
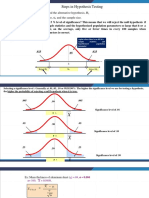
L24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, Association
L24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, Association
You might also like
- L2 Hypothesis TestingDocument35 pagesL2 Hypothesis TestingDragneelNo ratings yet
- Week 6 Homework - Chapter 12Document58 pagesWeek 6 Homework - Chapter 12JasonNo ratings yet
- Chapter 3-Numerical MeasuresDocument38 pagesChapter 3-Numerical MeasuresNadia TanzeemNo ratings yet
- Hypothesis TestingDocument12 pagesHypothesis TestingJp Combis100% (1)
- BVD Chapter Outlines648 PDFDocument46 pagesBVD Chapter Outlines648 PDFEvan LeeNo ratings yet
- Sample Size Recalculation in Internal Pilot Study Designs - A Review PDFDocument19 pagesSample Size Recalculation in Internal Pilot Study Designs - A Review PDFnelson huaytaNo ratings yet
- Turning Behaviour of WoodliceDocument5 pagesTurning Behaviour of WoodliceOlly CrossNo ratings yet
- Hypothesis Testing Slide 14Document45 pagesHypothesis Testing Slide 14Mario BrossNo ratings yet
- UOP E Assignments - QNT 561 Final Exam - Questions and AnswersDocument12 pagesUOP E Assignments - QNT 561 Final Exam - Questions and AnswersuopeassignmentsNo ratings yet
- Chi-Square Goodness of Fit TestDocument24 pagesChi-Square Goodness of Fit TestBen TorejaNo ratings yet
- Chapter 9 One Sample Hypothesis TestingDocument25 pagesChapter 9 One Sample Hypothesis TestingLakhan Subhash TrivediNo ratings yet
- QMB FL. Chap 04Document27 pagesQMB FL. Chap 04Manula JayawardhanaNo ratings yet
- Chapter 5Document35 pagesChapter 5abrajanojennilynNo ratings yet
- Hypothesis TestingDocument41 pagesHypothesis TestingVashishtha DadhichNo ratings yet
- StatDocument70 pagesStatcj_anero67% (3)
- Hypothesis TestingDocument72 pagesHypothesis TestingChaitanya Krishna DeepakNo ratings yet
- Hypothesis TestingDocument59 pagesHypothesis Testingshomitamaraewu0% (1)
- AFM 113 W22 Lecture Slides Chap 10Document66 pagesAFM 113 W22 Lecture Slides Chap 10nicklewandowski87No ratings yet
- Making Confident DecisionsDocument37 pagesMaking Confident DecisionsSium Adnan Khan 1511153030No ratings yet
- Testing of Hypothesis-1SDocument30 pagesTesting of Hypothesis-1SSaurabh Kumar GautamNo ratings yet
- Univariate StatisticsDocument54 pagesUnivariate Statisticsharsheen kaurNo ratings yet
- Glimpses Into Application of Chi in MarketingDocument6 pagesGlimpses Into Application of Chi in MarketingNutukurthi Venkat RamjiNo ratings yet
- CH 18Document17 pagesCH 18Piyush rajNo ratings yet
- Linear RegressionDocument23 pagesLinear RegressionRabiqa RaniNo ratings yet
- Statistics Interview QuestionsDocument20 pagesStatistics Interview QuestionssairameshtNo ratings yet
- L19 - Chi Square Test 1Document17 pagesL19 - Chi Square Test 1quang hoaNo ratings yet
- Week 6 - Result and Analysis 2 (UP)Document7 pagesWeek 6 - Result and Analysis 2 (UP)eddy siregarNo ratings yet
- Hypotheses TestingDocument56 pagesHypotheses TestingJordan RonquilloNo ratings yet
- QNT 351 Week 5 Final ExamDocument12 pagesQNT 351 Week 5 Final Exam491acc50% (2)
- Z-TEST and T-TestDocument45 pagesZ-TEST and T-Testabegail divina50% (6)
- Non-Parametric TestsDocument47 pagesNon-Parametric Testsaddis zewdNo ratings yet
- Reserch Analysis Between Wall S Omore Ice Cream by Mian ShahnnawazDocument31 pagesReserch Analysis Between Wall S Omore Ice Cream by Mian ShahnnawazAwais KhatriNo ratings yet
- SPSS2 Guide Basic Non-ParametricsDocument24 pagesSPSS2 Guide Basic Non-Parametricsrich_s_mooreNo ratings yet
- Chi SquareDocument25 pagesChi SquarerolandNo ratings yet
- Chi Square TestDocument5 pagesChi Square TestDwarika prasad choudhuryNo ratings yet
- Time SeriesDocument51 pagesTime Seriess.vijayaraniNo ratings yet
- 3 - Data Analysis - Tests of DifferencesDocument50 pages3 - Data Analysis - Tests of Differencesmnrk 1997No ratings yet
- MitDocument119 pagesMitalexNo ratings yet
- Ken Black QA ch09Document60 pagesKen Black QA ch09Rushabh VoraNo ratings yet
- Data Analysis: - Describing Data and DatasetsDocument15 pagesData Analysis: - Describing Data and DatasetsTarig GibreelNo ratings yet
- Multiple Regression PDFDocument19 pagesMultiple Regression PDFSachen KulandaivelNo ratings yet
- ADDB Week 6 For StudentsDocument59 pagesADDB Week 6 For StudentsAlya Khaira NazhifaNo ratings yet
- Statistics Interview Questions & Answers For Data ScientistsDocument43 pagesStatistics Interview Questions & Answers For Data ScientistsmlissaliNo ratings yet
- Business Statistics Day5Document72 pagesBusiness Statistics Day5NikhilNo ratings yet
- One Dimensional StatisticsDocument21 pagesOne Dimensional Statisticsdhbash ALKALINo ratings yet
- Chapter 4Document13 pagesChapter 4AndreaNo ratings yet
- Research Methodology For Management: Session 13: Bivariate Statistical Analysis (Introduction)Document16 pagesResearch Methodology For Management: Session 13: Bivariate Statistical Analysis (Introduction)Aman AgarwalNo ratings yet
- From, Chaithra .N Chaitra K.BDocument26 pagesFrom, Chaithra .N Chaitra K.BAjay Galagali0% (1)
- Interpreting Chi SquareDocument25 pagesInterpreting Chi SquareBidyut RayNo ratings yet
- Chi Square TestDocument24 pagesChi Square TestMohd ShadabNo ratings yet
- Multiple Regression MSDocument35 pagesMultiple Regression MSWaqar AhmadNo ratings yet
- Chi-Kong NG, ENGG2780B, Dept. of SEEM, CUHK 1:1Document16 pagesChi-Kong NG, ENGG2780B, Dept. of SEEM, CUHK 1:1BaoYu MoZhiNo ratings yet
- Quantitative Methods Case Study 2: 1) What Is The Most Economical Speed?Document2 pagesQuantitative Methods Case Study 2: 1) What Is The Most Economical Speed?Dilip Kumar SauNo ratings yet
- Old Book New Book: Unit 6 REVIEW (Ch. 23 - 25)Document3 pagesOld Book New Book: Unit 6 REVIEW (Ch. 23 - 25)HansNo ratings yet
- Specialty Toys Problem PDFDocument37 pagesSpecialty Toys Problem PDFSantanu Das80% (5)
- Research Methodology 22Document28 pagesResearch Methodology 22Ahmed MalikNo ratings yet
- Applied Environmental StatisticsDocument35 pagesApplied Environmental StatisticsMawuliNo ratings yet
- HT Part 2Document76 pagesHT Part 2marioma1752000No ratings yet
- STATS - WK - April 23 25Document9 pagesSTATS - WK - April 23 25Mark Denniel SumagueNo ratings yet
- Success Probability Estimation with Applications to Clinical TrialsFrom EverandSuccess Probability Estimation with Applications to Clinical TrialsNo ratings yet
- Pearson Higher Nationals In: BusinessDocument18 pagesPearson Higher Nationals In: Businessquang hoaNo ratings yet
- L24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, AssociationDocument24 pagesL24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, Associationquang hoaNo ratings yet
- L18 - Hypothesis Testing Using Minitab PDFDocument5 pagesL18 - Hypothesis Testing Using Minitab PDFquang hoaNo ratings yet
- Btec HN Business l5 Eab - Unit 11 PDFDocument10 pagesBtec HN Business l5 Eab - Unit 11 PDFquang hoaNo ratings yet
- L23 - Hypothesis Testing ExamplesDocument24 pagesL23 - Hypothesis Testing Examplesquang hoaNo ratings yet
- L20 - Regression Analysis 1 PDFDocument17 pagesL20 - Regression Analysis 1 PDFquang hoaNo ratings yet
- L19 - Chi Square Test 1Document17 pagesL19 - Chi Square Test 1quang hoaNo ratings yet
- L20 - Regression Analysis 1Document17 pagesL20 - Regression Analysis 1quang hoaNo ratings yet
- Btec HN Business l5 Eab - Unit 11 PDFDocument10 pagesBtec HN Business l5 Eab - Unit 11 PDFquang hoaNo ratings yet
- L18 - Hypothesis Testing Using MinitabDocument5 pagesL18 - Hypothesis Testing Using Minitabquang hoaNo ratings yet
- (DM) Categorical Data Analysis (Agresti, 2002) Companion (S-PLUS and R)Document265 pages(DM) Categorical Data Analysis (Agresti, 2002) Companion (S-PLUS and R)Luciene TorquatoNo ratings yet
- Basic Statistics in Bio MedicalDocument271 pagesBasic Statistics in Bio Medicalifai.gs7487100% (2)
- Yadunandan Sharma 500826933 MTH480 Due Date: April 15, 2021Document16 pagesYadunandan Sharma 500826933 MTH480 Due Date: April 15, 2021danNo ratings yet
- Personal Investment Literacy Among College StudentDocument11 pagesPersonal Investment Literacy Among College StudentMinh Châu VũNo ratings yet
- Chi-Square Test For AssociationDocument8 pagesChi-Square Test For AssociationPingotMagangaNo ratings yet
- Data Analysis Text BookDocument292 pagesData Analysis Text BookclaireNo ratings yet
- A Study On Consumer Satisfaction Towards Indian OilDocument12 pagesA Study On Consumer Satisfaction Towards Indian Oilarthiloosu421No ratings yet
- Hypothesis TestingDocument196 pagesHypothesis TestingSahil KumarNo ratings yet
- Chapter - I: Product Life Cycle of Britannia ProductsDocument40 pagesChapter - I: Product Life Cycle of Britannia ProductsLOKANATH CHOUDHURYNo ratings yet
- X2 Test (Chi Squared Test)Document5 pagesX2 Test (Chi Squared Test)Paewa PanennungiNo ratings yet
- 30117-Article Text-56491-2-10-20191119Document10 pages30117-Article Text-56491-2-10-20191119KENNETH EPPENo ratings yet
- Evidence Based Risk Analysis of Fire and Explosion Accident Scenarios in FPSOs PDFDocument16 pagesEvidence Based Risk Analysis of Fire and Explosion Accident Scenarios in FPSOs PDFAnu PrasobhNo ratings yet
- A Guide To Data ExplorationDocument20 pagesA Guide To Data Explorationmike110*No ratings yet
- Chi-Square Test: Dr. T. T. KachwalaDocument14 pagesChi-Square Test: Dr. T. T. KachwalaHarshdeep BhatiaNo ratings yet
- MB185288 PDFDocument5 pagesMB185288 PDFSreekanthNo ratings yet
- Mathematical Studies Internal Assessment: Education and Teenage PregnancyDocument23 pagesMathematical Studies Internal Assessment: Education and Teenage Pregnancyrajai farwagiNo ratings yet
- Drosophilia Lab ReportDocument5 pagesDrosophilia Lab ReportMaddie BleaseNo ratings yet
- Comparative Anatomo Radiological Study of Intrahe - 2021 - Annals of Anatomy - ADocument11 pagesComparative Anatomo Radiological Study of Intrahe - 2021 - Annals of Anatomy - AГне ДзжNo ratings yet
- Abc3036 PDFDocument147 pagesAbc3036 PDFBhavana PrettyNo ratings yet
- Chi SquareDocument2 pagesChi SquarePrasanth Kurien Mathew100% (3)
- Chapter 13 (Independent Study Unit)Document9 pagesChapter 13 (Independent Study Unit)Lauren StamNo ratings yet
- 6) BIOSTATISTICsDocument99 pages6) BIOSTATISTICsMadhulikaNo ratings yet
- A Prospective Observational Multi Centre Study On The Use of Negative Pressure Wound Therapy in Diabetic Foot UlcerDocument7 pagesA Prospective Observational Multi Centre Study On The Use of Negative Pressure Wound Therapy in Diabetic Foot UlcerHerald Scholarly Open AccessNo ratings yet
- "Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonDocument36 pages"Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonAnkita BhamreNo ratings yet
- Stata Class NotesDocument43 pagesStata Class NotesMido MedNo ratings yet
- Coefficient of SkewnessDocument89 pagesCoefficient of SkewnessAhsan KamranNo ratings yet
































































































Download as pdf or txt
You might also like
- L2 Hypothesis TestingDocument35 pagesL2 Hypothesis TestingDragneelNo ratings yet
- Week 6 Homework - Chapter 12Document58 pagesWeek 6 Homework - Chapter 12JasonNo ratings yet
- Chapter 3-Numerical MeasuresDocument38 pagesChapter 3-Numerical MeasuresNadia TanzeemNo ratings yet
- Hypothesis TestingDocument12 pagesHypothesis TestingJp Combis100% (1)
- BVD Chapter Outlines648 PDFDocument46 pagesBVD Chapter Outlines648 PDFEvan LeeNo ratings yet
- Sample Size Recalculation in Internal Pilot Study Designs - A Review PDFDocument19 pagesSample Size Recalculation in Internal Pilot Study Designs - A Review PDFnelson huaytaNo ratings yet
- Turning Behaviour of WoodliceDocument5 pagesTurning Behaviour of WoodliceOlly CrossNo ratings yet
- Hypothesis Testing Slide 14Document45 pagesHypothesis Testing Slide 14Mario BrossNo ratings yet
- UOP E Assignments - QNT 561 Final Exam - Questions and AnswersDocument12 pagesUOP E Assignments - QNT 561 Final Exam - Questions and AnswersuopeassignmentsNo ratings yet
- Chi-Square Goodness of Fit TestDocument24 pagesChi-Square Goodness of Fit TestBen TorejaNo ratings yet
- Chapter 9 One Sample Hypothesis TestingDocument25 pagesChapter 9 One Sample Hypothesis TestingLakhan Subhash TrivediNo ratings yet
- QMB FL. Chap 04Document27 pagesQMB FL. Chap 04Manula JayawardhanaNo ratings yet
- Chapter 5Document35 pagesChapter 5abrajanojennilynNo ratings yet
- Hypothesis TestingDocument41 pagesHypothesis TestingVashishtha DadhichNo ratings yet
- StatDocument70 pagesStatcj_anero67% (3)
- Hypothesis TestingDocument72 pagesHypothesis TestingChaitanya Krishna DeepakNo ratings yet
- Hypothesis TestingDocument59 pagesHypothesis Testingshomitamaraewu0% (1)
- AFM 113 W22 Lecture Slides Chap 10Document66 pagesAFM 113 W22 Lecture Slides Chap 10nicklewandowski87No ratings yet
- Making Confident DecisionsDocument37 pagesMaking Confident DecisionsSium Adnan Khan 1511153030No ratings yet
- Testing of Hypothesis-1SDocument30 pagesTesting of Hypothesis-1SSaurabh Kumar GautamNo ratings yet
- Univariate StatisticsDocument54 pagesUnivariate Statisticsharsheen kaurNo ratings yet
- Glimpses Into Application of Chi in MarketingDocument6 pagesGlimpses Into Application of Chi in MarketingNutukurthi Venkat RamjiNo ratings yet
- CH 18Document17 pagesCH 18Piyush rajNo ratings yet
- Linear RegressionDocument23 pagesLinear RegressionRabiqa RaniNo ratings yet
- Statistics Interview QuestionsDocument20 pagesStatistics Interview QuestionssairameshtNo ratings yet
- L19 - Chi Square Test 1Document17 pagesL19 - Chi Square Test 1quang hoaNo ratings yet
- Week 6 - Result and Analysis 2 (UP)Document7 pagesWeek 6 - Result and Analysis 2 (UP)eddy siregarNo ratings yet
- Hypotheses TestingDocument56 pagesHypotheses TestingJordan RonquilloNo ratings yet
- QNT 351 Week 5 Final ExamDocument12 pagesQNT 351 Week 5 Final Exam491acc50% (2)
- Z-TEST and T-TestDocument45 pagesZ-TEST and T-Testabegail divina50% (6)
- Non-Parametric TestsDocument47 pagesNon-Parametric Testsaddis zewdNo ratings yet
- Reserch Analysis Between Wall S Omore Ice Cream by Mian ShahnnawazDocument31 pagesReserch Analysis Between Wall S Omore Ice Cream by Mian ShahnnawazAwais KhatriNo ratings yet
- SPSS2 Guide Basic Non-ParametricsDocument24 pagesSPSS2 Guide Basic Non-Parametricsrich_s_mooreNo ratings yet
- Chi SquareDocument25 pagesChi SquarerolandNo ratings yet
- Chi Square TestDocument5 pagesChi Square TestDwarika prasad choudhuryNo ratings yet
- Time SeriesDocument51 pagesTime Seriess.vijayaraniNo ratings yet
- 3 - Data Analysis - Tests of DifferencesDocument50 pages3 - Data Analysis - Tests of Differencesmnrk 1997No ratings yet
- MitDocument119 pagesMitalexNo ratings yet
- Ken Black QA ch09Document60 pagesKen Black QA ch09Rushabh VoraNo ratings yet
- Data Analysis: - Describing Data and DatasetsDocument15 pagesData Analysis: - Describing Data and DatasetsTarig GibreelNo ratings yet
- Multiple Regression PDFDocument19 pagesMultiple Regression PDFSachen KulandaivelNo ratings yet
- ADDB Week 6 For StudentsDocument59 pagesADDB Week 6 For StudentsAlya Khaira NazhifaNo ratings yet
- Statistics Interview Questions & Answers For Data ScientistsDocument43 pagesStatistics Interview Questions & Answers For Data ScientistsmlissaliNo ratings yet
- Business Statistics Day5Document72 pagesBusiness Statistics Day5NikhilNo ratings yet
- One Dimensional StatisticsDocument21 pagesOne Dimensional Statisticsdhbash ALKALINo ratings yet
- Chapter 4Document13 pagesChapter 4AndreaNo ratings yet
- Research Methodology For Management: Session 13: Bivariate Statistical Analysis (Introduction)Document16 pagesResearch Methodology For Management: Session 13: Bivariate Statistical Analysis (Introduction)Aman AgarwalNo ratings yet
- From, Chaithra .N Chaitra K.BDocument26 pagesFrom, Chaithra .N Chaitra K.BAjay Galagali0% (1)
- Interpreting Chi SquareDocument25 pagesInterpreting Chi SquareBidyut RayNo ratings yet
- Chi Square TestDocument24 pagesChi Square TestMohd ShadabNo ratings yet
- Multiple Regression MSDocument35 pagesMultiple Regression MSWaqar AhmadNo ratings yet
- Chi-Kong NG, ENGG2780B, Dept. of SEEM, CUHK 1:1Document16 pagesChi-Kong NG, ENGG2780B, Dept. of SEEM, CUHK 1:1BaoYu MoZhiNo ratings yet
- Quantitative Methods Case Study 2: 1) What Is The Most Economical Speed?Document2 pagesQuantitative Methods Case Study 2: 1) What Is The Most Economical Speed?Dilip Kumar SauNo ratings yet
- Old Book New Book: Unit 6 REVIEW (Ch. 23 - 25)Document3 pagesOld Book New Book: Unit 6 REVIEW (Ch. 23 - 25)HansNo ratings yet
- Specialty Toys Problem PDFDocument37 pagesSpecialty Toys Problem PDFSantanu Das80% (5)
- Research Methodology 22Document28 pagesResearch Methodology 22Ahmed MalikNo ratings yet
- Applied Environmental StatisticsDocument35 pagesApplied Environmental StatisticsMawuliNo ratings yet
- HT Part 2Document76 pagesHT Part 2marioma1752000No ratings yet
- STATS - WK - April 23 25Document9 pagesSTATS - WK - April 23 25Mark Denniel SumagueNo ratings yet
- Success Probability Estimation with Applications to Clinical TrialsFrom EverandSuccess Probability Estimation with Applications to Clinical TrialsNo ratings yet
- Pearson Higher Nationals In: BusinessDocument18 pagesPearson Higher Nationals In: Businessquang hoaNo ratings yet
- L24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, AssociationDocument24 pagesL24 - Example of Chi-Square Goodness-of-Fit Test, Chi-Square Cross Table, Associationquang hoaNo ratings yet
- L18 - Hypothesis Testing Using Minitab PDFDocument5 pagesL18 - Hypothesis Testing Using Minitab PDFquang hoaNo ratings yet
- Btec HN Business l5 Eab - Unit 11 PDFDocument10 pagesBtec HN Business l5 Eab - Unit 11 PDFquang hoaNo ratings yet
- L23 - Hypothesis Testing ExamplesDocument24 pagesL23 - Hypothesis Testing Examplesquang hoaNo ratings yet
- L20 - Regression Analysis 1 PDFDocument17 pagesL20 - Regression Analysis 1 PDFquang hoaNo ratings yet
- L19 - Chi Square Test 1Document17 pagesL19 - Chi Square Test 1quang hoaNo ratings yet
- L20 - Regression Analysis 1Document17 pagesL20 - Regression Analysis 1quang hoaNo ratings yet
- Btec HN Business l5 Eab - Unit 11 PDFDocument10 pagesBtec HN Business l5 Eab - Unit 11 PDFquang hoaNo ratings yet
- L18 - Hypothesis Testing Using MinitabDocument5 pagesL18 - Hypothesis Testing Using Minitabquang hoaNo ratings yet
- (DM) Categorical Data Analysis (Agresti, 2002) Companion (S-PLUS and R)Document265 pages(DM) Categorical Data Analysis (Agresti, 2002) Companion (S-PLUS and R)Luciene TorquatoNo ratings yet
- Basic Statistics in Bio MedicalDocument271 pagesBasic Statistics in Bio Medicalifai.gs7487100% (2)
- Yadunandan Sharma 500826933 MTH480 Due Date: April 15, 2021Document16 pagesYadunandan Sharma 500826933 MTH480 Due Date: April 15, 2021danNo ratings yet
- Personal Investment Literacy Among College StudentDocument11 pagesPersonal Investment Literacy Among College StudentMinh Châu VũNo ratings yet
- Chi-Square Test For AssociationDocument8 pagesChi-Square Test For AssociationPingotMagangaNo ratings yet
- Data Analysis Text BookDocument292 pagesData Analysis Text BookclaireNo ratings yet
- A Study On Consumer Satisfaction Towards Indian OilDocument12 pagesA Study On Consumer Satisfaction Towards Indian Oilarthiloosu421No ratings yet
- Hypothesis TestingDocument196 pagesHypothesis TestingSahil KumarNo ratings yet
- Chapter - I: Product Life Cycle of Britannia ProductsDocument40 pagesChapter - I: Product Life Cycle of Britannia ProductsLOKANATH CHOUDHURYNo ratings yet
- X2 Test (Chi Squared Test)Document5 pagesX2 Test (Chi Squared Test)Paewa PanennungiNo ratings yet
- 30117-Article Text-56491-2-10-20191119Document10 pages30117-Article Text-56491-2-10-20191119KENNETH EPPENo ratings yet
- Evidence Based Risk Analysis of Fire and Explosion Accident Scenarios in FPSOs PDFDocument16 pagesEvidence Based Risk Analysis of Fire and Explosion Accident Scenarios in FPSOs PDFAnu PrasobhNo ratings yet
- A Guide To Data ExplorationDocument20 pagesA Guide To Data Explorationmike110*No ratings yet
- Chi-Square Test: Dr. T. T. KachwalaDocument14 pagesChi-Square Test: Dr. T. T. KachwalaHarshdeep BhatiaNo ratings yet
- MB185288 PDFDocument5 pagesMB185288 PDFSreekanthNo ratings yet
- Mathematical Studies Internal Assessment: Education and Teenage PregnancyDocument23 pagesMathematical Studies Internal Assessment: Education and Teenage Pregnancyrajai farwagiNo ratings yet
- Drosophilia Lab ReportDocument5 pagesDrosophilia Lab ReportMaddie BleaseNo ratings yet
- Comparative Anatomo Radiological Study of Intrahe - 2021 - Annals of Anatomy - ADocument11 pagesComparative Anatomo Radiological Study of Intrahe - 2021 - Annals of Anatomy - AГне ДзжNo ratings yet
- Abc3036 PDFDocument147 pagesAbc3036 PDFBhavana PrettyNo ratings yet
- Chi SquareDocument2 pagesChi SquarePrasanth Kurien Mathew100% (3)
- Chapter 13 (Independent Study Unit)Document9 pagesChapter 13 (Independent Study Unit)Lauren StamNo ratings yet
- 6) BIOSTATISTICsDocument99 pages6) BIOSTATISTICsMadhulikaNo ratings yet
- A Prospective Observational Multi Centre Study On The Use of Negative Pressure Wound Therapy in Diabetic Foot UlcerDocument7 pagesA Prospective Observational Multi Centre Study On The Use of Negative Pressure Wound Therapy in Diabetic Foot UlcerHerald Scholarly Open AccessNo ratings yet
- "Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonDocument36 pages"Customers Satistfaction Towards Promotional Strategies of D-Mart in Jalgaon City" A Project Work Submitted To Moolji Jaitha College, JalgaonAnkita BhamreNo ratings yet
- Stata Class NotesDocument43 pagesStata Class NotesMido MedNo ratings yet
- Coefficient of SkewnessDocument89 pagesCoefficient of SkewnessAhsan KamranNo ratings yet