
Abstract.: Array T N
Abstract.: Array T N
You might also like
- Using Matlab: Page 1 of 3 Spring Semester 2012Document3 pagesUsing Matlab: Page 1 of 3 Spring Semester 2012Alexand MelialaNo ratings yet
- Contractors List of USADocument21 pagesContractors List of USAjerry 121100% (2)
- Computational Aids in Aeroservoelastic Analysis Using MATLABDocument175 pagesComputational Aids in Aeroservoelastic Analysis Using MATLABHamed AzargoshasbNo ratings yet
- Biomedical Applications of Soft RoboticsDocument11 pagesBiomedical Applications of Soft RoboticsAbdul Rehman100% (2)
- Appendix Ii. Image Processing Using Opencv LibraryDocument11 pagesAppendix Ii. Image Processing Using Opencv LibraryvladNo ratings yet
- LAB ManualDocument99 pagesLAB ManualRohit ChaharNo ratings yet
- An Introduction To RcppEigenDocument16 pagesAn Introduction To RcppEigenAline OliveiraNo ratings yet
- Comm. Sys Lab: SPRING 2013Document85 pagesComm. Sys Lab: SPRING 2013ahmad035No ratings yet
- Intro To Programming Lesson 6Document15 pagesIntro To Programming Lesson 6Amos MunyiluNo ratings yet
- Multidimensional Arrays - MATLAB & Simulink - MathWorks IndiaDocument10 pagesMultidimensional Arrays - MATLAB & Simulink - MathWorks IndiaAranyakChakravartyNo ratings yet
- 19CBS1003 MATLAB Assignment-1Document8 pages19CBS1003 MATLAB Assignment-1Yala yoloNo ratings yet
- CE 205-MATLAB For Civil Engineers: Irfan Turk Fatih University, 2013-14Document20 pagesCE 205-MATLAB For Civil Engineers: Irfan Turk Fatih University, 2013-14Marco Antonio Osorio ClementeNo ratings yet
- Signals and Systems Lab Manual: University of Engineering & Technology, TaxilaDocument22 pagesSignals and Systems Lab Manual: University of Engineering & Technology, TaxilafatimaNo ratings yet
- Matlab Assignment-01 SEM-II-2016-2017 PDFDocument5 pagesMatlab Assignment-01 SEM-II-2016-2017 PDFfarhanfendiNo ratings yet
- Arrays in CDocument9 pagesArrays in Cmasacan191No ratings yet
- Matlab Chapter 1Document65 pagesMatlab Chapter 1Abhilash MallikarjunaNo ratings yet
- 1 Introduction To MatlabDocument17 pages1 Introduction To MatlabFizza ShaikhNo ratings yet
- PSCP Notes Co3&Co4Document58 pagesPSCP Notes Co3&Co4chennareddydeepu36No ratings yet
- Set 2Document10 pagesSet 2koushikmalakarNo ratings yet
- Laboratory Manual: Communication SystemsDocument12 pagesLaboratory Manual: Communication SystemsTaYyba NoreenNo ratings yet
- Basic Operations in Image Processing: ObjectivesDocument6 pagesBasic Operations in Image Processing: ObjectivesAamir ChohanNo ratings yet
- Mathematics With Matlab: 4.1 Data ClassesDocument9 pagesMathematics With Matlab: 4.1 Data ClassesSyarif HidayatNo ratings yet
- Technical Computing Laboratory ManualDocument54 pagesTechnical Computing Laboratory ManualKarlo UntalanNo ratings yet
- Arrays, Dynamic Array Allocation - Programming in CDocument9 pagesArrays, Dynamic Array Allocation - Programming in CIoakeimTziakosNo ratings yet
- Matlab Tutorial: Getting StartedDocument25 pagesMatlab Tutorial: Getting StartedGITAM UNIVERISTYNo ratings yet
- The Matrix PDFDocument120 pagesThe Matrix PDFGouse MaahiNo ratings yet
- 2D ArraysDocument38 pages2D ArraysAJAY J BITNo ratings yet
- Introduction Part I: Basic Matlab StructureDocument28 pagesIntroduction Part I: Basic Matlab StructureMahreenNo ratings yet
- Lab Notes: CE 33500, Computational Methods in Civil EngineeringDocument10 pagesLab Notes: CE 33500, Computational Methods in Civil EngineeringJose Lorenzo TrujilloNo ratings yet
- DSP LAB ManualCompleteDocument64 pagesDSP LAB ManualCompleteHamzaAliNo ratings yet
- Array in C ProgrammingDocument9 pagesArray in C ProgrammingsrkakarlapudiNo ratings yet
- LAB 02: MATLAB Programming: 2.1 Basic Symbols and CommandsDocument6 pagesLAB 02: MATLAB Programming: 2.1 Basic Symbols and CommandsMuhammad Massab KhanNo ratings yet
- ch05 (4) - Multi Dim ArraysDocument15 pagesch05 (4) - Multi Dim ArraysSamantha MorinNo ratings yet
- DSA Lab 2Document9 pagesDSA Lab 2Waleed RajaNo ratings yet
- Howto Octave C++Document14 pagesHowto Octave C++Simu66No ratings yet
- Matlab TutorDocument8 pagesMatlab Tutorwferry27No ratings yet
- C LabDocument59 pagesC LabMohammed ImthiazNo ratings yet
- ArraysDocument37 pagesArraysTahaRazviNo ratings yet
- Programming For Problem Solving Using C Unit-Iii: ArraysDocument20 pagesProgramming For Problem Solving Using C Unit-Iii: ArraysNaresh BabuNo ratings yet
- C NotesDocument12 pagesC NotesHarshit SrivastavaNo ratings yet
- 16 Arrays: L L L LDocument17 pages16 Arrays: L L L LroselathikaNo ratings yet
- C++Lec3 - Multi - DimensionalArrayDocument36 pagesC++Lec3 - Multi - DimensionalArrayhaponabeelNo ratings yet
- Matlab Tutorial: Getting StartedDocument25 pagesMatlab Tutorial: Getting StartedMetinOktayNo ratings yet
- Assignment 1 LabDocument14 pagesAssignment 1 LabUzair AshfaqNo ratings yet
- MatlabDocument42 pagesMatlabDeepakNo ratings yet
- Matlab TutorialDocument90 pagesMatlab Tutorialroghani50% (2)
- Sci Lab PrimerDocument18 pagesSci Lab PrimerBurcu DenizNo ratings yet
- Matlab TutorialDocument34 pagesMatlab TutorialrtloquiasNo ratings yet
- ManualDocument358 pagesManualBridenEspinozaNo ratings yet
- DSP Lab ManualDocument67 pagesDSP Lab Manualloststranger990100% (1)
- When You Start MATLABDocument78 pagesWhen You Start MATLABDemetriog1No ratings yet
- Arrays and Pointers in CDocument9 pagesArrays and Pointers in CShafil AhammedNo ratings yet
- C++ Vs FortranDocument10 pagesC++ Vs FortranKian ChuanNo ratings yet
- Classes (II) : Overloading OperatorsDocument2 pagesClasses (II) : Overloading Operatorsicul1No ratings yet
- Introduction To MATLAB: Lecturer: Cik Sitinoor Adeib Binti Idris Room: Level 5 CONTACT NUMBER: 03-5543 6362Document27 pagesIntroduction To MATLAB: Lecturer: Cik Sitinoor Adeib Binti Idris Room: Level 5 CONTACT NUMBER: 03-5543 6362seddeswertyNo ratings yet
- Differentiate Between Data Type and Data StructuresDocument11 pagesDifferentiate Between Data Type and Data StructureskrishnakumarNo ratings yet
- Lab 3Document8 pagesLab 3Mian BlalNo ratings yet
- Sns Lab ManualDocument33 pagesSns Lab ManualAnush ReeNo ratings yet
- Octave/Matlab Tutorial: Kai ArrasDocument111 pagesOctave/Matlab Tutorial: Kai ArrasAnonymous zBSE9MNo ratings yet
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Health & Family Welfare Department: Government of West BengalDocument2 pagesHealth & Family Welfare Department: Government of West BengalBiswajit GhoshNo ratings yet
- Azu Etd 11766 Sip1 M PDFDocument333 pagesAzu Etd 11766 Sip1 M PDFBiswajit GhoshNo ratings yet
- (NEET) UG July - 2020 Is Being Circulated Through Various Sources and Social MediaDocument1 page(NEET) UG July - 2020 Is Being Circulated Through Various Sources and Social MediaBiswajit GhoshNo ratings yet
- Santanu Dey: Academic Qualification Name of Exam/ Degree Year of Passing Percentage SubjectDocument3 pagesSantanu Dey: Academic Qualification Name of Exam/ Degree Year of Passing Percentage SubjectBiswajit GhoshNo ratings yet
- Products Detail PDFDocument7 pagesProducts Detail PDFBiswajit GhoshNo ratings yet
- Dear Professor XXXDocument1 pageDear Professor XXXBiswajit GhoshNo ratings yet
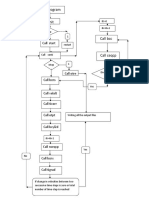
- Flow ChartDocument1 pageFlow ChartBiswajit GhoshNo ratings yet
- Eng Quist 77Document24 pagesEng Quist 77Biswajit GhoshNo ratings yet
- ThesisDocument24 pagesThesisBiswajit GhoshNo ratings yet
- Test Bank For Learning and Behavior Active Learning 6th Edition by ChanceDocument24 pagesTest Bank For Learning and Behavior Active Learning 6th Edition by ChanceTonyRamosriqzf100% (31)
- 2021 Nail and Systemic DiseasesDocument21 pages2021 Nail and Systemic Diseaseshaytham aliNo ratings yet
- Essential Orthopaedics 2Nd Edition Mark D Miller Full ChapterDocument67 pagesEssential Orthopaedics 2Nd Edition Mark D Miller Full Chaptermargaret.jones429100% (8)
- 1.2c atDocument3 pages1.2c atenyw160309No ratings yet
- Metodo Hach HierroDocument6 pagesMetodo Hach HierroJESSICA VANESSA ARISMENDI AVILEZNo ratings yet
- Appendix Table 1.: To FiDocument1 pageAppendix Table 1.: To FiPavitra HegdeNo ratings yet
- Zscaler Q3-23 Corporate PresentationDocument40 pagesZscaler Q3-23 Corporate Presentationjoshka musicNo ratings yet
- CIOs and The Future of ITDocument8 pagesCIOs and The Future of ITdany odarNo ratings yet
- HR Governance As A Part of The Corporate Governance ConceptDocument24 pagesHR Governance As A Part of The Corporate Governance ConceptRudi HaryantoNo ratings yet
- Internet Banking (E-Banking)Document16 pagesInternet Banking (E-Banking)Saurabh G0% (2)
- Mankind IPODocument548 pagesMankind IPOVishwas SharmaNo ratings yet
- Islamic Architecture PDFDocument32 pagesIslamic Architecture PDFCamille CiokonNo ratings yet
- Adam Black2004Document8 pagesAdam Black2004Kókai BalázsNo ratings yet
- Evangelism 1Document4 pagesEvangelism 1Horace Owiti O.No ratings yet
- Chap 1-5 NotesDocument14 pagesChap 1-5 NotesBismah SaleemNo ratings yet
- Quiz No. 1 Audit Opinion and Audit of Cash Part 1 PDFDocument4 pagesQuiz No. 1 Audit Opinion and Audit of Cash Part 1 PDFrhemanne18No ratings yet
- Presentation About MyselfDocument18 pagesPresentation About MyselfbisnunepmanyNo ratings yet
- 1st Periodical Test in IctDocument3 pages1st Periodical Test in IctWander Mary81% (16)
- Physics Investigatory Project Class 12Document22 pagesPhysics Investigatory Project Class 12Siddharth SinghNo ratings yet
- Volume 7 No 8 2018Document142 pagesVolume 7 No 8 2018Salhi AmaraNo ratings yet
- Assignment Solutions - 134Document6 pagesAssignment Solutions - 134Prof OliviaNo ratings yet
- E Commerce Chap 1Document28 pagesE Commerce Chap 1Jannatul FardusNo ratings yet
- Birth QnaDocument8 pagesBirth QnaaliazgarNo ratings yet
- Online Marketing EssentialsDocument508 pagesOnline Marketing EssentialsElena BotezatuNo ratings yet
- FIS - Fixed Income SecuritiesDocument3 pagesFIS - Fixed Income SecuritiesNavi FisNo ratings yet
- Power Electronics Project TitlesDocument4 pagesPower Electronics Project Titlesvmurali.infoNo ratings yet
- Describe One Memory Model With Reference To Research!Document10 pagesDescribe One Memory Model With Reference To Research!Thuý ThanhNo ratings yet

































































































Download as pdf or txt
You might also like
- Using Matlab: Page 1 of 3 Spring Semester 2012Document3 pagesUsing Matlab: Page 1 of 3 Spring Semester 2012Alexand MelialaNo ratings yet
- Contractors List of USADocument21 pagesContractors List of USAjerry 121100% (2)
- Computational Aids in Aeroservoelastic Analysis Using MATLABDocument175 pagesComputational Aids in Aeroservoelastic Analysis Using MATLABHamed AzargoshasbNo ratings yet
- Biomedical Applications of Soft RoboticsDocument11 pagesBiomedical Applications of Soft RoboticsAbdul Rehman100% (2)
- Appendix Ii. Image Processing Using Opencv LibraryDocument11 pagesAppendix Ii. Image Processing Using Opencv LibraryvladNo ratings yet
- LAB ManualDocument99 pagesLAB ManualRohit ChaharNo ratings yet
- An Introduction To RcppEigenDocument16 pagesAn Introduction To RcppEigenAline OliveiraNo ratings yet
- Comm. Sys Lab: SPRING 2013Document85 pagesComm. Sys Lab: SPRING 2013ahmad035No ratings yet
- Intro To Programming Lesson 6Document15 pagesIntro To Programming Lesson 6Amos MunyiluNo ratings yet
- Multidimensional Arrays - MATLAB & Simulink - MathWorks IndiaDocument10 pagesMultidimensional Arrays - MATLAB & Simulink - MathWorks IndiaAranyakChakravartyNo ratings yet
- 19CBS1003 MATLAB Assignment-1Document8 pages19CBS1003 MATLAB Assignment-1Yala yoloNo ratings yet
- CE 205-MATLAB For Civil Engineers: Irfan Turk Fatih University, 2013-14Document20 pagesCE 205-MATLAB For Civil Engineers: Irfan Turk Fatih University, 2013-14Marco Antonio Osorio ClementeNo ratings yet
- Signals and Systems Lab Manual: University of Engineering & Technology, TaxilaDocument22 pagesSignals and Systems Lab Manual: University of Engineering & Technology, TaxilafatimaNo ratings yet
- Matlab Assignment-01 SEM-II-2016-2017 PDFDocument5 pagesMatlab Assignment-01 SEM-II-2016-2017 PDFfarhanfendiNo ratings yet
- Arrays in CDocument9 pagesArrays in Cmasacan191No ratings yet
- Matlab Chapter 1Document65 pagesMatlab Chapter 1Abhilash MallikarjunaNo ratings yet
- 1 Introduction To MatlabDocument17 pages1 Introduction To MatlabFizza ShaikhNo ratings yet
- PSCP Notes Co3&Co4Document58 pagesPSCP Notes Co3&Co4chennareddydeepu36No ratings yet
- Set 2Document10 pagesSet 2koushikmalakarNo ratings yet
- Laboratory Manual: Communication SystemsDocument12 pagesLaboratory Manual: Communication SystemsTaYyba NoreenNo ratings yet
- Basic Operations in Image Processing: ObjectivesDocument6 pagesBasic Operations in Image Processing: ObjectivesAamir ChohanNo ratings yet
- Mathematics With Matlab: 4.1 Data ClassesDocument9 pagesMathematics With Matlab: 4.1 Data ClassesSyarif HidayatNo ratings yet
- Technical Computing Laboratory ManualDocument54 pagesTechnical Computing Laboratory ManualKarlo UntalanNo ratings yet
- Arrays, Dynamic Array Allocation - Programming in CDocument9 pagesArrays, Dynamic Array Allocation - Programming in CIoakeimTziakosNo ratings yet
- Matlab Tutorial: Getting StartedDocument25 pagesMatlab Tutorial: Getting StartedGITAM UNIVERISTYNo ratings yet
- The Matrix PDFDocument120 pagesThe Matrix PDFGouse MaahiNo ratings yet
- 2D ArraysDocument38 pages2D ArraysAJAY J BITNo ratings yet
- Introduction Part I: Basic Matlab StructureDocument28 pagesIntroduction Part I: Basic Matlab StructureMahreenNo ratings yet
- Lab Notes: CE 33500, Computational Methods in Civil EngineeringDocument10 pagesLab Notes: CE 33500, Computational Methods in Civil EngineeringJose Lorenzo TrujilloNo ratings yet
- DSP LAB ManualCompleteDocument64 pagesDSP LAB ManualCompleteHamzaAliNo ratings yet
- Array in C ProgrammingDocument9 pagesArray in C ProgrammingsrkakarlapudiNo ratings yet
- LAB 02: MATLAB Programming: 2.1 Basic Symbols and CommandsDocument6 pagesLAB 02: MATLAB Programming: 2.1 Basic Symbols and CommandsMuhammad Massab KhanNo ratings yet
- ch05 (4) - Multi Dim ArraysDocument15 pagesch05 (4) - Multi Dim ArraysSamantha MorinNo ratings yet
- DSA Lab 2Document9 pagesDSA Lab 2Waleed RajaNo ratings yet
- Howto Octave C++Document14 pagesHowto Octave C++Simu66No ratings yet
- Matlab TutorDocument8 pagesMatlab Tutorwferry27No ratings yet
- C LabDocument59 pagesC LabMohammed ImthiazNo ratings yet
- ArraysDocument37 pagesArraysTahaRazviNo ratings yet
- Programming For Problem Solving Using C Unit-Iii: ArraysDocument20 pagesProgramming For Problem Solving Using C Unit-Iii: ArraysNaresh BabuNo ratings yet
- C NotesDocument12 pagesC NotesHarshit SrivastavaNo ratings yet
- 16 Arrays: L L L LDocument17 pages16 Arrays: L L L LroselathikaNo ratings yet
- C++Lec3 - Multi - DimensionalArrayDocument36 pagesC++Lec3 - Multi - DimensionalArrayhaponabeelNo ratings yet
- Matlab Tutorial: Getting StartedDocument25 pagesMatlab Tutorial: Getting StartedMetinOktayNo ratings yet
- Assignment 1 LabDocument14 pagesAssignment 1 LabUzair AshfaqNo ratings yet
- MatlabDocument42 pagesMatlabDeepakNo ratings yet
- Matlab TutorialDocument90 pagesMatlab Tutorialroghani50% (2)
- Sci Lab PrimerDocument18 pagesSci Lab PrimerBurcu DenizNo ratings yet
- Matlab TutorialDocument34 pagesMatlab TutorialrtloquiasNo ratings yet
- ManualDocument358 pagesManualBridenEspinozaNo ratings yet
- DSP Lab ManualDocument67 pagesDSP Lab Manualloststranger990100% (1)
- When You Start MATLABDocument78 pagesWhen You Start MATLABDemetriog1No ratings yet
- Arrays and Pointers in CDocument9 pagesArrays and Pointers in CShafil AhammedNo ratings yet
- C++ Vs FortranDocument10 pagesC++ Vs FortranKian ChuanNo ratings yet
- Classes (II) : Overloading OperatorsDocument2 pagesClasses (II) : Overloading Operatorsicul1No ratings yet
- Introduction To MATLAB: Lecturer: Cik Sitinoor Adeib Binti Idris Room: Level 5 CONTACT NUMBER: 03-5543 6362Document27 pagesIntroduction To MATLAB: Lecturer: Cik Sitinoor Adeib Binti Idris Room: Level 5 CONTACT NUMBER: 03-5543 6362seddeswertyNo ratings yet
- Differentiate Between Data Type and Data StructuresDocument11 pagesDifferentiate Between Data Type and Data StructureskrishnakumarNo ratings yet
- Lab 3Document8 pagesLab 3Mian BlalNo ratings yet
- Sns Lab ManualDocument33 pagesSns Lab ManualAnush ReeNo ratings yet
- Octave/Matlab Tutorial: Kai ArrasDocument111 pagesOctave/Matlab Tutorial: Kai ArrasAnonymous zBSE9MNo ratings yet
- Advanced C Concepts and Programming: First EditionFrom EverandAdvanced C Concepts and Programming: First EditionRating: 3 out of 5 stars3/5 (1)
- Health & Family Welfare Department: Government of West BengalDocument2 pagesHealth & Family Welfare Department: Government of West BengalBiswajit GhoshNo ratings yet
- Azu Etd 11766 Sip1 M PDFDocument333 pagesAzu Etd 11766 Sip1 M PDFBiswajit GhoshNo ratings yet
- (NEET) UG July - 2020 Is Being Circulated Through Various Sources and Social MediaDocument1 page(NEET) UG July - 2020 Is Being Circulated Through Various Sources and Social MediaBiswajit GhoshNo ratings yet
- Santanu Dey: Academic Qualification Name of Exam/ Degree Year of Passing Percentage SubjectDocument3 pagesSantanu Dey: Academic Qualification Name of Exam/ Degree Year of Passing Percentage SubjectBiswajit GhoshNo ratings yet
- Products Detail PDFDocument7 pagesProducts Detail PDFBiswajit GhoshNo ratings yet
- Dear Professor XXXDocument1 pageDear Professor XXXBiswajit GhoshNo ratings yet
- Flow ChartDocument1 pageFlow ChartBiswajit GhoshNo ratings yet
- Eng Quist 77Document24 pagesEng Quist 77Biswajit GhoshNo ratings yet
- ThesisDocument24 pagesThesisBiswajit GhoshNo ratings yet
- Test Bank For Learning and Behavior Active Learning 6th Edition by ChanceDocument24 pagesTest Bank For Learning and Behavior Active Learning 6th Edition by ChanceTonyRamosriqzf100% (31)
- 2021 Nail and Systemic DiseasesDocument21 pages2021 Nail and Systemic Diseaseshaytham aliNo ratings yet
- Essential Orthopaedics 2Nd Edition Mark D Miller Full ChapterDocument67 pagesEssential Orthopaedics 2Nd Edition Mark D Miller Full Chaptermargaret.jones429100% (8)
- 1.2c atDocument3 pages1.2c atenyw160309No ratings yet
- Metodo Hach HierroDocument6 pagesMetodo Hach HierroJESSICA VANESSA ARISMENDI AVILEZNo ratings yet
- Appendix Table 1.: To FiDocument1 pageAppendix Table 1.: To FiPavitra HegdeNo ratings yet
- Zscaler Q3-23 Corporate PresentationDocument40 pagesZscaler Q3-23 Corporate Presentationjoshka musicNo ratings yet
- CIOs and The Future of ITDocument8 pagesCIOs and The Future of ITdany odarNo ratings yet
- HR Governance As A Part of The Corporate Governance ConceptDocument24 pagesHR Governance As A Part of The Corporate Governance ConceptRudi HaryantoNo ratings yet
- Internet Banking (E-Banking)Document16 pagesInternet Banking (E-Banking)Saurabh G0% (2)
- Mankind IPODocument548 pagesMankind IPOVishwas SharmaNo ratings yet
- Islamic Architecture PDFDocument32 pagesIslamic Architecture PDFCamille CiokonNo ratings yet
- Adam Black2004Document8 pagesAdam Black2004Kókai BalázsNo ratings yet
- Evangelism 1Document4 pagesEvangelism 1Horace Owiti O.No ratings yet
- Chap 1-5 NotesDocument14 pagesChap 1-5 NotesBismah SaleemNo ratings yet
- Quiz No. 1 Audit Opinion and Audit of Cash Part 1 PDFDocument4 pagesQuiz No. 1 Audit Opinion and Audit of Cash Part 1 PDFrhemanne18No ratings yet
- Presentation About MyselfDocument18 pagesPresentation About MyselfbisnunepmanyNo ratings yet
- 1st Periodical Test in IctDocument3 pages1st Periodical Test in IctWander Mary81% (16)
- Physics Investigatory Project Class 12Document22 pagesPhysics Investigatory Project Class 12Siddharth SinghNo ratings yet
- Volume 7 No 8 2018Document142 pagesVolume 7 No 8 2018Salhi AmaraNo ratings yet
- Assignment Solutions - 134Document6 pagesAssignment Solutions - 134Prof OliviaNo ratings yet
- E Commerce Chap 1Document28 pagesE Commerce Chap 1Jannatul FardusNo ratings yet
- Birth QnaDocument8 pagesBirth QnaaliazgarNo ratings yet
- Online Marketing EssentialsDocument508 pagesOnline Marketing EssentialsElena BotezatuNo ratings yet
- FIS - Fixed Income SecuritiesDocument3 pagesFIS - Fixed Income SecuritiesNavi FisNo ratings yet
- Power Electronics Project TitlesDocument4 pagesPower Electronics Project Titlesvmurali.infoNo ratings yet
- Describe One Memory Model With Reference To Research!Document10 pagesDescribe One Memory Model With Reference To Research!Thuý ThanhNo ratings yet