
Factor Analysis For Soil Test Data: A Methodological Approach in Environment Friendly Soil Fertility Management
Factor Analysis For Soil Test Data: A Methodological Approach in Environment Friendly Soil Fertility Management
You might also like
- Fluid Friction in Pipes Laboratory ReportDocument6 pagesFluid Friction in Pipes Laboratory ReportABamishe50% (2)
- The Career Futures InventoryDocument23 pagesThe Career Futures InventorySangLintangPanjerino0% (1)
- Quantitative Analysis or Rare Earths by X-Ray Fluorescence SpectrometryDocument8 pagesQuantitative Analysis or Rare Earths by X-Ray Fluorescence Spectrometrykulihat_hijauNo ratings yet
- Monika ProjectDocument34 pagesMonika Projectgurleen kaurNo ratings yet
- The Influence of Fundamental and Macroeconomic Analysis On Stock PriceDocument13 pagesThe Influence of Fundamental and Macroeconomic Analysis On Stock PriceWiria SalvatoreNo ratings yet
- Interpret DataDocument3 pagesInterpret Datacikedis.chocoNo ratings yet
- Example of Analyze Taguchi Design (Dynamic) - Minitab PDFDocument8 pagesExample of Analyze Taguchi Design (Dynamic) - Minitab PDFSachinihcasSacNo ratings yet
- Water Quality AnalysisDocument4 pagesWater Quality AnalysisMaahir AuckbarallyNo ratings yet
- Paper in TTP Scintific - Net-AuthorsDocument7 pagesPaper in TTP Scintific - Net-AuthorsMohan Kumar Pradhan Associate ProfessorNo ratings yet
- Institutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelDocument14 pagesInstitutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelNajib BenslimaneNo ratings yet
- Jaypee Institute of Information Technology NoidaDocument9 pagesJaypee Institute of Information Technology NoidaApoorv KumarNo ratings yet
- Submitted To: Sir Saeed Meo: MBEW-F17-17Document13 pagesSubmitted To: Sir Saeed Meo: MBEW-F17-17Arsal AliNo ratings yet
- Table AP1: Results of Wald Test: 5.0 AppendixDocument2 pagesTable AP1: Results of Wald Test: 5.0 Appendixbharatii khannaNo ratings yet
- Jaypee Institute of Information Technology NoidaDocument10 pagesJaypee Institute of Information Technology NoidaApoorv KumarNo ratings yet
- 1986 - Prediction of Properties of Petroleum Mixtures - Improvement in Reliability and Validity of Tuned ParametersDocument8 pages1986 - Prediction of Properties of Petroleum Mixtures - Improvement in Reliability and Validity of Tuned ParametersRosendo Monroy LoperenaNo ratings yet
- Ja200299u Si 002Document48 pagesJa200299u Si 002Mutiva YyNo ratings yet
- Phar0011 Radioligand Binding Analysis 2022Document5 pagesPhar0011 Radioligand Binding Analysis 20224wqzcq7p9xNo ratings yet
- 6.2. MethodologyDocument12 pages6.2. MethodologyAtiaTahiraNo ratings yet
- Propuesta de Solución de LillyDocument5 pagesPropuesta de Solución de LillyJames Rodriguez CarvajalNo ratings yet
- SLH Chapter FourDocument8 pagesSLH Chapter Foursadiqmedical160No ratings yet
- Empirical Findings: Unit Root TestDocument4 pagesEmpirical Findings: Unit Root TestkhalidhamdanNo ratings yet
- Financial Test ReportDocument11 pagesFinancial Test ReportAsad GhaffarNo ratings yet
- Vigneau Devaux Qannari Robert JChemo 1997Document12 pagesVigneau Devaux Qannari Robert JChemo 1997Stefany ValverdeNo ratings yet
- Chapter Fou1Document11 pagesChapter Fou1sue patrickNo ratings yet
- Mef 402 - InterpretationDocument27 pagesMef 402 - InterpretationDubem EnarunaNo ratings yet
- Chap VDocument16 pagesChap VBasavaraj MtNo ratings yet
- FN GRP 4.2 Assignment No 5Document7 pagesFN GRP 4.2 Assignment No 5Darshan sakleNo ratings yet
- 4.2 Empirical Analysis: 4.2.1 Descriptive StatisticsDocument12 pages4.2 Empirical Analysis: 4.2.1 Descriptive StatisticsAtiya KhanNo ratings yet
- Base Metal MMCRM Oreas 38: Ore Research & Exploration Pty LTDDocument22 pagesBase Metal MMCRM Oreas 38: Ore Research & Exploration Pty LTDHeber Diaz ChavezNo ratings yet
- EDUARDO JR. BAGAPORO - Laboratory Activity 8 Report SheetDocument4 pagesEDUARDO JR. BAGAPORO - Laboratory Activity 8 Report SheetJr BagaporoNo ratings yet
- IET 421/621 (Spring 2016) Exam-1 Total Points: 20Document5 pagesIET 421/621 (Spring 2016) Exam-1 Total Points: 20YUVISHAIS PAOLA PAYARES BALDIRISNo ratings yet
- IET 421/621 (Spring 2016) Exam-1 Total Points: 20Document5 pagesIET 421/621 (Spring 2016) Exam-1 Total Points: 20YUVISHAIS PAOLA PAYARES BALDIRISNo ratings yet
- Chapter Four Model Analysis and Estimation 4.1Document8 pagesChapter Four Model Analysis and Estimation 4.1Oladipupo Mayowa PaulNo ratings yet
- Regression Analysis and Its Interpretation With SpssDocument4 pagesRegression Analysis and Its Interpretation With SpssChakraKhadkaNo ratings yet
- Decision Science - June - 2023Document8 pagesDecision Science - June - 2023kumar.rajan0108No ratings yet
- One-Way ANOVA Calculator: Success!Document6 pagesOne-Way ANOVA Calculator: Success!Marcos DmitriNo ratings yet
- Module 4 Index NumbersDocument16 pagesModule 4 Index Numbersarunteja.chithram786No ratings yet
- Ardl Analysis Chapter Four FinalDocument9 pagesArdl Analysis Chapter Four Finalsadiqmedical160No ratings yet
- MTBF - Report - Rambutan (-I) - V1Document15 pagesMTBF - Report - Rambutan (-I) - V1Madhuseptember2022No ratings yet
- Stata Equipo BLDocument1 pageStata Equipo BLDaniel OlveraNo ratings yet
- FDP On Applied Econometrics PresentationDocument17 pagesFDP On Applied Econometrics PresentationDrDeepti JiNo ratings yet
- OUTPUTDocument3 pagesOUTPUTsalekeen sakibNo ratings yet
- Gold Reference MaterialDocument6 pagesGold Reference MaterialSatrya RachmanNo ratings yet
- Descriptive Statistics: Data Analysis AssignmentDocument9 pagesDescriptive Statistics: Data Analysis AssignmentSuriya SamNo ratings yet
- Analysis of Primary DataDocument20 pagesAnalysis of Primary Dataashok jaipalNo ratings yet
- Chapter Four The MethodologyDocument20 pagesChapter Four The MethodologyKola BamgboseNo ratings yet
- Chem Plant Assignment 1Document14 pagesChem Plant Assignment 1lungani butheleziNo ratings yet
- Adenike Project Chapter 4-5Document21 pagesAdenike Project Chapter 4-5Emeka MichealNo ratings yet
- FinalDocument17 pagesFinalhina khanNo ratings yet
- Profitabilitas, Liquiitas, Ukuran Perusahaan Terhaap Struktur ModalDocument10 pagesProfitabilitas, Liquiitas, Ukuran Perusahaan Terhaap Struktur ModaldoddyNo ratings yet
- Chapter 3 Multiple Linear RegressionDocument32 pagesChapter 3 Multiple Linear RegressionChriss TwhNo ratings yet
- Simple Regression & Correlation AnalysisDocument22 pagesSimple Regression & Correlation AnalysisAfaq SanaNo ratings yet
- PD-5-423 Module Characterization Energy Prediction Adjustment For Local SpectrumDocument3 pagesPD-5-423 Module Characterization Energy Prediction Adjustment For Local Spectrummiguelrobertosales337No ratings yet
- BFBV ReportDocument22 pagesBFBV ReportAASTHA MITTALNo ratings yet
- Chapter 4Document9 pagesChapter 4Rizwan RaziNo ratings yet
- Prediction of Physical Properties of Hydrocarbons and Petroleum Fractions by A New Group-Contribution MethodDocument6 pagesPrediction of Physical Properties of Hydrocarbons and Petroleum Fractions by A New Group-Contribution MethodJosé Blanco MosqueraNo ratings yet
- Class 10 Factor Analysis IDocument45 pagesClass 10 Factor Analysis IKenny ReyesNo ratings yet
- Aapm 2012Document3 pagesAapm 2012Peter HaseNo ratings yet
- (Velda Rifka Almira) Statistical AnalysisDocument13 pages(Velda Rifka Almira) Statistical Analysis22098713No ratings yet
- Green Tio2 as Nanocarriers for Targeting Cervical Cancer Cell LinesFrom EverandGreen Tio2 as Nanocarriers for Targeting Cervical Cancer Cell LinesNo ratings yet
- Digital PaymentDocument12 pagesDigital PaymentShowkatul IslamNo ratings yet
- 2b Factor AnaysisDocument24 pages2b Factor AnaysisWondwosen TilahunNo ratings yet
- Rebranding and Impact Toward Brand Equity: Goi Mei TehDocument14 pagesRebranding and Impact Toward Brand Equity: Goi Mei Tehowaiskhan_M100% (1)
- Potential NicheDocument13 pagesPotential NicheMiao BingNo ratings yet
- Factors Determining E-Learning Service Quality: Muhammad Amaad Uppal, Samnan Ali and Stephen R. GulliverDocument15 pagesFactors Determining E-Learning Service Quality: Muhammad Amaad Uppal, Samnan Ali and Stephen R. GulliverTheresia WatiNo ratings yet
- Replicability of Factors in CRPBI (Schludermann, 1970)Document13 pagesReplicability of Factors in CRPBI (Schludermann, 1970)Maria clara RegoNo ratings yet
- This Item Is The Archived Peer-Reviewed Author-Version ofDocument35 pagesThis Item Is The Archived Peer-Reviewed Author-Version ofJon SNo ratings yet
- E-Wallet: Factors Influencing User Acceptance Towards Cashless Society in Malaysia Among Public UniversitiesDocument8 pagesE-Wallet: Factors Influencing User Acceptance Towards Cashless Society in Malaysia Among Public UniversitiesLee Sook YeenNo ratings yet
- A Brief Guide To Structural Equation Modeling: The Counseling Psychologist September 2006Document34 pagesA Brief Guide To Structural Equation Modeling: The Counseling Psychologist September 2006Norberth Ioan OkrosNo ratings yet
- Rubach 2020Document17 pagesRubach 2020Myer Reign MendozaNo ratings yet
- Post Graduate Diploma in Business Management: On The Partial Fulfillment of 3 Tri-Semester ofDocument42 pagesPost Graduate Diploma in Business Management: On The Partial Fulfillment of 3 Tri-Semester ofchandanjeeNo ratings yet
- Writing Up A Factor AnalysisDocument7 pagesWriting Up A Factor AnalysisKhan SahabNo ratings yet
- 7.01 Feature SelectionDocument3 pages7.01 Feature Selectionjayant khanvilkarNo ratings yet
- Articol 2 Warehouse DesignDocument12 pagesArticol 2 Warehouse DesignGabriela Uretu100% (1)
- Brdar, Pokrajac, 1993 - Social Competence and Empathy - AlpDocument6 pagesBrdar, Pokrajac, 1993 - Social Competence and Empathy - AlpbrdarinNo ratings yet
- Analyzing The Factors Influencing The Attractiveness of Dong Thap Tourist Destination For Domestic TouristsDocument8 pagesAnalyzing The Factors Influencing The Attractiveness of Dong Thap Tourist Destination For Domestic TouristsPoonam KilaniyaNo ratings yet
- Ijm 10 06 055Document9 pagesIjm 10 06 055Phạm Phương ThùyNo ratings yet
- Chapter 11 Factorial ANOVADocument32 pagesChapter 11 Factorial ANOVALis GuziNo ratings yet
- Aappq PDFDocument11 pagesAappq PDFNalau Sapu RataNo ratings yet
- Total Quality Management Practices and Results in Food CompaniesDocument20 pagesTotal Quality Management Practices and Results in Food CompaniesNurul IzzatiNo ratings yet
- Ba7207 Business Research Methods Question Bank EditedDocument9 pagesBa7207 Business Research Methods Question Bank EditedVenkatNo ratings yet
- Statistics in EducationDocument28 pagesStatistics in Educationhu tongNo ratings yet
- Epidemiological MethodDocument7 pagesEpidemiological MethodAli Aman QaisarNo ratings yet
- Tests of Significance in Factor Analysis: JuneDocument9 pagesTests of Significance in Factor Analysis: JuneSajid Mohy Ul DinNo ratings yet
- A Study On Employees' Job Satisfaction in Leather Goods Manufacturing CompaniesDocument12 pagesA Study On Employees' Job Satisfaction in Leather Goods Manufacturing Companiesarcherselevators100% (1)
- The Effect of Destination Image On Destination Loyalty: An Application in AlanyaDocument13 pagesThe Effect of Destination Image On Destination Loyalty: An Application in AlanyaFERREN LEE SETIAWANNo ratings yet
- Assessing New Product Development Success Factors in The Thai Food IndustryDocument23 pagesAssessing New Product Development Success Factors in The Thai Food IndustryNuttoShinNo ratings yet
- A1 - 2023 - Who's Remembering To Buy The Eggs The Meaning, Measurement, and Implications of Invisible Family LoadDocument26 pagesA1 - 2023 - Who's Remembering To Buy The Eggs The Meaning, Measurement, and Implications of Invisible Family LoadamandaNo ratings yet
- In Kelantan A Research On Customer SatisfactionDocument6 pagesIn Kelantan A Research On Customer SatisfactionKhalid Mishczsuski LimuNo ratings yet












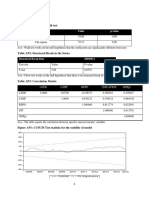











































































Download as pdf or txt
You might also like
- Fluid Friction in Pipes Laboratory ReportDocument6 pagesFluid Friction in Pipes Laboratory ReportABamishe50% (2)
- The Career Futures InventoryDocument23 pagesThe Career Futures InventorySangLintangPanjerino0% (1)
- Quantitative Analysis or Rare Earths by X-Ray Fluorescence SpectrometryDocument8 pagesQuantitative Analysis or Rare Earths by X-Ray Fluorescence Spectrometrykulihat_hijauNo ratings yet
- Monika ProjectDocument34 pagesMonika Projectgurleen kaurNo ratings yet
- The Influence of Fundamental and Macroeconomic Analysis On Stock PriceDocument13 pagesThe Influence of Fundamental and Macroeconomic Analysis On Stock PriceWiria SalvatoreNo ratings yet
- Interpret DataDocument3 pagesInterpret Datacikedis.chocoNo ratings yet
- Example of Analyze Taguchi Design (Dynamic) - Minitab PDFDocument8 pagesExample of Analyze Taguchi Design (Dynamic) - Minitab PDFSachinihcasSacNo ratings yet
- Water Quality AnalysisDocument4 pagesWater Quality AnalysisMaahir AuckbarallyNo ratings yet
- Paper in TTP Scintific - Net-AuthorsDocument7 pagesPaper in TTP Scintific - Net-AuthorsMohan Kumar Pradhan Associate ProfessorNo ratings yet
- Institutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelDocument14 pagesInstitutional Quality Indicators and Their Impact On Attracting Foreign Direct Investment in Algeria Using The ARDL ModelNajib BenslimaneNo ratings yet
- Jaypee Institute of Information Technology NoidaDocument9 pagesJaypee Institute of Information Technology NoidaApoorv KumarNo ratings yet
- Submitted To: Sir Saeed Meo: MBEW-F17-17Document13 pagesSubmitted To: Sir Saeed Meo: MBEW-F17-17Arsal AliNo ratings yet
- Table AP1: Results of Wald Test: 5.0 AppendixDocument2 pagesTable AP1: Results of Wald Test: 5.0 Appendixbharatii khannaNo ratings yet
- Jaypee Institute of Information Technology NoidaDocument10 pagesJaypee Institute of Information Technology NoidaApoorv KumarNo ratings yet
- 1986 - Prediction of Properties of Petroleum Mixtures - Improvement in Reliability and Validity of Tuned ParametersDocument8 pages1986 - Prediction of Properties of Petroleum Mixtures - Improvement in Reliability and Validity of Tuned ParametersRosendo Monroy LoperenaNo ratings yet
- Ja200299u Si 002Document48 pagesJa200299u Si 002Mutiva YyNo ratings yet
- Phar0011 Radioligand Binding Analysis 2022Document5 pagesPhar0011 Radioligand Binding Analysis 20224wqzcq7p9xNo ratings yet
- 6.2. MethodologyDocument12 pages6.2. MethodologyAtiaTahiraNo ratings yet
- Propuesta de Solución de LillyDocument5 pagesPropuesta de Solución de LillyJames Rodriguez CarvajalNo ratings yet
- SLH Chapter FourDocument8 pagesSLH Chapter Foursadiqmedical160No ratings yet
- Empirical Findings: Unit Root TestDocument4 pagesEmpirical Findings: Unit Root TestkhalidhamdanNo ratings yet
- Financial Test ReportDocument11 pagesFinancial Test ReportAsad GhaffarNo ratings yet
- Vigneau Devaux Qannari Robert JChemo 1997Document12 pagesVigneau Devaux Qannari Robert JChemo 1997Stefany ValverdeNo ratings yet
- Chapter Fou1Document11 pagesChapter Fou1sue patrickNo ratings yet
- Mef 402 - InterpretationDocument27 pagesMef 402 - InterpretationDubem EnarunaNo ratings yet
- Chap VDocument16 pagesChap VBasavaraj MtNo ratings yet
- FN GRP 4.2 Assignment No 5Document7 pagesFN GRP 4.2 Assignment No 5Darshan sakleNo ratings yet
- 4.2 Empirical Analysis: 4.2.1 Descriptive StatisticsDocument12 pages4.2 Empirical Analysis: 4.2.1 Descriptive StatisticsAtiya KhanNo ratings yet
- Base Metal MMCRM Oreas 38: Ore Research & Exploration Pty LTDDocument22 pagesBase Metal MMCRM Oreas 38: Ore Research & Exploration Pty LTDHeber Diaz ChavezNo ratings yet
- EDUARDO JR. BAGAPORO - Laboratory Activity 8 Report SheetDocument4 pagesEDUARDO JR. BAGAPORO - Laboratory Activity 8 Report SheetJr BagaporoNo ratings yet
- IET 421/621 (Spring 2016) Exam-1 Total Points: 20Document5 pagesIET 421/621 (Spring 2016) Exam-1 Total Points: 20YUVISHAIS PAOLA PAYARES BALDIRISNo ratings yet
- IET 421/621 (Spring 2016) Exam-1 Total Points: 20Document5 pagesIET 421/621 (Spring 2016) Exam-1 Total Points: 20YUVISHAIS PAOLA PAYARES BALDIRISNo ratings yet
- Chapter Four Model Analysis and Estimation 4.1Document8 pagesChapter Four Model Analysis and Estimation 4.1Oladipupo Mayowa PaulNo ratings yet
- Regression Analysis and Its Interpretation With SpssDocument4 pagesRegression Analysis and Its Interpretation With SpssChakraKhadkaNo ratings yet
- Decision Science - June - 2023Document8 pagesDecision Science - June - 2023kumar.rajan0108No ratings yet
- One-Way ANOVA Calculator: Success!Document6 pagesOne-Way ANOVA Calculator: Success!Marcos DmitriNo ratings yet
- Module 4 Index NumbersDocument16 pagesModule 4 Index Numbersarunteja.chithram786No ratings yet
- Ardl Analysis Chapter Four FinalDocument9 pagesArdl Analysis Chapter Four Finalsadiqmedical160No ratings yet
- MTBF - Report - Rambutan (-I) - V1Document15 pagesMTBF - Report - Rambutan (-I) - V1Madhuseptember2022No ratings yet
- Stata Equipo BLDocument1 pageStata Equipo BLDaniel OlveraNo ratings yet
- FDP On Applied Econometrics PresentationDocument17 pagesFDP On Applied Econometrics PresentationDrDeepti JiNo ratings yet
- OUTPUTDocument3 pagesOUTPUTsalekeen sakibNo ratings yet
- Gold Reference MaterialDocument6 pagesGold Reference MaterialSatrya RachmanNo ratings yet
- Descriptive Statistics: Data Analysis AssignmentDocument9 pagesDescriptive Statistics: Data Analysis AssignmentSuriya SamNo ratings yet
- Analysis of Primary DataDocument20 pagesAnalysis of Primary Dataashok jaipalNo ratings yet
- Chapter Four The MethodologyDocument20 pagesChapter Four The MethodologyKola BamgboseNo ratings yet
- Chem Plant Assignment 1Document14 pagesChem Plant Assignment 1lungani butheleziNo ratings yet
- Adenike Project Chapter 4-5Document21 pagesAdenike Project Chapter 4-5Emeka MichealNo ratings yet
- FinalDocument17 pagesFinalhina khanNo ratings yet
- Profitabilitas, Liquiitas, Ukuran Perusahaan Terhaap Struktur ModalDocument10 pagesProfitabilitas, Liquiitas, Ukuran Perusahaan Terhaap Struktur ModaldoddyNo ratings yet
- Chapter 3 Multiple Linear RegressionDocument32 pagesChapter 3 Multiple Linear RegressionChriss TwhNo ratings yet
- Simple Regression & Correlation AnalysisDocument22 pagesSimple Regression & Correlation AnalysisAfaq SanaNo ratings yet
- PD-5-423 Module Characterization Energy Prediction Adjustment For Local SpectrumDocument3 pagesPD-5-423 Module Characterization Energy Prediction Adjustment For Local Spectrummiguelrobertosales337No ratings yet
- BFBV ReportDocument22 pagesBFBV ReportAASTHA MITTALNo ratings yet
- Chapter 4Document9 pagesChapter 4Rizwan RaziNo ratings yet
- Prediction of Physical Properties of Hydrocarbons and Petroleum Fractions by A New Group-Contribution MethodDocument6 pagesPrediction of Physical Properties of Hydrocarbons and Petroleum Fractions by A New Group-Contribution MethodJosé Blanco MosqueraNo ratings yet
- Class 10 Factor Analysis IDocument45 pagesClass 10 Factor Analysis IKenny ReyesNo ratings yet
- Aapm 2012Document3 pagesAapm 2012Peter HaseNo ratings yet
- (Velda Rifka Almira) Statistical AnalysisDocument13 pages(Velda Rifka Almira) Statistical Analysis22098713No ratings yet
- Green Tio2 as Nanocarriers for Targeting Cervical Cancer Cell LinesFrom EverandGreen Tio2 as Nanocarriers for Targeting Cervical Cancer Cell LinesNo ratings yet
- Digital PaymentDocument12 pagesDigital PaymentShowkatul IslamNo ratings yet
- 2b Factor AnaysisDocument24 pages2b Factor AnaysisWondwosen TilahunNo ratings yet
- Rebranding and Impact Toward Brand Equity: Goi Mei TehDocument14 pagesRebranding and Impact Toward Brand Equity: Goi Mei Tehowaiskhan_M100% (1)
- Potential NicheDocument13 pagesPotential NicheMiao BingNo ratings yet
- Factors Determining E-Learning Service Quality: Muhammad Amaad Uppal, Samnan Ali and Stephen R. GulliverDocument15 pagesFactors Determining E-Learning Service Quality: Muhammad Amaad Uppal, Samnan Ali and Stephen R. GulliverTheresia WatiNo ratings yet
- Replicability of Factors in CRPBI (Schludermann, 1970)Document13 pagesReplicability of Factors in CRPBI (Schludermann, 1970)Maria clara RegoNo ratings yet
- This Item Is The Archived Peer-Reviewed Author-Version ofDocument35 pagesThis Item Is The Archived Peer-Reviewed Author-Version ofJon SNo ratings yet
- E-Wallet: Factors Influencing User Acceptance Towards Cashless Society in Malaysia Among Public UniversitiesDocument8 pagesE-Wallet: Factors Influencing User Acceptance Towards Cashless Society in Malaysia Among Public UniversitiesLee Sook YeenNo ratings yet
- A Brief Guide To Structural Equation Modeling: The Counseling Psychologist September 2006Document34 pagesA Brief Guide To Structural Equation Modeling: The Counseling Psychologist September 2006Norberth Ioan OkrosNo ratings yet
- Rubach 2020Document17 pagesRubach 2020Myer Reign MendozaNo ratings yet
- Post Graduate Diploma in Business Management: On The Partial Fulfillment of 3 Tri-Semester ofDocument42 pagesPost Graduate Diploma in Business Management: On The Partial Fulfillment of 3 Tri-Semester ofchandanjeeNo ratings yet
- Writing Up A Factor AnalysisDocument7 pagesWriting Up A Factor AnalysisKhan SahabNo ratings yet
- 7.01 Feature SelectionDocument3 pages7.01 Feature Selectionjayant khanvilkarNo ratings yet
- Articol 2 Warehouse DesignDocument12 pagesArticol 2 Warehouse DesignGabriela Uretu100% (1)
- Brdar, Pokrajac, 1993 - Social Competence and Empathy - AlpDocument6 pagesBrdar, Pokrajac, 1993 - Social Competence and Empathy - AlpbrdarinNo ratings yet
- Analyzing The Factors Influencing The Attractiveness of Dong Thap Tourist Destination For Domestic TouristsDocument8 pagesAnalyzing The Factors Influencing The Attractiveness of Dong Thap Tourist Destination For Domestic TouristsPoonam KilaniyaNo ratings yet
- Ijm 10 06 055Document9 pagesIjm 10 06 055Phạm Phương ThùyNo ratings yet
- Chapter 11 Factorial ANOVADocument32 pagesChapter 11 Factorial ANOVALis GuziNo ratings yet
- Aappq PDFDocument11 pagesAappq PDFNalau Sapu RataNo ratings yet
- Total Quality Management Practices and Results in Food CompaniesDocument20 pagesTotal Quality Management Practices and Results in Food CompaniesNurul IzzatiNo ratings yet
- Ba7207 Business Research Methods Question Bank EditedDocument9 pagesBa7207 Business Research Methods Question Bank EditedVenkatNo ratings yet
- Statistics in EducationDocument28 pagesStatistics in Educationhu tongNo ratings yet
- Epidemiological MethodDocument7 pagesEpidemiological MethodAli Aman QaisarNo ratings yet
- Tests of Significance in Factor Analysis: JuneDocument9 pagesTests of Significance in Factor Analysis: JuneSajid Mohy Ul DinNo ratings yet
- A Study On Employees' Job Satisfaction in Leather Goods Manufacturing CompaniesDocument12 pagesA Study On Employees' Job Satisfaction in Leather Goods Manufacturing Companiesarcherselevators100% (1)
- The Effect of Destination Image On Destination Loyalty: An Application in AlanyaDocument13 pagesThe Effect of Destination Image On Destination Loyalty: An Application in AlanyaFERREN LEE SETIAWANNo ratings yet
- Assessing New Product Development Success Factors in The Thai Food IndustryDocument23 pagesAssessing New Product Development Success Factors in The Thai Food IndustryNuttoShinNo ratings yet
- A1 - 2023 - Who's Remembering To Buy The Eggs The Meaning, Measurement, and Implications of Invisible Family LoadDocument26 pagesA1 - 2023 - Who's Remembering To Buy The Eggs The Meaning, Measurement, and Implications of Invisible Family LoadamandaNo ratings yet
- In Kelantan A Research On Customer SatisfactionDocument6 pagesIn Kelantan A Research On Customer SatisfactionKhalid Mishczsuski LimuNo ratings yet