Download as pdf or txt
You might also like
- Practical Approaches To Applied Research and Program Evaluation For Helping Professionals 1St Edition PDF Full Chapter PDFDocument50 pagesPractical Approaches To Applied Research and Program Evaluation For Helping Professionals 1St Edition PDF Full Chapter PDFrasmahjonaki34100% (6)
- AMC 12 Study Guide PDFDocument17 pagesAMC 12 Study Guide PDFHarsha PolavaramNo ratings yet
- Greek and Roman Jewellery (Art History)Document168 pagesGreek and Roman Jewellery (Art History)MN D King Maker100% (4)
- Power System Analysis II: Instructor: E-Mail: Office PhoneDocument66 pagesPower System Analysis II: Instructor: E-Mail: Office PhoneSelah TalepNo ratings yet
- 1 1 An Overview of Communication Skills in EnglishDocument11 pages1 1 An Overview of Communication Skills in EnglishBARIBOR SHADRACH100% (7)
- Ch4 SlidesDocument52 pagesCh4 Slidesthư đặng thị anhNo ratings yet
- Week 4 - The Multiple Linear Regression Model (Part 1) PDFDocument35 pagesWeek 4 - The Multiple Linear Regression Model (Part 1) PDFWindyee TanNo ratings yet
- Multiple Linear Regression 2Document30 pagesMultiple Linear Regression 2muthonifae19No ratings yet
- Lecture Introductory Econometrics For Finance: Chapter 4 - Chris BrooksDocument52 pagesLecture Introductory Econometrics For Finance: Chapter 4 - Chris BrooksDuy100% (1)
- Reservoir Simulation NoteDocument194 pagesReservoir Simulation NoteAminNo ratings yet
- A Brief Overview of The Classical Linear Regression Model (CLRM)Document85 pagesA Brief Overview of The Classical Linear Regression Model (CLRM)Nouf ANo ratings yet
- Ch4 Slides Ed3 Feb2021Document29 pagesCh4 Slides Ed3 Feb2021Phuc Hong PhamNo ratings yet
- Univariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' © Chris Brooks 2002 1Document62 pagesUnivariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' © Chris Brooks 2002 1Pawan PreetNo ratings yet
- Test and Goodness of Fit: Investment and Financial Data Analysis 2017Document21 pagesTest and Goodness of Fit: Investment and Financial Data Analysis 2017zafer iqbalNo ratings yet
- Estimating Definite Integrals: AcknowledgmentDocument4 pagesEstimating Definite Integrals: AcknowledgmentSai GokulNo ratings yet
- Ch3 Slides Ed4 2024Document72 pagesCh3 Slides Ed4 2024ann1172002No ratings yet
- Chap 6Document40 pagesChap 6pranjal meshramNo ratings yet
- RBC Extensions sp15Document52 pagesRBC Extensions sp15Franck BanaletNo ratings yet
- MatricesAndVectors PDFDocument53 pagesMatricesAndVectors PDFjaslinNo ratings yet
- Chapter 05 - Least SquaresDocument27 pagesChapter 05 - Least SquaresMuhammad IsmailNo ratings yet
- BE368 Lecture 4Document28 pagesBE368 Lecture 4Muhammad AfzaalNo ratings yet
- Lecture 2.1 RegressionDocument20 pagesLecture 2.1 RegressionLaw BusinessNo ratings yet
- MSC Econometrics (Ec402) : 2021-2022 Problem Set #3Document3 pagesMSC Econometrics (Ec402) : 2021-2022 Problem Set #3Yash PatelNo ratings yet
- Introduction To Uncertainty: Jes Us Fern Andez-Villaverde Duke UniversityDocument30 pagesIntroduction To Uncertainty: Jes Us Fern Andez-Villaverde Duke Universitythakur08No ratings yet
- Univariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' © Chris Brooks 2008 1Document62 pagesUnivariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' © Chris Brooks 2008 1OguzNo ratings yet
- Exam4 ReviewDocument7 pagesExam4 ReviewNoelle FreveNo ratings yet
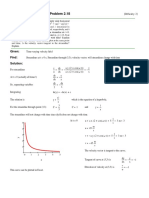
- Problem 2.18: Given: Find: SolutionDocument1 pageProblem 2.18: Given: Find: SolutionKauê BrittoNo ratings yet
- Problem 2.18 PDFDocument1 pageProblem 2.18 PDFMatheus RubikNo ratings yet
- Mathematics For Engineers PDF Ebook-1001-1005Document5 pagesMathematics For Engineers PDF Ebook-1001-1005robertodjoko001No ratings yet
- Univariate Time Series Modelling and ForecastingDocument62 pagesUnivariate Time Series Modelling and ForecastingderghalNo ratings yet
- Matrix Algebra: Addis Ababa University Computational Data Science ProgramDocument26 pagesMatrix Algebra: Addis Ababa University Computational Data Science ProgramfishNo ratings yet
- Chapter 2 P1Document20 pagesChapter 2 P1YoussefyassinNo ratings yet
- A Brief Overview of The Classical Linear Regression Model: Introductory Econometrics For Finance' © Chris Brooks 2013 1Document80 pagesA Brief Overview of The Classical Linear Regression Model: Introductory Econometrics For Finance' © Chris Brooks 2013 1sdfasdgNo ratings yet
- Von Mises Yield CriterionDocument4 pagesVon Mises Yield CriterionJanatan ChoiNo ratings yet
- Econometrics (EM2008) The K-Variable Linear Regression ModelDocument46 pagesEconometrics (EM2008) The K-Variable Linear Regression ModelSelMarie Nutelliina GomezNo ratings yet
- Univariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' by Dr. Le Trung Thanh 2020 1/73Document73 pagesUnivariate Time Series Modelling and Forecasting: Introductory Econometrics For Finance' by Dr. Le Trung Thanh 2020 1/73Huỳnh Phương Linh TrầnNo ratings yet
- Cyclotomicpolynomials GrasslDocument8 pagesCyclotomicpolynomials GrassljoseluisapNo ratings yet
- EconometricsDocument23 pagesEconometricstagashiiNo ratings yet
- Ec1 14Document16 pagesEc1 14Ayman RizwanNo ratings yet
- 2 Growth Neoclassical GrowthDocument71 pages2 Growth Neoclassical GrowthPAOLA NELLY ROJAS VALERONo ratings yet
- Ch2 Slides EditedDocument66 pagesCh2 Slides EditedFrancis Saviour John SteevanNo ratings yet
- Ch3 SlidesDocument30 pagesCh3 SlidesYiLinLiNo ratings yet
- Time - Series - in - BriefDocument11 pagesTime - Series - in - BriefPrak ParasharNo ratings yet
- Infinite Series: AppendixDocument9 pagesInfinite Series: AppendixJEENUPRIYA SAHANo ratings yet
- Lecture NotesDocument90 pagesLecture NotesSharad RaykhereNo ratings yet
- OPRE 6201: 4. Network Problems: 1.1 An LP FormulationDocument39 pagesOPRE 6201: 4. Network Problems: 1.1 An LP FormulationSajjad HossainNo ratings yet
- Statistical Interference Lecture-8Document12 pagesStatistical Interference Lecture-8Bilal KhanNo ratings yet
- OCR C1 Revision Notes PDFDocument12 pagesOCR C1 Revision Notes PDFsafaNo ratings yet
- VAR CopenhagenDocument16 pagesVAR CopenhagenCLIDERNo ratings yet
- Ch3 SlidesDocument80 pagesCh3 Slidesthư đặng thị anhNo ratings yet
- 7 1 First-Order SystemsDocument6 pages7 1 First-Order SystemsArheta ArethaNo ratings yet
- Lecture 11Document28 pagesLecture 11Usha chNo ratings yet
- On Discrete-Kirchhoff Plate Finite Elements: Implementation and Discretization ErrorDocument24 pagesOn Discrete-Kirchhoff Plate Finite Elements: Implementation and Discretization ErrorNourhan AymanNo ratings yet
- Slides Session 4Document135 pagesSlides Session 4Adarsh AgrawalNo ratings yet
- Vilan DynareDocument19 pagesVilan Dynarec9bj9bvr5dNo ratings yet
- CHP 9Document60 pagesCHP 9SarveshNo ratings yet
- Notes: Section 1: Exploratory Data AnalysisDocument6 pagesNotes: Section 1: Exploratory Data AnalysisbananacompNo ratings yet
- Chapter3 Econometrics MultipleLinearRegressionModelDocument41 pagesChapter3 Econometrics MultipleLinearRegressionModelAbdullah KhatibNo ratings yet
- Unit 5 Hard ModeDocument12 pagesUnit 5 Hard Moderakshapoddar32No ratings yet
- Ch3 Slides Ed4 March2021Document75 pagesCh3 Slides Ed4 March2021Phuc Hong PhamNo ratings yet
- RBCDocument52 pagesRBCAmine IzamNo ratings yet
- Least Squares Model Leastsquares PDFDocument27 pagesLeast Squares Model Leastsquares PDFmercure19100No ratings yet
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)From EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)No ratings yet
- Marketing Strategy vs. Marketing PlanDocument2 pagesMarketing Strategy vs. Marketing PlanNansaa BayarNo ratings yet
- Fin Ec@16Document1 pageFin Ec@16Nansaa BayarNo ratings yet
- Fin Ec@16Document1 pageFin Ec@16Nansaa BayarNo ratings yet
- Chapter 4 - Further Development and Analysis of The Classical Linear Regression ModelDocument2 pagesChapter 4 - Further Development and Analysis of The Classical Linear Regression ModelNansaa BayarNo ratings yet
- Chapter 4 - Further Development and Analysis of The Classical Linear Regression ModelDocument2 pagesChapter 4 - Further Development and Analysis of The Classical Linear Regression ModelNansaa BayarNo ratings yet
- Chapter 4 - Further Development and Analysis of The Classical Linear Regression ModelDocument2 pagesChapter 4 - Further Development and Analysis of The Classical Linear Regression ModelNansaa BayarNo ratings yet
- AFAR-09 (Separate & Consolidated Financial Statements)Document10 pagesAFAR-09 (Separate & Consolidated Financial Statements)Hasmin AmpatuaNo ratings yet
- Boiling and Condensation - 2Document39 pagesBoiling and Condensation - 2hasan shuvoNo ratings yet
- World Montary System, 1972Document52 pagesWorld Montary System, 1972Can UludağNo ratings yet
- Ce511 Tabinas HW01Document18 pagesCe511 Tabinas HW01Kathlyn Kit TabinasNo ratings yet
- Apr 30 23:59:59 IST 2023 Sunil Kumar Bhardwaj: 3rd Floor, No - 165 Megh Towers PH Road Maduravoyal Chennai - 600095Document1 pageApr 30 23:59:59 IST 2023 Sunil Kumar Bhardwaj: 3rd Floor, No - 165 Megh Towers PH Road Maduravoyal Chennai - 600095amanNo ratings yet
- FICS PresentationDocument13 pagesFICS PresentationShujat AliNo ratings yet
- PPM Rebuilt Unit Manual: Testing MethodDocument35 pagesPPM Rebuilt Unit Manual: Testing MethodNGUYENTHEPHAT100% (3)
- 2020 Wddty February 2020Document84 pages2020 Wddty February 2020San RajNo ratings yet
- Research Paper On Trade FacilitationDocument5 pagesResearch Paper On Trade Facilitationsgfdsvbnd100% (1)
- Limba Folktale Large FileDocument606 pagesLimba Folktale Large FileAmalia BanaşNo ratings yet
- Hardness Test: Materials Science and TestingDocument6 pagesHardness Test: Materials Science and TestingCharlyn FloresNo ratings yet
- CSP-24 02 WebDocument339 pagesCSP-24 02 WebTauqeer AbbasNo ratings yet
- Performance Appraisal: Building Trust Among Employees or Not-The Dilemma ContinuesDocument6 pagesPerformance Appraisal: Building Trust Among Employees or Not-The Dilemma ContinuesMaliha NazarNo ratings yet
- Hasegawa v. Giron, G.R. No. 184536, August 14, 2013Document6 pagesHasegawa v. Giron, G.R. No. 184536, August 14, 2013Braian HitaNo ratings yet
- +3.3Vstb For AVDDA: WWW - Fineprint.cnDocument11 pages+3.3Vstb For AVDDA: WWW - Fineprint.cnAung HeinNo ratings yet
- Chapter 2 Synchronous MachinespptDocument53 pagesChapter 2 Synchronous MachinespptraygharNo ratings yet
- Lab 1a RASPlib Installation Instructions R5 2016b-2017aDocument10 pagesLab 1a RASPlib Installation Instructions R5 2016b-2017aaleNo ratings yet
- Comaroff, John L. Rules and Rulers. Political Processes in A Tswana ChiefdownDocument21 pagesComaroff, John L. Rules and Rulers. Political Processes in A Tswana ChiefdownDiego AlbertoNo ratings yet
- DSF BoltsDocument2 pagesDSF BoltsSai SushankNo ratings yet
- Sindh Government Promotion RulesDocument41 pagesSindh Government Promotion RulesseoresercherNo ratings yet
- Disaster Management and Emergency Response Planning (DMERP-01)Document8 pagesDisaster Management and Emergency Response Planning (DMERP-01)Taimoor AhmadNo ratings yet
- Worksheet 5 CSDocument2 pagesWorksheet 5 CSPal KansaraNo ratings yet
- Influencer MarketingDocument4 pagesInfluencer MarketingVaibhav Wadhwa100% (1)
- State Variable Models: Dorf and Bishop, Modern Control SystemsDocument39 pagesState Variable Models: Dorf and Bishop, Modern Control SystemsveenadivyakishNo ratings yet
- Halfen Cast-In Channels: ConcreteDocument92 pagesHalfen Cast-In Channels: ConcreteFernando Castillo HerreraNo ratings yet
- Incessant Technologies, An NIIT Technologies Company, Becomes A Pegasystems Inc. Systems Integrator Partner (Company Update)Document2 pagesIncessant Technologies, An NIIT Technologies Company, Becomes A Pegasystems Inc. Systems Integrator Partner (Company Update)Shyam SunderNo ratings yet