
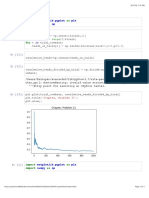
Assignment 3 - Building A Custom Visualization
Assignment 3 - Building A Custom Visualization
You might also like
- Data Mining - Business Report: Clustering Clean - AdsDocument24 pagesData Mining - Business Report: Clustering Clean - AdsKetan Sawalkar100% (4)
- Appendix D Scope of Work PipelineDocument43 pagesAppendix D Scope of Work PipelineAnonymous xh8IDaKzT100% (8)
- Solutions To II Unit Exercises From KamberDocument16 pagesSolutions To II Unit Exercises From Kamberjyothibellaryv83% (42)
- My Study Plan Guide For AmcDocument7 pagesMy Study Plan Guide For Amc0d&H 8No ratings yet
- Baldur's Gate - MapsDocument58 pagesBaldur's Gate - MapsLaurent GorseNo ratings yet
- Assignment ClusteringDocument22 pagesAssignment ClusteringNetra RainaNo ratings yet
- Assignment 2Document6 pagesAssignment 2Tiger YanNo ratings yet
- LRD Overload Relay - Tripping CurveDocument1 pageLRD Overload Relay - Tripping CurvemasoudNo ratings yet
- Skid Steer Loader SafetyDocument44 pagesSkid Steer Loader Safetytagliya100% (3)
- Final PPT of Carbon NanotubesDocument29 pagesFinal PPT of Carbon Nanotubesmkumar_5481467% (3)
- Be A 65 Ads Exp 2Document10 pagesBe A 65 Ads Exp 2Ritika dwivediNo ratings yet
- R Unit 4th and 5thDocument17 pagesR Unit 4th and 5thArshad BegNo ratings yet
- Linear Regression - Jupyter NotebookDocument56 pagesLinear Regression - Jupyter NotebookUjwal Vajranabhaiah100% (3)
- Lab 3 - Exploratory Data Analysis - 261119 QDocument16 pagesLab 3 - Exploratory Data Analysis - 261119 QJoker JrNo ratings yet
- Stsci4060 HW5Document9 pagesStsci4060 HW5Lei HuangNo ratings yet
- Aakash S Project ReportDocument12 pagesAakash S Project ReportVivekNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- GokulDocument10 pagesGokulcomputerg00007No ratings yet
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHANo ratings yet
- Data Mining - ProjectDocument25 pagesData Mining - ProjectAbhishek Arya100% (1)
- Image Editor SpecDocument8 pagesImage Editor SpecAbc XyzNo ratings yet
- Assignment 1 AIDocument6 pagesAssignment 1 AIRaj AryanNo ratings yet
- DWDM - Lab Manual1Document40 pagesDWDM - Lab Manual1aathyukthas.ai20001No ratings yet
- Exercise 7 Submission Group 12Document22 pagesExercise 7 Submission Group 12Mehmet YalçınNo ratings yet
- Secene Image SegmentationDocument30 pagesSecene Image SegmentationRasool ReddyNo ratings yet
- Engo 645Document9 pagesEngo 645sree vishnupriyqNo ratings yet
- Chandigarh Group of Colleges College of Engineering Landran, MohaliDocument47 pagesChandigarh Group of Colleges College of Engineering Landran, Mohalitanvi wadhwaNo ratings yet
- Chapter 3Document51 pagesChapter 3Ingle AshwiniNo ratings yet
- Lecture Notes - Linear RegressionDocument26 pagesLecture Notes - Linear RegressionAmandeep Kaur GahirNo ratings yet
- Revised Clustering Business ReportDocument5 pagesRevised Clustering Business ReportPratigya pathakNo ratings yet
- Linear RegressionDocument46 pagesLinear RegressionRajkiran PatilNo ratings yet
- EDA - Exploratory Data AnalysisDocument16 pagesEDA - Exploratory Data Analysisspraga1995No ratings yet
- Day 20 - NumpyDocument6 pagesDay 20 - NumpyBasic Programming knowledgeNo ratings yet
- 41 Perusse Alexander Aperusse PDFDocument7 pages41 Perusse Alexander Aperusse PDFAnurita MathurNo ratings yet
- Regression Linaire Python Tome IDocument9 pagesRegression Linaire Python Tome IElisée TEGUENo ratings yet
- Chapter 3 - DESCRIPTIVE ANALYSISDocument28 pagesChapter 3 - DESCRIPTIVE ANALYSISSimer FibersNo ratings yet
- Dar Unit-4Document23 pagesDar Unit-4Kalyan VarmaNo ratings yet
- Maxbox - Starter68 Machine LearningDocument5 pagesMaxbox - Starter68 Machine LearningMax KleinerNo ratings yet
- Consensus Cluster PlusDocument12 pagesConsensus Cluster PlusAndré ChristianesNo ratings yet
- Declaration:: MGNM801 Business Analytics-IDocument12 pagesDeclaration:: MGNM801 Business Analytics-Iakash hossainNo ratings yet
- 1 - Linear - Regression - Ipynb - ColaboratoryDocument7 pages1 - Linear - Regression - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Fds AnswersDocument53 pagesFds AnswerssaranyatvcetNo ratings yet
- Dimensional Reduction in RDocument24 pagesDimensional Reduction in RShil ShambharkarNo ratings yet
- Gradient Descent AlgorithmDocument5 pagesGradient Descent AlgorithmravinyseNo ratings yet
- 202003271604164717neeraj Jain Graphical RepresentationDocument12 pages202003271604164717neeraj Jain Graphical RepresentationSRIYANSH RAINo ratings yet
- EDA Lab ManualDocument93 pagesEDA Lab ManualYash Rox100% (2)
- data_analysis2Document16 pagesdata_analysis2rohit972012No ratings yet
- Zerox ReadyDocument21 pagesZerox Readygowrishankar nayanaNo ratings yet
- Augmentation and SegmentationDocument32 pagesAugmentation and SegmentationTanmay SahuNo ratings yet
- AD3411 - 1 To 5Document11 pagesAD3411 - 1 To 5Raj kamalNo ratings yet
- PHYS 356/452/953 - Medical Imaging Physics Lab Assignment 5Document6 pagesPHYS 356/452/953 - Medical Imaging Physics Lab Assignment 5nirakaNo ratings yet
- Tutorial NNDocument20 pagesTutorial NN黄琦妮No ratings yet
- Image ClassificationDocument18 pagesImage ClassificationDarshna GuptaNo ratings yet
- Datamining ReportDocument37 pagesDatamining ReportPranav ViswanathanNo ratings yet
- Figure Style and Scale: Darkgrid Whitegrid Dark White Ticks DarkgridDocument15 pagesFigure Style and Scale: Darkgrid Whitegrid Dark White Ticks DarkgridmaaottoniNo ratings yet
- Machine Learning-1Document24 pagesMachine Learning-1factpolice007No ratings yet
- Data AnalysisDocument8 pagesData AnalysisTayar ElieNo ratings yet
- Descriptive Statistics With Pandas: Data Handling Using Pandas - IIDocument37 pagesDescriptive Statistics With Pandas: Data Handling Using Pandas - IIB. Jennifer100% (1)
- Unit V Data VisualizationDocument49 pagesUnit V Data VisualizationnirmalampNo ratings yet
- BES - R LabDocument5 pagesBES - R LabViem AnhNo ratings yet
- Visual Data Insights Using Sas Ods Graphics A Guide To Communication Effective Data Visualization 1St Edition Leroy Bessler 2 All ChapterDocument68 pagesVisual Data Insights Using Sas Ods Graphics A Guide To Communication Effective Data Visualization 1St Edition Leroy Bessler 2 All Chapterbryan.nevill936100% (6)
- PYDS 3150713 Unit-4Document59 pagesPYDS 3150713 Unit-4Hetvy JadejaNo ratings yet
- DATA MINING Project ReportDocument28 pagesDATA MINING Project ReportAbhishek AbhiNo ratings yet
- Matplotlib Introduction ToDocument11 pagesMatplotlib Introduction Topriyanka sharma100% (1)
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- Histogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionFrom EverandHistogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionNo ratings yet
- Math Stats HW1Document2 pagesMath Stats HW1Tiger YanNo ratings yet
- 2 5 9 PDFDocument1 page2 5 9 PDFTiger YanNo ratings yet
- Mar 23-Mar 25 Selves As Immaterial SoulsDocument3 pagesMar 23-Mar 25 Selves As Immaterial SoulsTiger YanNo ratings yet
- Mar 30-April 1. Kripke On PhysicalismDocument2 pagesMar 30-April 1. Kripke On PhysicalismTiger YanNo ratings yet
- 4:21 Kant Third AntinomyDocument4 pages4:21 Kant Third AntinomyTiger YanNo ratings yet
- 3:26 Kant 2nd AnalogyDocument4 pages3:26 Kant 2nd AnalogyTiger YanNo ratings yet
- 4:14 Kant First AntinomyDocument4 pages4:14 Kant First AntinomyTiger YanNo ratings yet
- Fortune Is Unpredictable and MutableDocument4 pagesFortune Is Unpredictable and MutablenucleaNo ratings yet
- PST PlotDocument100 pagesPST PlotClaudiaNo ratings yet
- Design of 200m3 TankDocument4 pagesDesign of 200m3 TankMiko AbiNo ratings yet
- EXIBIT A - Property Inspection ChecklistDocument3 pagesEXIBIT A - Property Inspection ChecklistMaia CastañedaNo ratings yet
- Chapter 2: The Answer To The Age Ol' Question!Document44 pagesChapter 2: The Answer To The Age Ol' Question!mahadiNo ratings yet
- Steel Bar:: Basically Mild Steel BarsDocument7 pagesSteel Bar:: Basically Mild Steel BarsEdu PlatformNo ratings yet
- Behavioral Neuroscience of Motivation: Eleanor H. Simpson Peter D. Balsam EditorsDocument584 pagesBehavioral Neuroscience of Motivation: Eleanor H. Simpson Peter D. Balsam EditorsKyle penzes100% (1)
- Ch. 25 Body Defence MechanismsDocument34 pagesCh. 25 Body Defence Mechanisms吴昊No ratings yet
- PLC HardwareDocument17 pagesPLC HardwareAnonymous bppsPj8AGNo ratings yet
- New Science of Heaven - by David Barnes - Trailing The Clouds of GloryDocument27 pagesNew Science of Heaven - by David Barnes - Trailing The Clouds of GloryMazz MilesNo ratings yet
- Health Declaration FormDocument1 pageHealth Declaration FormCyberpoint Internet Cafe and Computer ShopNo ratings yet
- Water Level Controller Using 8051 Circuit PrincipleDocument4 pagesWater Level Controller Using 8051 Circuit PrincipleLappi SchematicsNo ratings yet
- John Aebercrombie Concepts For Jazz Guitar Improvisation AbmajGmDocument3 pagesJohn Aebercrombie Concepts For Jazz Guitar Improvisation AbmajGmIsrael CevallosNo ratings yet
- State of The Geothermal Resources in Bolivia Laguna Colorada ProjectDocument6 pagesState of The Geothermal Resources in Bolivia Laguna Colorada ProjectLuis Rolando SirpaNo ratings yet
- How To Do Busbar Inspection and Maintenance On ShipsDocument4 pagesHow To Do Busbar Inspection and Maintenance On ShipsibnuharyNo ratings yet
- Lymphedema Classification, Diagnosis, TherapyDocument12 pagesLymphedema Classification, Diagnosis, Therapymaevy dwiNo ratings yet
- Report Radiation Exchange Between SurfacesDocument52 pagesReport Radiation Exchange Between SurfacesStephen TabiarNo ratings yet
- Y3-English Skills HeccDocument98 pagesY3-English Skills HeccIraguha FaustinNo ratings yet
- Third Periodical Test in English 5.Document7 pagesThird Periodical Test in English 5.Emil Nayad ZamoraNo ratings yet
- VolcanoesDocument14 pagesVolcanoesSHANNEL ANN VILLUGANo ratings yet
- Lecture 1 - Map and Directions - 19492161 - 2023 - 07 - 15 - 04 - 47Document47 pagesLecture 1 - Map and Directions - 19492161 - 2023 - 07 - 15 - 04 - 47Rajbala SharmaNo ratings yet
- Additive ManufacturingDocument48 pagesAdditive ManufacturingSrinivasaReddyM100% (1)
- Measurement LabDocument4 pagesMeasurement LabHenessa GumiranNo ratings yet
- BCD 16206 e Nu 545 500Document1 pageBCD 16206 e Nu 545 500Rajeesh P RaviNo ratings yet
































































































Download as pdf or txt
You might also like
- Data Mining - Business Report: Clustering Clean - AdsDocument24 pagesData Mining - Business Report: Clustering Clean - AdsKetan Sawalkar100% (4)
- Appendix D Scope of Work PipelineDocument43 pagesAppendix D Scope of Work PipelineAnonymous xh8IDaKzT100% (8)
- Solutions To II Unit Exercises From KamberDocument16 pagesSolutions To II Unit Exercises From Kamberjyothibellaryv83% (42)
- My Study Plan Guide For AmcDocument7 pagesMy Study Plan Guide For Amc0d&H 8No ratings yet
- Baldur's Gate - MapsDocument58 pagesBaldur's Gate - MapsLaurent GorseNo ratings yet
- Assignment ClusteringDocument22 pagesAssignment ClusteringNetra RainaNo ratings yet
- Assignment 2Document6 pagesAssignment 2Tiger YanNo ratings yet
- LRD Overload Relay - Tripping CurveDocument1 pageLRD Overload Relay - Tripping CurvemasoudNo ratings yet
- Skid Steer Loader SafetyDocument44 pagesSkid Steer Loader Safetytagliya100% (3)
- Final PPT of Carbon NanotubesDocument29 pagesFinal PPT of Carbon Nanotubesmkumar_5481467% (3)
- Be A 65 Ads Exp 2Document10 pagesBe A 65 Ads Exp 2Ritika dwivediNo ratings yet
- R Unit 4th and 5thDocument17 pagesR Unit 4th and 5thArshad BegNo ratings yet
- Linear Regression - Jupyter NotebookDocument56 pagesLinear Regression - Jupyter NotebookUjwal Vajranabhaiah100% (3)
- Lab 3 - Exploratory Data Analysis - 261119 QDocument16 pagesLab 3 - Exploratory Data Analysis - 261119 QJoker JrNo ratings yet
- Stsci4060 HW5Document9 pagesStsci4060 HW5Lei HuangNo ratings yet
- Aakash S Project ReportDocument12 pagesAakash S Project ReportVivekNo ratings yet
- ML Practical FileDocument43 pagesML Practical FilePankaj Singh100% (1)
- GokulDocument10 pagesGokulcomputerg00007No ratings yet
- Principal Component Analysis Notes : InfoDocument22 pagesPrincipal Component Analysis Notes : InfoVALMICK GUHANo ratings yet
- Data Mining - ProjectDocument25 pagesData Mining - ProjectAbhishek Arya100% (1)
- Image Editor SpecDocument8 pagesImage Editor SpecAbc XyzNo ratings yet
- Assignment 1 AIDocument6 pagesAssignment 1 AIRaj AryanNo ratings yet
- DWDM - Lab Manual1Document40 pagesDWDM - Lab Manual1aathyukthas.ai20001No ratings yet
- Exercise 7 Submission Group 12Document22 pagesExercise 7 Submission Group 12Mehmet YalçınNo ratings yet
- Secene Image SegmentationDocument30 pagesSecene Image SegmentationRasool ReddyNo ratings yet
- Engo 645Document9 pagesEngo 645sree vishnupriyqNo ratings yet
- Chandigarh Group of Colleges College of Engineering Landran, MohaliDocument47 pagesChandigarh Group of Colleges College of Engineering Landran, Mohalitanvi wadhwaNo ratings yet
- Chapter 3Document51 pagesChapter 3Ingle AshwiniNo ratings yet
- Lecture Notes - Linear RegressionDocument26 pagesLecture Notes - Linear RegressionAmandeep Kaur GahirNo ratings yet
- Revised Clustering Business ReportDocument5 pagesRevised Clustering Business ReportPratigya pathakNo ratings yet
- Linear RegressionDocument46 pagesLinear RegressionRajkiran PatilNo ratings yet
- EDA - Exploratory Data AnalysisDocument16 pagesEDA - Exploratory Data Analysisspraga1995No ratings yet
- Day 20 - NumpyDocument6 pagesDay 20 - NumpyBasic Programming knowledgeNo ratings yet
- 41 Perusse Alexander Aperusse PDFDocument7 pages41 Perusse Alexander Aperusse PDFAnurita MathurNo ratings yet
- Regression Linaire Python Tome IDocument9 pagesRegression Linaire Python Tome IElisée TEGUENo ratings yet
- Chapter 3 - DESCRIPTIVE ANALYSISDocument28 pagesChapter 3 - DESCRIPTIVE ANALYSISSimer FibersNo ratings yet
- Dar Unit-4Document23 pagesDar Unit-4Kalyan VarmaNo ratings yet
- Maxbox - Starter68 Machine LearningDocument5 pagesMaxbox - Starter68 Machine LearningMax KleinerNo ratings yet
- Consensus Cluster PlusDocument12 pagesConsensus Cluster PlusAndré ChristianesNo ratings yet
- Declaration:: MGNM801 Business Analytics-IDocument12 pagesDeclaration:: MGNM801 Business Analytics-Iakash hossainNo ratings yet
- 1 - Linear - Regression - Ipynb - ColaboratoryDocument7 pages1 - Linear - Regression - Ipynb - Colaboratoryduryodhan sahooNo ratings yet
- Fds AnswersDocument53 pagesFds AnswerssaranyatvcetNo ratings yet
- Dimensional Reduction in RDocument24 pagesDimensional Reduction in RShil ShambharkarNo ratings yet
- Gradient Descent AlgorithmDocument5 pagesGradient Descent AlgorithmravinyseNo ratings yet
- 202003271604164717neeraj Jain Graphical RepresentationDocument12 pages202003271604164717neeraj Jain Graphical RepresentationSRIYANSH RAINo ratings yet
- EDA Lab ManualDocument93 pagesEDA Lab ManualYash Rox100% (2)
- data_analysis2Document16 pagesdata_analysis2rohit972012No ratings yet
- Zerox ReadyDocument21 pagesZerox Readygowrishankar nayanaNo ratings yet
- Augmentation and SegmentationDocument32 pagesAugmentation and SegmentationTanmay SahuNo ratings yet
- AD3411 - 1 To 5Document11 pagesAD3411 - 1 To 5Raj kamalNo ratings yet
- PHYS 356/452/953 - Medical Imaging Physics Lab Assignment 5Document6 pagesPHYS 356/452/953 - Medical Imaging Physics Lab Assignment 5nirakaNo ratings yet
- Tutorial NNDocument20 pagesTutorial NN黄琦妮No ratings yet
- Image ClassificationDocument18 pagesImage ClassificationDarshna GuptaNo ratings yet
- Datamining ReportDocument37 pagesDatamining ReportPranav ViswanathanNo ratings yet
- Figure Style and Scale: Darkgrid Whitegrid Dark White Ticks DarkgridDocument15 pagesFigure Style and Scale: Darkgrid Whitegrid Dark White Ticks DarkgridmaaottoniNo ratings yet
- Machine Learning-1Document24 pagesMachine Learning-1factpolice007No ratings yet
- Data AnalysisDocument8 pagesData AnalysisTayar ElieNo ratings yet
- Descriptive Statistics With Pandas: Data Handling Using Pandas - IIDocument37 pagesDescriptive Statistics With Pandas: Data Handling Using Pandas - IIB. Jennifer100% (1)
- Unit V Data VisualizationDocument49 pagesUnit V Data VisualizationnirmalampNo ratings yet
- BES - R LabDocument5 pagesBES - R LabViem AnhNo ratings yet
- Visual Data Insights Using Sas Ods Graphics A Guide To Communication Effective Data Visualization 1St Edition Leroy Bessler 2 All ChapterDocument68 pagesVisual Data Insights Using Sas Ods Graphics A Guide To Communication Effective Data Visualization 1St Edition Leroy Bessler 2 All Chapterbryan.nevill936100% (6)
- PYDS 3150713 Unit-4Document59 pagesPYDS 3150713 Unit-4Hetvy JadejaNo ratings yet
- DATA MINING Project ReportDocument28 pagesDATA MINING Project ReportAbhishek AbhiNo ratings yet
- Matplotlib Introduction ToDocument11 pagesMatplotlib Introduction Topriyanka sharma100% (1)
- AIDS - DM Using Python - Lab ProgramsDocument19 pagesAIDS - DM Using Python - Lab ProgramsyelubandirenukavidyadhariNo ratings yet
- Histogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionFrom EverandHistogram Equalization: Enhancing Image Contrast for Enhanced Visual PerceptionNo ratings yet
- Math Stats HW1Document2 pagesMath Stats HW1Tiger YanNo ratings yet
- 2 5 9 PDFDocument1 page2 5 9 PDFTiger YanNo ratings yet
- Mar 23-Mar 25 Selves As Immaterial SoulsDocument3 pagesMar 23-Mar 25 Selves As Immaterial SoulsTiger YanNo ratings yet
- Mar 30-April 1. Kripke On PhysicalismDocument2 pagesMar 30-April 1. Kripke On PhysicalismTiger YanNo ratings yet
- 4:21 Kant Third AntinomyDocument4 pages4:21 Kant Third AntinomyTiger YanNo ratings yet
- 3:26 Kant 2nd AnalogyDocument4 pages3:26 Kant 2nd AnalogyTiger YanNo ratings yet
- 4:14 Kant First AntinomyDocument4 pages4:14 Kant First AntinomyTiger YanNo ratings yet
- Fortune Is Unpredictable and MutableDocument4 pagesFortune Is Unpredictable and MutablenucleaNo ratings yet
- PST PlotDocument100 pagesPST PlotClaudiaNo ratings yet
- Design of 200m3 TankDocument4 pagesDesign of 200m3 TankMiko AbiNo ratings yet
- EXIBIT A - Property Inspection ChecklistDocument3 pagesEXIBIT A - Property Inspection ChecklistMaia CastañedaNo ratings yet
- Chapter 2: The Answer To The Age Ol' Question!Document44 pagesChapter 2: The Answer To The Age Ol' Question!mahadiNo ratings yet
- Steel Bar:: Basically Mild Steel BarsDocument7 pagesSteel Bar:: Basically Mild Steel BarsEdu PlatformNo ratings yet
- Behavioral Neuroscience of Motivation: Eleanor H. Simpson Peter D. Balsam EditorsDocument584 pagesBehavioral Neuroscience of Motivation: Eleanor H. Simpson Peter D. Balsam EditorsKyle penzes100% (1)
- Ch. 25 Body Defence MechanismsDocument34 pagesCh. 25 Body Defence Mechanisms吴昊No ratings yet
- PLC HardwareDocument17 pagesPLC HardwareAnonymous bppsPj8AGNo ratings yet
- New Science of Heaven - by David Barnes - Trailing The Clouds of GloryDocument27 pagesNew Science of Heaven - by David Barnes - Trailing The Clouds of GloryMazz MilesNo ratings yet
- Health Declaration FormDocument1 pageHealth Declaration FormCyberpoint Internet Cafe and Computer ShopNo ratings yet
- Water Level Controller Using 8051 Circuit PrincipleDocument4 pagesWater Level Controller Using 8051 Circuit PrincipleLappi SchematicsNo ratings yet
- John Aebercrombie Concepts For Jazz Guitar Improvisation AbmajGmDocument3 pagesJohn Aebercrombie Concepts For Jazz Guitar Improvisation AbmajGmIsrael CevallosNo ratings yet
- State of The Geothermal Resources in Bolivia Laguna Colorada ProjectDocument6 pagesState of The Geothermal Resources in Bolivia Laguna Colorada ProjectLuis Rolando SirpaNo ratings yet
- How To Do Busbar Inspection and Maintenance On ShipsDocument4 pagesHow To Do Busbar Inspection and Maintenance On ShipsibnuharyNo ratings yet
- Lymphedema Classification, Diagnosis, TherapyDocument12 pagesLymphedema Classification, Diagnosis, Therapymaevy dwiNo ratings yet
- Report Radiation Exchange Between SurfacesDocument52 pagesReport Radiation Exchange Between SurfacesStephen TabiarNo ratings yet
- Y3-English Skills HeccDocument98 pagesY3-English Skills HeccIraguha FaustinNo ratings yet
- Third Periodical Test in English 5.Document7 pagesThird Periodical Test in English 5.Emil Nayad ZamoraNo ratings yet
- VolcanoesDocument14 pagesVolcanoesSHANNEL ANN VILLUGANo ratings yet
- Lecture 1 - Map and Directions - 19492161 - 2023 - 07 - 15 - 04 - 47Document47 pagesLecture 1 - Map and Directions - 19492161 - 2023 - 07 - 15 - 04 - 47Rajbala SharmaNo ratings yet
- Additive ManufacturingDocument48 pagesAdditive ManufacturingSrinivasaReddyM100% (1)
- Measurement LabDocument4 pagesMeasurement LabHenessa GumiranNo ratings yet
- BCD 16206 e Nu 545 500Document1 pageBCD 16206 e Nu 545 500Rajeesh P RaviNo ratings yet