Download as pdf or txt
You might also like
- Creating A Story On Employee Data SheetDocument8 pagesCreating A Story On Employee Data SheetNgumbau MasilaNo ratings yet
- IT-6210-2013T (UGRD) Quantitative Methods Prelim: Question TextDocument41 pagesIT-6210-2013T (UGRD) Quantitative Methods Prelim: Question TextYoo Jung100% (1)
- Empirical Data Analysis in Accounting and FinanceDocument37 pagesEmpirical Data Analysis in Accounting and FinanceRa'fat JalladNo ratings yet
- Sparse Gaussian Process ApproximationsDocument119 pagesSparse Gaussian Process ApproximationsAlex StihiNo ratings yet
- Fluidised Bed ReactorDocument2 pagesFluidised Bed ReactorChris AndersonNo ratings yet
- Proyecto ADDocument6 pagesProyecto ADAnkaa MxNo ratings yet
- Summary Advancements in Full-Scale Wind Engineering Experimental FacilitiesDocument20 pagesSummary Advancements in Full-Scale Wind Engineering Experimental FacilitiesPetr M.No ratings yet
- Mano RecordDocument2 pagesMano RecordumaNo ratings yet
- L (Z) TableDocument4 pagesL (Z) TableLamiaNo ratings yet
- L (Z) TableDocument4 pagesL (Z) Tablegaurav sahuNo ratings yet
- Problem 4-27 HW8 Page 1 Out of 4: Figure 1 CDF For The Standard Normal Random VariableDocument4 pagesProblem 4-27 HW8 Page 1 Out of 4: Figure 1 CDF For The Standard Normal Random VariableAlejandro ArvizuNo ratings yet
- PracticoDocument6 pagesPracticoFranz Oscar AicaSotoNo ratings yet
- Bias Forward Dioda: 0 0 V (Volt) I ( A)Document6 pagesBias Forward Dioda: 0 0 V (Volt) I ( A)TomyNo ratings yet
- Derivative GraphsDocument1 pageDerivative GraphsteachopensourceNo ratings yet
- CALFEM Mesh Module ManualDocument28 pagesCALFEM Mesh Module ManualJohan Lorentzon100% (1)
- Group 4 ProjectDocument3 pagesGroup 4 ProjectJohn BuzzerioNo ratings yet
- ProbstatDocument2 pagesProbstatHamdi Fadli 2107110513No ratings yet
- Trazador Lineal Datos X F (X) 3 2.5 4.5 1 7 2.5 9 0.5 Pendiente M 0.6 F 5 1.3Document10 pagesTrazador Lineal Datos X F (X) 3 2.5 4.5 1 7 2.5 9 0.5 Pendiente M 0.6 F 5 1.3mauricio lopezNo ratings yet
- 3.3. Emotional Woman Distribution of Basic Emotions, Physical Experiences and Psychological Constructs (Both Positive and Negative) Are RelatedDocument6 pages3.3. Emotional Woman Distribution of Basic Emotions, Physical Experiences and Psychological Constructs (Both Positive and Negative) Are RelatedshelydindafatmaanggraeniNo ratings yet
- Table of ContentDocument48 pagesTable of Content健恒陳No ratings yet
- 21MAT117 12 MIS2 Hessian MUOptimizationDocument23 pages21MAT117 12 MIS2 Hessian MUOptimizationVamsi Vardhan ReddyNo ratings yet
- Checking, Selecting & Predicting With Gams: Mathematical Sciences, University of Bath, U.KDocument21 pagesChecking, Selecting & Predicting With Gams: Mathematical Sciences, University of Bath, U.KKiril IvanovNo ratings yet
- Using graphics and pictures in L TEX 2ε: 1 The picture environmentDocument3 pagesUsing graphics and pictures in L TEX 2ε: 1 The picture environmentnalluri_08No ratings yet
- Statistika 1819 PPT6 Estimating Parameter & Sample SizeDocument21 pagesStatistika 1819 PPT6 Estimating Parameter & Sample SizemxrcurrieeNo ratings yet
- RM Notes Speicher v2Document141 pagesRM Notes Speicher v2Luis Dario Ortíz IzquierdoNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout Planfasi rahmanNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout Planfasi rahmanNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout PlanFasi Rahman AbrarNo ratings yet
- Sub:-Working Drawing: Title:-Column Layout PlanDocument1 pageSub:-Working Drawing: Title:-Column Layout PlanFasi Rahman AbrarNo ratings yet
- Mosfet TransferDocument2 pagesMosfet TransferAashiq KhanNo ratings yet
- 4 - Hierachical ClusteringDocument43 pages4 - Hierachical ClusteringZhu HaoyuNo ratings yet
- Appendix 2: Probability ChartsDocument53 pagesAppendix 2: Probability ChartsPraphon TangwongsathitchokNo ratings yet
- Distribusi NormalDocument14 pagesDistribusi NormalR-StatsNo ratings yet
- Vitesses D'écoulement Plage BlancheDocument1 pageVitesses D'écoulement Plage BlancheZakaria11111No ratings yet
- Homclimatol3 A3Document8 pagesHomclimatol3 A3Magaly LujanNo ratings yet
- Kuiz 1 Dde3223 08091Document3 pagesKuiz 1 Dde3223 08091Razman RamedanNo ratings yet
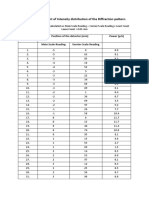
- (A) Measurement of Intensity Distribution of The Diffraction PatternDocument2 pages(A) Measurement of Intensity Distribution of The Diffraction PatternBhupesh YadavNo ratings yet
- Exam 1Document6 pagesExam 1Danien LopesNo ratings yet
- 2009-03-31 Function Transformation, Part 3.5Document2 pages2009-03-31 Function Transformation, Part 3.5samjshahNo ratings yet
- En Tanagra KMO Bartlett PDFDocument8 pagesEn Tanagra KMO Bartlett PDFtheNo ratings yet
- Permeabilidad y SolubilidadDocument2 pagesPermeabilidad y SolubilidadJackelin SanchezNo ratings yet
- Permeabilidad y SolubilidadDocument2 pagesPermeabilidad y SolubilidadJackelin SanchezNo ratings yet
- Quiz - Update (2) - ModelDocument1 pageQuiz - Update (2) - ModelEmmy MohamedNo ratings yet
- Basic Geometries On AutocadDocument20 pagesBasic Geometries On AutocadPujan NeupaneNo ratings yet
- MEDAN MAGNET RevisiDocument5 pagesMEDAN MAGNET RevisiHananNo ratings yet
- Funkciju Grafikai UzduotisDocument5 pagesFunkciju Grafikai UzduotisnetavoberniukasNo ratings yet
- No 1Document4 pagesNo 1Alma Tyara SNo ratings yet
- No 1Document4 pagesNo 1Alma Tyara SNo ratings yet
- No 1Document4 pagesNo 1Alma Tyara SNo ratings yet
- Grafik Id Terhadap VDDocument2 pagesGrafik Id Terhadap VDBima RamaNo ratings yet
- Keterangan: Titrasi Ke 1 2 Volume Awal 5,2 5,5 Volume Akhir 5,5 5,9 Volume Titrasi 0,3 0,4Document2 pagesKeterangan: Titrasi Ke 1 2 Volume Awal 5,2 5,5 Volume Akhir 5,5 5,9 Volume Titrasi 0,3 0,4Dina Aulya SeptianiNo ratings yet
- Libro 1Document11 pagesLibro 1DavidNo ratings yet
- Sampling, AD, and DADocument7 pagesSampling, AD, and DASempreInterNo ratings yet
- Tower - 3D Model Builder 6.0 Registered To KKK Radimpex - WWW - Radimpex.rsDocument1 pageTower - 3D Model Builder 6.0 Registered To KKK Radimpex - WWW - Radimpex.rsAljoša SkočajićNo ratings yet
- Reference:-MACE Material: Prepared By: - Nitesh PandeyDocument27 pagesReference:-MACE Material: Prepared By: - Nitesh PandeyDilawar KumarNo ratings yet
- Schroders Economics Lens 1717648778Document43 pagesSchroders Economics Lens 1717648778vn2689pb7hNo ratings yet
- Transformada JoukowskyDocument2 pagesTransformada JoukowskyGrecia Burga GuevaraNo ratings yet
- Program 1:: Figure 1 Figure 2Document5 pagesProgram 1:: Figure 1 Figure 2TRUE LOVERSNo ratings yet
- Aspersor Rainbird 42SA+ RotorPerformanceDocument1 pageAspersor Rainbird 42SA+ RotorPerformanceJorge BarrazaNo ratings yet
- Computationally-Efficient Range-Dependence Compensation Method For Bistatic Radar STAPDocument6 pagesComputationally-Efficient Range-Dependence Compensation Method For Bistatic Radar STAPatmroo9No ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Introduction To Multiple RegressionDocument36 pagesIntroduction To Multiple RegressionRa'fat JalladNo ratings yet
- Ordinary Least SquaresDocument17 pagesOrdinary Least SquaresRa'fat JalladNo ratings yet
- Hypothesis Tests and Confidence Intervals in Multiple RegressionDocument44 pagesHypothesis Tests and Confidence Intervals in Multiple RegressionRa'fat JalladNo ratings yet
- Regression With A Single Regressor: Hypothesis Tests and Confidence IntervalsDocument46 pagesRegression With A Single Regressor: Hypothesis Tests and Confidence IntervalsRa'fat JalladNo ratings yet
- مبادئ المحاسبة- ويجانت،كيسو، كميلDocument742 pagesمبادئ المحاسبة- ويجانت،كيسو، كميلRa'fat JalladNo ratings yet
- A Short Introduction To STATADocument8 pagesA Short Introduction To STATARa'fat JalladNo ratings yet
- Derivatives and Risk Management16mDocument291 pagesDerivatives and Risk Management16mRa'fat JalladNo ratings yet
- Linear Regression With One RegressionDocument42 pagesLinear Regression With One RegressionRa'fat JalladNo ratings yet
- Fintech: Overview, Payments, and Regulation: Key Considerations in FintechDocument79 pagesFintech: Overview, Payments, and Regulation: Key Considerations in FintechRa'fat JalladNo ratings yet
- Chapter 8 Government Regulation of InsuranceDocument12 pagesChapter 8 Government Regulation of InsuranceRa'fat JalladNo ratings yet
- Principles of Risk Management and Insurance, 13E, Global Edition (Rejda/Mcnamara)Document11 pagesPrinciples of Risk Management and Insurance, 13E, Global Edition (Rejda/Mcnamara)Ra'fat Jallad100% (1)
- Market EfficiencyDocument233 pagesMarket EfficiencyRa'fat JalladNo ratings yet
- Rejda rmiGE ppt01Document43 pagesRejda rmiGE ppt01Ra'fat JalladNo ratings yet
- TIF-chapter 4Document14 pagesTIF-chapter 4Ra'fat JalladNo ratings yet
- CALM4e Slides Ch01Document22 pagesCALM4e Slides Ch01Ra'fat JalladNo ratings yet
- Chapter 5 Types of Insurers and Marketing SystemsDocument11 pagesChapter 5 Types of Insurers and Marketing SystemsRa'fat JalladNo ratings yet
- The Role of Managerial FinanceDocument44 pagesThe Role of Managerial FinanceRa'fat JalladNo ratings yet
- Emerald: It Gives An Overview ofDocument1 pageEmerald: It Gives An Overview ofRa'fat JalladNo ratings yet
- Empirical Data Analysis in Accounting and FinanceDocument37 pagesEmpirical Data Analysis in Accounting and FinanceRa'fat JalladNo ratings yet
- Effects of Date Fruit (Phoenix Dactylifera L.) On Labor and Delivery Outcomes: A Systematic Review and Meta-AnalysisDocument14 pagesEffects of Date Fruit (Phoenix Dactylifera L.) On Labor and Delivery Outcomes: A Systematic Review and Meta-Analysisjoannamae molagaNo ratings yet
- Chapter 2-The Research Enterprise in Psychology-Psych 111-Student VersionDocument31 pagesChapter 2-The Research Enterprise in Psychology-Psych 111-Student VersionParker LarsonNo ratings yet
- Research Methodology: Dr. Anwar Hasan SiddiquiDocument30 pagesResearch Methodology: Dr. Anwar Hasan Siddiquigebreslassie gereziher100% (1)
- FINAL (SG) - PR 2 11 - 12 - UNIT 7 - LESSON 2 - Testing The Difference of Two MeansDocument27 pagesFINAL (SG) - PR 2 11 - 12 - UNIT 7 - LESSON 2 - Testing The Difference of Two MeansCamille Darcy AguilarNo ratings yet
- Which of The Following Provide The Most Powerful Information?Document10 pagesWhich of The Following Provide The Most Powerful Information?Media TeamNo ratings yet
- Lecture 4 PDFDocument9 pagesLecture 4 PDFQuoc KhanhNo ratings yet
- Inferential Statistics QuizletDocument2 pagesInferential Statistics QuizletDonna DuhigNo ratings yet
- Stat 2500 Fomula Sheet For Final ExamDocument1 pageStat 2500 Fomula Sheet For Final Examamaka.iwu10No ratings yet
- Sampling DistributionDocument102 pagesSampling DistributionMark B. BarrogaNo ratings yet
- Estimation of ParametersDocument20 pagesEstimation of ParametersJohnRoldGleyPanaliganNo ratings yet
- 20151113141143introduction To Statistics-7Document29 pages20151113141143introduction To Statistics-7thinagaranNo ratings yet
- Graded Worksheet D3Document1 pageGraded Worksheet D3Jacob DziubekNo ratings yet
- Ms. Koni Bernadette C. Tarayao Faculty in Mathematics College of EducationDocument68 pagesMs. Koni Bernadette C. Tarayao Faculty in Mathematics College of EducationChristyNo ratings yet
- AG213 ExamDocument7 pagesAG213 ExamTetzNo ratings yet
- Qualitative Versus Quantitative ResearchDocument11 pagesQualitative Versus Quantitative ResearchNehjoy GerangueNo ratings yet
- Business Statistics - Mid Term Set 1-1Document4 pagesBusiness Statistics - Mid Term Set 1-1vinayak mishraNo ratings yet
- Ma6452 Notes 1 PDFDocument238 pagesMa6452 Notes 1 PDFJohn Eric BernardNo ratings yet
- Medicine: Effects of Exercise Therapy For Pregnancy-Related Low Back Pain and Pelvic PainDocument7 pagesMedicine: Effects of Exercise Therapy For Pregnancy-Related Low Back Pain and Pelvic Painnovia wulandariNo ratings yet
- Practical Research 2 Learning CompetenciDocument2 pagesPractical Research 2 Learning CompetenciGerone Tolentino AtienzaNo ratings yet
- Bahan Univariate Linear RegressionDocument64 pagesBahan Univariate Linear RegressionDwi AstitiNo ratings yet
- RM Module 2Document14 pagesRM Module 2YogeshNo ratings yet
- Wilcoxon T TestDocument2 pagesWilcoxon T TestMikay DastasNo ratings yet
- Case Control StudyDocument12 pagesCase Control StudyNirav JoshiNo ratings yet
- Business Research (BA 501)Document21 pagesBusiness Research (BA 501)Allan Angelo GarciaNo ratings yet
- International Journal of Accounting Information SystemsDocument20 pagesInternational Journal of Accounting Information SystemsSherihan ElraysNo ratings yet
- Experimental Design With Sample TableDocument17 pagesExperimental Design With Sample TableAustinSalvadorNo ratings yet
- Type How To Carry Out Advantages Disadvantages: Simple Random SamplingDocument1 pageType How To Carry Out Advantages Disadvantages: Simple Random SamplingAmir PoustiNo ratings yet
- H T S M: Ypothesis Ests FOR A Ingle EANDocument1 pageH T S M: Ypothesis Ests FOR A Ingle EANRein BulahaoNo ratings yet
- Rangkuman Teknik Statistik Dalam Pengujian Hipotesis: IndependentDocument1 pageRangkuman Teknik Statistik Dalam Pengujian Hipotesis: Independentrizqya laramadhanaNo ratings yet