Download as pdf or txt
You might also like
- Statistics-for-Engineering-and-the-Sciences-Sixth-Edition - ESI 5219 PDFDocument1,170 pagesStatistics-for-Engineering-and-the-Sciences-Sixth-Edition - ESI 5219 PDFAnh H. Dinh100% (2)
- OU Open University SM358 2013 Exam SolutionsDocument54 pagesOU Open University SM358 2013 Exam Solutionssam smith100% (3)
- Handbook of Quantitative Supply Chain AnalysisDocument818 pagesHandbook of Quantitative Supply Chain AnalysisKondreddy Nageswara Reddy100% (5)
- Statistics, Data Mining, and Machine Learning in Astronomy: A Practical Python Guide for the Analysis of Survey Data, Updated EditionFrom EverandStatistics, Data Mining, and Machine Learning in Astronomy: A Practical Python Guide for the Analysis of Survey Data, Updated EditionNo ratings yet
- Bayesian Statistical Methods (Brian J. Reich, Sujit K. Ghosh)Document288 pagesBayesian Statistical Methods (Brian J. Reich, Sujit K. Ghosh)edwarzambranoNo ratings yet
- Keith McNulty - Handbook of Regression Modeling in People Analytics-Routledge (2021)Document272 pagesKeith McNulty - Handbook of Regression Modeling in People Analytics-Routledge (2021)Black Raven100% (1)
- Tenko Raykov, George A. Marcoulides-Basic Statistics - An Introduction With R-Rowman & Littlefield Publishers (2012) PDFDocument345 pagesTenko Raykov, George A. Marcoulides-Basic Statistics - An Introduction With R-Rowman & Littlefield Publishers (2012) PDFKunal YadavNo ratings yet
- Daphne Koller, Nir Friedman Probabilistic Graphical Models Principles and Techniques 2009Document1,270 pagesDaphne Koller, Nir Friedman Probabilistic Graphical Models Principles and Techniques 2009Sigvart Aaserud Midling-Hansen100% (10)
- AL Problem Solving Process Manual - Updated 10 - May 2016Document74 pagesAL Problem Solving Process Manual - Updated 10 - May 2016Akshi Karthikeyan100% (1)
- American Girl Presentaton Team-6Document9 pagesAmerican Girl Presentaton Team-6Ashish Kaushal RanjanNo ratings yet
- Paola Zuccolotto - Marica Manisera - Basketball Data Science - With Applications in R-CRC Press (2020)Document245 pagesPaola Zuccolotto - Marica Manisera - Basketball Data Science - With Applications in R-CRC Press (2020)tamexid239No ratings yet
- Data Visualization Charts, Maps, and Interactive GraphicsDocument249 pagesData Visualization Charts, Maps, and Interactive Graphicsvgkkctnd100% (11)
- Ebook Object Oriented Data Analysis 1St Edition Marron Online PDF All ChapterDocument69 pagesEbook Object Oriented Data Analysis 1St Edition Marron Online PDF All Chapterhoward.dangerfield857100% (7)
- Ebook Object Oriented Data Analysis 1St Edition James Stephen Marron Online PDF All ChapterDocument69 pagesEbook Object Oriented Data Analysis 1St Edition James Stephen Marron Online PDF All Chapteranna.rinehart397100% (7)
- Data Mining and Analysis: Fundamental Concepts and AlgorithmsDocument9 pagesData Mining and Analysis: Fundamental Concepts and Algorithmsnahum espinozaNo ratings yet
- PDF Just Enough R An Interactive Approach To Machine Learning and Analytics 1St Edition Richard J Roiger Ebook Full ChapterDocument53 pagesPDF Just Enough R An Interactive Approach To Machine Learning and Analytics 1St Edition Richard J Roiger Ebook Full Chaptercharles.barnes288100% (3)
- Datos CategóricosDocument451 pagesDatos Categóricoslaura melissa100% (1)
- Master Theses MBirkelandDocument70 pagesMaster Theses MBirkelandNqubeko DubazaneNo ratings yet
- Multiple Imputation of Missing DataDocument495 pagesMultiple Imputation of Missing DataTrinh Phạm Thị BíchNo ratings yet
- R For Actuaries & Data ScientistsDocument70 pagesR For Actuaries & Data ScientistsAlejandro AlvarezNo ratings yet
- Zlib - Pub - Swarm Intelligence Methods For Statistical RegressionDocument137 pagesZlib - Pub - Swarm Intelligence Methods For Statistical RegressionASDSADNo ratings yet
- DLMDSAS01 - Advanced Statistics.Document248 pagesDLMDSAS01 - Advanced Statistics.Kartikey ShuklaNo ratings yet
- Statistics For Business Decision Making and Analysis 3Rd Edition Full Chapter PDFDocument53 pagesStatistics For Business Decision Making and Analysis 3Rd Edition Full Chapter PDFarziabressy98100% (5)
- Multiple Imputation of Missing Data in Practice Basic Theory and Analysis Strategies Chapman Hall CRC Interdisciplinary Statistics 1St Edition Yulei He Online Ebook Texxtbook Full Chapter PDFDocument70 pagesMultiple Imputation of Missing Data in Practice Basic Theory and Analysis Strategies Chapman Hall CRC Interdisciplinary Statistics 1St Edition Yulei He Online Ebook Texxtbook Full Chapter PDFester.ahmadi991100% (11)
- AAATopological Data Analysis With Applications (Carlsson, Gunnar Vejdemo-Johansson, Mikael) (Z-Library)Document233 pagesAAATopological Data Analysis With Applications (Carlsson, Gunnar Vejdemo-Johansson, Mikael) (Z-Library)Daniel JohanssonNo ratings yet
- (Book) Bayesian Logistik - Hilbe Practical Guide To Logistic Regression (PDFDrive)Document170 pages(Book) Bayesian Logistik - Hilbe Practical Guide To Logistic Regression (PDFDrive)Liswatun NaimahNo ratings yet
- Stat Learning Notes IV2Document333 pagesStat Learning Notes IV2RaceaLineNo ratings yet
- Uuullltttiiivvvaaarrriiiaaattteee Aaannnaaalllyyysssiiisss ( ( (Uuusssiiinnnggg R R R) ) )Document75 pagesUuullltttiiivvvaaarrriiiaaattteee Aaannnaaalllyyysssiiisss ( ( (Uuusssiiinnnggg R R R) ) )Anh TuanNo ratings yet
- Nistspecialpublication960 11Document136 pagesNistspecialpublication960 11Shawn ByrdNo ratings yet
- Applied Data Mining: Statistical Methods for Business and IndustryFrom EverandApplied Data Mining: Statistical Methods for Business and IndustryNo ratings yet
- PpjfkmknoDocument249 pagesPpjfkmknohecto 21100% (1)
- Ebook Handbook of Regression Modeling in People Analytics 1St Edition Keith Mcnulty Online PDF All ChapterDocument69 pagesEbook Handbook of Regression Modeling in People Analytics 1St Edition Keith Mcnulty Online PDF All Chapterjason.komp763100% (7)
- Bussiness Statistics BookDocument5 pagesBussiness Statistics BookSikandar AliNo ratings yet
- Sic 2018 NotesDocument269 pagesSic 2018 NotesAslı YörüsünNo ratings yet
- Making Sense of Data II: A Practical Guide to Data Visualization, Advanced Data Mining Methods, and ApplicationsFrom EverandMaking Sense of Data II: A Practical Guide to Data Visualization, Advanced Data Mining Methods, and ApplicationsNo ratings yet
- Analysis and Visualization of Discrete Data Using Neural Networks Koji Koyamada Full ChapterDocument67 pagesAnalysis and Visualization of Discrete Data Using Neural Networks Koji Koyamada Full Chaptercrystal.rodriguez498100% (3)
- Master Thesis Report Magnus Tronstad Final Version 2022-06-22Document99 pagesMaster Thesis Report Magnus Tronstad Final Version 2022-06-22earth friendlyhqNo ratings yet
- BINF BSC 2023 Heidi Nagaty5Document81 pagesBINF BSC 2023 Heidi Nagaty5atanudas75No ratings yet
- Itsm Windows A User's Guide To Time Series: Modelling and ForecastingDocument126 pagesItsm Windows A User's Guide To Time Series: Modelling and ForecastingDiego Quispe OrtogorinNo ratings yet
- Practitioner's Guide To Data ScienceDocument403 pagesPractitioner's Guide To Data ScienceClassic BobbyNo ratings yet
- PDF Bayesian Statistical Methods 1St Edition Brian J Reich Ebook Full ChapterDocument53 pagesPDF Bayesian Statistical Methods 1St Edition Brian J Reich Ebook Full Chaptercherri.campbell186100% (4)
- A Tour of Data Science Learn R and Python in Parallel by Nailong ZhangDocument217 pagesA Tour of Data Science Learn R and Python in Parallel by Nailong Zhangrrrr100% (2)
- 1Document130 pages1Abdul ShamadNo ratings yet
- Practical Guide To Logistic Regression - Joseph M. Hilbe (2017)Document170 pagesPractical Guide To Logistic Regression - Joseph M. Hilbe (2017)Miguel Angel Lopez ParraNo ratings yet
- (Adaptive Computation and Machine Learning) Daphne Koller - Nir Friedman - Probabilistic Graphical Models - Principles and PDFDocument1,270 pages(Adaptive Computation and Machine Learning) Daphne Koller - Nir Friedman - Probabilistic Graphical Models - Principles and PDFSammy 123No ratings yet
- Numerical & Statistical Anylysis For Cheme's Part2Document129 pagesNumerical & Statistical Anylysis For Cheme's Part2Fug azNo ratings yet
- Fundamentals of Data Science Theory and Practice 1St Edition Jugal K Kalita Online Ebook Texxtbook Full Chapter PDFDocument54 pagesFundamentals of Data Science Theory and Practice 1St Edition Jugal K Kalita Online Ebook Texxtbook Full Chapter PDFdiane.linder152100% (13)
- The Mathematics of Games and GamblingDocument32 pagesThe Mathematics of Games and GamblingZhaung Ching100% (1)
- Optimization by Direct Search. New Perpectives On Some Classical and Modern Methods - KoldaDocument98 pagesOptimization by Direct Search. New Perpectives On Some Classical and Modern Methods - KoldaRainer Mercedes AponteNo ratings yet
- UntitledDocument10 pagesUntitledPriyanka KoreNo ratings yet
- Query Processing On Probabilistic Data: A SurveyDocument148 pagesQuery Processing On Probabilistic Data: A SurveychristhroopNo ratings yet
- Textbook Quantitative Methods of Data Analysis For The Physical Sciences and Engineering 1St Edition Douglas G Martinson Ebook All Chapter PDFDocument54 pagesTextbook Quantitative Methods of Data Analysis For The Physical Sciences and Engineering 1St Edition Douglas G Martinson Ebook All Chapter PDFtyrell.murray267100% (7)
- LinearRegressionUsing RDocument91 pagesLinearRegressionUsing RRuan CerqueiraNo ratings yet
- Visual Statistics: Seeing Data with Dynamic Interactive GraphicsFrom EverandVisual Statistics: Seeing Data with Dynamic Interactive GraphicsNo ratings yet
- Exploratory Data Analysis Using R 1St Edition Ronald K Pearson Full ChapterDocument67 pagesExploratory Data Analysis Using R 1St Edition Ronald K Pearson Full Chapterbrooks.mcgee209100% (7)
- MLNotesDocument65 pagesMLNotesTEB50Atharva PandharikarNo ratings yet
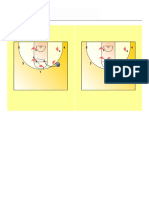
- Coach Izzat Reacting On Middle PenetrationDocument1 pageCoach Izzat Reacting On Middle PenetrationCoach-NeilKhayechNo ratings yet
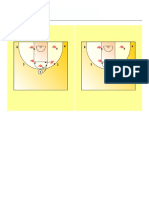
- Man To Man Defense: No Help One Pass Away - Coach IzzatDocument2 pagesMan To Man Defense: No Help One Pass Away - Coach IzzatCoach-NeilKhayechNo ratings yet
- Coach Izzat Baseline Penetration and RotationDocument1 pageCoach Izzat Baseline Penetration and RotationCoach-NeilKhayechNo ratings yet
- Offensive Teamwork Intensity As A Factor in Uencing The Result in BasketballDocument11 pagesOffensive Teamwork Intensity As A Factor in Uencing The Result in BasketballCoach-NeilKhayechNo ratings yet
- Analysisoftheoffensiveteamworkintensityinelitefemalebasketball Jhse Vol 10 N 1 47-51 PDFDocument6 pagesAnalysisoftheoffensiveteamworkintensityinelitefemalebasketball Jhse Vol 10 N 1 47-51 PDFCoach-NeilKhayechNo ratings yet
- 2013 Jtpe PDFDocument11 pages2013 Jtpe PDFCoach-NeilKhayechNo ratings yet
- Nonstandard Indicators of The Offensive Effectiven PDFDocument6 pagesNonstandard Indicators of The Offensive Effectiven PDFCoach-NeilKhayechNo ratings yet
- 2019 Santana Et Al IJSSC PDFDocument12 pages2019 Santana Et Al IJSSC PDFCoach-NeilKhayechNo ratings yet
- On Optimal Offensive Strategies in Basketball PDFDocument9 pagesOn Optimal Offensive Strategies in Basketball PDFCoach-NeilKhayechNo ratings yet
- Descriptive and Predictive Analysis of Euroleague PDFDocument25 pagesDescriptive and Predictive Analysis of Euroleague PDFCoach-NeilKhayechNo ratings yet
- YoungDawsonHenry2015 PDFDocument13 pagesYoungDawsonHenry2015 PDFCoach-NeilKhayechNo ratings yet
- Trends in Offensive Team Activity in Basketball PDFDocument8 pagesTrends in Offensive Team Activity in Basketball PDFCoach-NeilKhayechNo ratings yet
- ReliabilityofBMAT PDFDocument6 pagesReliabilityofBMAT PDFCoach-NeilKhayechNo ratings yet
- A5 LevelofBasketballDocument119 pagesA5 LevelofBasketballCoach-NeilKhayechNo ratings yet
- Power and Agility Testing Within The NBA Pre-Draft Combine: ArticleDocument7 pagesPower and Agility Testing Within The NBA Pre-Draft Combine: ArticleCoach-NeilKhayechNo ratings yet
- Different Training Programs of Mini-Basketball Players Have A Different Effect On Physical and Technical PreparationDocument11 pagesDifferent Training Programs of Mini-Basketball Players Have A Different Effect On Physical and Technical PreparationCoach-NeilKhayechNo ratings yet
- The Effect of Suspension Workout On Agility and Fo PDFDocument6 pagesThe Effect of Suspension Workout On Agility and Fo PDFCoach-NeilKhayechNo ratings yet
- Relationship Between Agility Performance and CogniDocument7 pagesRelationship Between Agility Performance and CogniCoach-NeilKhayechNo ratings yet
- Effects of High-Intensity Plyometric Training On Dynamic Balance, Agility, Vertical Jump and Sprint Performance in Young Male Basketball PlayersDocument11 pagesEffects of High-Intensity Plyometric Training On Dynamic Balance, Agility, Vertical Jump and Sprint Performance in Young Male Basketball PlayersCoach-NeilKhayechNo ratings yet
- Ijapey 3 AshokJSJDocument6 pagesIjapey 3 AshokJSJCoach-NeilKhayechNo ratings yet
- Measles Vaccine: Protective Against Covid-19?: Technical ReportDocument2 pagesMeasles Vaccine: Protective Against Covid-19?: Technical ReportCoach-NeilKhayechNo ratings yet
- Chapter 10 - Rock FoundationsDocument16 pagesChapter 10 - Rock FoundationsLupyana wa LupyanaNo ratings yet
- Earthquake Engineering Module 1Document32 pagesEarthquake Engineering Module 1Ed AnthonyNo ratings yet
- Adjusting For Bad DebtsDocument16 pagesAdjusting For Bad DebtssamahaseNo ratings yet
- Database Design: INFO2040 Distributed Computing Technologies TopicsDocument11 pagesDatabase Design: INFO2040 Distributed Computing Technologies TopicsTriztan Sutrisno RompasNo ratings yet
- Abu Dhabi With Dubai Bonanza 445 1 1 2390 FTPL-BI-1439Document15 pagesAbu Dhabi With Dubai Bonanza 445 1 1 2390 FTPL-BI-1439Navnitlal ShahNo ratings yet
- PT Dago Energi Nusantara TIME SHEET BULANAN KARYAWAN (26 Mar 2022 SD 25 Apr 2022)Document7 pagesPT Dago Energi Nusantara TIME SHEET BULANAN KARYAWAN (26 Mar 2022 SD 25 Apr 2022)muchamad luthfi aliNo ratings yet
- International Emergency Nursing: Yong Eun Kwon, Miyoung Kim, Sujin ChoiDocument7 pagesInternational Emergency Nursing: Yong Eun Kwon, Miyoung Kim, Sujin ChoiAmrinder RandhawaNo ratings yet
- Essentials of Service Development For Ibm Datapower Gateway V7.5Document9 pagesEssentials of Service Development For Ibm Datapower Gateway V7.5Saroj Raj DasNo ratings yet
- Benefits Management PlanDocument1 pageBenefits Management PlanTariq AlzahraniNo ratings yet
- Securitizing SuburbiaDocument105 pagesSecuritizing SuburbiaForeclosure FraudNo ratings yet
- Exam 2018 s1 Op2 NewDocument12 pagesExam 2018 s1 Op2 NewmakgethwawhitneyNo ratings yet
- Wartung Assyst Plus 204 enDocument32 pagesWartung Assyst Plus 204 enKent Wai100% (1)
- C2a. Logic SimplificationDocument53 pagesC2a. Logic SimplificationNicolaas LimNo ratings yet
- MTE 220 Course - NotesDocument163 pagesMTE 220 Course - NotesqNo ratings yet
- FLM 420 RLV1Document4 pagesFLM 420 RLV1Muhammad Ali ShahNo ratings yet
- Fall Background PowerPoint Template by SlideWinDocument29 pagesFall Background PowerPoint Template by SlideWinHoàng Thùy DươngNo ratings yet
- Robot Welding in ShipbuildingDocument5 pagesRobot Welding in Shipbuildingvictor navarro chiletNo ratings yet
- TRTDocument4 pagesTRTHendrias SoesantoNo ratings yet
- Me Market-StructureDocument3 pagesMe Market-Structurebenedick marcialNo ratings yet
- Strategic Management Journal - February 1996 - BARKEMA - FOREIGN ENTRY CULTURAL BARRIERS AND LEARNINGDocument16 pagesStrategic Management Journal - February 1996 - BARKEMA - FOREIGN ENTRY CULTURAL BARRIERS AND LEARNINGluana.macedo.ceNo ratings yet
- Development of Sensory TestingDocument35 pagesDevelopment of Sensory TestingEmmae ThaleenNo ratings yet
- MKT 460.6 Final AssignmentDocument93 pagesMKT 460.6 Final AssignmentSirajis SalekinNo ratings yet
- CUENCAS Allen - Classification - 2015Document52 pagesCUENCAS Allen - Classification - 2015Camila AldereteNo ratings yet
- Working Capital Management: Unit: 5Document20 pagesWorking Capital Management: Unit: 5Shaifali ChauhanNo ratings yet
- Eutectic 19910: A Hard Nickel-Chromium Coating For Resistance To AbrasionDocument2 pagesEutectic 19910: A Hard Nickel-Chromium Coating For Resistance To AbrasionFactel SANo ratings yet
- Brief Note On The Trusteeship Approach As Proposed by Mahatma Gandhi - Business Studies - Knowledge HubDocument2 pagesBrief Note On The Trusteeship Approach As Proposed by Mahatma Gandhi - Business Studies - Knowledge HubSagar GavitNo ratings yet
- The Constitution of BD With Comments N Case Laws by Latifur RahmanDocument275 pagesThe Constitution of BD With Comments N Case Laws by Latifur RahmanMd Ahsan-Ul- Kabir100% (1)