Download as pdf or txt
You might also like
- Fire Fighting System - P&IDDocument3 pagesFire Fighting System - P&IDAdetunji Taiwo100% (6)
- Jemine: (Edited by Laz Ekwueme) LiberamenteDocument3 pagesJemine: (Edited by Laz Ekwueme) LiberamenteSixtus Okoro100% (1)
- Marketing Mix: ProductDocument20 pagesMarketing Mix: ProductBao HoNo ratings yet
- Sunbeam: Instructor ManualDocument88 pagesSunbeam: Instructor ManualWill AsinNo ratings yet
- BS en 12350 7 2000 Testing Fresh Concrete Part 7 Air Content Pressure MethodsDocument19 pagesBS en 12350 7 2000 Testing Fresh Concrete Part 7 Air Content Pressure MethodsKayathiri100% (1)
- Good Presentation On Power TransformersDocument38 pagesGood Presentation On Power TransformersAdetunji TaiwoNo ratings yet
- Physics Annual PlanDocument60 pagesPhysics Annual Plan112233445566778899 998877665544332211100% (2)
- South Hampton Real Estate Market Activity ReportDocument19 pagesSouth Hampton Real Estate Market Activity ReportChris DowellNo ratings yet
- George WinstonDocument5 pagesGeorge WinstonrebekahsundayNo ratings yet
- 117 N Railroad Ave Petal MS 39465Document28 pages117 N Railroad Ave Petal MS 39465Nick DavisNo ratings yet
- ContactsDocument3,342 pagesContactsJoshColistraNo ratings yet
- Resume Bab 5 MSDMDocument2 pagesResume Bab 5 MSDMRahmat KurniawanNo ratings yet
- LALITHADocument6 pagesLALITHAjsanandkumar22No ratings yet
- Tabla de VerdadDocument1 pageTabla de VerdadErick HernándezNo ratings yet
- Intl Be 2018Document16 pagesIntl Be 2018ElenaCollantesBeltranNo ratings yet
- ArticleDocument9 pagesArticlemahboobeh hamzelooNo ratings yet
- Intimate CH: Recent XDocument3 pagesIntimate CH: Recent XChelsea BashfordNo ratings yet
- BS en 148 1 (1999) - Respiratory Protective Devices PDFDocument12 pagesBS en 148 1 (1999) - Respiratory Protective Devices PDFck19654840No ratings yet
- Male Reproductive System Study GuideDocument2 pagesMale Reproductive System Study Guideapi-306342919No ratings yet
- Quantum Chemistry II: Math Introduction: Albeiro Restrepo May 27, 2009Document6 pagesQuantum Chemistry II: Math Introduction: Albeiro Restrepo May 27, 2009Julieth MorenoNo ratings yet
- Dungeon Party Character SheetDocument1 pageDungeon Party Character SheetTh'kaalNo ratings yet
- Strategy Collection Demo PapersDocument5 pagesStrategy Collection Demo Papersapi-703107804No ratings yet
- Sistemas Críticos HVAC en La Industria FarmacéuticaDocument15 pagesSistemas Críticos HVAC en La Industria FarmacéuticaFRAJCO9248No ratings yet
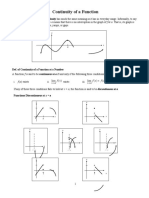
- Continuity Discontinuity of Functions (Revised 201819)Document5 pagesContinuity Discontinuity of Functions (Revised 201819)XXUnknown100% (1)
- Bs 6920 3 2000 - CompressDocument8 pagesBs 6920 3 2000 - CompressShwetha JayakumarNo ratings yet
- StatsticsDocument20 pagesStatsticshussenNo ratings yet
- Fill My Vision, Savior - SibDocument1 pageFill My Vision, Savior - SibwlamidoNo ratings yet
- D&D Dragons - JumpchainDocument93 pagesD&D Dragons - JumpchainVincent PerezNo ratings yet
- Piano Note 33Document12 pagesPiano Note 33icemeteorNo ratings yet
- Info Theory Co ClustDocument39 pagesInfo Theory Co Clustudin yomsNo ratings yet
- Go Cheese GujaratiDocument25 pagesGo Cheese Gujaratiadityajaju1685No ratings yet
- Solution 1Document6 pagesSolution 1Monica RicoNo ratings yet
- Walkthrough FezDocument42 pagesWalkthrough FezNacho Herrero RederNo ratings yet
- Httpssurokkha - Gov.bdmanagedownload Vaccine Card Birth Cert Reg111419211662291727Document1 pageHttpssurokkha - Gov.bdmanagedownload Vaccine Card Birth Cert Reg111419211662291727Naim Ahmed NaimNo ratings yet
- Analisis Foda Personal (1)Document1 pageAnalisis Foda Personal (1)I.E.S.T.P. HIPOLITO UNANUENo ratings yet
- Chord ChartDocument1 pageChord ChartCube StudioNo ratings yet
- Murray Math LinesDocument49 pagesMurray Math LinesTopNo ratings yet
- 09.nitya Prarathana Slokas 8th AvasanamDocument13 pages09.nitya Prarathana Slokas 8th AvasanamjohnyboyNo ratings yet
- A To Koli Ji PDFDocument4 pagesA To Koli Ji PDFPacôme KEKENo ratings yet
- ADocument1 pageAMartinez RrenyyNo ratings yet
- D Ef GH Ijk: PQR ST Uvwvxr Y Z (R R /) - ' Ab VC WR TC Tqde' Tfxec WVC ' E - SXR ( - G VWVXR HDocument7 pagesD Ef GH Ijk: PQR ST Uvwvxr Y Z (R R /) - ' Ab VC WR TC Tqde' Tfxec WVC ' E - SXR ( - G VWVXR HPa_3ANo ratings yet
- Lecture 1.1 - Single StatesDocument49 pagesLecture 1.1 - Single Stateshu jackNo ratings yet
- Truth TableDocument8 pagesTruth TableKartu BaruNo ratings yet
- Murrey Math Study Notes - Part 1 Written By: Tim KruzelDocument29 pagesMurrey Math Study Notes - Part 1 Written By: Tim KruzelY Ammar IsmailNo ratings yet
- SaglamasıDocument2 pagesSaglamasıIlker YuksekNo ratings yet
- Murrey Math Is A Trading System For All EquitiesDocument27 pagesMurrey Math Is A Trading System For All Equitiesvito111100% (1)
- Correlation and RegressionDocument13 pagesCorrelation and RegressionVincent BelsoiNo ratings yet
- Hanuman Chalisa TeluguDocument2 pagesHanuman Chalisa Telugudevender_bharatha3284No ratings yet
- 2A.3 Lecture Slides8 HeteroskedasticityDocument20 pages2A.3 Lecture Slides8 HeteroskedasticityUti LitiesNo ratings yet
- 8th Grade - Prepositions of TimeDocument1 page8th Grade - Prepositions of TimeDespina Trajkova GochevskiNo ratings yet
- Date Deposit Withdraw LOT Pair Gross Profit Commision Nett Profit $30.00 Total BalanceDocument4 pagesDate Deposit Withdraw LOT Pair Gross Profit Commision Nett Profit $30.00 Total BalancezicareNo ratings yet
- Easy Peasy Level 1 Daily ChecklistDocument6 pagesEasy Peasy Level 1 Daily ChecklistBrandon DvorakNo ratings yet
- By: Doron ShadmiDocument16 pagesBy: Doron ShadmiDoronShadmiNo ratings yet
- Mock Trial Week 2-5 WorkbookDocument16 pagesMock Trial Week 2-5 Workbookimanigi40No ratings yet
- 1 Algebra of State Vectors: 1.1 Inner ProductDocument9 pages1 Algebra of State Vectors: 1.1 Inner ProductAbrar Ul HaqNo ratings yet
- NF Specialties, LLC. All Rights Reserved Worldwide.: Form Rev: Orig FrontDocument2 pagesNF Specialties, LLC. All Rights Reserved Worldwide.: Form Rev: Orig FrontJeeva Raj JatNo ratings yet
- Description: Tags: Tabn144Document2 pagesDescription: Tags: Tabn144anon-290375No ratings yet
- REAKTOR PIK SDocument5 pagesREAKTOR PIK SDewiayunovNo ratings yet
- TPR-R Entrv. OnlineDocument12 pagesTPR-R Entrv. OnlineMacka Romy GPNo ratings yet
- TPR-R Entrv. OnlineDocument12 pagesTPR-R Entrv. OnlineMacka Romy GPNo ratings yet
- EM Manual Wall Design - 01Document1 pageEM Manual Wall Design - 01Manoj JaiswalNo ratings yet
- Lie Algebra and Representation of SU (4) : Mahmoud A. A. Sbaih, Moeen KH. Srour, M. S. Hamada and H. M. FayadDocument18 pagesLie Algebra and Representation of SU (4) : Mahmoud A. A. Sbaih, Moeen KH. Srour, M. S. Hamada and H. M. FayadRaul FraulNo ratings yet
- Practical LubricationDocument11 pagesPractical LubricationAdetunji TaiwoNo ratings yet
- Surge Arrestor Selection PDFDocument24 pagesSurge Arrestor Selection PDFAdetunji TaiwoNo ratings yet
- No.10 - Yard Service AirDocument1 pageNo.10 - Yard Service AirAdetunji TaiwoNo ratings yet
- Report On The Assessment of The Phase Two Export TransformerDocument1 pageReport On The Assessment of The Phase Two Export TransformerAdetunji TaiwoNo ratings yet
- Commissioning EngineerDocument5 pagesCommissioning EngineerAdetunji TaiwoNo ratings yet
- Report On The Assessment of The Phase Two Export TransformerDocument1 pageReport On The Assessment of The Phase Two Export TransformerAdetunji TaiwoNo ratings yet
- Relay Testing (Oc&ef Relay) PDFDocument4 pagesRelay Testing (Oc&ef Relay) PDFAdetunji TaiwoNo ratings yet
- Substation Design Guideliness PDFDocument40 pagesSubstation Design Guideliness PDFLimuel EspirituNo ratings yet
- 1 Organisational Structure of Electrical Workshop: 2.at A GlanceDocument7 pages1 Organisational Structure of Electrical Workshop: 2.at A GlanceAdetunji TaiwoNo ratings yet
- Underground Power Cable Insulation Lifetime Estimation MethodsDocument52 pagesUnderground Power Cable Insulation Lifetime Estimation MethodsAshroof AbdoNo ratings yet
- Vector Group of A Transformer PDFDocument4 pagesVector Group of A Transformer PDFAdetunji Taiwo0% (1)
- Theglobalworker PDFDocument60 pagesTheglobalworker PDFAdetunji TaiwoNo ratings yet
- Site Test Report For OVER CURRENT Relay (7SJ60XX) : Customer Contract # Project Job # Location Equipment TagDocument4 pagesSite Test Report For OVER CURRENT Relay (7SJ60XX) : Customer Contract # Project Job # Location Equipment TagAdetunji TaiwoNo ratings yet
- 6 2 Fuel Oil Tank Drawing PDFDocument1 page6 2 Fuel Oil Tank Drawing PDFAdetunji Taiwo100% (1)
- Surge Arrestor SelectionDocument24 pagesSurge Arrestor SelectionAdetunji TaiwoNo ratings yet
- MiCOM P143Document59 pagesMiCOM P143Adetunji TaiwoNo ratings yet
- FloWEB - UM - UNICIG - R24 ENGDocument151 pagesFloWEB - UM - UNICIG - R24 ENGAdetunji Taiwo100% (2)
- 85 Ea e 78923 - 00Document16 pages85 Ea e 78923 - 00Adetunji TaiwoNo ratings yet
- 85 EA E 78035 - 00 Control RoomDocument31 pages85 EA E 78035 - 00 Control RoomAdetunji TaiwoNo ratings yet
- El Operation Concept Extract ExampleDocument1 pageEl Operation Concept Extract ExampleAdetunji TaiwoNo ratings yet
- Thompson Nadler Lount Judgmental BiasesDocument27 pagesThompson Nadler Lount Judgmental BiasesWazeerullah KhanNo ratings yet
- Treatment of Gestational Hypertension With Oral Labetalol and Methyldopa in Iraqi Pregnant WomenDocument9 pagesTreatment of Gestational Hypertension With Oral Labetalol and Methyldopa in Iraqi Pregnant WomenOmar Nassir MoftahNo ratings yet
- Homework 13.3.2024Document2 pagesHomework 13.3.2024vothaibinh2004No ratings yet
- VELNET-SOLNET Eliminador en AerosolDocument11 pagesVELNET-SOLNET Eliminador en AerosolantonioNo ratings yet
- LMP 400-401 430-431 Series: Maximum Working Pressure Up To 6 Mpa (60 Bar) - Flow Rate Up To 740 L/MinDocument12 pagesLMP 400-401 430-431 Series: Maximum Working Pressure Up To 6 Mpa (60 Bar) - Flow Rate Up To 740 L/MinChris BanksNo ratings yet
- PDF File 5Th Class Math Lesson PlanFor 8 WeeksDocument8 pagesPDF File 5Th Class Math Lesson PlanFor 8 WeeksGB SportsNo ratings yet
- IETE Template JRDocument7 pagesIETE Template JRAshish Kumar0% (1)
- Rabies: Dr. Paul Bartlett, MPH., DVM., PH.DDocument45 pagesRabies: Dr. Paul Bartlett, MPH., DVM., PH.DnfrnufaNo ratings yet
- Polyflex 201 EnglishDocument2 pagesPolyflex 201 EnglishcesarNo ratings yet
- Project Identification and SelectionDocument8 pagesProject Identification and SelectionSathish Jayakumar50% (6)
- Human EvolutionDocument10 pagesHuman Evolution11 E Harsh dagarNo ratings yet
- PPT-finalDocument21 pagesPPT-finalRamu KetkarNo ratings yet
- GR9 - Q4 - Lesson 1 - Motion in One DimensionDocument5 pagesGR9 - Q4 - Lesson 1 - Motion in One DimensionJerome HizonNo ratings yet
- Manual Bluetti Eb150Document12 pagesManual Bluetti Eb150Rafa Lozoya AlbacarNo ratings yet
- Company Introduction PDFDocument14 pagesCompany Introduction PDFJeff SmithNo ratings yet
- Uninformed Search Strategies (Section 3.4) : Source: FotoliaDocument46 pagesUninformed Search Strategies (Section 3.4) : Source: FotoliaMohid SiddiqiNo ratings yet
- Spare Parts Price List - DeluxeDocument13 pagesSpare Parts Price List - Deluxesrikanthsri4uNo ratings yet
- 4.-Revised-Tle-As-Css10-Q3-Disk ManagementDocument5 pages4.-Revised-Tle-As-Css10-Q3-Disk ManagementJonald SalinasNo ratings yet
- Java Array: Logic Formulation and Intro. To ProgrammingDocument9 pagesJava Array: Logic Formulation and Intro. To ProgrammingklintNo ratings yet
- Sri Mahila Griha Udyog Lijjat Papad: Strategic Management CourseDocument23 pagesSri Mahila Griha Udyog Lijjat Papad: Strategic Management CoursePrachit ChaturvediNo ratings yet
- Null 13Document4 pagesNull 13oreeditsemasilo85No ratings yet
- 600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaDocument32 pages600 ngữ pháp chọn lọc luyện thi THPT Quốc GiaNguyen Chi Cuong100% (1)
- Nursing DocumentationDocument3 pagesNursing DocumentationWidfdsafdsaNo ratings yet
- Spesifikasi Produk - Yumizen H500Document1 pageSpesifikasi Produk - Yumizen H500Dexa Arfindo PratamaNo ratings yet
- Rman Standby Copy-2Document8 pagesRman Standby Copy-2SHAHID FAROOQNo ratings yet
- Pengaruh Pendidikan Kesehatan Tentang Kekerasan DalamDocument10 pagesPengaruh Pendidikan Kesehatan Tentang Kekerasan DalamDhaveFebby PapuanaNo ratings yet
- SYNAGIS Example Letter of Medical NecessityDocument1 pageSYNAGIS Example Letter of Medical NecessitynpNo ratings yet