Download as pdf or txt
You might also like
- Api Reference Guide PDFDocument440 pagesApi Reference Guide PDFDeVazo OnomaNo ratings yet
- Dice Rolling Simulator - Jagrit SahniDocument31 pagesDice Rolling Simulator - Jagrit SahniDimple Verma50% (2)
- INSTRUCCIONES V7.3 2017s English SpanishDocument15 pagesINSTRUCCIONES V7.3 2017s English Spanishjfernand81No ratings yet
- Project On Library ManagementDocument40 pagesProject On Library ManagementManoj KumarNo ratings yet
- Expt#4 - Quadrature Phase Shift KeyingDocument5 pagesExpt#4 - Quadrature Phase Shift KeyingElaiza M. PontriasNo ratings yet
- An Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsDocument6 pagesAn Area-Efficient 2-D Convolution Implementation On FPGA For Space ApplicationsCường Dương QuốcNo ratings yet
- FinFET - The Promises and The ChallengesDocument5 pagesFinFET - The Promises and The ChallengesprakashroutNo ratings yet
- Ultra-Low Overhead Dynamic Watermarking On Scan Design For Hard IP ProtectionDocument16 pagesUltra-Low Overhead Dynamic Watermarking On Scan Design For Hard IP Protectionpsathishkumar1232544No ratings yet
- Free and Open Source Software Codes For Antenna Design: Preliminary Numerical ExperimentsDocument8 pagesFree and Open Source Software Codes For Antenna Design: Preliminary Numerical ExperimentsJuan David CarrilloNo ratings yet
- Additive Manufacturing by Digital Light ProcessingDocument30 pagesAdditive Manufacturing by Digital Light ProcessingtrusilpolaraNo ratings yet
- Signal Processing: Image Communication: B. Krill, A. Ahmad, A. Amira, H. RabahDocument11 pagesSignal Processing: Image Communication: B. Krill, A. Ahmad, A. Amira, H. RabahŢoca CosminNo ratings yet
- An FPGA-Based Fully Synchronized Design of ADocument12 pagesAn FPGA-Based Fully Synchronized Design of AJoshua DuffyNo ratings yet
- An Overview of Ongoing Point Cloud Compression Standardization Activities Video Based V PCC and Geometry Based G PCCDocument17 pagesAn Overview of Ongoing Point Cloud Compression Standardization Activities Video Based V PCC and Geometry Based G PCCVNK90No ratings yet
- Approximative Signed Wallace Tree Multiplier Using Reversible LogicDocument7 pagesApproximative Signed Wallace Tree Multiplier Using Reversible LogicIJRASETPublicationsNo ratings yet
- Approximative Signed Wallace Tree Multiplier Using Reversible LogicDocument7 pagesApproximative Signed Wallace Tree Multiplier Using Reversible LogicIJRASETPublicationsNo ratings yet
- FPGA Implementation For Fractal Quadtree Image CompressionDocument5 pagesFPGA Implementation For Fractal Quadtree Image Compressionkanimozhi rajasekarenNo ratings yet
- Techno Economic Analysisof Inhouse Cablingfor FTTHDocument5 pagesTechno Economic Analysisof Inhouse Cablingfor FTTHnavneetnayanNo ratings yet
- Additive Manufacturing by Digital Light Processing: A ReviewDocument21 pagesAdditive Manufacturing by Digital Light Processing: A Reviewlayla.adham94No ratings yet
- Designing A G2 Structure Using Python With Graphical User InterfaceDocument9 pagesDesigning A G2 Structure Using Python With Graphical User InterfaceRajani TogarsiNo ratings yet
- System Design: Traditional Concepts and New ParadigmsDocument12 pagesSystem Design: Traditional Concepts and New ParadigmsArun MohanarajNo ratings yet
- Session Multi-Level Project Work A Study in Collaboration: Mats Daniels and Lars AsplundDocument3 pagesSession Multi-Level Project Work A Study in Collaboration: Mats Daniels and Lars Asplundvinc_palNo ratings yet
- Theory For Different Modulation PDFDocument8 pagesTheory For Different Modulation PDFKartik KulkarniNo ratings yet
- Nios 2Document57 pagesNios 2Rohit PradhanNo ratings yet
- An Open-Source Toolkit For Digital Image CorrelationDocument6 pagesAn Open-Source Toolkit For Digital Image Correlation17860528116No ratings yet
- Designing A G+2 Structure Using Python With Graphical User InterfaceDocument9 pagesDesigning A G+2 Structure Using Python With Graphical User InterfaceRajani TogarsiNo ratings yet
- FPGA Based Area Efficient Edge Detection Filter For Image Processing ApplicationsDocument4 pagesFPGA Based Area Efficient Edge Detection Filter For Image Processing ApplicationsAnoop KumarNo ratings yet
- Electronics 10 01495 v2Document13 pagesElectronics 10 01495 v2rsspacenerd23No ratings yet
- An Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAsDocument14 pagesAn Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAspalansamyNo ratings yet
- Eficient Integration of TSDF in Mobile Devices 2023Document10 pagesEficient Integration of TSDF in Mobile Devices 2023jomamuregNo ratings yet
- Car ParkingDocument65 pagesCar Parkingmaniblp100% (1)
- $R6BV4HTDocument10 pages$R6BV4HTrohit pratiushNo ratings yet
- The Practical Experience of Implementing A GSM BTSDocument6 pagesThe Practical Experience of Implementing A GSM BTSCamilo RestrepoNo ratings yet
- Dept. of Ece, Sreebuddha College of Engineering 1Document34 pagesDept. of Ece, Sreebuddha College of Engineering 1SARATH MOHANDASNo ratings yet
- Final Paper Yogatama TirtaDocument10 pagesFinal Paper Yogatama TirtaVidyaParamasivamNo ratings yet
- An Implementation of Convolutional Neural NetworksDocument23 pagesAn Implementation of Convolutional Neural NetworksRishima SardaNo ratings yet
- The JEDI Event-Based Infrastructure and Its ApplicDocument55 pagesThe JEDI Event-Based Infrastructure and Its ApplicRSX SNo ratings yet
- Dynamic Web Services On A Home Service PlatformDocument9 pagesDynamic Web Services On A Home Service PlatformRamasudhakarreddy MedapatiNo ratings yet
- FPGA Design of A Fast 32-Bit Floating PointDocument3 pagesFPGA Design of A Fast 32-Bit Floating PointNguyễn CườngNo ratings yet
- Design Issues in Heterogeneous 3D 2.5D IntegrationDocument8 pagesDesign Issues in Heterogeneous 3D 2.5D IntegrationMadapathiNo ratings yet
- Implementation of Rotation and Vectoring-Mode Reconfigurable CORDICDocument9 pagesImplementation of Rotation and Vectoring-Mode Reconfigurable CORDICEditor IJTSRDNo ratings yet
- 3400302.3415767Document7 pages3400302.3415767jianhuazhang916No ratings yet
- 2017 Salazar Com AidedDocument11 pages2017 Salazar Com AidedChalang AkramNo ratings yet
- Applications of Nanofabrication TechnologiesDocument26 pagesApplications of Nanofabrication TechnologiesNikhil SinghNo ratings yet
- Optimization of Single-Stage FFT Architectures Using Multiple Constant MultiplicationDocument8 pagesOptimization of Single-Stage FFT Architectures Using Multiple Constant MultiplicationCanalDTodoUnPoco PCNo ratings yet
- Algorithm and Architecture Optimization For 2D DisDocument17 pagesAlgorithm and Architecture Optimization For 2D DisMr GrachNo ratings yet
- Power Area FILTERSDocument8 pagesPower Area FILTERSRasigan UrNo ratings yet
- Design and Implementation of Novel Multiplier UsinDocument8 pagesDesign and Implementation of Novel Multiplier Usinananyagv263No ratings yet
- Applications of Fuzzy Logic in Image Processing - A Brief StudyDocument5 pagesApplications of Fuzzy Logic in Image Processing - A Brief StudyCompusoft JournalsNo ratings yet
- EEQ 2022 000954 v1 402336Document22 pagesEEQ 2022 000954 v1 402336Thiruvenkadam KNo ratings yet
- FPGA Implementation of LTE Physical Downlink Control Channel Under MIMO TechniqueDocument8 pagesFPGA Implementation of LTE Physical Downlink Control Channel Under MIMO Techniquekevints05No ratings yet
- Short Tech Description-2nd-OC FinalDocument20 pagesShort Tech Description-2nd-OC FinalazanacaroluisNo ratings yet
- FPGA-SoC Implementation of YOLOv4 For Flying-Object DetectionDocument20 pagesFPGA-SoC Implementation of YOLOv4 For Flying-Object DetectionKhaled IsmailNo ratings yet
- Cluster-Based Evolutionary Design of Digital CircuDocument9 pagesCluster-Based Evolutionary Design of Digital CircuMuntser MohNo ratings yet
- Multiple FPGAs Based Prototyping and Debugging With Complete Design FlowDocument7 pagesMultiple FPGAs Based Prototyping and Debugging With Complete Design FlowKhaled IsmailNo ratings yet
- Fast Modular Multipliers For SupersingularDocument13 pagesFast Modular Multipliers For SupersingularTRIAD TECHNO SERVICESNo ratings yet
- Plug-and-Play Solutions For Energy-Efficiency Deep Renovation of European Building StockDocument5 pagesPlug-and-Play Solutions For Energy-Efficiency Deep Renovation of European Building StockGiang LamNo ratings yet
- Stmicro Mcu Pfe 2012xDocument15 pagesStmicro Mcu Pfe 2012xkbma2009No ratings yet
- New Trends in Image and Video CompressionDocument7 pagesNew Trends in Image and Video CompressionSrinivasan JeganNo ratings yet
- Design, Implementation, and Evaluation of An XG-PON Module For The ns-3 Network SimulatorDocument16 pagesDesign, Implementation, and Evaluation of An XG-PON Module For The ns-3 Network SimulatorTú HoàngNo ratings yet
- A Novel FDTD Approach Considering Frequency Dispersion of FR-4 Substrates For Signal Transmission Analyses at GHZ Band PDFDocument11 pagesA Novel FDTD Approach Considering Frequency Dispersion of FR-4 Substrates For Signal Transmission Analyses at GHZ Band PDFsandrotmgNo ratings yet
- Campus Area Network Project Report PDFDocument116 pagesCampus Area Network Project Report PDFJay SarkarNo ratings yet
- Multi-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignFrom EverandMulti-Platform Graphics Programming with Kivy: Basic Analytical Programming for 2D, 3D, and Stereoscopic DesignNo ratings yet
- User Manual Furuno 701 901Document22 pagesUser Manual Furuno 701 901Nedjeljko PlazonićNo ratings yet
- Evolution of CdmaDocument4 pagesEvolution of CdmamonumunduriNo ratings yet
- Il Piccolo Yeti (2019) (BluRay Rip 1080p ITA DD+AC3 SUBS) (M@HD)Document5 pagesIl Piccolo Yeti (2019) (BluRay Rip 1080p ITA DD+AC3 SUBS) (M@HD)dddNo ratings yet
- SwitchingDocument20 pagesSwitchinglimenihNo ratings yet
- Ruggedcom RM1224 DatasheetDocument6 pagesRuggedcom RM1224 DatasheetAstrid Marin PalaciosNo ratings yet
- Dune HD Ultra Vision 4KDocument9 pagesDune HD Ultra Vision 4KWojciech BukowskiNo ratings yet
- QuickSilver Controls QCI-DS030 QCI-X23Document12 pagesQuickSilver Controls QCI-DS030 QCI-X23ElectromateNo ratings yet
- HP RDX Continuous Data Protection Software Product SheetDocument2 pagesHP RDX Continuous Data Protection Software Product Sheetchauhans_100No ratings yet
- Vip HostDocument4 pagesVip HostAndy Ahmad67% (3)
- Strategies For Network Administration in Oracle Solaris 11.4Document32 pagesStrategies For Network Administration in Oracle Solaris 11.4errr33No ratings yet
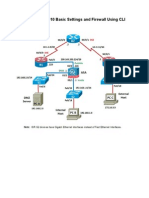
- Configuring ASA 5510 Basic Settings and Firewall Using CLIDocument18 pagesConfiguring ASA 5510 Basic Settings and Firewall Using CLIIrfee75% (8)
- Dev ListDocument5 pagesDev ListMt GrNo ratings yet
- BSR 2000 - Release 1.1 - SNMP Configuration and Management GuideDocument62 pagesBSR 2000 - Release 1.1 - SNMP Configuration and Management GuideToti ÚrNo ratings yet
- PL-100 DemoDocument19 pagesPL-100 Demosanju939No ratings yet
- Quanta ZU1Document39 pagesQuanta ZU1RayminusNo ratings yet
- Architecture of TMS320C54XX Digital Signal ProcessorsDocument20 pagesArchitecture of TMS320C54XX Digital Signal ProcessorsLydia Elezabeth Alappat100% (8)
- Cisco 7600 Redundancy High Availability Configuration GuideDocument113 pagesCisco 7600 Redundancy High Availability Configuration GuideJames OmaraNo ratings yet
- Nutanix Certified Professional - Multicloud Infrastructure (NCP-MCI)Document3 pagesNutanix Certified Professional - Multicloud Infrastructure (NCP-MCI)Маријан СтанићNo ratings yet
- Win Link 1000 - User ManualDocument96 pagesWin Link 1000 - User Manual12345612346No ratings yet
- 07 Indoor CameraDocument5 pages07 Indoor CameraalamgeerkNo ratings yet
- Ruijie XS-S1960-H Series Switches Datasheet 2019.11.19Document7 pagesRuijie XS-S1960-H Series Switches Datasheet 2019.11.19Wisnu tamaNo ratings yet
- Egate-2000 MNDocument326 pagesEgate-2000 MNprajeeshckNo ratings yet
- Agent Not Assigned in Task Which Is Configured in WE20 - Post Processing - Permitted Agent Tab - SAP Support - Get Help From Our ExpertsDocument4 pagesAgent Not Assigned in Task Which Is Configured in WE20 - Post Processing - Permitted Agent Tab - SAP Support - Get Help From Our ExpertsnoidsonlyNo ratings yet
- Dis Sys ArchitecturesDocument55 pagesDis Sys ArchitecturesArmend JashariNo ratings yet
- Homework 8 (C++)Document5 pagesHomework 8 (C++)hughng92No ratings yet
- DDR4 BasicsDocument12 pagesDDR4 BasicsAnh Viet NguyenNo ratings yet