Download as pdf or txt
You might also like
- Soal UAS Bahasa Inggris Kelas 1 SD Semester 2 Dan Kunci JawabanDocument4 pagesSoal UAS Bahasa Inggris Kelas 1 SD Semester 2 Dan Kunci Jawabanramzul91% (23)
- BritishCivilization 9 MMDocument415 pagesBritishCivilization 9 MMFrancisco Ortiz BecerraNo ratings yet
- Course Preview: Political Economy and Economic DevelopmentDocument3 pagesCourse Preview: Political Economy and Economic DevelopmentJourney toNo ratings yet
- 2020 Presidential Election Contrast ReportDocument61 pages2020 Presidential Election Contrast ReportJohn Droz, jr.100% (18)
- Letter To FettermanDocument1 pageLetter To FettermanPennLiveNo ratings yet
- Maths IA FinalDocument26 pagesMaths IA FinalBach HoangNo ratings yet
- What Is Time Series AnalysisDocument28 pagesWhat Is Time Series AnalysisNidhi KaushikNo ratings yet
- Prediction ModelDocument5 pagesPrediction ModelNidhi KaushikNo ratings yet
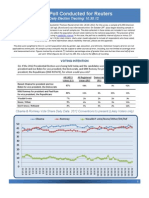
- 2012 Reuters Ipsos Daily Election Tracking 09.10.12Document3 pages2012 Reuters Ipsos Daily Election Tracking 09.10.12kyle_r_leightonNo ratings yet
- ND Poll DFM ResearchDocument7 pagesND Poll DFM ResearchinforumdocsNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 10.30.12Document5 pages2012 Reuters Ipsos Daily Election Tracking 10.30.12kyle_r_leightonNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 09.24.12Document3 pages2012 Reuters Ipsos Daily Election Tracking 09.24.12Casey MichelNo ratings yet
- Vitter Final ProjectDocument9 pagesVitter Final Projectapi-238251676No ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 09.19.12Document4 pages2012 Reuters Ipsos Daily Election Tracking 09.19.12kyle_r_leightonNo ratings yet
- Operational Definitions of VariablesDocument8 pagesOperational Definitions of VariablesJM Hernandez VillanuevaNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 11.03.12Document5 pages2012 Reuters Ipsos Daily Election Tracking 11.03.12Casey MichelNo ratings yet
- P State 0705 FinalDocument32 pagesP State 0705 FinalfadligmailNo ratings yet
- MethodologyDocument6 pagesMethodologybryanbreguetNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 09.20.12Document3 pages2012 Reuters Ipsos Daily Election Tracking 09.20.12Casey MichelNo ratings yet
- Problem Set 4Document4 pagesProblem Set 4Viswanathan NatarajanNo ratings yet
- Mcmahon by A Nose in Close Connecticut Senate Race, Quinnipiac University Poll Finds Obama Tops Romney by 7 PointsDocument21 pagesMcmahon by A Nose in Close Connecticut Senate Race, Quinnipiac University Poll Finds Obama Tops Romney by 7 PointsAlfonso RobinsonNo ratings yet
- Statistics For Criminology and Criminal Justice 4th Edition Bachman Paternoster Solution ManualDocument6 pagesStatistics For Criminology and Criminal Justice 4th Edition Bachman Paternoster Solution Manualkathy100% (30)
- Midterm Exam - Analytical Methods IDocument1 pageMidterm Exam - Analytical Methods IVatsal PatelNo ratings yet
- Michigan Vote AnalysisDocument24 pagesMichigan Vote AnalysisbbirchNo ratings yet
- Survey Design: The First Steps - MeasurementDocument26 pagesSurvey Design: The First Steps - Measurementdr_putnamNo ratings yet
- Crime in StatesDocument13 pagesCrime in StatesSonaarika MahajanNo ratings yet
- Data Analysis and Data InterpretationDocument6 pagesData Analysis and Data Interpretationritika aggarwalNo ratings yet
- CO-Gov Magellan (Oct. 2010)Document10 pagesCO-Gov Magellan (Oct. 2010)Daily Kos ElectionsNo ratings yet
- Survey Memo 19732Document1 pageSurvey Memo 19732Amy OliverNo ratings yet
- Selecting A Statistical Test and Chi-Square Test of IndependenceDocument6 pagesSelecting A Statistical Test and Chi-Square Test of IndependenceGianne GajardoNo ratings yet
- MEMO COVID-19 Voter Sentiment TX Statewide 04232020Document2 pagesMEMO COVID-19 Voter Sentiment TX Statewide 04232020The TexanNo ratings yet
- Gonzales Maryland Poll Report January 2020Document29 pagesGonzales Maryland Poll Report January 2020wtopwebNo ratings yet
- PollReport June2023 FLHD35Document7 pagesPollReport June2023 FLHD35Jacob OglesNo ratings yet
- NDVF Poll 2 - ReportDocument10 pagesNDVF Poll 2 - ReportinforumdocsNo ratings yet
- 2024 Presidential ElectionDocument5 pages2024 Presidential Electiondalvoscarpa@gmailNo ratings yet
- United States 2004 National Corrections Reporting ProgramDocument3 pagesUnited States 2004 National Corrections Reporting Programlaura castroNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 10.02.12Document4 pages2012 Reuters Ipsos Daily Election Tracking 10.02.12Casey MichelNo ratings yet
- DLCC StrategyDocument1 pageDLCC StrategyCasey MichelNo ratings yet
- Who Helps Who?: Visualizing How Economic Prosperity Affects The Elections, and Vice VersaDocument8 pagesWho Helps Who?: Visualizing How Economic Prosperity Affects The Elections, and Vice Versaasteady23No ratings yet
- Assignment - Unit 1Document2 pagesAssignment - Unit 1Giovanna ReyesNo ratings yet
- AFF October 2013 Poll MemoDocument3 pagesAFF October 2013 Poll MemoPoliticsPANo ratings yet
- Public Policy Polling Mass. Senate Race SurveyDocument17 pagesPublic Policy Polling Mass. Senate Race SurveyMassLiveNo ratings yet
- Tweetminster Predicts: FindingsDocument7 pagesTweetminster Predicts: FindingsTweetminsterNo ratings yet
- FERRAZ - Exposing Corrupt Politicians - The Effects of Brazil's Publicly Released Audits On Electoral OutcomesDocument43 pagesFERRAZ - Exposing Corrupt Politicians - The Effects of Brazil's Publicly Released Audits On Electoral OutcomesDetteDeCastroNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 11.01.12Document6 pages2012 Reuters Ipsos Daily Election Tracking 11.01.12Casey MichelNo ratings yet
- Marketing Research Project On StarbucksDocument49 pagesMarketing Research Project On StarbucksSalman Bin HabibNo ratings yet
- Understanding The Bias-Variance TradeoffDocument11 pagesUnderstanding The Bias-Variance TradeoffBalaganesh NallathambiNo ratings yet
- 02 Producing Data, SamplingDocument9 pages02 Producing Data, SamplingadmirodebritoNo ratings yet
- Connecticut Senate Race Is Tied, Quinnipiac University Poll Finds Obama Widens Lead Over Romney To 12 PointsDocument22 pagesConnecticut Senate Race Is Tied, Quinnipiac University Poll Finds Obama Widens Lead Over Romney To 12 PointsAlfonso RobinsonNo ratings yet
- Lab 3 SolutionsDocument4 pagesLab 3 SolutionsdanNo ratings yet
- The Economic and Social Conseuences of Left-Populist Regimes in Latin AmericaDocument73 pagesThe Economic and Social Conseuences of Left-Populist Regimes in Latin AmericaArelyMoralesNo ratings yet
- F&M PollDocument31 pagesF&M PollPhiladelphiaMagazineNo ratings yet
- 2012 Reuters Ipsos Daily Election Tracking 10.01.12Document3 pages2012 Reuters Ipsos Daily Election Tracking 10.01.12Casey MichelNo ratings yet
- 2008 2012 Elections Results Anomalies and Analysis - V1.5Document21 pages2008 2012 Elections Results Anomalies and Analysis - V1.5Jonathan 조나단 PharisNo ratings yet
- Statistics For Criminology and Criminal Justice 4th Edition Bachman Solutions ManualDocument25 pagesStatistics For Criminology and Criminal Justice 4th Edition Bachman Solutions ManualTinaFullerktjb100% (35)
- IA-04 DFM Research For SMART (Sept. 2014)Document14 pagesIA-04 DFM Research For SMART (Sept. 2014)Daily Kos ElectionsNo ratings yet
- Final Survey Writeup - Political StatisticsDocument12 pagesFinal Survey Writeup - Political StatisticsMaddyNo ratings yet
- The Impact of Close Races On Electoral College and Popular Vote Conflicts in US Presidential ElectionsDocument5 pagesThe Impact of Close Races On Electoral College and Popular Vote Conflicts in US Presidential ElectionsIVN.us EditorNo ratings yet
- The 2012 Elections in Florida: Obama Wins and Democrats Make Strides in Downticket RacesFrom EverandThe 2012 Elections in Florida: Obama Wins and Democrats Make Strides in Downticket RacesNo ratings yet
- Exploit Loophole 609 to Boost Your Credit Score and Remove All Negative Items From Your Credit Report (Second Edition): Personal Finance, #1From EverandExploit Loophole 609 to Boost Your Credit Score and Remove All Negative Items From Your Credit Report (Second Edition): Personal Finance, #1No ratings yet
- Chapter 17. Tool Kit For Financial Options and Real Options With The TAB Labeled "Real Options."Document30 pagesChapter 17. Tool Kit For Financial Options and Real Options With The TAB Labeled "Real Options."Nidhi KaushikNo ratings yet
- I. Income StatementDocument27 pagesI. Income StatementNidhi KaushikNo ratings yet
- 2020 Bull CAT 21: Section: Verbal AbilityDocument51 pages2020 Bull CAT 21: Section: Verbal AbilityNidhi KaushikNo ratings yet
- Notional Amount: Maturity:: Plain Vanilla Interest Rate SwapDocument2 pagesNotional Amount: Maturity:: Plain Vanilla Interest Rate SwapNidhi KaushikNo ratings yet
- Mutual Funds: Answer Role of Mutual Funds in The Financial Market: Mutual Funds Have Opened New Vistas ToDocument43 pagesMutual Funds: Answer Role of Mutual Funds in The Financial Market: Mutual Funds Have Opened New Vistas ToNidhi Kaushik100% (1)
- Prediction ModelDocument5 pagesPrediction ModelNidhi KaushikNo ratings yet
- AmendmentsDocument3 pagesAmendmentsNidhi KaushikNo ratings yet
- Assignment On Probit ModelDocument17 pagesAssignment On Probit ModelNidhi KaushikNo ratings yet
- What's The Use of A Fine House If You Haven't Got A Tolerable Planet To Put It On."Document2 pagesWhat's The Use of A Fine House If You Haven't Got A Tolerable Planet To Put It On."Nidhi KaushikNo ratings yet
- Econometrics - Functional FormsDocument22 pagesEconometrics - Functional FormsNidhi KaushikNo ratings yet
- Bullet Trains PDFDocument5 pagesBullet Trains PDFNidhi KaushikNo ratings yet
- Regression Statistics: Summary OutputDocument27 pagesRegression Statistics: Summary OutputNidhi KaushikNo ratings yet
- Assignment Submission - Nidhi Kaushik - 18349 - BBA (FIA) 2ADocument26 pagesAssignment Submission - Nidhi Kaushik - 18349 - BBA (FIA) 2ANidhi KaushikNo ratings yet
- Industry AnalysisDocument34 pagesIndustry AnalysisNidhi KaushikNo ratings yet
- Overall Returns 11.100% Risk 3.6359% Weights 0.3744394619 MVP Returns 11.18% Correlation - 0.678146 Risk MVP 3.4755%Document2 pagesOverall Returns 11.100% Risk 3.6359% Weights 0.3744394619 MVP Returns 11.18% Correlation - 0.678146 Risk MVP 3.4755%Nidhi KaushikNo ratings yet
- Probit ModelDocument5 pagesProbit ModelNidhi KaushikNo ratings yet
- Evolution of Philippine Constitution & The New PhilippineDocument10 pagesEvolution of Philippine Constitution & The New PhilippineFrancisco Amistoso Jr.No ratings yet
- Social Policy Concepts & PrinciplesDocument12 pagesSocial Policy Concepts & PrinciplesSisir DasNo ratings yet
- Bspa 2-2 - Santiago, Leona C. - Assignment #2Document3 pagesBspa 2-2 - Santiago, Leona C. - Assignment #2Leilani SantiagoNo ratings yet
- 2020 LaPorte County Election ResultsDocument5 pages2020 LaPorte County Election ResultsNate LoucksNo ratings yet
- Full Chapter The Globalization of World Politics An Introduction To International Relations 7Th Edition John Baylis Steve Smith Patricia Owens PDFDocument54 pagesFull Chapter The Globalization of World Politics An Introduction To International Relations 7Th Edition John Baylis Steve Smith Patricia Owens PDFstephen.inoue766100% (5)
- Commonwealthgames ScamDocument8 pagesCommonwealthgames ScamVinarmata OjhaNo ratings yet
- Test Bank For American Pageant Volume 1 16th EditionDocument36 pagesTest Bank For American Pageant Volume 1 16th Editionzoonwinkfoxyj8100% (54)
- Vet Fed Party V ComelecDocument40 pagesVet Fed Party V Comelecjuverglen ilaganNo ratings yet
- MATERI BHS INGGRIS SD 2 Basic English Sentence Structure and ElementsDocument4 pagesMATERI BHS INGGRIS SD 2 Basic English Sentence Structure and ElementsErlin Dwi MeiningrumNo ratings yet
- Final Cause List - 17 - (From 24-Apr-17 To 28-Apr-17)Document85 pagesFinal Cause List - 17 - (From 24-Apr-17 To 28-Apr-17)Syed Haris Shah Shah GNo ratings yet
- The Daily Tar Heel For Nov. 4, 2014Document6 pagesThe Daily Tar Heel For Nov. 4, 2014The Daily Tar HeelNo ratings yet
- Edward Said Crisis in Orientalism EleanorDocument2 pagesEdward Said Crisis in Orientalism Eleanordebolina060703No ratings yet
- This Study Resource WasDocument2 pagesThis Study Resource WasmayaNo ratings yet
- 3.1 Hitler's Germany - Reasons For Rise To Power SBQ COMPARISON HANDOUTDocument4 pages3.1 Hitler's Germany - Reasons For Rise To Power SBQ COMPARISON HANDOUTKaif SNo ratings yet
- 6 Ed Handbook IntroDocument8 pages6 Ed Handbook IntroCurtis PalmerNo ratings yet
- Or Tawbachuun Barbaada GaruuDocument54 pagesOr Tawbachuun Barbaada GaruuNasri Ahmed mohammed100% (1)
- Collected Works of The Communist Party of Peru Volume 3 1991-1992 by The Communist Party of PeruDocument561 pagesCollected Works of The Communist Party of Peru Volume 3 1991-1992 by The Communist Party of Peruv lauriNo ratings yet
- Legal Warning To Associated Press CEO. GARY B. PRUITTDocument7 pagesLegal Warning To Associated Press CEO. GARY B. PRUITTMario HerreraNo ratings yet
- English Exam For S2Document6 pagesEnglish Exam For S2NSANZUMUHIRE EmmanuelNo ratings yet
- Vacation Leavepnpa Class 20201 PDFDocument13 pagesVacation Leavepnpa Class 20201 PDFgiselle anne martinezNo ratings yet
- 1 BusinessDocument9 pages1 BusinessArzo QaderiNo ratings yet
- 6634 - KJEI's Trinity Academy of Engineering, Yewalewadi, PuneDocument8 pages6634 - KJEI's Trinity Academy of Engineering, Yewalewadi, PuneAditya ChavanNo ratings yet
- Group Assignment Personal Paper Tun Abdullah Ahmad BadawiDocument129 pagesGroup Assignment Personal Paper Tun Abdullah Ahmad BadawiZydan RizqinNo ratings yet
- Estrada v. DesiertoDocument3 pagesEstrada v. DesiertoTootsie GuzmaNo ratings yet
- 2021 Abyip ResoDocument5 pages2021 Abyip ResoEldie NazarNo ratings yet
- Op-Ed ArticleDocument2 pagesOp-Ed Articleapi-590700346No ratings yet
- Summary VotesDocument52 pagesSummary VotesIan Van MamugayNo ratings yet