Download as pdf or txt
You might also like
- Personal Knowledge Graphs: Connected thinking to boost productivity, creativity and discoveryFrom EverandPersonal Knowledge Graphs: Connected thinking to boost productivity, creativity and discoveryNo ratings yet
- Digital Tools For Qualitative ResearchDocument28 pagesDigital Tools For Qualitative ResearchMarini Budiarti100% (2)
- Data Fluency: Empowering Your Organization with Effective Data CommunicationFrom EverandData Fluency: Empowering Your Organization with Effective Data CommunicationRating: 2 out of 5 stars2/5 (5)
- Crime File Management SystemDocument17 pagesCrime File Management SystemSunil Singh100% (1)
- Information Visualization Chaomei ChenDocument17 pagesInformation Visualization Chaomei ChenMécia SáNo ratings yet
- Module - 1 - Introduction To Business Analytics - Communicating With DataDocument87 pagesModule - 1 - Introduction To Business Analytics - Communicating With DataSumedhaChauhanNo ratings yet
- Enrico Caldarola BigGrafs DBpediaDocument8 pagesEnrico Caldarola BigGrafs DBpediaFati DahNo ratings yet
- Digital Data Analysis and ManagementDocument23 pagesDigital Data Analysis and ManagementGow BeveragesNo ratings yet
- Changing Minds To Changing The World: Mapping The Spectrum of Intent in Data Visualization and Data ArtsDocument30 pagesChanging Minds To Changing The World: Mapping The Spectrum of Intent in Data Visualization and Data Artssmarttelgroup1No ratings yet
- Where Data Meets DesignDocument15 pagesWhere Data Meets DesignAimée KnightNo ratings yet
- What Questions Reveal About Novices' Attempts To Make Sense of Data Visualizations: Patterns and MisconceptionsDocument11 pagesWhat Questions Reveal About Novices' Attempts To Make Sense of Data Visualizations: Patterns and MisconceptionsMarcus Vinicius GonçalvesNo ratings yet
- ELI7052Document2 pagesELI7052O'Brien's PubNo ratings yet
- Zaphiris Et Al. - 2004 - Exploring The Use of Information Visualization For Digital Libraries - New Review of Information NetworkingDocument20 pagesZaphiris Et Al. - 2004 - Exploring The Use of Information Visualization For Digital Libraries - New Review of Information NetworkingPanayiotis ZaphirisNo ratings yet
- 2018 The Concept of Data in Digital Research The-Sage-Handbook-Of-Qualitative-Data-Collection - I2921Document9 pages2018 The Concept of Data in Digital Research The-Sage-Handbook-Of-Qualitative-Data-Collection - I2921Camilo OsejoNo ratings yet
- NewPaper DataVisualizationDocument7 pagesNewPaper DataVisualizationKim MonzonNo ratings yet
- AHDS-Why Bother With Digitisation PDFDocument7 pagesAHDS-Why Bother With Digitisation PDFSebaMastropieroNo ratings yet
- Usage of Visualization Techniques in Data Science Workflows: Johanna SchmidtDocument8 pagesUsage of Visualization Techniques in Data Science Workflows: Johanna SchmidtSabavath SwathiNo ratings yet
- Finalversion QualitativedatadisplayDocument24 pagesFinalversion QualitativedatadisplayDwi 1703No ratings yet
- Ridley Evaluatingdatavisualization 2020Document15 pagesRidley Evaluatingdatavisualization 2020sharmaprateek2005No ratings yet
- Impact of Data Visualization On Management DecisionsDocument12 pagesImpact of Data Visualization On Management DecisionsDouglas GodoyNo ratings yet
- Pre PrintDocument36 pagesPre PrintDouglas GodoyNo ratings yet
- Data Visualization A Guide To Visual Storytelling For LibrariesDocument293 pagesData Visualization A Guide To Visual Storytelling For LibrariesPhong Nguyen100% (2)
- Data Mining To Discovery of KnowledgeDocument5 pagesData Mining To Discovery of KnowledgeIJRASETPublicationsNo ratings yet
- Week 4 Analyzing and Visualizing Data Andy KirkDocument3 pagesWeek 4 Analyzing and Visualizing Data Andy KirkElisha KemboiNo ratings yet
- Fe 550Document4 pagesFe 550SpdSudheerNo ratings yet
- Why Data Storytelling Is Your New Superpower - Data Storytelling CornerDocument11 pagesWhy Data Storytelling Is Your New Superpower - Data Storytelling CornertataxpNo ratings yet
- DEW 2019: Data Exploration in The Web 3.0 AgeDocument2 pagesDEW 2019: Data Exploration in The Web 3.0 Ageعلي الاريابيNo ratings yet
- Infographics IntroductionDocument25 pagesInfographics IntroductionJenniferFerreira100% (5)
- 04 InteractionDocument28 pages04 Interactionismailia ayuzraNo ratings yet
- Infogr8 Trend Report Spring 2015Document33 pagesInfogr8 Trend Report Spring 2015Aji AjaNo ratings yet
- What Is Visualization?Document23 pagesWhat Is Visualization?choloNo ratings yet
- Data Visualization - Data MiningDocument11 pagesData Visualization - Data Miningzhiarabas31No ratings yet
- What Is Data Visualization - Definition & Examples - Tableau - NotesDocument10 pagesWhat Is Data Visualization - Definition & Examples - Tableau - NotesRaj Narayan MishraNo ratings yet
- 2010 - A Wodehouse, Information Use in Conceptual Design, Existing Taxonomies and New Approaches - International Journal of DesignDocument13 pages2010 - A Wodehouse, Information Use in Conceptual Design, Existing Taxonomies and New Approaches - International Journal of Designis03lcmNo ratings yet
- The Art and Science of Data Visualization - by Michael Mahoney - Towards Data ScienceDocument75 pagesThe Art and Science of Data Visualization - by Michael Mahoney - Towards Data ScienceNanda KumarNo ratings yet
- Visualization 2010 Lev ManovichDocument23 pagesVisualization 2010 Lev ManovichLuciana MoherdauiNo ratings yet
- Data VisualisationDocument20 pagesData Visualisationdoraemon80100% (2)
- SummariesDocument20 pagesSummariesFizza ShahidNo ratings yet
- Article Guidelines For Designing Information VisualizationDocument7 pagesArticle Guidelines For Designing Information VisualizationBoban CelebicNo ratings yet
- Introduction To Data VisualisationDocument47 pagesIntroduction To Data VisualisationAdil Bin Khalid100% (1)
- Data Visualization: Methods, Types, Benefits, and Checklist: March 2019Document10 pagesData Visualization: Methods, Types, Benefits, and Checklist: March 2019ecs71No ratings yet
- Empowerment TechnologyDocument24 pagesEmpowerment Technologysol therese cairelNo ratings yet
- Norvig Et Al - 2023 - More Than Just AlgorithmsDocument9 pagesNorvig Et Al - 2023 - More Than Just AlgorithmsdcpalaciNo ratings yet
- Corti 2016Document13 pagesCorti 2016IHNo ratings yet
- ING Improving Outcomes With Qualitative Data Analysis Software MAXQDA 12 - Oswald (2019)Document7 pagesING Improving Outcomes With Qualitative Data Analysis Software MAXQDA 12 - Oswald (2019)raphaestcgNo ratings yet
- 1 s2.0 S2590118422000272 MainDocument15 pages1 s2.0 S2590118422000272 MainxxxNo ratings yet
- Challenges in Visual Data AnalysisDocument6 pagesChallenges in Visual Data AnalysisjmauricioezNo ratings yet
- Data Visualization1Document5 pagesData Visualization1JelinNo ratings yet
- Manovich Visualization 2010Document28 pagesManovich Visualization 2010Angela MaielloNo ratings yet
- Jansen ViewingDocument8 pagesJansen Viewingcebila9115No ratings yet
- New Perspectives On DigitalizationDocument138 pagesNew Perspectives On DigitalizationUdayan DasguptaNo ratings yet
- Comprehensive Review of Data Visualization Techniques Using PythonDocument7 pagesComprehensive Review of Data Visualization Techniques Using PythonTanwee H ShankarNo ratings yet
- Visualizations of User Data in A Social Media Enhanced Web-Based Environment in Higher EducationDocument8 pagesVisualizations of User Data in A Social Media Enhanced Web-Based Environment in Higher EducationBia Bezerra de MenesesNo ratings yet
- 7 SchritteDocument2 pages7 SchritteAndreas HavemannNo ratings yet
- Unsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaDocument11 pagesUnsupervised by Any Other Name - Hidden Layers of Knowledge Production in Artificial Intelligence On Social MediaJames WilsonNo ratings yet
- PendahuluanDocument11 pagesPendahuluanhadji supriyadiNo ratings yet
- Kar Big DataDocument10 pagesKar Big DataPranav NijhawanNo ratings yet
- Chapter 2Document13 pagesChapter 2Shible SheikhNo ratings yet
- Data Viz ToolsDocument6 pagesData Viz Toolsouaatoufatima2No ratings yet
- Makers of the Environment: Building Resilience Into Our World, One Model at a Time.From EverandMakers of the Environment: Building Resilience Into Our World, One Model at a Time.No ratings yet
- How to be Clear and Compelling with Data: Principles, Practice and Getting Beyond the BasicsFrom EverandHow to be Clear and Compelling with Data: Principles, Practice and Getting Beyond the BasicsNo ratings yet
- Document Management SystemDocument28 pagesDocument Management SystemJake Tamayo100% (1)
- Sublime Text Power UserDocument202 pagesSublime Text Power UserGeorgeProimakisNo ratings yet
- Lesson Plan - WebDocument3 pagesLesson Plan - WebAbinaya87No ratings yet
- CSS - OverviewDocument5 pagesCSS - OverviewRakotoarison Louis FrederickNo ratings yet
- JavascriptDocument53 pagesJavascriptGaurika PopliNo ratings yet
- XML inDocument19 pagesXML inSanhith ChowdaryNo ratings yet
- Alyssa Dyck's PortfolioDocument11 pagesAlyssa Dyck's PortfolioAlyssa DyckNo ratings yet
- Lab Manual: Channabasaveshwara Institute of TechnologyDocument46 pagesLab Manual: Channabasaveshwara Institute of TechnologyAnonymous 0OpvwCLNo ratings yet
- XMetaL Author Enterprise User's GuideDocument182 pagesXMetaL Author Enterprise User's GuidebcmonzaiNo ratings yet
- Creating HTML Reports in Windows PowerShell PDFDocument26 pagesCreating HTML Reports in Windows PowerShell PDFtrojan89100% (1)
- Unit: Designing and Developing A Website Assignment Title: Rambling Autumn 2020Document5 pagesUnit: Designing and Developing A Website Assignment Title: Rambling Autumn 2020FatsaniNo ratings yet
- Mastering PhoneGap Mobile Application Development - Sample ChapterDocument46 pagesMastering PhoneGap Mobile Application Development - Sample ChapterPackt PublishingNo ratings yet
- Web Accessibility GuideDocument22 pagesWeb Accessibility Guidebloodymary816071No ratings yet
- The CSS For The Gloss Pop-Up Fisierul Popup Salvation FolderDocument3 pagesThe CSS For The Gloss Pop-Up Fisierul Popup Salvation FolderkarpopNo ratings yet
- Css Menu and Hexa ColorsDocument43 pagesCss Menu and Hexa Colorsalpha joy tinazaNo ratings yet
- Website Design and Styling Independent AssignmentDocument2 pagesWebsite Design and Styling Independent AssignmentSeven YoshisNo ratings yet
- Joomla! V 1 5 Template Installation Troubleshooting ManualDocument4 pagesJoomla! V 1 5 Template Installation Troubleshooting ManualAmyStephen100% (25)
- Bca 1to6 2016 Su PDFDocument82 pagesBca 1to6 2016 Su PDFSmartNo ratings yet
- Collapse BootstrapDocument7 pagesCollapse BootstrapJose AngelNo ratings yet
- 30 CSS SelectorsDocument11 pages30 CSS SelectorspauldupuisNo ratings yet
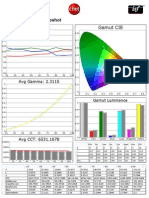
- Panasonic TC-P50ST30 CNET Review Calibration ResultsDocument7 pagesPanasonic TC-P50ST30 CNET Review Calibration ResultsDavid KatzmaierNo ratings yet
- CIS 690 - Implementation Project Proposal: Palaniappan Ramanathan Department of Computing & Information SciencesDocument3 pagesCIS 690 - Implementation Project Proposal: Palaniappan Ramanathan Department of Computing & Information SciencesTarun VBRSITNo ratings yet
- Banner Student Self-Service User Guide 8.7Document550 pagesBanner Student Self-Service User Guide 8.7Ronald MariottiNo ratings yet
- R Color SheetDocument2 pagesR Color SheetArturo CoronaNo ratings yet
- Design & Development of Website For DIT: A Project Report OnDocument65 pagesDesign & Development of Website For DIT: A Project Report OnavnishNo ratings yet
- Revell Conversion Color ChartDocument2 pagesRevell Conversion Color ChartDražen HorvatNo ratings yet
- Katagori Product Base & Colourant Base Tinting MowilexDocument6 pagesKatagori Product Base & Colourant Base Tinting MowilexwindaelNo ratings yet
- OA ComponentDocument266 pagesOA ComponentkarthicknarayanNo ratings yet
- PHP - LAB - Course PlanDocument13 pagesPHP - LAB - Course PlankhatNo ratings yet