Download as pdf or txt
You might also like
- cs229 Notes EnsembleDocument7 pagescs229 Notes EnsemblebobNo ratings yet
- DDE Seminar Tutorial IIDocument24 pagesDDE Seminar Tutorial IISandeep Ravikumar MurthyNo ratings yet
- Lab#1 Sampling and Quantization Objectives:: Communication II Lab (EELE 4170)Document6 pagesLab#1 Sampling and Quantization Objectives:: Communication II Lab (EELE 4170)MarteNo ratings yet
- Friedman Two Way Analysis of Variance by RanksDocument27 pagesFriedman Two Way Analysis of Variance by RanksRohaila Rohani100% (2)
- Hedging Strategy For GM To Manage Competitive Currency ExposureDocument26 pagesHedging Strategy For GM To Manage Competitive Currency ExposureAbhineet Gaurav75% (12)
- Basic Concepts in StatisticsDocument40 pagesBasic Concepts in StatisticsJeffrey CabarrubiasNo ratings yet
- Clinical Epidemiology 3rd EdDocument283 pagesClinical Epidemiology 3rd Edkenz18096100% (3)
- 6.034 Quiz 2 November 17, 2003: Name EmailDocument20 pages6.034 Quiz 2 November 17, 2003: Name EmailMaria SilvaNo ratings yet
- 6.034 QUIZ 2: Fall 2002Document15 pages6.034 QUIZ 2: Fall 2002gomathyNo ratings yet
- Lecture Notes On Numerical Solution of Ordinary Differential EquationsDocument47 pagesLecture Notes On Numerical Solution of Ordinary Differential EquationsAbdul Hanan 784-FBAS/MSMA/F21No ratings yet
- Algorithm & Solved Example - ADALINEDocument5 pagesAlgorithm & Solved Example - ADALINEVansh SantdasaniNo ratings yet
- ML Support Vector Machines 2Document22 pagesML Support Vector Machines 223mb0072No ratings yet
- Exam 2003 BDocument20 pagesExam 2003 Bkib6707No ratings yet
- Chapter 1Document9 pagesChapter 1nuofanxiaNo ratings yet
- Imp Questions For Ci - UpdateDocument8 pagesImp Questions For Ci - Updaterajeshwari64.yNo ratings yet
- Note 5Document24 pagesNote 5nuthan manideepNo ratings yet
- DAA Unit 4Document24 pagesDAA Unit 4hari karanNo ratings yet
- HW1 Solution PDFDocument13 pagesHW1 Solution PDFmsk123123No ratings yet
- AI-Lecture 12 - Simple PerceptronDocument24 pagesAI-Lecture 12 - Simple PerceptronMadiha Nasrullah100% (1)
- Lab 3 Topic 2Document12 pagesLab 3 Topic 2ShwrulNo ratings yet
- Ann MPDM IiDocument42 pagesAnn MPDM Iisidra shafiqNo ratings yet
- Lecture 11 - Introduction To Artificial Neural Networks (ANN)Document35 pagesLecture 11 - Introduction To Artificial Neural Networks (ANN)johndeuterokNo ratings yet
- Lab Floating Point Genetic AlgorithmDocument5 pagesLab Floating Point Genetic Algorithmm.a7med82002No ratings yet
- K Nearest Neighbor (Revised)Document20 pagesK Nearest Neighbor (Revised)AradhyaNo ratings yet
- Artificial Neural NetworkDocument44 pagesArtificial Neural Networkgangotri chakrabortyNo ratings yet
- Process Modeling Lecture 6Document51 pagesProcess Modeling Lecture 6Muddys007No ratings yet
- PRu 4Document13 pagesPRu 4Yash ShahNo ratings yet
- Kohen's Self Organizing Maps - NotesDocument4 pagesKohen's Self Organizing Maps - NotesjamieabeyNo ratings yet
- ANN NotesDocument54 pagesANN NotesstacyanzemoNo ratings yet
- Machine Learning SolutionDocument6 pagesMachine Learning SolutionPRABHU PRASAD DEVNo ratings yet
- Lec 11Document8 pagesLec 11stathiss11No ratings yet
- Homework Assignment 3 Homework Assignment 3Document10 pagesHomework Assignment 3 Homework Assignment 3Ido AkovNo ratings yet
- Module 3Document79 pagesModule 3sabharish varshan410100% (1)
- Computer-Based Interpretation-Fundamentals of Machine LearningDocument22 pagesComputer-Based Interpretation-Fundamentals of Machine LearningBarakaMonSifNo ratings yet
- Supervised Learning Networks: Perceptron Networks Back Propagation NetworksDocument22 pagesSupervised Learning Networks: Perceptron Networks Back Propagation NetworksmohitNo ratings yet
- OmNarayanSingh CC306 IS FinalDocument15 pagesOmNarayanSingh CC306 IS FinalOm SinghNo ratings yet
- SVMDocument36 pagesSVMHimanshu BhattNo ratings yet
- cs188 sp23 Note25Document8 pagescs188 sp23 Note25sondosNo ratings yet
- Appl Diff EqsDocument94 pagesAppl Diff EqsSasivardhan ReddyNo ratings yet
- Teknik SimulasiDocument5 pagesTeknik SimulasiBee BaiiNo ratings yet
- CS702. 2011-SolDocument13 pagesCS702. 2011-Solmc210202963 MAMOONA RANANo ratings yet
- Lesson 3 Measures of Central TendencyDocument17 pagesLesson 3 Measures of Central TendencypyaplauaanNo ratings yet
- Basic Vibration Analysis in AnsysDocument30 pagesBasic Vibration Analysis in AnsysmanjunathbagaliNo ratings yet
- Lab ANDandXOR REGRESSION ANNDocument13 pagesLab ANDandXOR REGRESSION ANNtechoverlord.contactNo ratings yet
- CS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationDocument9 pagesCS 188 Introduction To Artificial Intelligence Fall 2017 Note 10 Neural Networks: MotivationEman JaffriNo ratings yet
- Analysis I: Carl Turner November 21, 2010Document54 pagesAnalysis I: Carl Turner November 21, 2010rasromeoNo ratings yet
- Lecture 2 MathDocument34 pagesLecture 2 Mathnikola001No ratings yet
- Genetic Algorithms TutorialsDocument29 pagesGenetic Algorithms TutorialsMustafamna Al SalamNo ratings yet
- Robust NotesDocument23 pagesRobust Notescuterose95No ratings yet
- Unit - II MLDocument9 pagesUnit - II MLraviNo ratings yet
- Pattern Recognition & Analysis Assignment - IiDocument19 pagesPattern Recognition & Analysis Assignment - IiShabeeb Ali OruvangaraNo ratings yet
- Measurement Techniques - Lesson03Document35 pagesMeasurement Techniques - Lesson03Umut ŞENNo ratings yet
- Sorting Algorithms 20222 NotesDocument135 pagesSorting Algorithms 20222 NotesSaba RaeesNo ratings yet
- Min ImDocument17 pagesMin ImRam Charan KonidelaNo ratings yet
- Business Intelligence & Data Mining-10Document39 pagesBusiness Intelligence & Data Mining-10binzidd007No ratings yet
- ML Unit-IvDocument19 pagesML Unit-IvYadavilli VinayNo ratings yet
- 030 Problem Set 1Document5 pages030 Problem Set 1HMNo ratings yet
- DL KIET Model Question PaperDocument31 pagesDL KIET Model Question PaperSrinivas NaiduNo ratings yet
- Refresher: Perceptron Training AlgorithmDocument12 pagesRefresher: Perceptron Training Algorithmeduardo_quintanill_3No ratings yet
- Ann Mid1: Artificial Neural Networks With Biological Neural Network - SimilarityDocument13 pagesAnn Mid1: Artificial Neural Networks With Biological Neural Network - SimilaritySirishaNo ratings yet
- Unit VDocument22 pagesUnit VUdaya sriNo ratings yet
- MLCH9Document45 pagesMLCH9sam33rdhakalNo ratings yet
- Logistic Regression and Discriminant Analysis: Jerry D.T. Purnomo, PH.DDocument54 pagesLogistic Regression and Discriminant Analysis: Jerry D.T. Purnomo, PH.DBina Aji NugrahaNo ratings yet
- Standard-Slope Integration: A New Approach to Numerical IntegrationFrom EverandStandard-Slope Integration: A New Approach to Numerical IntegrationNo ratings yet
- Taste of Home 2012 10 11Document104 pagesTaste of Home 2012 10 11mlevilsNo ratings yet
- Irma S Rombauer Joy of Cooking All About Grilling 2001Document129 pagesIrma S Rombauer Joy of Cooking All About Grilling 2001mlevilsNo ratings yet
- Spiti ONEDocument24 pagesSpiti ONEmlevilsNo ratings yet
- BBC Easy Cook 2019 125Document92 pagesBBC Easy Cook 2019 125mlevils100% (1)
- 17 Marzetti Caramel Dip RecipesDocument10 pages17 Marzetti Caramel Dip RecipesmlevilsNo ratings yet
- Moravian Yeast RollDocument2 pagesMoravian Yeast Rollmlevils0% (1)
- Games and CSP Search 1. Games:: A) General Minimax SearchDocument7 pagesGames and CSP Search 1. Games:: A) General Minimax SearchmlevilsNo ratings yet
- PentominoesNivasch PDFDocument4 pagesPentominoesNivasch PDFmlevilsNo ratings yet
- UNIT-1 What Is HR Analytics?Document74 pagesUNIT-1 What Is HR Analytics?mukul dish ahirwarNo ratings yet
- 8102 StatsDocument5 pages8102 Statsgaurav jainNo ratings yet
- SAMPLING Lectures - 3Document11 pagesSAMPLING Lectures - 3Robert ManeaNo ratings yet
- K-Nearest Neighbor: Scholarpedia January 2009Document14 pagesK-Nearest Neighbor: Scholarpedia January 2009Anonymous 3NmUUDtNo ratings yet
- Bozarth ch09Document48 pagesBozarth ch09Erica ClarkeNo ratings yet
- MA 20104 Probability and Statistics Assignment No. 3: T X e TDocument3 pagesMA 20104 Probability and Statistics Assignment No. 3: T X e TSubhajit BagNo ratings yet
- CH 6-2 Comparing Diagnostic TestsDocument8 pagesCH 6-2 Comparing Diagnostic TestsJimmyNo ratings yet
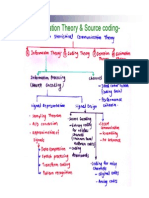
- Unit I Information Theory & Coding Techniques P IDocument48 pagesUnit I Information Theory & Coding Techniques P IShanmugapriyaVinodkumarNo ratings yet
- Estimation of ParameterDocument3 pagesEstimation of Parameteralteya cailaoNo ratings yet
- Journal of Statistical Software: The Pls Package: Principal Component and Partial Least Squares Regression in RDocument23 pagesJournal of Statistical Software: The Pls Package: Principal Component and Partial Least Squares Regression in RDiego SotoNo ratings yet
- Probability: (EAMCET 2009)Document11 pagesProbability: (EAMCET 2009)eamcetmaterials100% (1)
- Introductory Statistics Using Spss 2Nd Edition Knapp Solutions Manual Full Chapter PDFDocument63 pagesIntroductory Statistics Using Spss 2Nd Edition Knapp Solutions Manual Full Chapter PDFKimberlyWilliamsonepda100% (9)
- Cataquis, Marianne Jubille - ActOct10Document17 pagesCataquis, Marianne Jubille - ActOct10EES StudyNo ratings yet
- Chapter 6 PPT SldiesDocument30 pagesChapter 6 PPT SldiesParisa MohammadrezaieNo ratings yet
- Prof. Monica RomanDocument19 pagesProf. Monica RomansandrageorgiaionNo ratings yet
- Math 212 - Krishna Kumar VDocument19 pagesMath 212 - Krishna Kumar VSantoshNo ratings yet
- CBISDocument9 pagesCBISRahul KhaitanNo ratings yet
- StatDocument14 pagesStatPiolo AguirreNo ratings yet
- Probability DistributionDocument17 pagesProbability DistributionMasudur RahmanNo ratings yet
- 2021 Stat NotesDocument162 pages2021 Stat NotesKhushiNo ratings yet
- Clustering in BioinformaticsDocument110 pagesClustering in BioinformaticstisimpsonNo ratings yet
- Decline, Turnaround, and Managerial Ownership: Key Words: Turnaround Strategies, Governance, Agency TheoryDocument20 pagesDecline, Turnaround, and Managerial Ownership: Key Words: Turnaround Strategies, Governance, Agency TheorySharief Mastan ShaikNo ratings yet
- Adorable Question: IdentificationDocument3 pagesAdorable Question: Identificationdiego lopezNo ratings yet
- Chapter 4Document40 pagesChapter 4eyob bitewNo ratings yet