Download as pdf or txt
You might also like
- Bangor Dyslexia TestDocument7 pagesBangor Dyslexia Testhafsa11160% (15)
- Child Development An Active Learning Approach 3rd Edition Levine Test BankDocument23 pagesChild Development An Active Learning Approach 3rd Edition Levine Test Bankwhateverluminarycx9100% (29)
- Brainy Klasa 4 Teaching Notes and Answer KeyDocument135 pagesBrainy Klasa 4 Teaching Notes and Answer Keysamborini100% (2)
- Sidman 1971Document10 pagesSidman 1971siepa0% (1)
- Neurodiversity Celebration Week 2021Document22 pagesNeurodiversity Celebration Week 2021Belegan CrengutaNo ratings yet
- Lesson Plan 1 Alphabetic PrincipleDocument2 pagesLesson Plan 1 Alphabetic Principleapi-385281264No ratings yet
- Fourteen Steps To Teach Dyslexics 7 StepsDocument20 pagesFourteen Steps To Teach Dyslexics 7 StepsMischa SmirnovNo ratings yet
- Dyslexia & Academic WritingDocument17 pagesDyslexia & Academic WritingDavemate100% (1)
- Pacheco Et Al (2014) Cognitive Profiles DD in PortugueseDocument17 pagesPacheco Et Al (2014) Cognitive Profiles DD in Portuguesediana_carreiraNo ratings yet
- 19 Parrila, Dudley, Song & Georgiou, Meta analysis of reading level match dyslexia studies in consistent alphabetic orthographiesDocument27 pages19 Parrila, Dudley, Song & Georgiou, Meta analysis of reading level match dyslexia studies in consistent alphabetic orthographiesjohanaruizc19No ratings yet
- Araújo Et Al (2013) Phonological ProcessDocument16 pagesAraújo Et Al (2013) Phonological ProcessCarolinaNo ratings yet
- Subtipos de Dislexia Vellutino y Fletcher en Developmental DyslexiaDocument6 pagesSubtipos de Dislexia Vellutino y Fletcher en Developmental DyslexiaAndy AramayoNo ratings yet
- Jurnal 2Document9 pagesJurnal 2yoghes waryNo ratings yet
- Subtipos de Dislexia en Lenguas Que DifiDocument34 pagesSubtipos de Dislexia en Lenguas Que DifiAlexandre Jose Melo BarreiraNo ratings yet
- Octávio Moura Et Al (2020) Double Deficit in DDDocument19 pagesOctávio Moura Et Al (2020) Double Deficit in DDAna MartinsNo ratings yet
- Huettig Et Al 2015 DyslexftffiaDocument26 pagesHuettig Et Al 2015 Dyslexftffiadimich08No ratings yet
- Awg 076Document25 pagesAwg 076courursulaNo ratings yet
- Doctoral Thesis Subtypes of DevelopmentaDocument300 pagesDoctoral Thesis Subtypes of DevelopmentaИрина МокракNo ratings yet
- Reading Achievement in Relation To Phonological Coding and Awareness in Deaf Readers: A Meta-AnalysisDocument25 pagesReading Achievement in Relation To Phonological Coding and Awareness in Deaf Readers: A Meta-AnalysisNino LomadzeNo ratings yet
- Farmer-Klein1995 Article TheEvidenceForATemporalProcessDocument34 pagesFarmer-Klein1995 Article TheEvidenceForATemporalProcessangieNo ratings yet
- Im Plica Tures AutismDocument0 pagesIm Plica Tures AutismJesus RiveraNo ratings yet
- Research Paper DyslexiaDocument6 pagesResearch Paper Dyslexiac9jg5wx4100% (1)
- Functional Neuroanatomical Evidence For The Double-Deficit HypothesisDocument12 pagesFunctional Neuroanatomical Evidence For The Double-Deficit HypothesisCíntia SantosNo ratings yet
- Oral Language Deficits in Familial Dyslexia: A Meta-Analysis and ReviewDocument48 pagesOral Language Deficits in Familial Dyslexia: A Meta-Analysis and ReviewnurlatifahNo ratings yet
- Transitional Probability and Word SegmentationDocument4 pagesTransitional Probability and Word Segmentationgiuseppe varaschinNo ratings yet
- Reading Research Quarterly - 2021 - Law - Morphological Processing in Children With Developmental Dyslexia A Visual MaskedDocument15 pagesReading Research Quarterly - 2021 - Law - Morphological Processing in Children With Developmental Dyslexia A Visual Maskedjabangunsitumorang04No ratings yet
- Anne-Marie DePape - Use of Prosody and Information Structure in High Functioning Adults With AutismDocument13 pagesAnne-Marie DePape - Use of Prosody and Information Structure in High Functioning Adults With Autismdaniel_avila4251No ratings yet
- Introduction To This Special Issue Dyslexia Across Languages and Writing SystemsDocument7 pagesIntroduction To This Special Issue Dyslexia Across Languages and Writing SystemsMarilyn BucahchanNo ratings yet
- Performance of Children With Developmental Dyslexia On High and Low Topological Entropy Artificial Grammar Learning TaskDocument17 pagesPerformance of Children With Developmental Dyslexia On High and Low Topological Entropy Artificial Grammar Learning TaskPriss SaezNo ratings yet
- Chinese Dyslexic's Statistical Learning and Orthographic Regularity LearningDocument32 pagesChinese Dyslexic's Statistical Learning and Orthographic Regularity LearningmatttNo ratings yet
- Nihms 1063020Document19 pagesNihms 1063020Fernanda FreitasNo ratings yet
- Hella Et Al. 2013Document9 pagesHella Et Al. 2013Felipe SanchezNo ratings yet
- The Dissociation of Word Reading and Text CompreheDocument26 pagesThe Dissociation of Word Reading and Text CompreheAndrea BereczNo ratings yet
- Adults With DislexiaDocument27 pagesAdults With DislexiaAfiqatiyah shopNo ratings yet
- Basma Et Al - 2024 - N400 y Alexia RevisiónDocument14 pagesBasma Et Al - 2024 - N400 y Alexia RevisiónMicaela DiNo ratings yet
- Procedural Memory in Children With Autism Double DissociationDocument4 pagesProcedural Memory in Children With Autism Double DissociationEditor IJTSRDNo ratings yet
- The Place of Morphology in Learning To Read in English: SciencedirectDocument10 pagesThe Place of Morphology in Learning To Read in English: SciencedirectasNo ratings yet
- Reading Ability in Children Relates To Rhythm Perception Across ModalitiesDocument27 pagesReading Ability in Children Relates To Rhythm Perception Across Modalitiesbiahonda15No ratings yet
- Orthographic and Semantic Processing in Young Readers: Lara R. PolseDocument26 pagesOrthographic and Semantic Processing in Young Readers: Lara R. PolseNani JuraidaNo ratings yet
- Bettcher Apsy 652 Term PaperDocument13 pagesBettcher Apsy 652 Term Paperapi-162509150No ratings yet
- Of Developmental Dyslexia What Is Orthography, Orthographic Knowledge and Orthographic Processing?Document6 pagesOf Developmental Dyslexia What Is Orthography, Orthographic Knowledge and Orthographic Processing?jbc6018No ratings yet
- Evolution of Language From The Aphasia PerspectiveDocument3 pagesEvolution of Language From The Aphasia PerspectiveLaura Arbelaez ArcilaNo ratings yet
- Language Performance in SchizophreniaDocument19 pagesLanguage Performance in SchizophreniahandpamNo ratings yet
- Gather Cole 1993Document14 pagesGather Cole 1993HocvienMAENo ratings yet
- Apraxia and Verbal Dyspraxia For Educators: Accommodations in The ClassroomDocument12 pagesApraxia and Verbal Dyspraxia For Educators: Accommodations in The Classroomapi-584896872No ratings yet
- Running Head: Morphology and Compensation in Adults With DyslexiaDocument30 pagesRunning Head: Morphology and Compensation in Adults With DyslexiaRustian GunadiNo ratings yet
- SnowlingDocument3 pagesSnowlingjorgedacunhaNo ratings yet
- 1978 Caramazza Berndt PBDocument21 pages1978 Caramazza Berndt PBEddiesvoiceNo ratings yet
- Evans Levinson BBS ResponseDocument21 pagesEvans Levinson BBS ResponsenugrahasakertabaratNo ratings yet
- DyslexiaDocument14 pagesDyslexiaRazelFernandezNo ratings yet
- The Contribution of Phonological Short-Term Memory To Artificial Grammar LearningDocument15 pagesThe Contribution of Phonological Short-Term Memory To Artificial Grammar LearningLaura CannellaNo ratings yet
- DISLEXIADocument25 pagesDISLEXIANanda MachadoNo ratings yet
- Kissing and Dancing TestDocument13 pagesKissing and Dancing TestisabellesheungNo ratings yet
- Fnhum 08 00331Document13 pagesFnhum 08 00331courursulaNo ratings yet
- Effects of Fluency, Oral Language and Ef On Reading Comprehension PerformanceDocument21 pagesEffects of Fluency, Oral Language and Ef On Reading Comprehension PerformanceCecilia AgostNo ratings yet
- Vulchanova Et Al - 2015Document11 pagesVulchanova Et Al - 2015Anahí Lopez FavilliNo ratings yet
- 2018 - LSHSS Dyslc 18 0049Document12 pages2018 - LSHSS Dyslc 18 0049chrisrodriguesfgaNo ratings yet
- Dyslexia Research Paper ConclusionDocument7 pagesDyslexia Research Paper Conclusionfzg9e1r9100% (1)
- Research Paper On Dyslexia and EducationDocument5 pagesResearch Paper On Dyslexia and Educationgz8zw71w100% (1)
- CPL 380Document10 pagesCPL 380Ioanna Maria MonopoliNo ratings yet
- Marks 2021Document23 pagesMarks 2021Centro AllkünNo ratings yet
- Dyslexia Research PaperDocument8 pagesDyslexia Research Paperscxofyplg100% (1)
- Summary of Review of ArticlesDocument8 pagesSummary of Review of Articleskeihoina keihoinaNo ratings yet
- JamesGaskellHenderson2020 Pre-Print RevisedDocument46 pagesJamesGaskellHenderson2020 Pre-Print RevisedКароліна ГиричNo ratings yet
- PsycholinguisticsDocument5 pagesPsycholinguisticsipinx gantengNo ratings yet
- Analysis of a Medical Research Corpus: A Prelude for Learners, Teachers, Readers and BeyondFrom EverandAnalysis of a Medical Research Corpus: A Prelude for Learners, Teachers, Readers and BeyondNo ratings yet
- Informal Speech: Alphabetic and Phonemic Text with Statistical Analyses and TablesFrom EverandInformal Speech: Alphabetic and Phonemic Text with Statistical Analyses and TablesNo ratings yet
- Body and HealthDocument2 pagesBody and HealthSze Sze LiNo ratings yet
- Technology Predictions For 2025Document1 pageTechnology Predictions For 2025Sze Sze LiNo ratings yet
- Technology Predictions For 2025Document1 pageTechnology Predictions For 2025Sze Sze LiNo ratings yet
- Technology Predictions For 2025Document1 pageTechnology Predictions For 2025Sze Sze LiNo ratings yet
- Technology Predictions For 2025Document1 pageTechnology Predictions For 2025Sze Sze LiNo ratings yet
- Reading Chinese ScriptDocument1 pageReading Chinese ScriptSze Sze LiNo ratings yet
- Technology Predictions For 2025Document1 pageTechnology Predictions For 2025Sze Sze LiNo ratings yet
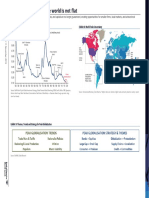
- Theme 2020 - 1. Peak Globalization - The World Is Not FlatDocument4 pagesTheme 2020 - 1. Peak Globalization - The World Is Not FlatSze Sze LiNo ratings yet
- New Paradigms of The 2020S: Exhibit 1: Bofaml Transforming World: 2010S vs. 2020SDocument1 pageNew Paradigms of The 2020S: Exhibit 1: Bofaml Transforming World: 2010S vs. 2020SSze Sze LiNo ratings yet
- Musical Phrase BoundariesDocument9 pagesMusical Phrase BoundariesSze Sze LiNo ratings yet
- U.S. Views of China Increasingly Negative Amid Coronavirus OutbreakDocument25 pagesU.S. Views of China Increasingly Negative Amid Coronavirus OutbreakSze Sze LiNo ratings yet
- Smartkarma Special Report Editors PicksDocument234 pagesSmartkarma Special Report Editors PicksSze Sze LiNo ratings yet
- LPDocument478 pagesLPRaunak JainNo ratings yet
- Mathematics Anxiety in Secondary Students in England: Independent Maths LD/Dyscalculia Consultant, Ledbury, UKDocument8 pagesMathematics Anxiety in Secondary Students in England: Independent Maths LD/Dyscalculia Consultant, Ledbury, UK贼贼JacksonNo ratings yet
- IE - Small Victories Pedro's StoryDocument23 pagesIE - Small Victories Pedro's StoryALPASLAN TOKERNo ratings yet
- Am I DyslexicDocument2 pagesAm I Dyslexickeed07No ratings yet
- Genius and CreativityDocument13 pagesGenius and CreativityHelper12No ratings yet
- SMTDocument42 pagesSMTMirjana PrekovicNo ratings yet
- Anna Marie Ranillo - Job-Embedded-Learning-PlanDocument5 pagesAnna Marie Ranillo - Job-Embedded-Learning-PlanAnna Marie Andal RanilloNo ratings yet
- 19 - Executive Functions in Children With Learning Disabilities (Exekutive Funktionen Bei Kindern Mit Lernstörungen)Document17 pages19 - Executive Functions in Children With Learning Disabilities (Exekutive Funktionen Bei Kindern Mit Lernstörungen)Faras ArinalNo ratings yet
- Orton Who What and HowDocument10 pagesOrton Who What and HowSueNo ratings yet
- Dissertation Dyslexia and Self EsteemDocument8 pagesDissertation Dyslexia and Self EsteemPaperWritingServicesForCollegeStudentsSingapore100% (1)
- Review of Related LiteratureDocument9 pagesReview of Related Literaturejohnciryl serranoNo ratings yet
- VellutinoDocument39 pagesVellutinojorgedacunhaNo ratings yet
- Inclusive Practices: English LanguageDocument46 pagesInclusive Practices: English LanguageNguyen Thi Thu TrangNo ratings yet
- COGS1010 Test 3Document11 pagesCOGS1010 Test 3Jessica TandonNo ratings yet
- Specific Learning DisordersDocument33 pagesSpecific Learning DisordersGnaneswar PiduguNo ratings yet
- Eng2 Every Child Is Special Movie ReviewDocument6 pagesEng2 Every Child Is Special Movie ReviewOliva Gardon Perez0% (2)
- DyslexiaDocument1 pageDyslexiaapi-242024640No ratings yet
- Literature ReviewDocument7 pagesLiterature Reviewapi-320716438No ratings yet
- Aphasia and DyslexiaDocument17 pagesAphasia and DyslexiaMary Christine GonzalesNo ratings yet
- The Efficacy of Computer Assisted Cognitive Training in The Remediation of Specific Learning DisordersDocument4 pagesThe Efficacy of Computer Assisted Cognitive Training in The Remediation of Specific Learning DisordersRakesh KumarNo ratings yet
- Music TherapyDocument18 pagesMusic TherapyMarylyn Anne AtotNo ratings yet
- Oral Versus Written Assessments: A Test of Student Performance and AttitudesDocument14 pagesOral Versus Written Assessments: A Test of Student Performance and AttitudesSilvinaNo ratings yet