Download as pdf or txt
You might also like
- Lefkowitz v. Great Minneapolis Surplus StoreDocument1 pageLefkowitz v. Great Minneapolis Surplus StorecrlstinaaaNo ratings yet
- Drama ScriptDocument3 pagesDrama ScriptDiana Zaibi57% (7)
- Transtextuality KeynoteDocument29 pagesTranstextuality Keynotekunz_fabian75% (4)
- C2 W2 SoftMaxDocument7 pagesC2 W2 SoftMaxmr ceanNo ratings yet
- Fuzzy Algo UpdatedDocument8 pagesFuzzy Algo Updatednirmala periasamyNo ratings yet
- Evaluating Double IntegralsDocument12 pagesEvaluating Double IntegralsVinod MoganNo ratings yet
- Jablonsky 2015Document14 pagesJablonsky 2015anisbouzouita2005No ratings yet
- Banking Efficiency in China: Application of DEA and Tobit AnalysisDocument5 pagesBanking Efficiency in China: Application of DEA and Tobit AnalysisBereket Zerai GebremichaelNo ratings yet
- MLMC FounderDocument10 pagesMLMC FoundersaadonNo ratings yet
- MultivariableRegression SummaryDocument15 pagesMultivariableRegression SummaryAlada manaNo ratings yet
- Comparing Differentiable Logics For Learning Systems: A Research PreviewDocument13 pagesComparing Differentiable Logics For Learning Systems: A Research Previewmeyina4311No ratings yet
- Panel CookbookDocument98 pagesPanel CookbookMaruška VizekNo ratings yet
- Branch Wise Chhattisgarh Sankra 14 8 2022Document18 pagesBranch Wise Chhattisgarh Sankra 14 8 2022Aditya SharmaNo ratings yet
- GLM Lec 1Document7 pagesGLM Lec 1HazemIbrahimNo ratings yet
- Week 7 LectureDocument54 pagesWeek 7 LectureHANJING QUANNo ratings yet
- CIR CalibrationDocument8 pagesCIR CalibrationNicolas Lefevre-LaumonierNo ratings yet
- Week 9 Lecture NotesDocument7 pagesWeek 9 Lecture NotesIlhan YunusNo ratings yet
- Solutions 1Document17 pagesSolutions 1Eman AsemNo ratings yet
- Measuring The Efficiency of Production Units by AHP Models: Josef JablonskyDocument8 pagesMeasuring The Efficiency of Production Units by AHP Models: Josef Jablonskydelia2011No ratings yet
- Problem Set 7 Solution Numerical MethodsDocument12 pagesProblem Set 7 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- Test (MP3)Document6 pagesTest (MP3)Akshay BoraNo ratings yet
- Metrics WT 2023-24 Unit10 Ml+Discrete ChoiceDocument36 pagesMetrics WT 2023-24 Unit10 Ml+Discrete ChoicenoahroosNo ratings yet
- Julia MarkowitzDocument12 pagesJulia MarkowitzHugo RoqueNo ratings yet
- Matlab-Lecture 9 2018Document13 pagesMatlab-Lecture 9 2018berk1aslan2No ratings yet
- Prof. Richardson NeuralnetworksDocument61 pagesProf. Richardson NeuralnetworkschrissbansNo ratings yet
- Runge-Kutta Method: Lab Exercise 6Document15 pagesRunge-Kutta Method: Lab Exercise 6shriyaagupta18No ratings yet
- Matlab Code: 2.2 Exercises With Matlab 2.2.1 Standard Normal DistributionDocument8 pagesMatlab Code: 2.2 Exercises With Matlab 2.2.1 Standard Normal Distributionthomasgalaxy100% (1)
- Report#1Document11 pagesReport#1morris gichuhiNo ratings yet
- DP 2Document16 pagesDP 2KARTIKEY GARGNo ratings yet
- 42459Document11 pages42459Maher AliNo ratings yet
- Chapter 1 Introduction To Data MiningDocument10 pagesChapter 1 Introduction To Data MiningTsoi Yun PuiNo ratings yet
- Data Envelopment Analysis - TheoryDocument18 pagesData Envelopment Analysis - TheoryWei GuoNo ratings yet
- Random Number GenerationDocument42 pagesRandom Number GenerationNikhil AggarwalNo ratings yet
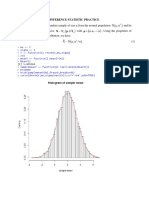
- C Inference Statistic With RDocument11 pagesC Inference Statistic With RLinh NguyễnNo ratings yet
- Maths - Construction of Fuzzy - Muhamediyeva Dilnoz TulkunovnaDocument14 pagesMaths - Construction of Fuzzy - Muhamediyeva Dilnoz TulkunovnaTJPRC PublicationsNo ratings yet
- Minimum Variance Portfolio Optimization in The Spiked Covariance ModelDocument4 pagesMinimum Variance Portfolio Optimization in The Spiked Covariance ModelAnonymous 8mDFImqaZVNo ratings yet
- Alternative Karnik-Mendel Algorithm For Interval Type-2 Type-ReductionDocument8 pagesAlternative Karnik-Mendel Algorithm For Interval Type-2 Type-ReductionGEDLERGNo ratings yet
- DGM 2023 EndtermDocument12 pagesDGM 2023 EndtermGhaith ChebilNo ratings yet
- PHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckDocument20 pagesPHD Econ, Applied Econometrics 2021/22 - Takehome University of InnsbruckKarim BekhtiarNo ratings yet
- Uso de Modelos de Eficiencia PDFDocument5 pagesUso de Modelos de Eficiencia PDFCarlos BlancoNo ratings yet
- Machine Learning - Home - Week 2 - Notes - CourseraDocument10 pagesMachine Learning - Home - Week 2 - Notes - CourseracopsamostoNo ratings yet
- Ordered Probit ModelDocument13 pagesOrdered Probit ModelSNKNo ratings yet
- International Journal of Pure and Applied Mathematics No. 4 2013, 435-450Document16 pagesInternational Journal of Pure and Applied Mathematics No. 4 2013, 435-450Tania BenadalidNo ratings yet
- Basic Number Theory-1: Tutorial ProblemsDocument10 pagesBasic Number Theory-1: Tutorial ProblemsdkitovNo ratings yet
- A New Formulation For Empirical Mode Decomposition Based On Constrained OptimizationDocument10 pagesA New Formulation For Empirical Mode Decomposition Based On Constrained OptimizationStoffelinusNo ratings yet
- Problem Set 3 Solution Numerical MethodsDocument11 pagesProblem Set 3 Solution Numerical MethodsAriyan JahanyarNo ratings yet
- Gretl Guide (401 450)Document50 pagesGretl Guide (401 450)Taha NajidNo ratings yet
- Optical Flow ComputationDocument4 pagesOptical Flow ComputationDonato FormicolaNo ratings yet
- Interpolation Methods: Paul BourkeDocument12 pagesInterpolation Methods: Paul BourkeTiểu Minh TháiNo ratings yet
- Data Envelopment Analysis: Priori Assumptions That Accompany OtherDocument27 pagesData Envelopment Analysis: Priori Assumptions That Accompany Othersanuri_snNo ratings yet
- Anomaly DetectionDocument7 pagesAnomaly DetectionRutvikNo ratings yet
- 4 Ijmcaraug20184Document10 pages4 Ijmcaraug20184TJPRC PublicationsNo ratings yet
- AAEC 6984 / SPRING 2014 Instructor: Klaus MoeltnerDocument9 pagesAAEC 6984 / SPRING 2014 Instructor: Klaus MoeltnerRenato Salazar RiosNo ratings yet
- HW1 SolDocument7 pagesHW1 SolprakshiNo ratings yet
- Unit3 NotesDocument29 pagesUnit3 NotesprassadyashwinNo ratings yet
- Unit3 CS8792 CNS Notes PECDocument26 pagesUnit3 CS8792 CNS Notes PECK ManeeshNo ratings yet
- Fuz2Y: The Relationship Between Goal Programming and Fuzzy ProgrammingDocument8 pagesFuz2Y: The Relationship Between Goal Programming and Fuzzy ProgrammingMaid OmerovicNo ratings yet
- A Discriminate Multidimensional Mapping For Small Sample DatabaseDocument9 pagesA Discriminate Multidimensional Mapping For Small Sample DatabaseSâm HoàngNo ratings yet
- Tema5 Teoria-2830Document57 pagesTema5 Teoria-2830Luis Alejandro Sanchez SanchezNo ratings yet
- Practice MidtermDocument4 pagesPractice MidtermArka MitraNo ratings yet
- 9.1 OptimizationDocument29 pages9.1 Optimizationabdul azizNo ratings yet
- Mathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsFrom EverandMathematics 1St First Order Linear Differential Equations 2Nd Second Order Linear Differential Equations Laplace Fourier Bessel MathematicsNo ratings yet
- For Students14Document9 pagesFor Students14sunil kumarNo ratings yet
- Ardl 1Document166 pagesArdl 1sunil kumarNo ratings yet
- Student Application4Document14 pagesStudent Application4sunil kumarNo ratings yet
- Bangla 4Document11 pagesBangla 4sunil kumarNo ratings yet
- Bangla 3Document9 pagesBangla 3sunil kumarNo ratings yet
- Joe Zhu Insuarnce ReviewDocument13 pagesJoe Zhu Insuarnce Reviewsunil kumarNo ratings yet
- Examining and Comparing DistributionsDocument62 pagesExamining and Comparing Distributionssunil kumarNo ratings yet
- The Measurement of Technical Efficiency: A Neural Network ApproachDocument11 pagesThe Measurement of Technical Efficiency: A Neural Network Approachsunil kumarNo ratings yet
- A New Network Data Envelopment Analysis Models To Measure The Efficiency of Natural Gas Supply ChainDocument26 pagesA New Network Data Envelopment Analysis Models To Measure The Efficiency of Natural Gas Supply Chainsunil kumarNo ratings yet
- Dynamic Analysis of The Relationship Between Stock Prices and Macroeconomic Variables: An Empirical Study of Pakistan Stock ExchangeDocument18 pagesDynamic Analysis of The Relationship Between Stock Prices and Macroeconomic Variables: An Empirical Study of Pakistan Stock Exchangesunil kumarNo ratings yet
- Elect 28Document6 pagesElect 28sunil kumarNo ratings yet
- Applied Economics LettersDocument6 pagesApplied Economics Letterssunil kumarNo ratings yet
- DEA Directional ClassDocument24 pagesDEA Directional Classsunil kumarNo ratings yet
- IJPPM - Best SubsetsDocument29 pagesIJPPM - Best Subsetssunil kumarNo ratings yet
- DEA For ClassDocument9 pagesDEA For Classsunil kumarNo ratings yet
- ARDL in RDocument23 pagesARDL in Rsunil kumarNo ratings yet
- Using of Composite Index in Measuring of Well-Being: Miroslav Hužvár, Alena KaščákováDocument13 pagesUsing of Composite Index in Measuring of Well-Being: Miroslav Hužvár, Alena Kaščákovásunil kumarNo ratings yet
- An Introduction To Benefit of The Doubt' Composite IndicatorsDocument36 pagesAn Introduction To Benefit of The Doubt' Composite Indicatorssunil kumarNo ratings yet
- Workpackage 5 Benefit of The Doubt' Composite Indicators: Deliverable 5.3Document23 pagesWorkpackage 5 Benefit of The Doubt' Composite Indicators: Deliverable 5.3sunil kumarNo ratings yet
- Bounds Testing Approach: An Examination of Foreign Direct Investment, Trade, and Growth RelationshipsDocument22 pagesBounds Testing Approach: An Examination of Foreign Direct Investment, Trade, and Growth Relationshipssunil kumarNo ratings yet
- Futility of Trying To Teach Everything of Importance - 220Document7 pagesFutility of Trying To Teach Everything of Importance - 220escandidadNo ratings yet
- Vocabulary Words Print It Out. Envelope. Blocks. Worksheets. BallDocument5 pagesVocabulary Words Print It Out. Envelope. Blocks. Worksheets. Ballapi-300889911No ratings yet
- Silahis Marketing Corp. v. IAC (1989)Document2 pagesSilahis Marketing Corp. v. IAC (1989)Fides DamascoNo ratings yet
- Teacher NetworkDocument8 pagesTeacher NetworkSaurav SinglaNo ratings yet
- Part-II Poem Article and Report For College Magazine-2015-16 Dr.M.Q. KhanDocument4 pagesPart-II Poem Article and Report For College Magazine-2015-16 Dr.M.Q. KhanTechi Son taraNo ratings yet
- NCM 108 - Bioethics - Chapter 4Document2 pagesNCM 108 - Bioethics - Chapter 4Rohoney LogronioNo ratings yet
- ADE 420 Spring 2015 Assignment #1 GuidelinesDocument2 pagesADE 420 Spring 2015 Assignment #1 Guidelinesapi-20975547No ratings yet
- Cerebral PalsyDocument36 pagesCerebral PalsyZulaikha Fadzil100% (1)
- History of Stereochemistry and EnantiomersDocument2 pagesHistory of Stereochemistry and EnantiomersMahru Antonio100% (1)
- CCNP Lab Questions:: AnswerDocument27 pagesCCNP Lab Questions:: Answerjakeandmis100% (1)
- Success Is in Our Own HandsDocument12 pagesSuccess Is in Our Own HandsEnp Gus AgostoNo ratings yet
- Assignment On Allegories in Fairie QueeneDocument5 pagesAssignment On Allegories in Fairie QueeneAltaf Sheikh100% (1)
- Thank You Jesus For The Blood Chords - Charity Gayle - E-ChordsDocument5 pagesThank You Jesus For The Blood Chords - Charity Gayle - E-Chordslahsee1No ratings yet
- Summary Standard CostingDocument2 pagesSummary Standard CostingMaria Callista LovinaNo ratings yet
- CS 108 - Human Computer InteractionDocument17 pagesCS 108 - Human Computer InteractionWILSON LLAVENo ratings yet
- Filsafat Manusia - LifeDocument15 pagesFilsafat Manusia - LifeFerdinand YoriNo ratings yet
- Smrithi A: ContactDocument3 pagesSmrithi A: ContactAshwathi NarayananNo ratings yet
- Complete Thesis... VarquezDocument59 pagesComplete Thesis... VarquezrodielimNo ratings yet
- Welfare of Subjects, Experimenters and EnvironmentDocument15 pagesWelfare of Subjects, Experimenters and EnvironmentPaul BryanNo ratings yet
- Nod 28Document82 pagesNod 28Sendral OrokNo ratings yet
- Jee Mains Previous Year Paper Class 12 Physics 2022 25 Jun Shift 2 Actual Doubtnut English Medium 2023 Web 3Document36 pagesJee Mains Previous Year Paper Class 12 Physics 2022 25 Jun Shift 2 Actual Doubtnut English Medium 2023 Web 3Himansh MehtaNo ratings yet
- Solidum Vs People of The Philippines DigestedDocument2 pagesSolidum Vs People of The Philippines DigestedEllen Glae DaquipilNo ratings yet
- Types of Rights: and InterestDocument11 pagesTypes of Rights: and Interestvicky .mNo ratings yet
- My Five Sences Lesson PlanDocument5 pagesMy Five Sences Lesson Planapi-307613003No ratings yet
- The Trans Mereb Experience Perceptions of The Historical Relationship Between Eritrea and EthiopiaDocument19 pagesThe Trans Mereb Experience Perceptions of The Historical Relationship Between Eritrea and EthiopiaKing Bazén Ze EthiopiaNo ratings yet
- Apara Ekadashi PDFDocument2 pagesApara Ekadashi PDFRanjitNo ratings yet
- Reading ComprehensionDocument5 pagesReading ComprehensionMyatkokooo MandalayNo ratings yet