
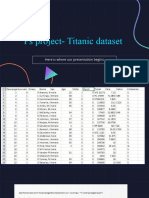
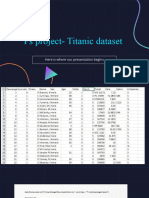
Logistic Regression
Logistic Regression
You might also like
- Q 2Document3 pagesQ 2Mohit JainNo ratings yet
- Tarea de Ciencia de DatosDocument32 pagesTarea de Ciencia de DatosLeomaris FerrerasNo ratings yet
- Writing Efficient R CodeDocument5 pagesWriting Efficient R CodeOctavio FloresNo ratings yet
- CodesDocument14 pagesCodesArvind NANDAN SINGHNo ratings yet
- Visualizing Big Data With TrelliscopeDocument7 pagesVisualizing Big Data With TrelliscopeOctavio FloresNo ratings yet
- AIML Lab - Ws10Document9 pagesAIML Lab - Ws10lucky oneNo ratings yet
- PSPPTDocument10 pagesPSPPTSowmyaNo ratings yet
- Ps NewDocument9 pagesPs NewSowmyaNo ratings yet
- "Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Document9 pages"Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Alper Tamay ArslanNo ratings yet
- Output2Document2 pagesOutput2Laptop-Dimas-249No ratings yet
- CH 5Document3 pagesCH 5AnonymousNo ratings yet
- Apiriori and K-MedoidsDocument3 pagesApiriori and K-MedoidsTAMIL SARAVANNo ratings yet
- 20BCE1205 Lab6Document12 pages20BCE1205 Lab6SHUBHAM OJHANo ratings yet
- Retail Relay CaseDocument6 pagesRetail Relay CaseNishita AgrawalNo ratings yet
- Package Prediction': June 17, 2019Document20 pagesPackage Prediction': June 17, 2019SumedhaNo ratings yet
- R ProgrammingDocument9 pagesR Programmingouahib.chafiai1No ratings yet
- Materi Demo Data MiningDocument5 pagesMateri Demo Data MiningDhike IwrNo ratings yet
- Practica 2 TemperaturaDocument11 pagesPractica 2 TemperaturaJilmeNo ratings yet
- Laporan Praktikum 2 672022337Document33 pagesLaporan Praktikum 2 672022337672022337No ratings yet
- R T2 Econ3005Document10 pagesR T2 Econ3005bellance xavierNo ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- Pertemuan 13Document3 pagesPertemuan 13gilangNo ratings yet
- 1.1 Loading The Data: Survival by SexDocument6 pages1.1 Loading The Data: Survival by Sexk767No ratings yet
- 1st Harvard ProjectDocument17 pages1st Harvard ProjectAlexandre Tem-PassNo ratings yet
- CodeDocument25 pagesCodeClassy ManNo ratings yet
- Source CodeDocument19 pagesSource CodeKash SharmaNo ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- AMDA Practical - A048Document35 pagesAMDA Practical - A048Shubham PhatangareNo ratings yet
- 15.1 (1)Document7 pages15.1 (1)Nake ShippudenNo ratings yet
- Escript Com Rede de CorrelaçãoDocument2 pagesEscript Com Rede de CorrelaçãoRychaellen Silva de BritoNo ratings yet
- DeepLearningForVisionSystems Ch5 AlexNetDocument32 pagesDeepLearningForVisionSystems Ch5 AlexNetmkkadambiNo ratings yet
- Forecast RDocument16 pagesForecast Rhectorla03No ratings yet
- Introduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )Document10 pagesIntroduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )optimistic_harishNo ratings yet
- Email Spam ClassifierDocument22 pagesEmail Spam Classifierphenomenal beastNo ratings yet
- Data Manipulation RDocument13 pagesData Manipulation RumaNo ratings yet
- R AssignmentDocument8 pagesR AssignmentTunaNo ratings yet
- MLT FinalDocument3 pagesMLT Finalshrihari.9919anNo ratings yet
- Zoo FaqDocument15 pagesZoo FaqCarolina Silva TorresNo ratings yet
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- MSstats R Manual2Document4 pagesMSstats R Manual2Gisele WiezelNo ratings yet
- 2_Logistic RegressionDocument4 pages2_Logistic Regressiontasya lopaNo ratings yet
- Code Documentation: Loading The PackagesDocument5 pagesCode Documentation: Loading The PackagesShashwat Patel mm19b053No ratings yet
- "A" "B" "B" "C" 'D': Ggplot2 Geom - ViolinDocument4 pages"A" "B" "B" "C" 'D': Ggplot2 Geom - ViolinLuis EmilioNo ratings yet
- Grid Search For SVMDocument9 pagesGrid Search For SVMkPrasad8No ratings yet
- Awab R 2.5Document3 pagesAwab R 2.5silvapi1994No ratings yet
- Rice - Ipynb - ColabDocument11 pagesRice - Ipynb - ColabMortal king JNJNo ratings yet
- Ex4 EdaDocument1 pageEx4 Eda510821205304.itNo ratings yet
- Supervised Learning in R ClassificationDocument7 pagesSupervised Learning in R ClassificationOctavio FloresNo ratings yet
- Exploratory Data AnalysisDocument5 pagesExploratory Data AnalysisCyd DuqueNo ratings yet
- Machine LeaarningDocument32 pagesMachine LeaarningLuis Eduardo Calderon CantoNo ratings yet
- CodigoDocument6 pagesCodigoRoger Adrian Lopez BriceñoNo ratings yet
- Problem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDocument24 pagesProblem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDarnell LarsenNo ratings yet
- Lstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubDocument5 pagesLstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubMuhammad Hamdani AzmiNo ratings yet
- BAR-Classification ModellingDocument2 pagesBAR-Classification ModellingAninda DuttaNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sravanthi AmmuNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sravanthi AmmuNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sweety SekharNo ratings yet
- 21bme145 Exp 4Document3 pages21bme145 Exp 421bme145No ratings yet


























































Download as txt, pdf, or txt
You might also like
- Q 2Document3 pagesQ 2Mohit JainNo ratings yet
- Tarea de Ciencia de DatosDocument32 pagesTarea de Ciencia de DatosLeomaris FerrerasNo ratings yet
- Writing Efficient R CodeDocument5 pagesWriting Efficient R CodeOctavio FloresNo ratings yet
- CodesDocument14 pagesCodesArvind NANDAN SINGHNo ratings yet
- Visualizing Big Data With TrelliscopeDocument7 pagesVisualizing Big Data With TrelliscopeOctavio FloresNo ratings yet
- AIML Lab - Ws10Document9 pagesAIML Lab - Ws10lucky oneNo ratings yet
- PSPPTDocument10 pagesPSPPTSowmyaNo ratings yet
- Ps NewDocument9 pagesPs NewSowmyaNo ratings yet
- "Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Document9 pages"Cps - TXT" "Education" "South" "SEX" "Experience" "Union" "WAGE" "AGE" "RACE" "Occupat Ion" "Sector" "MARR"Alper Tamay ArslanNo ratings yet
- Output2Document2 pagesOutput2Laptop-Dimas-249No ratings yet
- CH 5Document3 pagesCH 5AnonymousNo ratings yet
- Apiriori and K-MedoidsDocument3 pagesApiriori and K-MedoidsTAMIL SARAVANNo ratings yet
- 20BCE1205 Lab6Document12 pages20BCE1205 Lab6SHUBHAM OJHANo ratings yet
- Retail Relay CaseDocument6 pagesRetail Relay CaseNishita AgrawalNo ratings yet
- Package Prediction': June 17, 2019Document20 pagesPackage Prediction': June 17, 2019SumedhaNo ratings yet
- R ProgrammingDocument9 pagesR Programmingouahib.chafiai1No ratings yet
- Materi Demo Data MiningDocument5 pagesMateri Demo Data MiningDhike IwrNo ratings yet
- Practica 2 TemperaturaDocument11 pagesPractica 2 TemperaturaJilmeNo ratings yet
- Laporan Praktikum 2 672022337Document33 pagesLaporan Praktikum 2 672022337672022337No ratings yet
- R T2 Econ3005Document10 pagesR T2 Econ3005bellance xavierNo ratings yet
- Rstudio Study Notes For PA 20181126Document6 pagesRstudio Study Notes For PA 20181126Trong Nghia VuNo ratings yet
- Pertemuan 13Document3 pagesPertemuan 13gilangNo ratings yet
- 1.1 Loading The Data: Survival by SexDocument6 pages1.1 Loading The Data: Survival by Sexk767No ratings yet
- 1st Harvard ProjectDocument17 pages1st Harvard ProjectAlexandre Tem-PassNo ratings yet
- CodeDocument25 pagesCodeClassy ManNo ratings yet
- Source CodeDocument19 pagesSource CodeKash SharmaNo ratings yet
- Unit1 ML ProgramsDocument5 pagesUnit1 ML Programsdiroja5648No ratings yet
- Bda AssignDocument15 pagesBda AssignAishwarya BiradarNo ratings yet
- AMDA Practical - A048Document35 pagesAMDA Practical - A048Shubham PhatangareNo ratings yet
- 15.1 (1)Document7 pages15.1 (1)Nake ShippudenNo ratings yet
- Escript Com Rede de CorrelaçãoDocument2 pagesEscript Com Rede de CorrelaçãoRychaellen Silva de BritoNo ratings yet
- DeepLearningForVisionSystems Ch5 AlexNetDocument32 pagesDeepLearningForVisionSystems Ch5 AlexNetmkkadambiNo ratings yet
- Forecast RDocument16 pagesForecast Rhectorla03No ratings yet
- Introduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )Document10 pagesIntroduction To Basics of R - Assignment: Log2 (2 5) Log (Exp (1) Exp (2) )optimistic_harishNo ratings yet
- Email Spam ClassifierDocument22 pagesEmail Spam Classifierphenomenal beastNo ratings yet
- Data Manipulation RDocument13 pagesData Manipulation RumaNo ratings yet
- R AssignmentDocument8 pagesR AssignmentTunaNo ratings yet
- MLT FinalDocument3 pagesMLT Finalshrihari.9919anNo ratings yet
- Zoo FaqDocument15 pagesZoo FaqCarolina Silva TorresNo ratings yet
- Assignment 11-17-15: Michael Petzold November 19, 2015Document4 pagesAssignment 11-17-15: Michael Petzold November 19, 2015mikey pNo ratings yet
- MSstats R Manual2Document4 pagesMSstats R Manual2Gisele WiezelNo ratings yet
- 2_Logistic RegressionDocument4 pages2_Logistic Regressiontasya lopaNo ratings yet
- Code Documentation: Loading The PackagesDocument5 pagesCode Documentation: Loading The PackagesShashwat Patel mm19b053No ratings yet
- "A" "B" "B" "C" 'D': Ggplot2 Geom - ViolinDocument4 pages"A" "B" "B" "C" 'D': Ggplot2 Geom - ViolinLuis EmilioNo ratings yet
- Grid Search For SVMDocument9 pagesGrid Search For SVMkPrasad8No ratings yet
- Awab R 2.5Document3 pagesAwab R 2.5silvapi1994No ratings yet
- Rice - Ipynb - ColabDocument11 pagesRice - Ipynb - ColabMortal king JNJNo ratings yet
- Ex4 EdaDocument1 pageEx4 Eda510821205304.itNo ratings yet
- Supervised Learning in R ClassificationDocument7 pagesSupervised Learning in R ClassificationOctavio FloresNo ratings yet
- Exploratory Data AnalysisDocument5 pagesExploratory Data AnalysisCyd DuqueNo ratings yet
- Machine LeaarningDocument32 pagesMachine LeaarningLuis Eduardo Calderon CantoNo ratings yet
- CodigoDocument6 pagesCodigoRoger Adrian Lopez BriceñoNo ratings yet
- Problem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDocument24 pagesProblem Set 1: Introduction To R - Solutions With R Output: 1 Install PackagesDarnell LarsenNo ratings yet
- Lstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubDocument5 pagesLstm-Load-Forecasting:6 - All - Features - Ipynb at Master Dafrie:lstm-Load-Forecasting GitHubMuhammad Hamdani AzmiNo ratings yet
- BAR-Classification ModellingDocument2 pagesBAR-Classification ModellingAninda DuttaNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sravanthi AmmuNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sravanthi AmmuNo ratings yet
- Golf Code1Document2 pagesGolf Code1Sweety SekharNo ratings yet
- 21bme145 Exp 4Document3 pages21bme145 Exp 421bme145No ratings yet