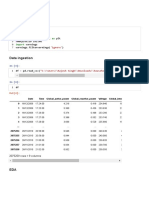
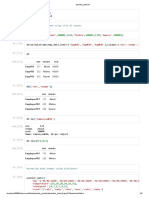
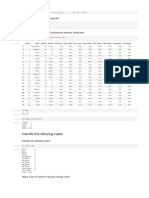
Download as pdf or txt
You might also like
- Tax Opinion PDFDocument8 pagesTax Opinion PDFclaoctavianoNo ratings yet
- Problem Statement (Tableau - Graded Project)Document2 pagesProblem Statement (Tableau - Graded Project)Kaustav De0% (1)
- Leer Los Datos: Import As Import As Import As From Import From ImportDocument14 pagesLeer Los Datos: Import As Import As Import As From Import From ImportRicardo Sebastian100% (1)
- Scrib 2Document4 pagesScrib 2Aldwin Abidin50% (2)
- FRA Milestone 1 Jupyter Notebook PDFDocument42 pagesFRA Milestone 1 Jupyter Notebook PDFSravan100% (3)
- Assignment 11Document7 pagesAssignment 11ankit mahto100% (1)
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Advertising Data AnalysisDocument12 pagesAdvertising Data AnalysisVishal SharmaNo ratings yet
- Individual Household Electric Power ConsumptionDocument29 pagesIndividual Household Electric Power ConsumptionVISHAL SHARMANo ratings yet
- Covid-19 Prediction - Jupyter NotebookDocument6 pagesCovid-19 Prediction - Jupyter NotebookTEEGALAMEHERRITHWIK 122010320035No ratings yet
- Logistic Binary ClassificationDocument3 pagesLogistic Binary Classificationjaymehta1444No ratings yet
- Practical - 5 - 52Document4 pagesPractical - 5 - 52Royal EmpireNo ratings yet
- Load Prediction With 20 ModelsDocument19 pagesLoad Prediction With 20 ModelsdharamNo ratings yet
- Decision Tree Regressor and Ensemble Techniques - RegressorsDocument18 pagesDecision Tree Regressor and Ensemble Techniques - RegressorsS ANo ratings yet
- News Network AnalysisDocument23 pagesNews Network AnalysisKaartik ModiNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- GraphDocument4 pagesGraphRakesh M BNo ratings yet
- Graph 1Document4 pagesGraph 1Rakesh M BNo ratings yet
- Hasil RendiDocument11 pagesHasil RendiFitria KintaNo ratings yet
- Pro Yec To Machine LearningDocument35 pagesPro Yec To Machine LearningcredifamiliadesarrolloNo ratings yet
- Simple Linear regression-LAB4.ipynb - ColaboratoryDocument6 pagesSimple Linear regression-LAB4.ipynb - ColaboratoryPATTABHI RAMANJANEYULUNo ratings yet
- ETE-DIP SolutionDocument15 pagesETE-DIP SolutionANSHNo ratings yet
- Decision TreeDocument2 pagesDecision Treejaymehta1444No ratings yet
- DS-500 CCU Performance Analysis Via QSDocument7 pagesDS-500 CCU Performance Analysis Via QSRuslan CrabNo ratings yet
- Assignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Document7 pagesAssignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Manikanta Sai100% (1)
- Assignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Document7 pagesAssignment-7 (CSL5402) Name:-Kommireddy - Manikanta Sai Roll No: - 1906036 Branch: - CSE-1Manikanta Sai100% (1)
- 20bce2251 VL2021220503859 Ast02Document10 pages20bce2251 VL2021220503859 Ast02TANMAY MEHROTRANo ratings yet
- test_2Document11 pagestest_2benjaminxin11No ratings yet
- Ids Final SolDocument16 pagesIds Final SolHumayun RazaNo ratings yet
- #Creating Data Frame Using List of Tuples: Import As Import AsDocument3 pages#Creating Data Frame Using List of Tuples: Import As Import AsRamesh Kumar MojjadaNo ratings yet
- TrabajoDocument5 pagesTrabajoJAVIER OCHOANo ratings yet
- A Distance-Based Kernel For Classification Via Support Vector Machines - PMC-18Document1 pageA Distance-Based Kernel For Classification Via Support Vector Machines - PMC-18jefferyleclercNo ratings yet
- Utf-8''libraries Data ManagementDocument9 pagesUtf-8''libraries Data ManagementSarah MendesNo ratings yet
- Multivariate Linear RegressionDocument5 pagesMultivariate Linear Regressionjaymehta1444No ratings yet
- Fashion MNIST-6Document10 pagesFashion MNIST-6akif barbaros dikmenNo ratings yet
- Solution To 4.13Document5 pagesSolution To 4.13Niyati ShahNo ratings yet
- Data PreprocessingDocument5 pagesData Preprocessingvishalsharma24ytNo ratings yet
- EastWestAirlines ClusterDocument6 pagesEastWestAirlines ClusterNiranjana Menon100% (1)
- Glass ClassificationDocument3 pagesGlass ClassificationSiddharth Tiwari100% (2)
- ProjectDocument18 pagesProjectapi-525983464No ratings yet
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- Lab 5Document4 pagesLab 5Muhammad SalmanNo ratings yet
- Tarea 4Document6 pagesTarea 4Jonathan JiménezNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- ML Assignment 01Document1 pageML Assignment 01duawajih02No ratings yet
- Hysdkmedia TransDocument273 pagesHysdkmedia TransMuhammad IlhamNo ratings yet
- Logistic RegressionDocument8 pagesLogistic RegressionNipuniNo ratings yet
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- EDA - Session-4 - Numerical Data AnalysisDocument9 pagesEDA - Session-4 - Numerical Data Analysisjeeshu048No ratings yet
- Pandas PD: File PD Read - CSV File HeadDocument10 pagesPandas PD: File PD Read - CSV File HeadAbhijeet DubeyNo ratings yet
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (4)
- Import As Import As Import As: "Default - CSV"Document9 pagesImport As Import As Import As: "Default - CSV"growhigh007No ratings yet
- Estats: June 19, 2019Document33 pagesEstats: June 19, 2019Victor Mariano LeiteNo ratings yet
- Informe Tarea 3Document10 pagesInforme Tarea 3Miguel angel BarreroNo ratings yet
- Logistics RegressionDocument5 pagesLogistics RegressionNazakat ali100% (1)
- VaR & Python & BVCDocument4 pagesVaR & Python & BVCSiham Ait ima100% (1)
- Handle The Missing Value: Importing Pandas and Numpy LibsDocument4 pagesHandle The Missing Value: Importing Pandas and Numpy LibsAkshay PatilNo ratings yet
- Project Intern - Jupyter NotebookDocument16 pagesProject Intern - Jupyter NotebookruchitcsganeshNo ratings yet
- Decision Tree Algorithm in Machine LearningDocument13 pagesDecision Tree Algorithm in Machine LearningVasudevanNo ratings yet
- Bolted Joint 070506Document146 pagesBolted Joint 070506vijay10484No ratings yet
- 3.0 Data Analysis 3.3 Linpro: Figure 1: Truss'S Members and JointDocument12 pages3.0 Data Analysis 3.3 Linpro: Figure 1: Truss'S Members and Jointfuad haziqNo ratings yet
- KimlolDocument9 pagesKimlolMorello SiméonNo ratings yet
- Problem Statement - Graded Project: Variable DetailsDocument3 pagesProblem Statement - Graded Project: Variable DetailsKaustav De0% (1)
- Mahamana Ka Krititatva - Hi.enDocument2 pagesMahamana Ka Krititatva - Hi.enKaustav DeNo ratings yet
- Graded Quiz - SAS (Week 4) - Data Analysis Using SAS - Great LearningDocument6 pagesGraded Quiz - SAS (Week 4) - Data Analysis Using SAS - Great LearningKaustav DeNo ratings yet
- Recommendation Letter 2018Document1 pageRecommendation Letter 2018Kaustav DeNo ratings yet
- Dimension Alalysis AssingmentDocument5 pagesDimension Alalysis AssingmentKaustav DeNo ratings yet
- ANALYSIS OF STRESSES (Assignment#1)Document4 pagesANALYSIS OF STRESSES (Assignment#1)jowasa920533% (3)
- External Flows: Dr. Om Prakash Singh Asst. Prof., IIT MandiDocument37 pagesExternal Flows: Dr. Om Prakash Singh Asst. Prof., IIT MandiKaustav DeNo ratings yet
- Assignment-4: Course Code: BM-515Document2 pagesAssignment-4: Course Code: BM-515Kaustav DeNo ratings yet
- Online Course Reg 7th SemDocument1 pageOnline Course Reg 7th SemKaustav DeNo ratings yet
- Indian Institute of Technology (B.H.U.), VaranasiDocument2 pagesIndian Institute of Technology (B.H.U.), VaranasiKaustav DeNo ratings yet
- Kaustav de - Res19Document2 pagesKaustav de - Res19Kaustav DeNo ratings yet
- Conditional Health Monitoring of Gear Box Using Convolutional Neural NetworkDocument14 pagesConditional Health Monitoring of Gear Box Using Convolutional Neural NetworkKaustav DeNo ratings yet
- FinalDocument86 pagesFinalSunil RamchandaniNo ratings yet
- List of Instruments For 2nd Year BDSDocument17 pagesList of Instruments For 2nd Year BDSMohammad ShoebNo ratings yet
- Drift Analysis For Lateral Stability PDFDocument5 pagesDrift Analysis For Lateral Stability PDFadriano4850No ratings yet
- Lillian Cicerchia - Why Does Class MatterDocument26 pagesLillian Cicerchia - Why Does Class Matterdoraszujo1994No ratings yet
- Multiple Choice Questions: Chronic Obstructive Pulmonary Disease and Anaesthesia Anaesthesia For Awake CraniotomyDocument4 pagesMultiple Choice Questions: Chronic Obstructive Pulmonary Disease and Anaesthesia Anaesthesia For Awake CraniotomyEliza AmandoNo ratings yet
- Endless HaulageDocument6 pagesEndless Haulagedudealok100% (3)
- Advances Against SecuritiesDocument26 pagesAdvances Against SecuritiesSAMBIT SAHOONo ratings yet
- CLM TutorialDocument18 pagesCLM Tutorialrico.caballero7No ratings yet
- The SEPA Regulation GuidanceDocument23 pagesThe SEPA Regulation GuidanceBaatar SukhbaatarNo ratings yet
- All Cement Formulae PDFDocument163 pagesAll Cement Formulae PDFGanapathy SubramaniamNo ratings yet
- Synopsis On Wireless Power TransferDocument20 pagesSynopsis On Wireless Power TransferMohammed Arshad AliNo ratings yet
- Drdo 1Document28 pagesDrdo 1Basavaraj PatilNo ratings yet
- Eric Van Dyk: Professional SummaryDocument3 pagesEric Van Dyk: Professional SummaryEric Van DykNo ratings yet
- Security Threats To E-Business: BIT Noida 1Document73 pagesSecurity Threats To E-Business: BIT Noida 1Kanishk GuptaNo ratings yet
- Privacy by Design UK ICODocument18 pagesPrivacy by Design UK ICOJeremieNo ratings yet
- HR ReportDocument6 pagesHR ReportJulius EdillorNo ratings yet
- Project Course Report (Spintronics)Document16 pagesProject Course Report (Spintronics)Arvind RaoNo ratings yet
- Punjab Police: Recruitment For The Post of Police Constable in District Police Cadre of Punjab Police - 2023Document15 pagesPunjab Police: Recruitment For The Post of Police Constable in District Police Cadre of Punjab Police - 2023ishare digitalNo ratings yet
- Ex. 428 JEREMY L. KEATING RICHARD P. GIGLIOTTI and ALEXANDER J. MELEDocument18 pagesEx. 428 JEREMY L. KEATING RICHARD P. GIGLIOTTI and ALEXANDER J. MELEWai DaiNo ratings yet
- Scheduling Practice ProblemsDocument2 pagesScheduling Practice ProblemsM ThuNo ratings yet
- Conc. Folded SlabDocument17 pagesConc. Folded SlabBenedict CharlesNo ratings yet
- LNG Plant Process OverviewDocument23 pagesLNG Plant Process Overviewnoor hidayatiNo ratings yet
- Bokeh Cheat Sheet Python For Data Science: 3 Renderers & Visual CustomizationsDocument26 pagesBokeh Cheat Sheet Python For Data Science: 3 Renderers & Visual CustomizationsAyuro TechNo ratings yet
- Liquid Resins Additives - EmeaDocument59 pagesLiquid Resins Additives - Emearndsb.aopNo ratings yet
- Company Name State LocationDocument18 pagesCompany Name State LocationompatelNo ratings yet
- 15 Mark QuestionsDocument18 pages15 Mark QuestionsBigBoi100% (1)
- User's and Maintenance Manual: Franke Finland OyDocument19 pagesUser's and Maintenance Manual: Franke Finland OyRomário Caribé100% (1)
- AWS Certified Solutions Architect Professional Slides v2.0Document724 pagesAWS Certified Solutions Architect Professional Slides v2.0John Nguyen100% (1)