 2 NotesDocument20 pagesLinear Regression Analysis. Statistics 2 NotesNAJJEMBA WINNIFREDNo ratings yet
- Economic Statistical Design of X Bar Control ChartDocument14 pagesEconomic Statistical Design of X Bar Control ChartAtif AvdovićNo ratings yet
- Statistics NotesDocument32 pagesStatistics Notesxujamin90No ratings yet
- Tut-1-Cvg4150-2016-For PostingDocument20 pagesTut-1-Cvg4150-2016-For PostingLokiNo ratings yet
- Level Set Method: Advancing Computer Vision, Exploring the Level Set MethodFrom EverandLevel Set Method: Advancing Computer Vision, Exploring the Level Set MethodNo ratings yet
- Neurobiology Assignment PDFDocument2 pagesNeurobiology Assignment PDFThe Panda EntertainerNo ratings yet
- 24 Short - Term - Depression - TC FFI - Optional PDFDocument9 pages24 Short - Term - Depression - TC FFI - Optional PDFThe Panda EntertainerNo ratings yet
- Stimulation of Neuronal Activity With LightDocument29 pagesStimulation of Neuronal Activity With LightThe Panda EntertainerNo ratings yet
- 25 Learning - Memory1 PDFDocument28 pages25 Learning - Memory1 PDFThe Panda EntertainerNo ratings yet
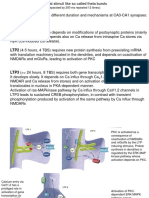
- LTP1 ( 2 Hours, 1 TBS) Depends On Modifications of Postsynaptic Proteins (MainlyDocument12 pagesLTP1 ( 2 Hours, 1 TBS) Depends On Modifications of Postsynaptic Proteins (MainlyThe Panda EntertainerNo ratings yet
- Mechanisms of Short-Term Synaptic PlasticityDocument13 pagesMechanisms of Short-Term Synaptic PlasticityThe Panda EntertainerNo ratings yet
- 21 Synaptic Plasticity - Short - Term PDFDocument19 pages21 Synaptic Plasticity - Short - Term PDFThe Panda EntertainerNo ratings yet
- Synaptic Depression: Many Different Possible MechanismsDocument24 pagesSynaptic Depression: Many Different Possible MechanismsThe Panda EntertainerNo ratings yet
- 28 Optical - Techniques PDFDocument28 pages28 Optical - Techniques PDFThe Panda EntertainerNo ratings yet
- 20 Synaptic Transmission - Vel - Ca - Nano Vs Microdomains PDFDocument23 pages20 Synaptic Transmission - Vel - Ca - Nano Vs Microdomains PDFThe Panda EntertainerNo ratings yet
- LydiaDocument219 pagesLydiatayabakhanNo ratings yet
- Aligned Automation - JD - Business AnalystDocument2 pagesAligned Automation - JD - Business Analystuday vengalaNo ratings yet
- bt1101 Cheat SheetDocument3 pagesbt1101 Cheat SheetRandom DudeNo ratings yet
- Introduction To Google Earth Engine: Warren Scott February 24, 2021Document32 pagesIntroduction To Google Earth Engine: Warren Scott February 24, 2021ilmiNo ratings yet
- GemPremier3000 ManualDocument24 pagesGemPremier3000 ManualAlina OpreaNo ratings yet
- ECMT1010 Final FormulaDocument2 pagesECMT1010 Final FormulaAbdulla ShaheedNo ratings yet
- HEC Approved Ethical GuidelinesDocument12 pagesHEC Approved Ethical GuidelinesMuhammad Asif JoyoNo ratings yet
- Research 111119Document47 pagesResearch 111119Eva LumantaNo ratings yet
- Strategic Alliances For Corporate Sustainability Innovation - 2022 - Long RangeDocument20 pagesStrategic Alliances For Corporate Sustainability Innovation - 2022 - Long RangeHisham HeedaNo ratings yet
- Census Analysis Project STAT 330Document22 pagesCensus Analysis Project STAT 330Robert LeeNo ratings yet
- Panchamrut DairyDocument52 pagesPanchamrut DairyAksha Khan50% (2)
- ANOVA, Correlation and Regression: Dr. Faris Al Lami MB, CHB PHD FFPHDocument40 pagesANOVA, Correlation and Regression: Dr. Faris Al Lami MB, CHB PHD FFPHمحمود محمدNo ratings yet
- Data Analytics Explained EasilyDocument2 pagesData Analytics Explained EasilySai ManasaNo ratings yet
- Sources of Validity Evidence PDFDocument14 pagesSources of Validity Evidence PDFhbakry9608No ratings yet
- Flow Diagram of Machine Learning or Life Cycle of Machine LearningDocument91 pagesFlow Diagram of Machine Learning or Life Cycle of Machine LearningJay MangukiyaNo ratings yet
- Human Evaluation of Automatically Generated Text CDocument24 pagesHuman Evaluation of Automatically Generated Text CYunus Emre CoşkunNo ratings yet
- Fyp SlideDocument52 pagesFyp SlideZulhilmi ZalizanNo ratings yet
- Flight Delay Prediction System Paper - 802 - 826 - 828Document7 pagesFlight Delay Prediction System Paper - 802 - 826 - 828aepatil74No ratings yet
- Study On Working Capital ManagementDocument25 pagesStudy On Working Capital ManagementAmrutha Ammu100% (1)
- FEU Institute of Technology: Laboratory Report #8Document4 pagesFEU Institute of Technology: Laboratory Report #8piknikmonsterNo ratings yet
- MAS202 - Homework For Chapter 13-14Document7 pagesMAS202 - Homework For Chapter 13-14Bui Van Anh (K15 HL)No ratings yet
- THE Impact OF Promotional Mix-Elements On Sales Volume: (In Case of Anbessa Shoe Share Co.)Document54 pagesTHE Impact OF Promotional Mix-Elements On Sales Volume: (In Case of Anbessa Shoe Share Co.)Jessa Mae Solivio LuzaNo ratings yet
- Lecture - 6.1 and 6.2 - Correlation AnalysisDocument16 pagesLecture - 6.1 and 6.2 - Correlation AnalysisElham AjmotgirNo ratings yet
- SL Paper2Document26 pagesSL Paper2aftabNo ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- Lecture 7 TestDocument35 pagesLecture 7 Test21142467No ratings yet
- AOS (2004) Cooper and SlagmulderDocument26 pagesAOS (2004) Cooper and SlagmulderjpltsangNo ratings yet
- Statistical Modeling For Data AnalysisDocument24 pagesStatistical Modeling For Data Analysisfisha adaneNo ratings yet



































































































Download as pdf or txt
You might also like
- Minitab Engage - Periodic Table of Problem-Solving Methodologies Ebook - ENDocument6 pagesMinitab Engage - Periodic Table of Problem-Solving Methodologies Ebook - ENleticia0% (1)
- VIMS Application Guide (SELD7001)Document114 pagesVIMS Application Guide (SELD7001)Wilson Claveria86% (7)
- MET604 Majid Week-02 Lecture-01Document48 pagesMET604 Majid Week-02 Lecture-01Ehsan HaroonNo ratings yet
- MAT2001-SE Course Materials - Module 3 PDFDocument32 pagesMAT2001-SE Course Materials - Module 3 PDFKiruthiga DeepikaNo ratings yet
- WINSEM2020-21 MAT2001 ETH VL2020210505834 Reference Material I 25-Mar-2021 Module 3 - Correlation and RegressionDocument31 pagesWINSEM2020-21 MAT2001 ETH VL2020210505834 Reference Material I 25-Mar-2021 Module 3 - Correlation and RegressiondeepanshuNo ratings yet
- SpatstatDocument75 pagesSpatstatAgatha AstriseleNo ratings yet
- Chapter 5 Regression AnalysisDocument14 pagesChapter 5 Regression AnalysisLeslie Anne BiteNo ratings yet
- Functional Local Linear Estimate For Functional Relative-Error RegressionDocument20 pagesFunctional Local Linear Estimate For Functional Relative-Error Regressionالشمس اشرقتNo ratings yet
- Iassc Lean Six Sigma Green Belt: Analyse Phase: Course StructureDocument75 pagesIassc Lean Six Sigma Green Belt: Analyse Phase: Course StructureDimitris PapamatthaiakisNo ratings yet
- ML Assignment No. 1: 1.1 TitleDocument8 pagesML Assignment No. 1: 1.1 TitleKirti PhegadeNo ratings yet
- Stochastic Optimization Algorithms For Instrumental Variable Regression With Streaming DataDocument30 pagesStochastic Optimization Algorithms For Instrumental Variable Regression With Streaming DatagamininganelaNo ratings yet
- Chapter Five: Regression and CorrelationDocument12 pagesChapter Five: Regression and Correlationጌታ እኮ ነውNo ratings yet
- Week 10: Basic ConceptDocument11 pagesWeek 10: Basic ConceptmichaelNo ratings yet
- The Effect of Parameter Estimation On X-Bar Control Charts For The Lognormal DistributionDocument16 pagesThe Effect of Parameter Estimation On X-Bar Control Charts For The Lognormal Distributionroshni.t0707No ratings yet
- Cha 6Document8 pagesCha 6Senay HaftuNo ratings yet
- Gakhov Time Series Forecasting With PythonDocument66 pagesGakhov Time Series Forecasting With PythonSadık DelioğluNo ratings yet
- Module 1 Additional NotesDocument7 pagesModule 1 Additional NotesWaqas KhanNo ratings yet
- Statistical Analysis TechniquesDocument11 pagesStatistical Analysis TechniquesSashiNo ratings yet
- Part3. 实用教程 - Practical Regression and ANOVA using RDocument102 pagesPart3. 实用教程 - Practical Regression and ANOVA using Rapi-19919644No ratings yet
- Correlation Regression - 2023Document69 pagesCorrelation Regression - 2023Writabrata BhattacharyaNo ratings yet
- Stat RevisionDocument23 pagesStat Revisiongamingleague777No ratings yet
- ch.3 Part 2Document4 pagesch.3 Part 2Mohamed ZizoNo ratings yet
- Statistical Process Control (SPC)Document66 pagesStatistical Process Control (SPC)Fritz Jay TorreNo ratings yet
- DIT W16 RegressionDocument58 pagesDIT W16 RegressionBill FASSINOUNo ratings yet
- 8 Chapter SummaryDocument3 pages8 Chapter SummaryJob PolvorizaNo ratings yet
- Lecture 1. Part 1-Regression Analysis. Correlation and SLRMDocument44 pagesLecture 1. Part 1-Regression Analysis. Correlation and SLRMRichelle PausangNo ratings yet
- Chapter 14 (14.1 - 14.2)Document22 pagesChapter 14 (14.1 - 14.2)JaydeNo ratings yet
- BPCC-104 EM 2021-22 IHT 7980393936 - WatermarkedDocument12 pagesBPCC-104 EM 2021-22 IHT 7980393936 - Watermarkedtanzeelarahman31No ratings yet
- 1-7 Least-Square RegressionDocument23 pages1-7 Least-Square RegressionRawash Omar100% (1)
- Estimating Demand FunctionDocument45 pagesEstimating Demand FunctionManisha AdliNo ratings yet
- Lecture 05 - Linear RegressionDocument12 pagesLecture 05 - Linear RegressionRamona CirstianNo ratings yet
- An Alternative Approach To AIC and Mallow's CP Statistics Based Relative Influence Measure (RIMs) in Regression Variable SelectionDocument6 pagesAn Alternative Approach To AIC and Mallow's CP Statistics Based Relative Influence Measure (RIMs) in Regression Variable SelectionObulezi OJNo ratings yet
- Chapter 2 Simple Linear RegressionDocument60 pagesChapter 2 Simple Linear RegressionChriss TwhNo ratings yet
- Regression Analysis For Forecasting: Yosef DaryantoDocument36 pagesRegression Analysis For Forecasting: Yosef DaryantoEvan KartikaNo ratings yet
- Correlation and Regression: Libeeth B. GuevarraDocument10 pagesCorrelation and Regression: Libeeth B. GuevarraReanne MedianoNo ratings yet
- Time Series Analysis Using e ViewsDocument131 pagesTime Series Analysis Using e ViewsNabeel Mahdi Aljanabi100% (1)
- PPT 08 - Quantitative Data AnalysisDocument51 pagesPPT 08 - Quantitative Data AnalysisZakaria AliNo ratings yet
- SPC V V IyerDocument85 pagesSPC V V IyerAravind KumarNo ratings yet
- Business Mathematics & StatisticsDocument31 pagesBusiness Mathematics & StatisticszainaliNo ratings yet
- Trends of Rainfall and Rice Yield of Cities in PunjabDocument3 pagesTrends of Rainfall and Rice Yield of Cities in PunjabInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- SOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsDocument113 pagesSOB 1040 Lecture 2 - Data Organisation and Descriptive StatisticsCaroline KapilaNo ratings yet
- Lectures 8 9 10Document185 pagesLectures 8 9 10AzmiHafifiNo ratings yet
- Week 5 Empirical - Methods 2Document20 pagesWeek 5 Empirical - Methods 2muller1234No ratings yet
- Agresti Ordinal TutorialDocument75 pagesAgresti Ordinal TutorialKen MatsudaNo ratings yet
- Analyze 01 - Understanding GraphsDocument21 pagesAnalyze 01 - Understanding GraphsSaumya GunawardanaNo ratings yet
- SEEC DiscussionPaper No8Document24 pagesSEEC DiscussionPaper No8Shuchi GoelNo ratings yet
- CHM121 - Module 3 - Evaluation of Analytical DataDocument114 pagesCHM121 - Module 3 - Evaluation of Analytical DataNeil WarrenNo ratings yet
- 0810 4808 PDFDocument25 pages0810 4808 PDFAyush ChopraNo ratings yet
- Unit IiiDocument101 pagesUnit IiiMECH HODNo ratings yet
- Bda 1Document28 pagesBda 1Ikhsan WijayaNo ratings yet
- Executive Summary: Business Statistics 061 - Fp-036 Final ReportDocument35 pagesExecutive Summary: Business Statistics 061 - Fp-036 Final ReportOneway BongNo ratings yet
- Applied Statistics II-SLRDocument23 pagesApplied Statistics II-SLRMagnifico FangaWoro100% (1)
- Statistical Analysis: Linear RegressionDocument36 pagesStatistical Analysis: Linear RegressionDafter KhemboNo ratings yet
- 1.10 Simple Linear Regression - AnswersDocument22 pages1.10 Simple Linear Regression - AnswersThe SpectreNo ratings yet
- Fundamentals of Biostatistics: August 2017Document123 pagesFundamentals of Biostatistics: August 2017Velu SamyNo ratings yet
- StefanoIacus PDFDocument128 pagesStefanoIacus PDFmathibettuNo ratings yet
- Linear Regression Analysis. Statistics 2 NotesDocument20 pagesLinear Regression Analysis. Statistics 2 NotesNAJJEMBA WINNIFREDNo ratings yet
- Economic Statistical Design of X Bar Control ChartDocument14 pagesEconomic Statistical Design of X Bar Control ChartAtif AvdovićNo ratings yet
- Statistics NotesDocument32 pagesStatistics Notesxujamin90No ratings yet
- Tut-1-Cvg4150-2016-For PostingDocument20 pagesTut-1-Cvg4150-2016-For PostingLokiNo ratings yet
- Level Set Method: Advancing Computer Vision, Exploring the Level Set MethodFrom EverandLevel Set Method: Advancing Computer Vision, Exploring the Level Set MethodNo ratings yet
- Neurobiology Assignment PDFDocument2 pagesNeurobiology Assignment PDFThe Panda EntertainerNo ratings yet
- 24 Short - Term - Depression - TC FFI - Optional PDFDocument9 pages24 Short - Term - Depression - TC FFI - Optional PDFThe Panda EntertainerNo ratings yet
- Stimulation of Neuronal Activity With LightDocument29 pagesStimulation of Neuronal Activity With LightThe Panda EntertainerNo ratings yet
- 25 Learning - Memory1 PDFDocument28 pages25 Learning - Memory1 PDFThe Panda EntertainerNo ratings yet
- LTP1 ( 2 Hours, 1 TBS) Depends On Modifications of Postsynaptic Proteins (MainlyDocument12 pagesLTP1 ( 2 Hours, 1 TBS) Depends On Modifications of Postsynaptic Proteins (MainlyThe Panda EntertainerNo ratings yet
- Mechanisms of Short-Term Synaptic PlasticityDocument13 pagesMechanisms of Short-Term Synaptic PlasticityThe Panda EntertainerNo ratings yet
- 21 Synaptic Plasticity - Short - Term PDFDocument19 pages21 Synaptic Plasticity - Short - Term PDFThe Panda EntertainerNo ratings yet
- Synaptic Depression: Many Different Possible MechanismsDocument24 pagesSynaptic Depression: Many Different Possible MechanismsThe Panda EntertainerNo ratings yet
- 28 Optical - Techniques PDFDocument28 pages28 Optical - Techniques PDFThe Panda EntertainerNo ratings yet
- 20 Synaptic Transmission - Vel - Ca - Nano Vs Microdomains PDFDocument23 pages20 Synaptic Transmission - Vel - Ca - Nano Vs Microdomains PDFThe Panda EntertainerNo ratings yet
- LydiaDocument219 pagesLydiatayabakhanNo ratings yet
- Aligned Automation - JD - Business AnalystDocument2 pagesAligned Automation - JD - Business Analystuday vengalaNo ratings yet
- bt1101 Cheat SheetDocument3 pagesbt1101 Cheat SheetRandom DudeNo ratings yet
- Introduction To Google Earth Engine: Warren Scott February 24, 2021Document32 pagesIntroduction To Google Earth Engine: Warren Scott February 24, 2021ilmiNo ratings yet
- GemPremier3000 ManualDocument24 pagesGemPremier3000 ManualAlina OpreaNo ratings yet
- ECMT1010 Final FormulaDocument2 pagesECMT1010 Final FormulaAbdulla ShaheedNo ratings yet
- HEC Approved Ethical GuidelinesDocument12 pagesHEC Approved Ethical GuidelinesMuhammad Asif JoyoNo ratings yet
- Research 111119Document47 pagesResearch 111119Eva LumantaNo ratings yet
- Strategic Alliances For Corporate Sustainability Innovation - 2022 - Long RangeDocument20 pagesStrategic Alliances For Corporate Sustainability Innovation - 2022 - Long RangeHisham HeedaNo ratings yet
- Census Analysis Project STAT 330Document22 pagesCensus Analysis Project STAT 330Robert LeeNo ratings yet
- Panchamrut DairyDocument52 pagesPanchamrut DairyAksha Khan50% (2)
- ANOVA, Correlation and Regression: Dr. Faris Al Lami MB, CHB PHD FFPHDocument40 pagesANOVA, Correlation and Regression: Dr. Faris Al Lami MB, CHB PHD FFPHمحمود محمدNo ratings yet
- Data Analytics Explained EasilyDocument2 pagesData Analytics Explained EasilySai ManasaNo ratings yet
- Sources of Validity Evidence PDFDocument14 pagesSources of Validity Evidence PDFhbakry9608No ratings yet
- Flow Diagram of Machine Learning or Life Cycle of Machine LearningDocument91 pagesFlow Diagram of Machine Learning or Life Cycle of Machine LearningJay MangukiyaNo ratings yet
- Human Evaluation of Automatically Generated Text CDocument24 pagesHuman Evaluation of Automatically Generated Text CYunus Emre CoşkunNo ratings yet
- Fyp SlideDocument52 pagesFyp SlideZulhilmi ZalizanNo ratings yet
- Flight Delay Prediction System Paper - 802 - 826 - 828Document7 pagesFlight Delay Prediction System Paper - 802 - 826 - 828aepatil74No ratings yet
- Study On Working Capital ManagementDocument25 pagesStudy On Working Capital ManagementAmrutha Ammu100% (1)
- FEU Institute of Technology: Laboratory Report #8Document4 pagesFEU Institute of Technology: Laboratory Report #8piknikmonsterNo ratings yet
- MAS202 - Homework For Chapter 13-14Document7 pagesMAS202 - Homework For Chapter 13-14Bui Van Anh (K15 HL)No ratings yet
- THE Impact OF Promotional Mix-Elements On Sales Volume: (In Case of Anbessa Shoe Share Co.)Document54 pagesTHE Impact OF Promotional Mix-Elements On Sales Volume: (In Case of Anbessa Shoe Share Co.)Jessa Mae Solivio LuzaNo ratings yet
- Lecture - 6.1 and 6.2 - Correlation AnalysisDocument16 pagesLecture - 6.1 and 6.2 - Correlation AnalysisElham AjmotgirNo ratings yet
- SL Paper2Document26 pagesSL Paper2aftabNo ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- Lecture 7 TestDocument35 pagesLecture 7 Test21142467No ratings yet
- AOS (2004) Cooper and SlagmulderDocument26 pagesAOS (2004) Cooper and SlagmulderjpltsangNo ratings yet
- Statistical Modeling For Data AnalysisDocument24 pagesStatistical Modeling For Data Analysisfisha adaneNo ratings yet