
Genomics: James M. Heather, Benjamin Chain
Genomics: James M. Heather, Benjamin Chain
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- NCS-DM Type 2 For Case PresentationDocument49 pagesNCS-DM Type 2 For Case Presentationadnelg0771% (7)
- Road To The Moon - A Great Occult Story - DR George W CareyDocument30 pagesRoad To The Moon - A Great Occult Story - DR George W CareyBret Trismegistus100% (4)
- Public Gdcmassbookdig Gramaticacomplet00stap Gramaticacomplet00stapDocument284 pagesPublic Gdcmassbookdig Gramaticacomplet00stap Gramaticacomplet00stapalanbecker_alNo ratings yet
- Pathogens 11 00663Document13 pagesPathogens 11 00663alanbecker_alNo ratings yet
- DiosgeninaDocument15 pagesDiosgeninaalanbecker_alNo ratings yet
- Molecules: Middle Eastern Plant Extracts: An Alternative To Modern Medicine ProblemsDocument19 pagesMolecules: Middle Eastern Plant Extracts: An Alternative To Modern Medicine Problemsalanbecker_alNo ratings yet
- Molecules: Chemistry and Reactivity of Tannins in Vitis SPP.: A ReviewDocument24 pagesMolecules: Chemistry and Reactivity of Tannins in Vitis SPP.: A Reviewalanbecker_alNo ratings yet
- Gamma SitosterolDocument7 pagesGamma Sitosterolalanbecker_alNo ratings yet
- Phytochemical Screening and Biological ActivitiesDocument6 pagesPhytochemical Screening and Biological Activitiesalanbecker_alNo ratings yet
- Molecules: Antibacterial Prodrugs To Overcome Bacterial ResistanceDocument16 pagesMolecules: Antibacterial Prodrugs To Overcome Bacterial Resistancealanbecker_alNo ratings yet
- Molecules: NMR-Based Plant Metabolomics in Nutraceutical Research: An OverviewDocument22 pagesMolecules: NMR-Based Plant Metabolomics in Nutraceutical Research: An Overviewalanbecker_alNo ratings yet
- E Coli 2016Document27 pagesE Coli 2016alanbecker_alNo ratings yet
- Fitoquimica 1Document5 pagesFitoquimica 1alanbecker_alNo ratings yet
- Antibaterial, Concentracion Minima Inhibitoria de Extractos de LarvasDocument8 pagesAntibaterial, Concentracion Minima Inhibitoria de Extractos de Larvasalanbecker_alNo ratings yet
- Antimicrobial ActivityDocument7 pagesAntimicrobial Activityalanbecker_alNo ratings yet
- Pharmacy Customers' Knowledge of Side Effects of Purchased Medicines in MexicoDocument8 pagesPharmacy Customers' Knowledge of Side Effects of Purchased Medicines in Mexicoalanbecker_alNo ratings yet
- Plantas de PakistanDocument17 pagesPlantas de Pakistanalanbecker_alNo ratings yet
- đề 1Document11 pagesđề 1Hải PhươngNo ratings yet
- Science Magazine 5694 2004-10-08 PDFDocument89 pagesScience Magazine 5694 2004-10-08 PDFTân ChipNo ratings yet
- Assessment Diagnosis Scientific Reason Planning Intervention Rational E EvaluationDocument2 pagesAssessment Diagnosis Scientific Reason Planning Intervention Rational E EvaluationCamille VirayNo ratings yet
- Ahar Parinamkar BhavDocument9 pagesAhar Parinamkar BhavDr Prajakta BNo ratings yet
- Nat 5 Biology SQ App 2019Document48 pagesNat 5 Biology SQ App 2019muntazNo ratings yet
- Rationale: Answer: C. If A Patient HasDocument12 pagesRationale: Answer: C. If A Patient HasNur SanaaniNo ratings yet
- Tensile Test of Copper Fibers in Conformance With ASTM C1557 Using Agilent UTM T150Document4 pagesTensile Test of Copper Fibers in Conformance With ASTM C1557 Using Agilent UTM T150Celeste LopezNo ratings yet
- Introduction (Recovered)Document37 pagesIntroduction (Recovered)muhamedshuaibbhaiNo ratings yet
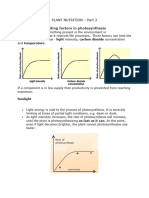
- PLANT NUTRITION Part 2Document10 pagesPLANT NUTRITION Part 2dineo kabasiaNo ratings yet
- The Fundamental Unit of LifeDocument16 pagesThe Fundamental Unit of LifeSriram RNo ratings yet
- ĐỀ TỰ LUYỆN SỐ 2 KEYDocument9 pagesĐỀ TỰ LUYỆN SỐ 2 KEYYinnieNo ratings yet
- Hypothalamus 2004Document9 pagesHypothalamus 2004Deepak MainiNo ratings yet
- Reading Comprehension Test Submitted By: Panicha Vongthoytong (Por) /1001Document5 pagesReading Comprehension Test Submitted By: Panicha Vongthoytong (Por) /1001api-327731606No ratings yet
- Dental PlaqueDocument93 pagesDental Plaquebhasalepooja100% (1)
- 2.01 Medical Term PrefixesDocument60 pages2.01 Medical Term PrefixesNicholas FerroniNo ratings yet
- Connecting Chemistry To Our WorldDocument8 pagesConnecting Chemistry To Our WorldjyclynnnNo ratings yet
- Bioenergetics Photosynthesis and Energy FlowDocument4 pagesBioenergetics Photosynthesis and Energy Flowvin ocangNo ratings yet
- Nickel (II) Sulfate - Wikipedia, The Free EncyclopediaDocument3 pagesNickel (II) Sulfate - Wikipedia, The Free EncyclopediaPriyanshYadavNo ratings yet
- Grp.2 DNA REPLICATION EMERALDDocument48 pagesGrp.2 DNA REPLICATION EMERALDLinda Ann BacunadorNo ratings yet
- Determining Soil FertilityDocument5 pagesDetermining Soil FertilityRenDenverL.DequiñaIINo ratings yet
- New English Sba 2018Document15 pagesNew English Sba 2018ashawni patterson88% (8)
- Sybiotic Architecture - Architecture of The In-BetweenDocument28 pagesSybiotic Architecture - Architecture of The In-BetweenAbhishek PatraNo ratings yet
- Pgem-T and Pgem-T Easy Vector Systems ProtocolDocument29 pagesPgem-T and Pgem-T Easy Vector Systems ProtocolAprilia Isma DenilaNo ratings yet
- Classification of OrganismDocument35 pagesClassification of OrganismJnll JstnNo ratings yet
- Human Blood GroupsDocument12 pagesHuman Blood GroupsAme Roxan AwidNo ratings yet
- Skin Conditions Worksheet 2017Document3 pagesSkin Conditions Worksheet 2017Tamia WatsonNo ratings yet
- Yeast Pop. LabDocument3 pagesYeast Pop. Labtanu96tp5952No ratings yet
- Indigenous Sea Country PDFDocument196 pagesIndigenous Sea Country PDFsamu2-4uNo ratings yet




















































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5825)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (903)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- NCS-DM Type 2 For Case PresentationDocument49 pagesNCS-DM Type 2 For Case Presentationadnelg0771% (7)
- Road To The Moon - A Great Occult Story - DR George W CareyDocument30 pagesRoad To The Moon - A Great Occult Story - DR George W CareyBret Trismegistus100% (4)
- Public Gdcmassbookdig Gramaticacomplet00stap Gramaticacomplet00stapDocument284 pagesPublic Gdcmassbookdig Gramaticacomplet00stap Gramaticacomplet00stapalanbecker_alNo ratings yet
- Pathogens 11 00663Document13 pagesPathogens 11 00663alanbecker_alNo ratings yet
- DiosgeninaDocument15 pagesDiosgeninaalanbecker_alNo ratings yet
- Molecules: Middle Eastern Plant Extracts: An Alternative To Modern Medicine ProblemsDocument19 pagesMolecules: Middle Eastern Plant Extracts: An Alternative To Modern Medicine Problemsalanbecker_alNo ratings yet
- Molecules: Chemistry and Reactivity of Tannins in Vitis SPP.: A ReviewDocument24 pagesMolecules: Chemistry and Reactivity of Tannins in Vitis SPP.: A Reviewalanbecker_alNo ratings yet
- Gamma SitosterolDocument7 pagesGamma Sitosterolalanbecker_alNo ratings yet
- Phytochemical Screening and Biological ActivitiesDocument6 pagesPhytochemical Screening and Biological Activitiesalanbecker_alNo ratings yet
- Molecules: Antibacterial Prodrugs To Overcome Bacterial ResistanceDocument16 pagesMolecules: Antibacterial Prodrugs To Overcome Bacterial Resistancealanbecker_alNo ratings yet
- Molecules: NMR-Based Plant Metabolomics in Nutraceutical Research: An OverviewDocument22 pagesMolecules: NMR-Based Plant Metabolomics in Nutraceutical Research: An Overviewalanbecker_alNo ratings yet
- E Coli 2016Document27 pagesE Coli 2016alanbecker_alNo ratings yet
- Fitoquimica 1Document5 pagesFitoquimica 1alanbecker_alNo ratings yet
- Antibaterial, Concentracion Minima Inhibitoria de Extractos de LarvasDocument8 pagesAntibaterial, Concentracion Minima Inhibitoria de Extractos de Larvasalanbecker_alNo ratings yet
- Antimicrobial ActivityDocument7 pagesAntimicrobial Activityalanbecker_alNo ratings yet
- Pharmacy Customers' Knowledge of Side Effects of Purchased Medicines in MexicoDocument8 pagesPharmacy Customers' Knowledge of Side Effects of Purchased Medicines in Mexicoalanbecker_alNo ratings yet
- Plantas de PakistanDocument17 pagesPlantas de Pakistanalanbecker_alNo ratings yet
- đề 1Document11 pagesđề 1Hải PhươngNo ratings yet
- Science Magazine 5694 2004-10-08 PDFDocument89 pagesScience Magazine 5694 2004-10-08 PDFTân ChipNo ratings yet
- Assessment Diagnosis Scientific Reason Planning Intervention Rational E EvaluationDocument2 pagesAssessment Diagnosis Scientific Reason Planning Intervention Rational E EvaluationCamille VirayNo ratings yet
- Ahar Parinamkar BhavDocument9 pagesAhar Parinamkar BhavDr Prajakta BNo ratings yet
- Nat 5 Biology SQ App 2019Document48 pagesNat 5 Biology SQ App 2019muntazNo ratings yet
- Rationale: Answer: C. If A Patient HasDocument12 pagesRationale: Answer: C. If A Patient HasNur SanaaniNo ratings yet
- Tensile Test of Copper Fibers in Conformance With ASTM C1557 Using Agilent UTM T150Document4 pagesTensile Test of Copper Fibers in Conformance With ASTM C1557 Using Agilent UTM T150Celeste LopezNo ratings yet
- Introduction (Recovered)Document37 pagesIntroduction (Recovered)muhamedshuaibbhaiNo ratings yet
- PLANT NUTRITION Part 2Document10 pagesPLANT NUTRITION Part 2dineo kabasiaNo ratings yet
- The Fundamental Unit of LifeDocument16 pagesThe Fundamental Unit of LifeSriram RNo ratings yet
- ĐỀ TỰ LUYỆN SỐ 2 KEYDocument9 pagesĐỀ TỰ LUYỆN SỐ 2 KEYYinnieNo ratings yet
- Hypothalamus 2004Document9 pagesHypothalamus 2004Deepak MainiNo ratings yet
- Reading Comprehension Test Submitted By: Panicha Vongthoytong (Por) /1001Document5 pagesReading Comprehension Test Submitted By: Panicha Vongthoytong (Por) /1001api-327731606No ratings yet
- Dental PlaqueDocument93 pagesDental Plaquebhasalepooja100% (1)
- 2.01 Medical Term PrefixesDocument60 pages2.01 Medical Term PrefixesNicholas FerroniNo ratings yet
- Connecting Chemistry To Our WorldDocument8 pagesConnecting Chemistry To Our WorldjyclynnnNo ratings yet
- Bioenergetics Photosynthesis and Energy FlowDocument4 pagesBioenergetics Photosynthesis and Energy Flowvin ocangNo ratings yet
- Nickel (II) Sulfate - Wikipedia, The Free EncyclopediaDocument3 pagesNickel (II) Sulfate - Wikipedia, The Free EncyclopediaPriyanshYadavNo ratings yet
- Grp.2 DNA REPLICATION EMERALDDocument48 pagesGrp.2 DNA REPLICATION EMERALDLinda Ann BacunadorNo ratings yet
- Determining Soil FertilityDocument5 pagesDetermining Soil FertilityRenDenverL.DequiñaIINo ratings yet
- New English Sba 2018Document15 pagesNew English Sba 2018ashawni patterson88% (8)
- Sybiotic Architecture - Architecture of The In-BetweenDocument28 pagesSybiotic Architecture - Architecture of The In-BetweenAbhishek PatraNo ratings yet
- Pgem-T and Pgem-T Easy Vector Systems ProtocolDocument29 pagesPgem-T and Pgem-T Easy Vector Systems ProtocolAprilia Isma DenilaNo ratings yet
- Classification of OrganismDocument35 pagesClassification of OrganismJnll JstnNo ratings yet
- Human Blood GroupsDocument12 pagesHuman Blood GroupsAme Roxan AwidNo ratings yet
- Skin Conditions Worksheet 2017Document3 pagesSkin Conditions Worksheet 2017Tamia WatsonNo ratings yet
- Yeast Pop. LabDocument3 pagesYeast Pop. Labtanu96tp5952No ratings yet
- Indigenous Sea Country PDFDocument196 pagesIndigenous Sea Country PDFsamu2-4uNo ratings yet