Download as pdf or txt
You might also like
- Manual e Stufa Sara Auto Constructor EsDocument15 pagesManual e Stufa Sara Auto Constructor EsDamián Follino80% (5)
- Matrix Algebra and Random VectorsDocument37 pagesMatrix Algebra and Random VectorsJonathan HuNo ratings yet
- Limits AlgebraicallyDocument6 pagesLimits AlgebraicallyImad H. HalasahNo ratings yet
- Chapter 5 IntegrationDocument57 pagesChapter 5 IntegrationThomas GuoNo ratings yet
- Practice Final Exam - SolutionsDocument8 pagesPractice Final Exam - SolutionsNALUGOODHA MUSANo ratings yet
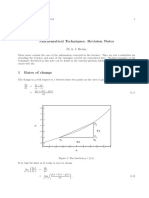
- Mathematical Techniques: Revision Notes: DR A. J. BevanDocument11 pagesMathematical Techniques: Revision Notes: DR A. J. BevanRoy VeseyNo ratings yet
- Differential CalculusDocument3 pagesDifferential CalculusIvy Joy UbinaNo ratings yet
- Infinite Series: X X X X X X X .Document28 pagesInfinite Series: X X X X X X X .CristianAbelNo ratings yet
- Blake Farman: B A N 0 1 2 N 1 NDocument11 pagesBlake Farman: B A N 0 1 2 N 1 NMatthew SimeonNo ratings yet
- Mathematics SummaryDocument7 pagesMathematics SummaryMoses KabeteNo ratings yet
- 1653 List 10 AnswersDocument5 pages1653 List 10 Answerscs17plNo ratings yet
- Notes On Implicit DifferentiationDocument4 pagesNotes On Implicit Differentiationhw0870410No ratings yet
- Math 106: Review For Exam II - SOLUTIONS: Udv Uv Vdu Uv DX Uv U VDXDocument6 pagesMath 106: Review For Exam II - SOLUTIONS: Udv Uv Vdu Uv DX Uv U VDXsakNo ratings yet
- Multiple Linear ReegressionDocument21 pagesMultiple Linear ReegressionTawhid Uddin AlviNo ratings yet
- 331 Notes MatrixDocument15 pages331 Notes MatrixSharifullah ShamimNo ratings yet
- Test LaTeXDocument3 pagesTest LaTeXmynameislickyNo ratings yet
- Multivariate Statistical Methods: Abiyot Negash (Assi. Prof)Document28 pagesMultivariate Statistical Methods: Abiyot Negash (Assi. Prof)Tolesa F BegnaNo ratings yet
- Gram MatrixDocument16 pagesGram MatrixbobbyjeddNo ratings yet
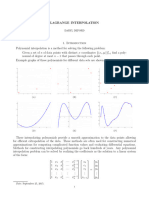
- Lagrange InterpolationDocument3 pagesLagrange InterpolationMacloud KamulaNo ratings yet
- 3-Graph 0Document7 pages3-Graph 0CSP EDUNo ratings yet
- 2.3 Derivatives of Exponential and Logarithmic FunctionsDocument7 pages2.3 Derivatives of Exponential and Logarithmic Functionsexplorers.beamaepetracortaNo ratings yet
- Mathsfull BookDocument3 pagesMathsfull Bookpunjabcollegekwl5800No ratings yet
- F17XB2 2014-15 Class Test Mathematics For Engineers and Scientists 2 Attempt All Questions (B)Document2 pagesF17XB2 2014-15 Class Test Mathematics For Engineers and Scientists 2 Attempt All Questions (B)BuyuNo ratings yet
- 2019 8N DifferentiationDocument12 pages2019 8N DifferentiationmitoNo ratings yet
- 8.2 Table of Derivatives: D y D X !Document2 pages8.2 Table of Derivatives: D y D X !Sahil GouthamNo ratings yet
- Calculus FormulaDocument2 pagesCalculus FormulaGeramagliquiangNo ratings yet
- MTH4100 Calculus I: Lecture Notes For Week 6 Thomas' Calculus, Sections 3.5 To 4.1 Except 3.7Document12 pagesMTH4100 Calculus I: Lecture Notes For Week 6 Thomas' Calculus, Sections 3.5 To 4.1 Except 3.7Roy VeseyNo ratings yet
- EE C222/ME C237 - Spring'18 - Lecture 3 Notes: Murat Arcak January 24 2018Document5 pagesEE C222/ME C237 - Spring'18 - Lecture 3 Notes: Murat Arcak January 24 2018SBNo ratings yet
- MathsDocument2 pagesMathssatyasravanthNo ratings yet
- Ma1103 3RDWDocument11 pagesMa1103 3RDWDanur WendaNo ratings yet
- ExampleDocument3 pagesExampleNguyễn Phi Anh KhôiNo ratings yet
- L20. IntegrationDocument18 pagesL20. IntegrationHoàng PhongNo ratings yet
- Math 001+Document10 pagesMath 001+Dali LinNo ratings yet
- Week 8 Fourier SeriesDocument11 pagesWeek 8 Fourier SeriesLuqman NHNo ratings yet
- Ssce 1793 Test 1 201420152Document4 pagesSsce 1793 Test 1 201420152Gantan Etika MurtyNo ratings yet
- Test 1 Ssce1693 2122 01 Utmspace-11.12.2021Document4 pagesTest 1 Ssce1693 2122 01 Utmspace-11.12.2021Wan Abdul HadiNo ratings yet
- C 06 Anti DifferentiationDocument31 pagesC 06 Anti Differentiationebrahimipour1360No ratings yet
- Elements of H2 A Level MathDocument13 pagesElements of H2 A Level MathnicNo ratings yet
- Answer All Questions in This Section. F (X) X, X 1 X 1), X 1Document3 pagesAnswer All Questions in This Section. F (X) X, X 1 X 1), X 1Catherine LowNo ratings yet
- W-13 Solving The Linear Equation Systems by Iteration MethodDocument24 pagesW-13 Solving The Linear Equation Systems by Iteration Methodumuhuza salomonNo ratings yet
- 033 SurbhiGole A1Document18 pages033 SurbhiGole A1Surbhi GoleNo ratings yet
- AGE 212: Mathematics Iii: Luanar 2014/2015 Academic Year Lecturer: Wellam KamthunziDocument139 pagesAGE 212: Mathematics Iii: Luanar 2014/2015 Academic Year Lecturer: Wellam KamthunziDonald NgalawaNo ratings yet
- Topic 5Document2 pagesTopic 5Syed Abdul Mussaver ShahNo ratings yet
- Lab 2015Document4 pagesLab 2015emonster22000No ratings yet
- Lecture Note 2 PDFDocument29 pagesLecture Note 2 PDFFrendick LegaspiNo ratings yet
- Q3W5 Lesson Differentiability and Continuity and Rules of DifferentiationDocument65 pagesQ3W5 Lesson Differentiability and Continuity and Rules of DifferentiationDannyelle SorredaNo ratings yet
- 03 - Chain Rule With Inverse TrigDocument2 pages03 - Chain Rule With Inverse Trigski3013No ratings yet
- 03 - Chain Rule With Inverse TrigDocument2 pages03 - Chain Rule With Inverse TrigkerningerNo ratings yet
- 03 - Chain Rule With Inverse Trig PDFDocument2 pages03 - Chain Rule With Inverse Trig PDFAlakaNo ratings yet
- 03 - Chain Rule With Inverse TrigDocument2 pages03 - Chain Rule With Inverse TrigJaywarven Leuterio GonzalesNo ratings yet
- Solutions: MATH 214-2 - Fall 2001 - Final Exam (Solutions)Document11 pagesSolutions: MATH 214-2 - Fall 2001 - Final Exam (Solutions)Patrick ManzanzaNo ratings yet
- M1 +Review+of+Mathematical+FoundationsDocument4 pagesM1 +Review+of+Mathematical+FoundationsKpop HarteuNo ratings yet
- DF FormulaeDocument7 pagesDF FormulaeBentojaNo ratings yet
- Written Homework 4 Solutions: Section 3.4Document3 pagesWritten Homework 4 Solutions: Section 3.4Faisi GikianNo ratings yet
- Lec9 3Document7 pagesLec9 3manoj reddyNo ratings yet
- Lecture 2Document15 pagesLecture 2Abdur Rehman KharalNo ratings yet
- Paper Maths Maron 1Document3 pagesPaper Maths Maron 1Rajat KaliaNo ratings yet
- 1st Half 2nd y MathDocument3 pages1st Half 2nd y Maththe.scholars.girls.schoolNo ratings yet
- 1 2 2 Cos X: Integrals of Piecewise Defined Functions & Use ofDocument2 pages1 2 2 Cos X: Integrals of Piecewise Defined Functions & Use ofRahulNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Factoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)From EverandFactoring and Algebra - A Selection of Classic Mathematical Articles Containing Examples and Exercises on the Subject of Algebra (Mathematics Series)No ratings yet
- Instructions To Bidders For Painting Services For Onshore FacilitiesDocument17 pagesInstructions To Bidders For Painting Services For Onshore FacilitiesjaslinNo ratings yet
- Polar ARRAY: Ar-Hbone Ar-Parq1 ClayDocument1 pagePolar ARRAY: Ar-Hbone Ar-Parq1 ClayjaslinNo ratings yet
- Edu Cadd: Details of Plummer BlockDocument1 pageEdu Cadd: Details of Plummer BlockjaslinNo ratings yet
- 11 PDFDocument1 page11 PDFjaslinNo ratings yet
- Design CalculationDocument56 pagesDesign Calculationjaslin100% (2)
- All Edges Are 5: Rectangular ARRAYDocument1 pageAll Edges Are 5: Rectangular ARRAYjaslinNo ratings yet
- Please Follow These Steps To Upgrade Your SystemDocument3 pagesPlease Follow These Steps To Upgrade Your SystemphanisanyNo ratings yet
- Moody's Report 2005Document52 pagesMoody's Report 2005as111320034667No ratings yet
- IR400 Data SheetDocument2 pagesIR400 Data Sheetdarkchess76No ratings yet
- GPT Au480Document1 pageGPT Au480xuanhungyteNo ratings yet
- Mann-1999-Marine Mammal ScienceDocument21 pagesMann-1999-Marine Mammal ScienceLUCAS GARCIA MARTINSNo ratings yet
- Low Power Blood Pressure Meter Demonstration - Microchip Technology Inc - PDFDocument3 pagesLow Power Blood Pressure Meter Demonstration - Microchip Technology Inc - PDFRene Gonzales Vasquez100% (1)
- Pirouette ManualDocument506 pagesPirouette ManualBeatrizCamposNo ratings yet
- Pirates InesDocument17 pagesPirates Inesdjelaibia2789No ratings yet
- STS-3 6KTL-P Datasheet ENDocument2 pagesSTS-3 6KTL-P Datasheet ENSIKANDER KHANNo ratings yet
- Arstruct Reviewer Compilation (GRP 7)Document9 pagesArstruct Reviewer Compilation (GRP 7)Nicole FrancisNo ratings yet
- Hochiki DIALux - The Basics PDFDocument18 pagesHochiki DIALux - The Basics PDFMostafadarwishNo ratings yet
- Higher Order Differentiation and Its ApplicationsDocument22 pagesHigher Order Differentiation and Its ApplicationsPranaykumar PatraNo ratings yet
- Fluid Mechanics 2 Lab ManualDocument50 pagesFluid Mechanics 2 Lab ManualMuhammad IsmailNo ratings yet
- Applications and Characteristics of Overcurrent Relays (ANSI 50, 51)Document6 pagesApplications and Characteristics of Overcurrent Relays (ANSI 50, 51)catalinccNo ratings yet
- E196-06 (2012) Standard Practice For Gravity Load Testing of Floors and Low Slope RoofsDocument3 pagesE196-06 (2012) Standard Practice For Gravity Load Testing of Floors and Low Slope RoofsAlabbas FadhelNo ratings yet
- Unit D Geometric Construction PowerpointDocument34 pagesUnit D Geometric Construction PowerpointShiela Fherl S. BudionganNo ratings yet
- ICL's FR-370 TdsDocument2 pagesICL's FR-370 TdsMinh NguyễnNo ratings yet
- Indivisual Assignment by Raja Dilawar Riaz 297151Document13 pagesIndivisual Assignment by Raja Dilawar Riaz 297151Raja DIlawarNo ratings yet
- M1.Infra. Demand AssessmentDocument17 pagesM1.Infra. Demand AssessmentprincesaleemNo ratings yet
- SALINITYDocument6 pagesSALINITYNEENU M GNo ratings yet
- Test-01 - GUJCET-2021 - Code-A - Physics & Chemistry Model Test Paper (24-07-2021)Document8 pagesTest-01 - GUJCET-2021 - Code-A - Physics & Chemistry Model Test Paper (24-07-2021)dhruv kakadiyaNo ratings yet
- Assignment 1-Blueprint Reading Recap and Introduction To SolidWorks v1Document19 pagesAssignment 1-Blueprint Reading Recap and Introduction To SolidWorks v1Carlo BalbuenaNo ratings yet
- Glosario de Mecanica Ingles Español EditadoDocument96 pagesGlosario de Mecanica Ingles Español EditadoMalena AragonNo ratings yet
- MECH 1A - IntroooDocument11 pagesMECH 1A - IntroooLey YanNo ratings yet
- EDM Electrical Discharge MachiningDocument16 pagesEDM Electrical Discharge Machiningsuherlan endanNo ratings yet
- Green'S Theorem and Green'S Functions For Certain Systems of Differential EquationsDocument6 pagesGreen'S Theorem and Green'S Functions For Certain Systems of Differential EquationsEdwin Okoampa BoaduNo ratings yet
- GCSE Maths 314648 Foundation Tier Terminal Unit 3 Section B Mark Scheme (Specimen)Document3 pagesGCSE Maths 314648 Foundation Tier Terminal Unit 3 Section B Mark Scheme (Specimen)gcsemathstutor100% (1)
- Voice Recognition SystemDocument18 pagesVoice Recognition SystemArun Sharma75% (16)
- Stainless Steel For Potable Water Treatment Plants PWTP Guidelines PDFDocument8 pagesStainless Steel For Potable Water Treatment Plants PWTP Guidelines PDFAsgard SanchezNo ratings yet