
Ensemble Classifiers For Network Intrusion Detection System: July 2009
Ensemble Classifiers For Network Intrusion Detection System: July 2009
You might also like
- CNN ExamplesDocument2 pagesCNN ExamplesCarmen PoparascuNo ratings yet
- Tenta 210826Document3 pagesTenta 210826InetheroNo ratings yet
- Research Proposal For MS (CS) ThesisDocument9 pagesResearch Proposal For MS (CS) ThesisUmar Ali100% (1)
- Lab # 6 Time Response AnalysisDocument10 pagesLab # 6 Time Response AnalysisFahad AneebNo ratings yet
- Ensemble Classifiers For Network Intrusion Detection System: July 2009Document10 pagesEnsemble Classifiers For Network Intrusion Detection System: July 2009EDGAR RODRIGO NAULA LOPEZNo ratings yet
- A Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningDocument12 pagesA Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningB AnandNo ratings yet
- Ids Ae 2Document9 pagesIds Ae 2Aliya TabassumNo ratings yet
- Cyber5 Cyber SecurityDocument9 pagesCyber5 Cyber SecurityMoriwamNo ratings yet
- Ensemble Based Approach For IntrusionDocument8 pagesEnsemble Based Approach For IntrusionKurniabudi ZaimarNo ratings yet
- Enhanced Network Anomaly Detection Based On Deep Neural NetworksDocument16 pagesEnhanced Network Anomaly Detection Based On Deep Neural NetworksYishak TadeleNo ratings yet
- Evaluating Machine Learning Algorithms F-1Document6 pagesEvaluating Machine Learning Algorithms F-1keerthiksNo ratings yet
- 1 s2.0 S2405609X15300300 MainDocument11 pages1 s2.0 S2405609X15300300 MaingmgaargiNo ratings yet
- Feature Selection and Comparison of Classifcation AlgorithmsDocument13 pagesFeature Selection and Comparison of Classifcation AlgorithmsankeeonlineNo ratings yet
- Intrusion Detection Using Big Data and Deep Learning TechniquesDocument9 pagesIntrusion Detection Using Big Data and Deep Learning TechniquesumarjavedNo ratings yet
- IET Communications - 2020 - Safara - Improved Intrusion Detection Method For Communication Networks Using Association RuleDocument6 pagesIET Communications - 2020 - Safara - Improved Intrusion Detection Method For Communication Networks Using Association RuleAqeel AlbahriNo ratings yet
- Ali 2018Document7 pagesAli 2018ahmedsaeedobiedNo ratings yet
- Artificial Neural Networks Optimized With Unsupervised Clustering For IDS ClassificationDocument7 pagesArtificial Neural Networks Optimized With Unsupervised Clustering For IDS ClassificationNewbiew PalsuNo ratings yet
- Evolving Dynamic Fuzzy Clustering (EDFC) To Enhance DRDoS - DNS AttacksDocument12 pagesEvolving Dynamic Fuzzy Clustering (EDFC) To Enhance DRDoS - DNS AttacksAli ALsaeediNo ratings yet
- 8478457Document13 pages8478457Zinia Anzum TonniNo ratings yet
- IDS in Telecommunication Network Using PCADocument11 pagesIDS in Telecommunication Network Using PCAAIRCC - IJCNCNo ratings yet
- Dimensionality Reduction With IG PCA and Ensemble Classifier - 2019 - Computer NDocument12 pagesDimensionality Reduction With IG PCA and Ensemble Classifier - 2019 - Computer NVian AlfalahNo ratings yet
- Network Intrusion Detection System Using Federated Machine Learning ApproachDocument8 pagesNetwork Intrusion Detection System Using Federated Machine Learning ApproachInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Building Auto-Encoder Intrusion Detection System Based On RandomDocument15 pagesBuilding Auto-Encoder Intrusion Detection System Based On Random21020028 Trần Quang TàiNo ratings yet
- Intelligent IdsDocument12 pagesIntelligent IdsyasserNo ratings yet
- Smart Intrusion Detection System ComprisDocument6 pagesSmart Intrusion Detection System ComprisfitsumNo ratings yet
- 1 s2.0 S2666285X21000947 MainDocument6 pages1 s2.0 S2666285X21000947 Mainder kochNo ratings yet
- Measuring of Data Quality in KYC Using Anomaly DetDocument7 pagesMeasuring of Data Quality in KYC Using Anomaly DetberhanNo ratings yet
- Comparison of Single and Ensemble Intrusion Detection Techniques Using Multiple DatasetsDocument10 pagesComparison of Single and Ensemble Intrusion Detection Techniques Using Multiple DatasetsWARSE JournalsNo ratings yet
- DattaDeshmukhecs 2014 6892542Document7 pagesDattaDeshmukhecs 2014 6892542Rohit MajumderNo ratings yet
- Enhanced Intrusion Detection System UsinDocument8 pagesEnhanced Intrusion Detection System UsinyonasNo ratings yet
- Topic 3Document12 pagesTopic 3swathi thotaNo ratings yet
- Paper 75-Detecting Generic Network Intrusion AttacksDocument8 pagesPaper 75-Detecting Generic Network Intrusion AttacksKhalid SyfullahNo ratings yet
- A Novel Feature Selection Approach For Intrusion Detection Data ClassificationDocument9 pagesA Novel Feature Selection Approach For Intrusion Detection Data ClassificationGururaja Hebbur SatyanarayanaNo ratings yet
- 1 s2.0 S0167404824000312 MainDocument9 pages1 s2.0 S0167404824000312 MaindaytdeenNo ratings yet
- Network Intrusion Detection Using Supervised Machine Learning Technique With Feature SelectionDocument4 pagesNetwork Intrusion Detection Using Supervised Machine Learning Technique With Feature SelectionShahid AzeemNo ratings yet
- Sarnovsky and Paralic - 2020 - Hierarchical Intrusion Detection Using Machine LeaDocument14 pagesSarnovsky and Paralic - 2020 - Hierarchical Intrusion Detection Using Machine LeaabirrazaNo ratings yet
- Ensemble Models For Intrusion Detection System ClassificationDocument15 pagesEnsemble Models For Intrusion Detection System ClassificationKurniabudi ZaimarNo ratings yet
- Intrusion Detection System Using Gradient Boosted Trees For VANETsDocument7 pagesIntrusion Detection System Using Gradient Boosted Trees For VANETsIJRASETPublicationsNo ratings yet
- A Review of Intrusion Detection System Using Machine Learning ApproachDocument8 pagesA Review of Intrusion Detection System Using Machine Learning Approachrushendra.umbNo ratings yet
- Research Paper 1Document7 pagesResearch Paper 1Meenakshi AryaNo ratings yet
- DB-OLS: An Approach For IDS1Document10 pagesDB-OLS: An Approach For IDS1ijp2pjournalNo ratings yet
- Data Mining Techniques and ApplicationsDocument6 pagesData Mining Techniques and ApplicationsIJRASETPublicationsNo ratings yet
- Proposed Algorithm Base Optimization Scheme For Intrusion Detection Using Feature SelectionDocument9 pagesProposed Algorithm Base Optimization Scheme For Intrusion Detection Using Feature SelectionInternational Journal of Advances in Applied Sciences (IJAAS)No ratings yet
- InfoSec Project ReportDocument7 pagesInfoSec Project ReporteishafarrukhNo ratings yet
- A Literature Review-Acceptance Models For E-Learning Implementation in Higher InstitutionDocument19 pagesA Literature Review-Acceptance Models For E-Learning Implementation in Higher InstitutionKurniabudi ZaimarNo ratings yet
- Optimizing Cybersecurity Attack Detection in Computer Networks 2Document6 pagesOptimizing Cybersecurity Attack Detection in Computer Networks 2NahidaNigarNo ratings yet
- 4768-Article Text-8889-1-10-20210501Document8 pages4768-Article Text-8889-1-10-20210501sumit.rksNo ratings yet
- SeguridadDocument29 pagesSeguridadandres pythonNo ratings yet
- Statistical Performance Assessment of Supervised Machine Learning Algorithms For Intrusion Detection SystemDocument12 pagesStatistical Performance Assessment of Supervised Machine Learning Algorithms For Intrusion Detection SystemIAES IJAINo ratings yet
- Innovative Machine Learning Algorithms For Classification and Intrusion DetectionDocument6 pagesInnovative Machine Learning Algorithms For Classification and Intrusion DetectionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Intrusion Detection Systems: Principles and Perspectives: November 2018Document6 pagesIntrusion Detection Systems: Principles and Perspectives: November 2018skamelNo ratings yet
- A Comparison Study For Intrusion Database (KDD99, NSL-KDD) Based On Self Organization Map (SOM) Artificial Neural NetworkDocument14 pagesA Comparison Study For Intrusion Database (KDD99, NSL-KDD) Based On Self Organization Map (SOM) Artificial Neural Networkhanifa pramanaNo ratings yet
- Tisa Random FileDocument23 pagesTisa Random Filedaenieltan2No ratings yet
- Acharya, Toya Khatri, Ishan Annamalai, Annamalai Chouikha, Mohamed F (2021)Document7 pagesAcharya, Toya Khatri, Ishan Annamalai, Annamalai Chouikha, Mohamed F (2021)soutien104No ratings yet
- A Study On Prediction Techniques of Data Mining in Educational DomainDocument4 pagesA Study On Prediction Techniques of Data Mining in Educational DomainijcnesNo ratings yet
- Malware Detection Using Machine LearningDocument5 pagesMalware Detection Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Paper 2-Application of Machine Learning Approaches in Intrusion Detection SystemDocument10 pagesPaper 2-Application of Machine Learning Approaches in Intrusion Detection SystemIbrahim qashtaNo ratings yet
- Vol 8 No 0103Document5 pagesVol 8 No 0103RAGHAVENDRA SAINo ratings yet
- Convolutional Neural Networks With LSTM For Intrusion DetectionDocument11 pagesConvolutional Neural Networks With LSTM For Intrusion DetectionAqeel AlbahriNo ratings yet
- 1 s2.0 S2212017312002964 MainDocument10 pages1 s2.0 S2212017312002964 MainGautham Krishna KbNo ratings yet
- Intrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsAIRCC - IJCNCNo ratings yet
- Intrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsAIRCC - IJCNCNo ratings yet
- Mixture Models and ApplicationsFrom EverandMixture Models and ApplicationsNizar BouguilaNo ratings yet
- A SDR-based Verification Platform For 802.11 PHY Layer Security AuthenticationDocument24 pagesA SDR-based Verification Platform For 802.11 PHY Layer Security AuthenticationEDGAR RODRIGO NAULA LOPEZNo ratings yet
- A Nationwide Census On Wifi Security Threats: Prevalence, Riskiness, and The EconomicsDocument14 pagesA Nationwide Census On Wifi Security Threats: Prevalence, Riskiness, and The EconomicsEDGAR RODRIGO NAULA LOPEZNo ratings yet
- Ensemble Classifiers For Network Intrusion Detection System: July 2009Document10 pagesEnsemble Classifiers For Network Intrusion Detection System: July 2009EDGAR RODRIGO NAULA LOPEZNo ratings yet
- Intrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and A Public DatasetDocument26 pagesIntrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and A Public DatasetEDGAR RODRIGO NAULA LOPEZ100% (1)
- Au Coe QP: Question Paper CodeDocument2 pagesAu Coe QP: Question Paper CodePeter ParkerNo ratings yet
- Lovell AE 362 Lecture Slides #9Document11 pagesLovell AE 362 Lecture Slides #9cantkillthemetalNo ratings yet
- Mte 10Document10 pagesMte 10VipinNo ratings yet
- X.509 Certificates: R.Muthukkumar Asst - Prof. (SG) /IT NEC, KovilpattiDocument25 pagesX.509 Certificates: R.Muthukkumar Asst - Prof. (SG) /IT NEC, KovilpattiRmkumarsNo ratings yet
- Random Number Generators1Document26 pagesRandom Number Generators1Scribd JdjNo ratings yet
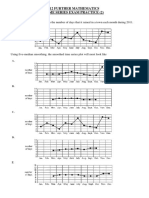
- 12 Further Mathematics Time Series Exam PracticeDocument5 pages12 Further Mathematics Time Series Exam PracticeJordan TassoneNo ratings yet
- Wavelet TransformDocument28 pagesWavelet TransformShimaa Barakat100% (1)
- Digital Signal Processing First Global Edition Full ChapterDocument41 pagesDigital Signal Processing First Global Edition Full Chaptertommy.kondracki100100% (27)
- CSE3013-Artificial Intelligence CAT1 E1 Slot Section - ADocument4 pagesCSE3013-Artificial Intelligence CAT1 E1 Slot Section - AVIT ONLINE COURSESNo ratings yet
- GARCH Parameter Estimation by Machine LearningDocument4 pagesGARCH Parameter Estimation by Machine Learningdaniel18ctNo ratings yet
- Workshop 1Document16 pagesWorkshop 1kakakkawaiiNo ratings yet
- Segmentation and Decision - Tree in SasDocument2 pagesSegmentation and Decision - Tree in SasWanohiNo ratings yet
- Introduction To Second Quantization: 1.1 Single-Particle Hilbert SpaceDocument6 pagesIntroduction To Second Quantization: 1.1 Single-Particle Hilbert Space김띵No ratings yet
- Ai, ML, DL PDFDocument2 pagesAi, ML, DL PDFsetiawan.hadiNo ratings yet
- AIML Lab ManualDocument41 pagesAIML Lab Manualheartyhome.inNo ratings yet
- Miao, Jianjun: Economic Dynamics in Discrete TimeDocument4 pagesMiao, Jianjun: Economic Dynamics in Discrete TimeMiguel OrrilloNo ratings yet
- Factorial ExperimentsDocument17 pagesFactorial ExperimentsHrithik SenNo ratings yet
- Linear System Equations: Mongi BLEL King Saud UniversityDocument24 pagesLinear System Equations: Mongi BLEL King Saud UniversityazizNo ratings yet
- Weightage of Marks in GATE Physics PDFDocument1 pageWeightage of Marks in GATE Physics PDFPankaj GuptaNo ratings yet
- Assignment#2 Image ProcessingDocument5 pagesAssignment#2 Image Processingpradeep GNo ratings yet
- Unit 7 - Week 6: Assignment 6Document4 pagesUnit 7 - Week 6: Assignment 6Raushan KashyapNo ratings yet
- Verification and Validation in CFD and Heat Transfer: ANSYS Practice and The New ASME StandardDocument22 pagesVerification and Validation in CFD and Heat Transfer: ANSYS Practice and The New ASME StandardMaxim100% (1)
- Unit 3 MLDocument28 pagesUnit 3 MLSrujana ShettyNo ratings yet
- Algorithm and FlowchartDocument16 pagesAlgorithm and FlowchartSarah Mae GonzalesNo ratings yet
- A Secure Electronic Transaction Payment Protocol DDocument9 pagesA Secure Electronic Transaction Payment Protocol DVukašin KolarevićNo ratings yet
- Partial Solutions To Exercises 2.2Document4 pagesPartial Solutions To Exercises 2.2Luhan ZhaoNo ratings yet
- WUT - M.sc. Artificial IntelligenceDocument3 pagesWUT - M.sc. Artificial IntelligenceSujeendran MenonNo ratings yet
























































































Download as pdf or txt
You might also like
- CNN ExamplesDocument2 pagesCNN ExamplesCarmen PoparascuNo ratings yet
- Tenta 210826Document3 pagesTenta 210826InetheroNo ratings yet
- Research Proposal For MS (CS) ThesisDocument9 pagesResearch Proposal For MS (CS) ThesisUmar Ali100% (1)
- Lab # 6 Time Response AnalysisDocument10 pagesLab # 6 Time Response AnalysisFahad AneebNo ratings yet
- Ensemble Classifiers For Network Intrusion Detection System: July 2009Document10 pagesEnsemble Classifiers For Network Intrusion Detection System: July 2009EDGAR RODRIGO NAULA LOPEZNo ratings yet
- A Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningDocument12 pagesA Novel Algorithm For Network Anomaly Detection Using Adaptive Machine LearningB AnandNo ratings yet
- Ids Ae 2Document9 pagesIds Ae 2Aliya TabassumNo ratings yet
- Cyber5 Cyber SecurityDocument9 pagesCyber5 Cyber SecurityMoriwamNo ratings yet
- Ensemble Based Approach For IntrusionDocument8 pagesEnsemble Based Approach For IntrusionKurniabudi ZaimarNo ratings yet
- Enhanced Network Anomaly Detection Based On Deep Neural NetworksDocument16 pagesEnhanced Network Anomaly Detection Based On Deep Neural NetworksYishak TadeleNo ratings yet
- Evaluating Machine Learning Algorithms F-1Document6 pagesEvaluating Machine Learning Algorithms F-1keerthiksNo ratings yet
- 1 s2.0 S2405609X15300300 MainDocument11 pages1 s2.0 S2405609X15300300 MaingmgaargiNo ratings yet
- Feature Selection and Comparison of Classifcation AlgorithmsDocument13 pagesFeature Selection and Comparison of Classifcation AlgorithmsankeeonlineNo ratings yet
- Intrusion Detection Using Big Data and Deep Learning TechniquesDocument9 pagesIntrusion Detection Using Big Data and Deep Learning TechniquesumarjavedNo ratings yet
- IET Communications - 2020 - Safara - Improved Intrusion Detection Method For Communication Networks Using Association RuleDocument6 pagesIET Communications - 2020 - Safara - Improved Intrusion Detection Method For Communication Networks Using Association RuleAqeel AlbahriNo ratings yet
- Ali 2018Document7 pagesAli 2018ahmedsaeedobiedNo ratings yet
- Artificial Neural Networks Optimized With Unsupervised Clustering For IDS ClassificationDocument7 pagesArtificial Neural Networks Optimized With Unsupervised Clustering For IDS ClassificationNewbiew PalsuNo ratings yet
- Evolving Dynamic Fuzzy Clustering (EDFC) To Enhance DRDoS - DNS AttacksDocument12 pagesEvolving Dynamic Fuzzy Clustering (EDFC) To Enhance DRDoS - DNS AttacksAli ALsaeediNo ratings yet
- 8478457Document13 pages8478457Zinia Anzum TonniNo ratings yet
- IDS in Telecommunication Network Using PCADocument11 pagesIDS in Telecommunication Network Using PCAAIRCC - IJCNCNo ratings yet
- Dimensionality Reduction With IG PCA and Ensemble Classifier - 2019 - Computer NDocument12 pagesDimensionality Reduction With IG PCA and Ensemble Classifier - 2019 - Computer NVian AlfalahNo ratings yet
- Network Intrusion Detection System Using Federated Machine Learning ApproachDocument8 pagesNetwork Intrusion Detection System Using Federated Machine Learning ApproachInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Building Auto-Encoder Intrusion Detection System Based On RandomDocument15 pagesBuilding Auto-Encoder Intrusion Detection System Based On Random21020028 Trần Quang TàiNo ratings yet
- Intelligent IdsDocument12 pagesIntelligent IdsyasserNo ratings yet
- Smart Intrusion Detection System ComprisDocument6 pagesSmart Intrusion Detection System ComprisfitsumNo ratings yet
- 1 s2.0 S2666285X21000947 MainDocument6 pages1 s2.0 S2666285X21000947 Mainder kochNo ratings yet
- Measuring of Data Quality in KYC Using Anomaly DetDocument7 pagesMeasuring of Data Quality in KYC Using Anomaly DetberhanNo ratings yet
- Comparison of Single and Ensemble Intrusion Detection Techniques Using Multiple DatasetsDocument10 pagesComparison of Single and Ensemble Intrusion Detection Techniques Using Multiple DatasetsWARSE JournalsNo ratings yet
- DattaDeshmukhecs 2014 6892542Document7 pagesDattaDeshmukhecs 2014 6892542Rohit MajumderNo ratings yet
- Enhanced Intrusion Detection System UsinDocument8 pagesEnhanced Intrusion Detection System UsinyonasNo ratings yet
- Topic 3Document12 pagesTopic 3swathi thotaNo ratings yet
- Paper 75-Detecting Generic Network Intrusion AttacksDocument8 pagesPaper 75-Detecting Generic Network Intrusion AttacksKhalid SyfullahNo ratings yet
- A Novel Feature Selection Approach For Intrusion Detection Data ClassificationDocument9 pagesA Novel Feature Selection Approach For Intrusion Detection Data ClassificationGururaja Hebbur SatyanarayanaNo ratings yet
- 1 s2.0 S0167404824000312 MainDocument9 pages1 s2.0 S0167404824000312 MaindaytdeenNo ratings yet
- Network Intrusion Detection Using Supervised Machine Learning Technique With Feature SelectionDocument4 pagesNetwork Intrusion Detection Using Supervised Machine Learning Technique With Feature SelectionShahid AzeemNo ratings yet
- Sarnovsky and Paralic - 2020 - Hierarchical Intrusion Detection Using Machine LeaDocument14 pagesSarnovsky and Paralic - 2020 - Hierarchical Intrusion Detection Using Machine LeaabirrazaNo ratings yet
- Ensemble Models For Intrusion Detection System ClassificationDocument15 pagesEnsemble Models For Intrusion Detection System ClassificationKurniabudi ZaimarNo ratings yet
- Intrusion Detection System Using Gradient Boosted Trees For VANETsDocument7 pagesIntrusion Detection System Using Gradient Boosted Trees For VANETsIJRASETPublicationsNo ratings yet
- A Review of Intrusion Detection System Using Machine Learning ApproachDocument8 pagesA Review of Intrusion Detection System Using Machine Learning Approachrushendra.umbNo ratings yet
- Research Paper 1Document7 pagesResearch Paper 1Meenakshi AryaNo ratings yet
- DB-OLS: An Approach For IDS1Document10 pagesDB-OLS: An Approach For IDS1ijp2pjournalNo ratings yet
- Data Mining Techniques and ApplicationsDocument6 pagesData Mining Techniques and ApplicationsIJRASETPublicationsNo ratings yet
- Proposed Algorithm Base Optimization Scheme For Intrusion Detection Using Feature SelectionDocument9 pagesProposed Algorithm Base Optimization Scheme For Intrusion Detection Using Feature SelectionInternational Journal of Advances in Applied Sciences (IJAAS)No ratings yet
- InfoSec Project ReportDocument7 pagesInfoSec Project ReporteishafarrukhNo ratings yet
- A Literature Review-Acceptance Models For E-Learning Implementation in Higher InstitutionDocument19 pagesA Literature Review-Acceptance Models For E-Learning Implementation in Higher InstitutionKurniabudi ZaimarNo ratings yet
- Optimizing Cybersecurity Attack Detection in Computer Networks 2Document6 pagesOptimizing Cybersecurity Attack Detection in Computer Networks 2NahidaNigarNo ratings yet
- 4768-Article Text-8889-1-10-20210501Document8 pages4768-Article Text-8889-1-10-20210501sumit.rksNo ratings yet
- SeguridadDocument29 pagesSeguridadandres pythonNo ratings yet
- Statistical Performance Assessment of Supervised Machine Learning Algorithms For Intrusion Detection SystemDocument12 pagesStatistical Performance Assessment of Supervised Machine Learning Algorithms For Intrusion Detection SystemIAES IJAINo ratings yet
- Innovative Machine Learning Algorithms For Classification and Intrusion DetectionDocument6 pagesInnovative Machine Learning Algorithms For Classification and Intrusion DetectionInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Intrusion Detection Systems: Principles and Perspectives: November 2018Document6 pagesIntrusion Detection Systems: Principles and Perspectives: November 2018skamelNo ratings yet
- A Comparison Study For Intrusion Database (KDD99, NSL-KDD) Based On Self Organization Map (SOM) Artificial Neural NetworkDocument14 pagesA Comparison Study For Intrusion Database (KDD99, NSL-KDD) Based On Self Organization Map (SOM) Artificial Neural Networkhanifa pramanaNo ratings yet
- Tisa Random FileDocument23 pagesTisa Random Filedaenieltan2No ratings yet
- Acharya, Toya Khatri, Ishan Annamalai, Annamalai Chouikha, Mohamed F (2021)Document7 pagesAcharya, Toya Khatri, Ishan Annamalai, Annamalai Chouikha, Mohamed F (2021)soutien104No ratings yet
- A Study On Prediction Techniques of Data Mining in Educational DomainDocument4 pagesA Study On Prediction Techniques of Data Mining in Educational DomainijcnesNo ratings yet
- Malware Detection Using Machine LearningDocument5 pagesMalware Detection Using Machine LearningInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Paper 2-Application of Machine Learning Approaches in Intrusion Detection SystemDocument10 pagesPaper 2-Application of Machine Learning Approaches in Intrusion Detection SystemIbrahim qashtaNo ratings yet
- Vol 8 No 0103Document5 pagesVol 8 No 0103RAGHAVENDRA SAINo ratings yet
- Convolutional Neural Networks With LSTM For Intrusion DetectionDocument11 pagesConvolutional Neural Networks With LSTM For Intrusion DetectionAqeel AlbahriNo ratings yet
- 1 s2.0 S2212017312002964 MainDocument10 pages1 s2.0 S2212017312002964 MainGautham Krishna KbNo ratings yet
- Intrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (Ids) Development Using Tree - Based Machine Learning AlgorithmsAIRCC - IJCNCNo ratings yet
- Intrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsDocument17 pagesIntrusion Detection System (IDS) Development Using Tree-Based Machine Learning AlgorithmsAIRCC - IJCNCNo ratings yet
- Mixture Models and ApplicationsFrom EverandMixture Models and ApplicationsNizar BouguilaNo ratings yet
- A SDR-based Verification Platform For 802.11 PHY Layer Security AuthenticationDocument24 pagesA SDR-based Verification Platform For 802.11 PHY Layer Security AuthenticationEDGAR RODRIGO NAULA LOPEZNo ratings yet
- A Nationwide Census On Wifi Security Threats: Prevalence, Riskiness, and The EconomicsDocument14 pagesA Nationwide Census On Wifi Security Threats: Prevalence, Riskiness, and The EconomicsEDGAR RODRIGO NAULA LOPEZNo ratings yet
- Ensemble Classifiers For Network Intrusion Detection System: July 2009Document10 pagesEnsemble Classifiers For Network Intrusion Detection System: July 2009EDGAR RODRIGO NAULA LOPEZNo ratings yet
- Intrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and A Public DatasetDocument26 pagesIntrusion Detection in 802.11 Networks: Empirical Evaluation of Threats and A Public DatasetEDGAR RODRIGO NAULA LOPEZ100% (1)
- Au Coe QP: Question Paper CodeDocument2 pagesAu Coe QP: Question Paper CodePeter ParkerNo ratings yet
- Lovell AE 362 Lecture Slides #9Document11 pagesLovell AE 362 Lecture Slides #9cantkillthemetalNo ratings yet
- Mte 10Document10 pagesMte 10VipinNo ratings yet
- X.509 Certificates: R.Muthukkumar Asst - Prof. (SG) /IT NEC, KovilpattiDocument25 pagesX.509 Certificates: R.Muthukkumar Asst - Prof. (SG) /IT NEC, KovilpattiRmkumarsNo ratings yet
- Random Number Generators1Document26 pagesRandom Number Generators1Scribd JdjNo ratings yet
- 12 Further Mathematics Time Series Exam PracticeDocument5 pages12 Further Mathematics Time Series Exam PracticeJordan TassoneNo ratings yet
- Wavelet TransformDocument28 pagesWavelet TransformShimaa Barakat100% (1)
- Digital Signal Processing First Global Edition Full ChapterDocument41 pagesDigital Signal Processing First Global Edition Full Chaptertommy.kondracki100100% (27)
- CSE3013-Artificial Intelligence CAT1 E1 Slot Section - ADocument4 pagesCSE3013-Artificial Intelligence CAT1 E1 Slot Section - AVIT ONLINE COURSESNo ratings yet
- GARCH Parameter Estimation by Machine LearningDocument4 pagesGARCH Parameter Estimation by Machine Learningdaniel18ctNo ratings yet
- Workshop 1Document16 pagesWorkshop 1kakakkawaiiNo ratings yet
- Segmentation and Decision - Tree in SasDocument2 pagesSegmentation and Decision - Tree in SasWanohiNo ratings yet
- Introduction To Second Quantization: 1.1 Single-Particle Hilbert SpaceDocument6 pagesIntroduction To Second Quantization: 1.1 Single-Particle Hilbert Space김띵No ratings yet
- Ai, ML, DL PDFDocument2 pagesAi, ML, DL PDFsetiawan.hadiNo ratings yet
- AIML Lab ManualDocument41 pagesAIML Lab Manualheartyhome.inNo ratings yet
- Miao, Jianjun: Economic Dynamics in Discrete TimeDocument4 pagesMiao, Jianjun: Economic Dynamics in Discrete TimeMiguel OrrilloNo ratings yet
- Factorial ExperimentsDocument17 pagesFactorial ExperimentsHrithik SenNo ratings yet
- Linear System Equations: Mongi BLEL King Saud UniversityDocument24 pagesLinear System Equations: Mongi BLEL King Saud UniversityazizNo ratings yet
- Weightage of Marks in GATE Physics PDFDocument1 pageWeightage of Marks in GATE Physics PDFPankaj GuptaNo ratings yet
- Assignment#2 Image ProcessingDocument5 pagesAssignment#2 Image Processingpradeep GNo ratings yet
- Unit 7 - Week 6: Assignment 6Document4 pagesUnit 7 - Week 6: Assignment 6Raushan KashyapNo ratings yet
- Verification and Validation in CFD and Heat Transfer: ANSYS Practice and The New ASME StandardDocument22 pagesVerification and Validation in CFD and Heat Transfer: ANSYS Practice and The New ASME StandardMaxim100% (1)
- Unit 3 MLDocument28 pagesUnit 3 MLSrujana ShettyNo ratings yet
- Algorithm and FlowchartDocument16 pagesAlgorithm and FlowchartSarah Mae GonzalesNo ratings yet
- A Secure Electronic Transaction Payment Protocol DDocument9 pagesA Secure Electronic Transaction Payment Protocol DVukašin KolarevićNo ratings yet
- Partial Solutions To Exercises 2.2Document4 pagesPartial Solutions To Exercises 2.2Luhan ZhaoNo ratings yet
- WUT - M.sc. Artificial IntelligenceDocument3 pagesWUT - M.sc. Artificial IntelligenceSujeendran MenonNo ratings yet