
Chapter 3: Solutions To Selected Exercises
Chapter 3: Solutions To Selected Exercises
You might also like
- Google+Sheet+ExerciseDocument10 pagesGoogle+Sheet+ExerciseSubhadwip Tunga0% (1)
- AAP-20 NATO Life Cycle Model-Ekim 2015Document78 pagesAAP-20 NATO Life Cycle Model-Ekim 2015sergiobicho1960100% (1)
- Mcv4u CH 1 Nelson SolutionsDocument76 pagesMcv4u CH 1 Nelson SolutionsStephanie100% (1)
- Ninja Hacks GuideDocument96 pagesNinja Hacks GuideZsuzsi McCluskieNo ratings yet
- 2000 Deep WebsDocument23 pages2000 Deep Webscaos iepaNo ratings yet
- CE 411 ModuleDocument55 pagesCE 411 ModuleAshaduzzaman RayhanNo ratings yet
- Apple CoDocument4 pagesApple CoMunawar AliNo ratings yet
- Chapter 3: Solutions To Selected ExercisesDocument14 pagesChapter 3: Solutions To Selected ExercisesBruno SilvaNo ratings yet
- Mind Action Series Igrade 11 Paper 2 MemorandumDocument10 pagesMind Action Series Igrade 11 Paper 2 MemorandumlashefosterNo ratings yet
- Chapter 8 SurdsDocument2 pagesChapter 8 Surdsisele1977No ratings yet
- Maths Gr10 Paper2 MemoDocument12 pagesMaths Gr10 Paper2 MemombaliNo ratings yet
- Design Formula For EC2-Version 2 PDFDocument36 pagesDesign Formula For EC2-Version 2 PDFZiThiamNo ratings yet
- Design Formula For EC2-Version 2Document36 pagesDesign Formula For EC2-Version 2Anas ShamsudinNo ratings yet
- Analysis of Doubly RC-Beam RC-1Document8 pagesAnalysis of Doubly RC-Beam RC-1obsadaniel63No ratings yet
- Assignment 1 SolutionDocument11 pagesAssignment 1 SolutionKash TorabiNo ratings yet
- Grade 8 and 9 Item Banks For RevisionDocument131 pagesGrade 8 and 9 Item Banks For RevisionNhlanzeko Nhlanzeko100% (1)
- IFEM Ch02Document11 pagesIFEM Ch02Jadiel OliveiraNo ratings yet
- TSI-LIB-131Aslam Kassimali Matrix Analysis of Structure-Alvarez1Document25 pagesTSI-LIB-131Aslam Kassimali Matrix Analysis of Structure-Alvarez1Alexander Ivan Cornejo SanchezNo ratings yet
- 1D Unit 2 - Powers and PolynomialsDocument21 pages1D Unit 2 - Powers and PolynomialscallmecrzNo ratings yet
- Important Properties For Design of RC Members: Limits On DeflectionDocument4 pagesImportant Properties For Design of RC Members: Limits On DeflectionAntenehNo ratings yet
- Design Formula For EC2 Version 06 PDFDocument35 pagesDesign Formula For EC2 Version 06 PDFscegts100% (1)
- T1000 - MATHEMATICS N2 QP APR 2018 Signed OffDocument10 pagesT1000 - MATHEMATICS N2 QP APR 2018 Signed OffThobee LinahNo ratings yet
- Mathematics: Daily Practice ProblemsDocument2 pagesMathematics: Daily Practice ProblemsAkshit MaheshwariNo ratings yet
- Indices, Surds & LogarithmsDocument9 pagesIndices, Surds & Logarithmsmintchoco98No ratings yet
- Indices, Surds & LogarithmsDocument9 pagesIndices, Surds & Logarithmsmintchoco98No ratings yet
- Batch2 - Set B - CT3 Answer KeyDocument12 pagesBatch2 - Set B - CT3 Answer KeyHEMAN PRASADNo ratings yet
- EndSem SP21 CA255 QPDocument2 pagesEndSem SP21 CA255 QPrahulNo ratings yet
- Math 4am C1 21 22Document4 pagesMath 4am C1 21 22Zead kirituNo ratings yet
- Holt Algebra 1 - Chapter 05 - SAT-ACTDocument3 pagesHolt Algebra 1 - Chapter 05 - SAT-ACTStanley GuoNo ratings yet
- Table 3.1 Stress and Deformation Characteristics For ConcreteDocument1 pageTable 3.1 Stress and Deformation Characteristics For ConcreteDong-Yong KimNo ratings yet
- Matrices Worksheet 1Document4 pagesMatrices Worksheet 1siany adeNo ratings yet
- GR 10 Quiz 1Document24 pagesGR 10 Quiz 1rudyrbNo ratings yet
- Answer All Questions.: Sulit 3472/1Document16 pagesAnswer All Questions.: Sulit 3472/1azirawaniNo ratings yet
- Pse Chapter 1-Number System and EquationsDocument2 pagesPse Chapter 1-Number System and EquationsNur RafizahNo ratings yet
- EMTH202-Tutorial 1-Week 1-3-With SolutionDocument7 pagesEMTH202-Tutorial 1-Week 1-3-With SolutionOlebile Thap2No ratings yet
- Dwnload Full Linear Algebra and Its Applications 5th Edition Lay Solutions Manual PDFDocument36 pagesDwnload Full Linear Algebra and Its Applications 5th Edition Lay Solutions Manual PDFmoldwarp.collumgn81100% (10)
- Linear Algebra and Its Applications 5th Edition Lay Solutions ManualDocument36 pagesLinear Algebra and Its Applications 5th Edition Lay Solutions Manualwoollyprytheeuctw100% (28)
- Chapter 5Document19 pagesChapter 5poniteNo ratings yet
- +2 DPP 3Document2 pages+2 DPP 3arunupadhyay9317No ratings yet
- Example On Analysis of Double Reinforced-Beam Sections PDFDocument8 pagesExample On Analysis of Double Reinforced-Beam Sections PDFWendimu TolessaNo ratings yet
- Full Download PDF of Test Bank For Essential Calculus 2nd Edition: James Stewart All ChapterDocument47 pagesFull Download PDF of Test Bank For Essential Calculus 2nd Edition: James Stewart All Chapterdadamobergit62100% (2)
- ICSE Sample Papers For Class 9 Mathematics Paper 1 (2023-24)Document26 pagesICSE Sample Papers For Class 9 Mathematics Paper 1 (2023-24)bijay beheraNo ratings yet
- St. Joseph's College of Arts & Science (Autonomous) St. Joseph's College Road, Cuddalore - 607001 B.SC Degree Examination November 2021Document3 pagesSt. Joseph's College of Arts & Science (Autonomous) St. Joseph's College Road, Cuddalore - 607001 B.SC Degree Examination November 2021A19ACE11 Kundavai devi.RNo ratings yet
- CH 03Document2 pagesCH 03Enrique RodríguezNo ratings yet
- Tailored Tuitions Grade 12 Paper 2 Revision Memo 08 June 2024 by Sosibo M (078 7870 904)Document12 pagesTailored Tuitions Grade 12 Paper 2 Revision Memo 08 June 2024 by Sosibo M (078 7870 904)mngomanokwanda19No ratings yet
- ECS332 2015 Postmidterm HWDocument69 pagesECS332 2015 Postmidterm HWDeadpool 001No ratings yet
- OjobbnDocument2 pagesOjobbnKartik BhararaNo ratings yet
- Unit Test 2 Ihp PaperDocument1 pageUnit Test 2 Ihp PaperSachin PawarNo ratings yet
- PAP U8 Exponent Rules PracticeDocument2 pagesPAP U8 Exponent Rules PracticeAlly BenavidezNo ratings yet
- Maths N3Document6 pagesMaths N3Anesu MasirahaNo ratings yet
- Lab-Week5-Question and SolutionDocument13 pagesLab-Week5-Question and Solutionulageswaran.kishokumarNo ratings yet
- 01 10 23 SR IIT STAR CO SCMODEL B Jee Main CTM 5 KEY & SOLDocument18 pages01 10 23 SR IIT STAR CO SCMODEL B Jee Main CTM 5 KEY & SOLTanay1 MitraNo ratings yet
- Geometric Properties of A Parabolic Section, Dr. Victor M. Ponce and Jhonath W. Mejía G., 2021Document1 pageGeometric Properties of A Parabolic Section, Dr. Victor M. Ponce and Jhonath W. Mejía G., 2021Mmreza ShamaeiNo ratings yet
- ICSE Board Class IX Mathematics Paper 5 - Solution Time: 2 Hrs Total Marks: 80Document14 pagesICSE Board Class IX Mathematics Paper 5 - Solution Time: 2 Hrs Total Marks: 80sudhu bhina4No ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseTeacher JAY-AR LAGMANNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseNIXONNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseBretana joanNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseJane OlescoNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseAlzen Van Jyroe AranasNo ratings yet
- A Level Maths Paper 3 Exponential and Logarithmic QuizDocument4 pagesA Level Maths Paper 3 Exponential and Logarithmic QuizPatrick PhuahNo ratings yet
- Aits 2223 FT X Jeea Paper 2 SolDocument11 pagesAits 2223 FT X Jeea Paper 2 SolSuvrajyoti TaraphdarNo ratings yet
- Homework 1 SolDocument4 pagesHomework 1 SolELF7878No ratings yet
- 5 BIDMAS (With Indices)Document8 pages5 BIDMAS (With Indices)amandeep kaurNo ratings yet
- Modular Forms and Special Cycles on Shimura Curves. (AM-161)From EverandModular Forms and Special Cycles on Shimura Curves. (AM-161)No ratings yet
- Xii Physics by Anees HussainDocument66 pagesXii Physics by Anees HussainDaniya Sohail Sohail HashimNo ratings yet
- Processing Is Broken Down Into Simple Steps: Ravi Jaiswani FMA Quiz 2Document5 pagesProcessing Is Broken Down Into Simple Steps: Ravi Jaiswani FMA Quiz 2RAVI JAISWANI Student, Jaipuria IndoreNo ratings yet
- Compal La-6841p r0.1 SchematicsDocument45 pagesCompal La-6841p r0.1 Schematicskamil_yilmaz_6No ratings yet
- Crash 2022 07 24 - 23.18.18 ClientDocument7 pagesCrash 2022 07 24 - 23.18.18 ClientSebastian Torres PizañaNo ratings yet
- HP ILO3 Popular CommandsDocument4 pagesHP ILO3 Popular Commandsprince264No ratings yet
- Terminales Con Gama: Y Precios de Lista en SolesDocument34 pagesTerminales Con Gama: Y Precios de Lista en SolesbilgradoNo ratings yet
- Training Strategies I: E-LearningDocument34 pagesTraining Strategies I: E-LearningSahityaNo ratings yet
- A Machine Learning Approach For Digital WatermarkingDocument12 pagesA Machine Learning Approach For Digital Watermarkingfebaxag385No ratings yet
- IOI Training Week 7 Advanced Data Structures: 1.1 Square-Root (SQRT) DecompositionDocument6 pagesIOI Training Week 7 Advanced Data Structures: 1.1 Square-Root (SQRT) DecompositionHimanshu RanjanNo ratings yet
- Seamo Paper - E - 2021Document8 pagesSeamo Paper - E - 2021Bá Phong67% (3)
- Quectel BG96 MQTT Application Note V1.1Document32 pagesQuectel BG96 MQTT Application Note V1.1LaloNo ratings yet
- All C Programs DatabaseDocument13 pagesAll C Programs Databaseasha.py81No ratings yet
- Digital Image Processing: Lecture # 2 FundamentalsDocument41 pagesDigital Image Processing: Lecture # 2 FundamentalsAhsanNo ratings yet
- Rashid Wassan - ResumeDocument1 pageRashid Wassan - ResumeMuzafar MaharNo ratings yet
- ConfigurationDocument28 pagesConfigurationMohamed ShabanaNo ratings yet
- Shortest Path Problems: Baba Yaga-MissionDocument4 pagesShortest Path Problems: Baba Yaga-MissionSavage cgpianNo ratings yet
- 1390-PS-0011 High Speed WindObserver Manual Issue 3Document33 pages1390-PS-0011 High Speed WindObserver Manual Issue 3Wee WeeNo ratings yet
- Gmail - New Activity in Freelancer OnboardingDocument3 pagesGmail - New Activity in Freelancer OnboardingSUNIL SAININo ratings yet
- Cosc 112 Final MCQDocument3 pagesCosc 112 Final MCQAlex UchennaNo ratings yet
- Simplified Modeling of Cement Kiln PrecalcinerDocument5 pagesSimplified Modeling of Cement Kiln PrecalcinerrujunliNo ratings yet
- Judy Brady I Want A Wife EssayDocument7 pagesJudy Brady I Want A Wife Essayrlxaqgnbf100% (2)
- RFID Reader Installation MaualDocument1 pageRFID Reader Installation MaualRenato BeltránNo ratings yet
- PDF Created With Pdffactory Pro Trial VersionDocument62 pagesPDF Created With Pdffactory Pro Trial VersionMts Nu AmbitNo ratings yet
- Operations Management LectureDocument31 pagesOperations Management LectureAnjan SarkarNo ratings yet
- Baterias Narada Aplicaciones IndustrialesDocument88 pagesBaterias Narada Aplicaciones IndustrialesJose Carlos MartinezNo ratings yet





























































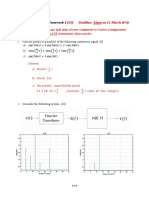



























Download as pdf or txt
You might also like
- Google+Sheet+ExerciseDocument10 pagesGoogle+Sheet+ExerciseSubhadwip Tunga0% (1)
- AAP-20 NATO Life Cycle Model-Ekim 2015Document78 pagesAAP-20 NATO Life Cycle Model-Ekim 2015sergiobicho1960100% (1)
- Mcv4u CH 1 Nelson SolutionsDocument76 pagesMcv4u CH 1 Nelson SolutionsStephanie100% (1)
- Ninja Hacks GuideDocument96 pagesNinja Hacks GuideZsuzsi McCluskieNo ratings yet
- 2000 Deep WebsDocument23 pages2000 Deep Webscaos iepaNo ratings yet
- CE 411 ModuleDocument55 pagesCE 411 ModuleAshaduzzaman RayhanNo ratings yet
- Apple CoDocument4 pagesApple CoMunawar AliNo ratings yet
- Chapter 3: Solutions To Selected ExercisesDocument14 pagesChapter 3: Solutions To Selected ExercisesBruno SilvaNo ratings yet
- Mind Action Series Igrade 11 Paper 2 MemorandumDocument10 pagesMind Action Series Igrade 11 Paper 2 MemorandumlashefosterNo ratings yet
- Chapter 8 SurdsDocument2 pagesChapter 8 Surdsisele1977No ratings yet
- Maths Gr10 Paper2 MemoDocument12 pagesMaths Gr10 Paper2 MemombaliNo ratings yet
- Design Formula For EC2-Version 2 PDFDocument36 pagesDesign Formula For EC2-Version 2 PDFZiThiamNo ratings yet
- Design Formula For EC2-Version 2Document36 pagesDesign Formula For EC2-Version 2Anas ShamsudinNo ratings yet
- Analysis of Doubly RC-Beam RC-1Document8 pagesAnalysis of Doubly RC-Beam RC-1obsadaniel63No ratings yet
- Assignment 1 SolutionDocument11 pagesAssignment 1 SolutionKash TorabiNo ratings yet
- Grade 8 and 9 Item Banks For RevisionDocument131 pagesGrade 8 and 9 Item Banks For RevisionNhlanzeko Nhlanzeko100% (1)
- IFEM Ch02Document11 pagesIFEM Ch02Jadiel OliveiraNo ratings yet
- TSI-LIB-131Aslam Kassimali Matrix Analysis of Structure-Alvarez1Document25 pagesTSI-LIB-131Aslam Kassimali Matrix Analysis of Structure-Alvarez1Alexander Ivan Cornejo SanchezNo ratings yet
- 1D Unit 2 - Powers and PolynomialsDocument21 pages1D Unit 2 - Powers and PolynomialscallmecrzNo ratings yet
- Important Properties For Design of RC Members: Limits On DeflectionDocument4 pagesImportant Properties For Design of RC Members: Limits On DeflectionAntenehNo ratings yet
- Design Formula For EC2 Version 06 PDFDocument35 pagesDesign Formula For EC2 Version 06 PDFscegts100% (1)
- T1000 - MATHEMATICS N2 QP APR 2018 Signed OffDocument10 pagesT1000 - MATHEMATICS N2 QP APR 2018 Signed OffThobee LinahNo ratings yet
- Mathematics: Daily Practice ProblemsDocument2 pagesMathematics: Daily Practice ProblemsAkshit MaheshwariNo ratings yet
- Indices, Surds & LogarithmsDocument9 pagesIndices, Surds & Logarithmsmintchoco98No ratings yet
- Indices, Surds & LogarithmsDocument9 pagesIndices, Surds & Logarithmsmintchoco98No ratings yet
- Batch2 - Set B - CT3 Answer KeyDocument12 pagesBatch2 - Set B - CT3 Answer KeyHEMAN PRASADNo ratings yet
- EndSem SP21 CA255 QPDocument2 pagesEndSem SP21 CA255 QPrahulNo ratings yet
- Math 4am C1 21 22Document4 pagesMath 4am C1 21 22Zead kirituNo ratings yet
- Holt Algebra 1 - Chapter 05 - SAT-ACTDocument3 pagesHolt Algebra 1 - Chapter 05 - SAT-ACTStanley GuoNo ratings yet
- Table 3.1 Stress and Deformation Characteristics For ConcreteDocument1 pageTable 3.1 Stress and Deformation Characteristics For ConcreteDong-Yong KimNo ratings yet
- Matrices Worksheet 1Document4 pagesMatrices Worksheet 1siany adeNo ratings yet
- GR 10 Quiz 1Document24 pagesGR 10 Quiz 1rudyrbNo ratings yet
- Answer All Questions.: Sulit 3472/1Document16 pagesAnswer All Questions.: Sulit 3472/1azirawaniNo ratings yet
- Pse Chapter 1-Number System and EquationsDocument2 pagesPse Chapter 1-Number System and EquationsNur RafizahNo ratings yet
- EMTH202-Tutorial 1-Week 1-3-With SolutionDocument7 pagesEMTH202-Tutorial 1-Week 1-3-With SolutionOlebile Thap2No ratings yet
- Dwnload Full Linear Algebra and Its Applications 5th Edition Lay Solutions Manual PDFDocument36 pagesDwnload Full Linear Algebra and Its Applications 5th Edition Lay Solutions Manual PDFmoldwarp.collumgn81100% (10)
- Linear Algebra and Its Applications 5th Edition Lay Solutions ManualDocument36 pagesLinear Algebra and Its Applications 5th Edition Lay Solutions Manualwoollyprytheeuctw100% (28)
- Chapter 5Document19 pagesChapter 5poniteNo ratings yet
- +2 DPP 3Document2 pages+2 DPP 3arunupadhyay9317No ratings yet
- Example On Analysis of Double Reinforced-Beam Sections PDFDocument8 pagesExample On Analysis of Double Reinforced-Beam Sections PDFWendimu TolessaNo ratings yet
- Full Download PDF of Test Bank For Essential Calculus 2nd Edition: James Stewart All ChapterDocument47 pagesFull Download PDF of Test Bank For Essential Calculus 2nd Edition: James Stewart All Chapterdadamobergit62100% (2)
- ICSE Sample Papers For Class 9 Mathematics Paper 1 (2023-24)Document26 pagesICSE Sample Papers For Class 9 Mathematics Paper 1 (2023-24)bijay beheraNo ratings yet
- St. Joseph's College of Arts & Science (Autonomous) St. Joseph's College Road, Cuddalore - 607001 B.SC Degree Examination November 2021Document3 pagesSt. Joseph's College of Arts & Science (Autonomous) St. Joseph's College Road, Cuddalore - 607001 B.SC Degree Examination November 2021A19ACE11 Kundavai devi.RNo ratings yet
- CH 03Document2 pagesCH 03Enrique RodríguezNo ratings yet
- Tailored Tuitions Grade 12 Paper 2 Revision Memo 08 June 2024 by Sosibo M (078 7870 904)Document12 pagesTailored Tuitions Grade 12 Paper 2 Revision Memo 08 June 2024 by Sosibo M (078 7870 904)mngomanokwanda19No ratings yet
- ECS332 2015 Postmidterm HWDocument69 pagesECS332 2015 Postmidterm HWDeadpool 001No ratings yet
- OjobbnDocument2 pagesOjobbnKartik BhararaNo ratings yet
- Unit Test 2 Ihp PaperDocument1 pageUnit Test 2 Ihp PaperSachin PawarNo ratings yet
- PAP U8 Exponent Rules PracticeDocument2 pagesPAP U8 Exponent Rules PracticeAlly BenavidezNo ratings yet
- Maths N3Document6 pagesMaths N3Anesu MasirahaNo ratings yet
- Lab-Week5-Question and SolutionDocument13 pagesLab-Week5-Question and Solutionulageswaran.kishokumarNo ratings yet
- 01 10 23 SR IIT STAR CO SCMODEL B Jee Main CTM 5 KEY & SOLDocument18 pages01 10 23 SR IIT STAR CO SCMODEL B Jee Main CTM 5 KEY & SOLTanay1 MitraNo ratings yet
- Geometric Properties of A Parabolic Section, Dr. Victor M. Ponce and Jhonath W. Mejía G., 2021Document1 pageGeometric Properties of A Parabolic Section, Dr. Victor M. Ponce and Jhonath W. Mejía G., 2021Mmreza ShamaeiNo ratings yet
- ICSE Board Class IX Mathematics Paper 5 - Solution Time: 2 Hrs Total Marks: 80Document14 pagesICSE Board Class IX Mathematics Paper 5 - Solution Time: 2 Hrs Total Marks: 80sudhu bhina4No ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseTeacher JAY-AR LAGMANNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseNIXONNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseBretana joanNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseJane OlescoNo ratings yet
- Laws of Exponents Student UseDocument19 pagesLaws of Exponents Student UseAlzen Van Jyroe AranasNo ratings yet
- A Level Maths Paper 3 Exponential and Logarithmic QuizDocument4 pagesA Level Maths Paper 3 Exponential and Logarithmic QuizPatrick PhuahNo ratings yet
- Aits 2223 FT X Jeea Paper 2 SolDocument11 pagesAits 2223 FT X Jeea Paper 2 SolSuvrajyoti TaraphdarNo ratings yet
- Homework 1 SolDocument4 pagesHomework 1 SolELF7878No ratings yet
- 5 BIDMAS (With Indices)Document8 pages5 BIDMAS (With Indices)amandeep kaurNo ratings yet
- Modular Forms and Special Cycles on Shimura Curves. (AM-161)From EverandModular Forms and Special Cycles on Shimura Curves. (AM-161)No ratings yet
- Xii Physics by Anees HussainDocument66 pagesXii Physics by Anees HussainDaniya Sohail Sohail HashimNo ratings yet
- Processing Is Broken Down Into Simple Steps: Ravi Jaiswani FMA Quiz 2Document5 pagesProcessing Is Broken Down Into Simple Steps: Ravi Jaiswani FMA Quiz 2RAVI JAISWANI Student, Jaipuria IndoreNo ratings yet
- Compal La-6841p r0.1 SchematicsDocument45 pagesCompal La-6841p r0.1 Schematicskamil_yilmaz_6No ratings yet
- Crash 2022 07 24 - 23.18.18 ClientDocument7 pagesCrash 2022 07 24 - 23.18.18 ClientSebastian Torres PizañaNo ratings yet
- HP ILO3 Popular CommandsDocument4 pagesHP ILO3 Popular Commandsprince264No ratings yet
- Terminales Con Gama: Y Precios de Lista en SolesDocument34 pagesTerminales Con Gama: Y Precios de Lista en SolesbilgradoNo ratings yet
- Training Strategies I: E-LearningDocument34 pagesTraining Strategies I: E-LearningSahityaNo ratings yet
- A Machine Learning Approach For Digital WatermarkingDocument12 pagesA Machine Learning Approach For Digital Watermarkingfebaxag385No ratings yet
- IOI Training Week 7 Advanced Data Structures: 1.1 Square-Root (SQRT) DecompositionDocument6 pagesIOI Training Week 7 Advanced Data Structures: 1.1 Square-Root (SQRT) DecompositionHimanshu RanjanNo ratings yet
- Seamo Paper - E - 2021Document8 pagesSeamo Paper - E - 2021Bá Phong67% (3)
- Quectel BG96 MQTT Application Note V1.1Document32 pagesQuectel BG96 MQTT Application Note V1.1LaloNo ratings yet
- All C Programs DatabaseDocument13 pagesAll C Programs Databaseasha.py81No ratings yet
- Digital Image Processing: Lecture # 2 FundamentalsDocument41 pagesDigital Image Processing: Lecture # 2 FundamentalsAhsanNo ratings yet
- Rashid Wassan - ResumeDocument1 pageRashid Wassan - ResumeMuzafar MaharNo ratings yet
- ConfigurationDocument28 pagesConfigurationMohamed ShabanaNo ratings yet
- Shortest Path Problems: Baba Yaga-MissionDocument4 pagesShortest Path Problems: Baba Yaga-MissionSavage cgpianNo ratings yet
- 1390-PS-0011 High Speed WindObserver Manual Issue 3Document33 pages1390-PS-0011 High Speed WindObserver Manual Issue 3Wee WeeNo ratings yet
- Gmail - New Activity in Freelancer OnboardingDocument3 pagesGmail - New Activity in Freelancer OnboardingSUNIL SAININo ratings yet
- Cosc 112 Final MCQDocument3 pagesCosc 112 Final MCQAlex UchennaNo ratings yet
- Simplified Modeling of Cement Kiln PrecalcinerDocument5 pagesSimplified Modeling of Cement Kiln PrecalcinerrujunliNo ratings yet
- Judy Brady I Want A Wife EssayDocument7 pagesJudy Brady I Want A Wife Essayrlxaqgnbf100% (2)
- RFID Reader Installation MaualDocument1 pageRFID Reader Installation MaualRenato BeltránNo ratings yet
- PDF Created With Pdffactory Pro Trial VersionDocument62 pagesPDF Created With Pdffactory Pro Trial VersionMts Nu AmbitNo ratings yet
- Operations Management LectureDocument31 pagesOperations Management LectureAnjan SarkarNo ratings yet
- Baterias Narada Aplicaciones IndustrialesDocument88 pagesBaterias Narada Aplicaciones IndustrialesJose Carlos MartinezNo ratings yet