Download as pdf or txt
You might also like
- Top 100 Machine Learning Questions With Answers For Interview PDFDocument48 pagesTop 100 Machine Learning Questions With Answers For Interview PDFPiyush Saraf100% (2)
- Applied Course PDFDocument159 pagesApplied Course PDFsp rathoreNo ratings yet
- DL - Assignment 9 SolutionDocument7 pagesDL - Assignment 9 Solutionswathisreejith6100% (3)
- AdvanceTS1handson - Jupyter NotebookDocument3 pagesAdvanceTS1handson - Jupyter NotebookVikas100% (2)
- Question BankDocument14 pagesQuestion BankVinayak PhutaneNo ratings yet
- Hcia Ai Huawei Mock Exam Written DocuDocument10 pagesHcia Ai Huawei Mock Exam Written DocuJonafe PiamonteNo ratings yet
- IIT Kanpur Machine Learning End Sem PaperDocument10 pagesIIT Kanpur Machine Learning End Sem PaperJivnesh SandhanNo ratings yet
- Data Science and Machine Learning - MCQDocument19 pagesData Science and Machine Learning - MCQshahid kamalNo ratings yet
- AI Dump - E0Document3 pagesAI Dump - E0Music LoverNo ratings yet
- DL - Assignment 2 SolutionDocument7 pagesDL - Assignment 2 Solutionswathisreejith6No ratings yet
- Deep Learning - IIT Ropar - Unit 3 - Week 1Document3 pagesDeep Learning - IIT Ropar - Unit 3 - Week 1DhivyaNo ratings yet
- DL - Assignment 3 SolutionDocument7 pagesDL - Assignment 3 Solutionswathisreejith6No ratings yet
- DL - Assignment 4 SolutionDocument6 pagesDL - Assignment 4 Solutionswathisreejith6No ratings yet
- MCQ QuestionDocument5 pagesMCQ QuestionSURENDRAN D CS085No ratings yet
- MCQDocument9 pagesMCQK.P.Revathi Asst prof - IT Dept100% (1)
- DL - Assignment 5 SolutionDocument7 pagesDL - Assignment 5 Solutionswathisreejith6No ratings yet
- DL - Assignment 8 SolutionDocument6 pagesDL - Assignment 8 Solutionswathisreejith6100% (1)
- DL - Assignment 6 SolutionDocument6 pagesDL - Assignment 6 Solutionswathisreejith6100% (1)
- (Final) 600+ ML MCQDocument319 pages(Final) 600+ ML MCQAsmit Yadav100% (2)
- DL - Assignment 7 SolutionDocument5 pagesDL - Assignment 7 Solutionswathisreejith6100% (1)
- DL - Assignment 12 SolutionDocument7 pagesDL - Assignment 12 Solutionswathisreejith6No ratings yet
- Assignment Week 4-Deep-Learning PDFDocument7 pagesAssignment Week 4-Deep-Learning PDFashish kumar100% (1)
- Assignment Week 11-Deep-Learning PDFDocument7 pagesAssignment Week 11-Deep-Learning PDFashish kumar100% (2)
- Week3 AssignmentDocument6 pagesWeek3 AssignmentSURENDRAN D CS085No ratings yet
- Ai Sample PaperDocument2 pagesAi Sample PaperManish AryaNo ratings yet
- Assignment Week 8-Deep-Learning PDFDocument5 pagesAssignment Week 8-Deep-Learning PDFashish kumar100% (1)
- UNIT 1 Practice Quiz - MCQs - MLDocument10 pagesUNIT 1 Practice Quiz - MCQs - MLGaurav Rajput100% (1)
- DL - Assignment 10 SolutionDocument6 pagesDL - Assignment 10 Solutionswathisreejith6100% (2)
- Question Bank Beel801 PDFDocument10 pagesQuestion Bank Beel801 PDFKanak GargNo ratings yet
- ML Mcqs Without AnswersDocument21 pagesML Mcqs Without AnswersSyeda Maria50% (2)
- Unit 1Document13 pagesUnit 1ठाकुर अनमोल राजपूत100% (1)
- Time SeriesDocument43 pagesTime SerieshardikpadhyNo ratings yet
- Gold Price Prediction Using Ensemble Based Supervised Machine LearningDocument30 pagesGold Price Prediction Using Ensemble Based Supervised Machine LearningSai Teja deevela100% (2)
- Image ClassificationDocument3 pagesImage ClassificationSameer AbidiNo ratings yet
- Machine Learning MCQDocument29 pagesMachine Learning MCQDeepak Daksh100% (2)
- Assignment - Week 6 (Neural Networks) Type of Question: MCQ/MSQDocument4 pagesAssignment - Week 6 (Neural Networks) Type of Question: MCQ/MSQSURENDRAN D CS085No ratings yet
- Advanced Data Structures NotesDocument142 pagesAdvanced Data Structures NotesChinkal Nagpal100% (2)
- Introduction To Machine Learning - Unit 3 - Week 1Document3 pagesIntroduction To Machine Learning - Unit 3 - Week 1DhivyaNo ratings yet
- Huawei H13-311 - V3 0 v2020-12-02 q129Document28 pagesHuawei H13-311 - V3 0 v2020-12-02 q129Akram AlkouzNo ratings yet
- D. Null OperatorDocument49 pagesD. Null OperatorPlayIt All100% (2)
- MCQDocument4 pagesMCQspraveen2007No ratings yet
- Machine Learning Unit 3Document40 pagesMachine Learning Unit 3read4freeNo ratings yet
- Data Mining MCQ LinksDocument1 pageData Mining MCQ LinksTimNo ratings yet
- Wipro ReasoningDocument13 pagesWipro ReasoningcherryNo ratings yet
- Basic Programming LogicDocument18 pagesBasic Programming LogicSuvarchala DeviNo ratings yet
- CS 703 (C) Agile Software Development (ASD) Mid Sem 1paperDocument1 pageCS 703 (C) Agile Software Development (ASD) Mid Sem 1papershubh agrawalNo ratings yet
- DL - Assignment 1 SolutionDocument8 pagesDL - Assignment 1 Solutionswathisreejith6No ratings yet
- NNFLC QuestionDocument1 pageNNFLC Questionnaveeth11No ratings yet
- Final: CS 189 Spring 2013 Introduction To Machine LearningDocument9 pagesFinal: CS 189 Spring 2013 Introduction To Machine LearningShabsNo ratings yet
- ML Unit 1 MCQDocument9 pagesML Unit 1 MCQpranav chaudhari100% (1)
- Web Minng - Mining Association Rules in Large DatabasesDocument108 pagesWeb Minng - Mining Association Rules in Large DatabasesVishnuprasad NagadevaraNo ratings yet
- Applied Generative AI ProfessionalDocument8 pagesApplied Generative AI ProfessionalrinalNo ratings yet
- Unit 2 - MCQ Bank PDFDocument15 pagesUnit 2 - MCQ Bank PDFDr.J. ThamilselviNo ratings yet
- Unix Kernel Support For FilesDocument17 pagesUnix Kernel Support For FilesKeerti Priya K25% (4)
- Basic Interview Q's On ML PDFDocument243 pagesBasic Interview Q's On ML PDFsourajit roy chowdhury100% (2)
- 300+ TOP Neural Networks Multiple Choice Questions and AnswersDocument29 pages300+ TOP Neural Networks Multiple Choice Questions and AnswersJAVARIA NAZIRNo ratings yet
- ML Mid Sem Question BankDocument11 pagesML Mid Sem Question BankshreyashNo ratings yet
- Assignment9 DeepLearningDocument6 pagesAssignment9 DeepLearningMadhur KabraNo ratings yet
- Solutions To Deep LearningDocument25 pagesSolutions To Deep LearningiqbalNo ratings yet
- Cs230exam Spr18 Soln PDFDocument45 pagesCs230exam Spr18 Soln PDFMOHAMMAD100% (1)
- Powder Bed Fusion ProcessesDocument10 pagesPowder Bed Fusion Processeshimanshu singhNo ratings yet
- Vat Photopolymerization ProcessesDocument17 pagesVat Photopolymerization Processeshimanshu singhNo ratings yet
- Scanning Probe MicroscopeDocument25 pagesScanning Probe Microscopehimanshu singhNo ratings yet
- X-Ray Diffraction: Dr. Mukesh KumarDocument31 pagesX-Ray Diffraction: Dr. Mukesh Kumarhimanshu singhNo ratings yet
- Programming Assignments of Deep Learning Specialization 5 Courses 1Document304 pagesProgramming Assignments of Deep Learning Specialization 5 Courses 1himanshu singhNo ratings yet
- Dr. Mukesh Kumar: Department of Physics IIT Ropar Office: 2 Floor, #206 Ph. No.: 01881-24-2263 EmailDocument24 pagesDr. Mukesh Kumar: Department of Physics IIT Ropar Office: 2 Floor, #206 Ph. No.: 01881-24-2263 Emailhimanshu singhNo ratings yet
- Summary of Daily News Analysis: - by Jatin VermaDocument46 pagesSummary of Daily News Analysis: - by Jatin Vermahimanshu singhNo ratings yet
- Flexible Manufacturing Cells and SystemsDocument99 pagesFlexible Manufacturing Cells and Systemshimanshu singhNo ratings yet
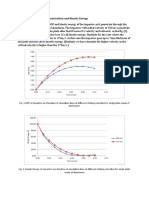
- Plot For Depth of Penetration and Kinetic EnergyDocument3 pagesPlot For Depth of Penetration and Kinetic Energyhimanshu singhNo ratings yet
- SSC Junior Engineer Papers Electrical Engineering 27 Jan 2018 Morning Shift PDFDocument35 pagesSSC Junior Engineer Papers Electrical Engineering 27 Jan 2018 Morning Shift PDFhimanshu singhNo ratings yet
- Production Systems, Automation EtcDocument45 pagesProduction Systems, Automation Etchimanshu singhNo ratings yet
- Industrial RoboticsDocument45 pagesIndustrial Roboticshimanshu singhNo ratings yet
- Design Lab 2 IIT RoparDocument13 pagesDesign Lab 2 IIT Roparhimanshu singhNo ratings yet
- Computer Integrated Manufacturing PDFDocument28 pagesComputer Integrated Manufacturing PDFhimanshu singhNo ratings yet
- Assignment 2 ME 305Document2 pagesAssignment 2 ME 305himanshu singhNo ratings yet
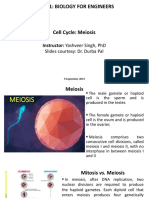
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument15 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument21 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument15 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Transportation and AssignmentDocument44 pagesTransportation and Assignmenthimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument23 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Lecture 9 PDFDocument21 pagesLecture 9 PDFhimanshu singh100% (1)
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument16 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument19 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument19 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- 03 Reference Material HMT ME302 Steady Heat Conduction PDFDocument38 pages03 Reference Material HMT ME302 Steady Heat Conduction PDFhimanshu singhNo ratings yet
- 01 Reference Material HMT ME302 1 IntroductionDocument35 pages01 Reference Material HMT ME302 1 Introductionhimanshu singhNo ratings yet
- Bm101: Biology For Engineers: Instructor: Yashveer Singh, PHDDocument23 pagesBm101: Biology For Engineers: Instructor: Yashveer Singh, PHDhimanshu singhNo ratings yet
- 03 Reference Material HMT ME302 Steady Heat Conduction PDFDocument38 pages03 Reference Material HMT ME302 Steady Heat Conduction PDFhimanshu singhNo ratings yet
- OOPS & DS Question BankDocument5 pagesOOPS & DS Question BankParandaman Sampathkumar SNo ratings yet
- Lab2a 10 FinalDocument3 pagesLab2a 10 FinalAlfarsi AalfarsiNo ratings yet
- Varga - Functional Analysis and Approximations in Numerical AnalysisDocument87 pagesVarga - Functional Analysis and Approximations in Numerical Analysisaedicofidia100% (2)
- Row Reduction Algorithm MATHS PROJECT.Document11 pagesRow Reduction Algorithm MATHS PROJECT.Bhargav SaiNo ratings yet
- College Exam-Math 221Document3 pagesCollege Exam-Math 221Nova Mae Quillas AgraviadorNo ratings yet
- Jboi 2014 FulecoandBrazilAntSolutionDocument3 pagesJboi 2014 FulecoandBrazilAntSolutionVedran MarićNo ratings yet
- Basics of Hermitian Geometry: Vector Spaces Over The Complex Numbers Complex ConjugationDocument52 pagesBasics of Hermitian Geometry: Vector Spaces Over The Complex Numbers Complex ConjugationmaxxagainNo ratings yet
- Probability AxiomsDocument1 pageProbability AxiomsJohn Michael Galingana CaneroNo ratings yet
- Linear Stability of Lid-Driven Cavity Flow: Articles You May Be Interested inDocument13 pagesLinear Stability of Lid-Driven Cavity Flow: Articles You May Be Interested inDebendra Nath SarkarNo ratings yet
- ProbabilityDocument65 pagesProbabilityduvan stiven garcía flórezNo ratings yet
- Orientation Conversion FormulasDocument4 pagesOrientation Conversion FormulasMatheus FurstenbergerNo ratings yet
- Linear Algebra (Lec-5)Document6 pagesLinear Algebra (Lec-5)Samiul LesumNo ratings yet
- Projective Modules 3. Hairy Ball Theorem 4. Hochster's Example 5. Historical Context ReferencesDocument17 pagesProjective Modules 3. Hairy Ball Theorem 4. Hochster's Example 5. Historical Context ReferencesHiba MansoorNo ratings yet
- Chain Product Quotient Rules 277qagsDocument7 pagesChain Product Quotient Rules 277qagsRobert JoeNo ratings yet
- MTH102: Mathematics I: Prerequisites Courses: NoneDocument4 pagesMTH102: Mathematics I: Prerequisites Courses: NoneanuragNo ratings yet
- Bisection MethodDocument33 pagesBisection MethodMohammed SallamNo ratings yet
- Mathematics Passing Package (40+ Marks) 2022 - 23) Student ChecklistDocument2 pagesMathematics Passing Package (40+ Marks) 2022 - 23) Student ChecklistSeema KoreNo ratings yet
- Numerical TechniquesDocument7 pagesNumerical TechniquesBob HopeNo ratings yet
- Simultaneous Equations: M N N MDocument12 pagesSimultaneous Equations: M N N MHadibahHarunNo ratings yet
- E-Book 'Pure Maths Part Two - Integration' From A-Level Maths TutorDocument39 pagesE-Book 'Pure Maths Part Two - Integration' From A-Level Maths TutorA-level Maths Tutor100% (2)
- Supplement: The Inductive Discovery of DeterminantsDocument6 pagesSupplement: The Inductive Discovery of DeterminantsSyedaNo ratings yet
- FP3 NotesDocument56 pagesFP3 NotesMoeezNo ratings yet
- Subspacesofr2 PDFDocument2 pagesSubspacesofr2 PDFReshma SNo ratings yet
- 1b Rainbow Antimagic ColoringDocument13 pages1b Rainbow Antimagic ColoringRosanita NisviasariNo ratings yet
- 4.2.1 Slope of The Tangent and Normal: F y y X PDocument17 pages4.2.1 Slope of The Tangent and Normal: F y y X PAnkit Kumar Thakur100% (1)
- MATH 131 Tutorial 2 2024Document2 pagesMATH 131 Tutorial 2 2024jamakonke8No ratings yet
- Chimera Project 2015Document6 pagesChimera Project 2015Hevant BhojaramNo ratings yet
- STM 111 Lesson 1 The Circle AutosavedDocument53 pagesSTM 111 Lesson 1 The Circle Autosavednadine catiloNo ratings yet