
04 LinearRegression PDF
04 LinearRegression PDF
You might also like
- Marsis Playout ManualDocument84 pagesMarsis Playout ManualJāzeps BrencisNo ratings yet
- Class Test - STAT 1011Y (11 April 2017)Document3 pagesClass Test - STAT 1011Y (11 April 2017)Ne PaNo ratings yet
- Ceragon FibeAir IP-20 Split-Mount Release Notes 10.0 Rev B.10 PDFDocument129 pagesCeragon FibeAir IP-20 Split-Mount Release Notes 10.0 Rev B.10 PDFJose Parra100% (2)
- Class 2 ADocument32 pagesClass 2 AAgathaNo ratings yet
- 04 LinearRegressionDocument61 pages04 LinearRegressionjoselazaromrNo ratings yet
- Class 2 BDocument10 pagesClass 2 BAgathaNo ratings yet
- 05 LogisticRegression PDFDocument23 pages05 LogisticRegression PDFAlka ChoudharyNo ratings yet
- 04 LogisticRegressionDocument46 pages04 LogisticRegressiondfcuervooNo ratings yet
- Regression Modelling and Least-Squares: GSA Short Course: Session 1 RegressionDocument6 pagesRegression Modelling and Least-Squares: GSA Short Course: Session 1 Regressioncarles1972mmNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- Class 2 CDocument10 pagesClass 2 CAgathaNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- FALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIDocument6 pagesFALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIKartik SoniNo ratings yet
- Mathematics All Edited Final For RegularDocument138 pagesMathematics All Edited Final For RegularAddaa WondimeNo ratings yet
- Generating Functions: 1 Introductory ExamplesDocument9 pagesGenerating Functions: 1 Introductory Examplesb9902233No ratings yet
- Signal Processing, Representation, Modeling, and Analysis: Alfred M. Bruckstein & Ron KimmelDocument50 pagesSignal Processing, Representation, Modeling, and Analysis: Alfred M. Bruckstein & Ron KimmelIlya KotlovNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- Wilson2020 Part1Document52 pagesWilson2020 Part1hu jackNo ratings yet
- SBE I - Biomedical Data Science (580.421/721) : Ren e Vidal September 7, 2018Document4 pagesSBE I - Biomedical Data Science (580.421/721) : Ren e Vidal September 7, 2018DavidNo ratings yet
- Inference Quals 1992-2019Document66 pagesInference Quals 1992-2019Anirban NathNo ratings yet
- Lecture 1Document48 pagesLecture 1GauravNo ratings yet
- MspacesDocument29 pagesMspacesNitish KumarNo ratings yet
- Fast Unsupervised Texture Segmentation Using Active Contours Model Driven by Bhattacharyya Gradient FlowDocument8 pagesFast Unsupervised Texture Segmentation Using Active Contours Model Driven by Bhattacharyya Gradient FlowMohammed Abdul RahmanNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- MohamedDocument23 pagesMohamedmohammed issaNo ratings yet
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- Problem Set 0Document2 pagesProblem Set 0JUAN BECERRA MENANo ratings yet
- Multiple View Geometry: Exercise Sheet 8Document3 pagesMultiple View Geometry: Exercise Sheet 8Berkay ÖzerbayNo ratings yet
- DNN - M2 - Deep Feedforward NN 23decDocument97 pagesDNN - M2 - Deep Feedforward NN 23decManju Prasad NNo ratings yet
- Day 1 - Rules For DifferentiationDocument44 pagesDay 1 - Rules For DifferentiationRowmell ThomasNo ratings yet
- Lecture 4-Logistic-RegressionDocument50 pagesLecture 4-Logistic-RegressionNada ShaabanNo ratings yet
- Calculus BasicDocument4 pagesCalculus Basic郭大維No ratings yet
- AC-ED L04 - Logistic Regression, RegularizationDocument80 pagesAC-ED L04 - Logistic Regression, RegularizationAbel EspinNo ratings yet
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- Using Second DerivativeDocument23 pagesUsing Second DerivativeAljon Malinao FloresNo ratings yet
- The Power Rule and Other Rules For DifferentiationDocument23 pagesThe Power Rule and Other Rules For DifferentiationAngel EngbinoNo ratings yet
- Lecture 2 AnnotatedDocument60 pagesLecture 2 AnnotatedAdil SadikiNo ratings yet
- ch2 PDFDocument22 pagesch2 PDFJorge Vega RodríguezNo ratings yet
- Worksheet 1Document2 pagesWorksheet 1sultanhsu168No ratings yet
- Introduction To Matlab: Doikon@Document26 pagesIntroduction To Matlab: Doikon@Milind RavindranathNo ratings yet
- Day 1 - Rules For DifferentiationDocument23 pagesDay 1 - Rules For DifferentiationAron paul San MiguelNo ratings yet
- APP2Document3 pagesAPP2Dayana JimenezNo ratings yet
- Rules of DifferentiationDocument24 pagesRules of DifferentiationJordan RonquilloNo ratings yet
- Institute of Actuaries of India: CT3: Probability and Mathematical Statistics Indicative Solution November 2008Document9 pagesInstitute of Actuaries of India: CT3: Probability and Mathematical Statistics Indicative Solution November 2008euticusNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialCajun SefNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialIrmak ErkolNo ratings yet
- ML Week 4 To 10 PDFDocument146 pagesML Week 4 To 10 PDFdcs sfscollegeNo ratings yet
- PRACTICErational Char Find EqtnDocument4 pagesPRACTICErational Char Find EqtnMM J30No ratings yet
- Measurement of Centeral TendencyDocument34 pagesMeasurement of Centeral TendencyWondmageneUrgessaNo ratings yet
- Test 3 BDocument4 pagesTest 3 BHải VũNo ratings yet
- Deep Learning: Models and Optimization: Marco CuturiDocument272 pagesDeep Learning: Models and Optimization: Marco CuturiBojan BankovicNo ratings yet
- 2 D TransformationsDocument41 pages2 D Transformationsakanshalg1No ratings yet
- GopiSir GRNFunc CL9 PDFDocument45 pagesGopiSir GRNFunc CL9 PDFUjwal khatiwadaNo ratings yet
- Theory of Numbers - Lecture 12Document4 pagesTheory of Numbers - Lecture 12ANDHIKA NUGROHONo ratings yet
- SVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationDocument11 pagesSVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationChris DiehlNo ratings yet
- Integración Por Sustitución 1Document6 pagesIntegración Por Sustitución 1jose_dino10005190No ratings yet
- SY 2324 STM 002 Derivative of Log and Exp Func. TrigonometryDocument42 pagesSY 2324 STM 002 Derivative of Log and Exp Func. Trigonometrynicabanados555No ratings yet
- ˆ β = (X X) X y: dyˆ i,i dyDocument7 pagesˆ β = (X X) X y: dyˆ i,i dyvishakhaNo ratings yet
- Nonlife Actuarial Models: Nonparametric Model EstimationDocument41 pagesNonlife Actuarial Models: Nonparametric Model Estimationvoikien01No ratings yet
- Differential EquationsDocument3 pagesDifferential Equationsme21b002No ratings yet
- Decision Trees: Decision Tree Is One of The Most Widely Used andDocument53 pagesDecision Trees: Decision Tree Is One of The Most Widely Used andAlka ChoudharyNo ratings yet
- 05 LogisticRegression PDFDocument23 pages05 LogisticRegression PDFAlka ChoudharyNo ratings yet
- FramesDocument5 pagesFramesAlka ChoudharyNo ratings yet
- Chapter 1Document1 pageChapter 1Alka ChoudharyNo ratings yet
- Bytesense - Forms - Nda Unilateral Signing LogDocument2 pagesBytesense - Forms - Nda Unilateral Signing LogJannatul ferdousNo ratings yet
- IOCL Employee Purchase ProgramDocument4 pagesIOCL Employee Purchase Programmpawan245No ratings yet
- Orthanc Tools JS DocumentationDocument17 pagesOrthanc Tools JS DocumentationRichardson VieiraNo ratings yet
- Usman's ResumeDocument1 pageUsman's Resumebsf2105191No ratings yet
- Midterm Exam (MIL)Document4 pagesMidterm Exam (MIL)NEAH SANTIAGONo ratings yet
- Project Status Report Template-AdvancedDocument3 pagesProject Status Report Template-AdvancedSaikumar SelaNo ratings yet
- Quiz - RadicalsDocument1 pageQuiz - RadicalsLEOGIE LAMUJERNo ratings yet
- Milestone2 Ee3043Document14 pagesMilestone2 Ee3043teoNo ratings yet
- Accounting AnalyticsDocument4 pagesAccounting AnalyticsATUL YADAVNo ratings yet
- Numerical Analysis Course Outline 2020Document2 pagesNumerical Analysis Course Outline 2020Muhammad Ahmad RazaNo ratings yet
- Data Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseDocument24 pagesData Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseLewis TorresNo ratings yet
- Heavy Rock - Thrash MetalDocument101 pagesHeavy Rock - Thrash MetalRichard ONo ratings yet
- Digital AnswersDocument5 pagesDigital AnswersSachin JunejaNo ratings yet
- Department of Computer Science & Engineering: Time TableDocument14 pagesDepartment of Computer Science & Engineering: Time TableDevanshNo ratings yet
- Vehicle Accident Prevention Using Eye Blink Sensor - SUSHANTDocument39 pagesVehicle Accident Prevention Using Eye Blink Sensor - SUSHANTMayugam InfotechNo ratings yet
- SENR11930001Document5 pagesSENR11930001Muhammad RamadhanNo ratings yet
- EtaUltra Modbus MapDocument63 pagesEtaUltra Modbus MapSowarav KumarNo ratings yet
- 2 Osilasi TeredamDocument40 pages2 Osilasi TeredamAPNNo ratings yet
- HP StoreOnce Catalyst Best Practice With DPDocument55 pagesHP StoreOnce Catalyst Best Practice With DPJose MesenNo ratings yet
- MCBT - Teacher Survey ReadinessDocument137 pagesMCBT - Teacher Survey Readinesscristina tamonteNo ratings yet
- AWT ComponentsDocument28 pagesAWT ComponentsMahesh RaghvaniNo ratings yet
- Project Name: 18RRETEPD12430 and Oil Movement Area Units at Rre Installation of Closed Process CondensateDocument3 pagesProject Name: 18RRETEPD12430 and Oil Movement Area Units at Rre Installation of Closed Process CondensateYogesh MittalNo ratings yet
- Diosdado BanataoDocument3 pagesDiosdado BanataoJanice LahoylahoyNo ratings yet
- Jessica Jones: About Me Work HistoryDocument2 pagesJessica Jones: About Me Work HistoryAli RazaNo ratings yet
- Ethical HarkingDocument18 pagesEthical HarkingMakinde Yung FreemanNo ratings yet
- Buy Verified CashApp AccountDocument7 pagesBuy Verified CashApp AccountBuy Verified CashApp AccountNo ratings yet
- 03 - Aq - Xray - ff4Document35 pages03 - Aq - Xray - ff4katabalwa eric100% (2)
- Coursework CO4219-CO7219 - 2021Document4 pagesCoursework CO4219-CO7219 - 2021Binh TruongNo ratings yet



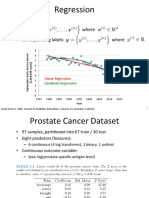




















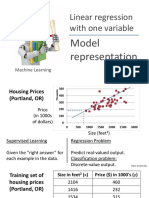




































































Download as pdf or txt
You might also like
- Marsis Playout ManualDocument84 pagesMarsis Playout ManualJāzeps BrencisNo ratings yet
- Class Test - STAT 1011Y (11 April 2017)Document3 pagesClass Test - STAT 1011Y (11 April 2017)Ne PaNo ratings yet
- Ceragon FibeAir IP-20 Split-Mount Release Notes 10.0 Rev B.10 PDFDocument129 pagesCeragon FibeAir IP-20 Split-Mount Release Notes 10.0 Rev B.10 PDFJose Parra100% (2)
- Class 2 ADocument32 pagesClass 2 AAgathaNo ratings yet
- 04 LinearRegressionDocument61 pages04 LinearRegressionjoselazaromrNo ratings yet
- Class 2 BDocument10 pagesClass 2 BAgathaNo ratings yet
- 05 LogisticRegression PDFDocument23 pages05 LogisticRegression PDFAlka ChoudharyNo ratings yet
- 04 LogisticRegressionDocument46 pages04 LogisticRegressiondfcuervooNo ratings yet
- Regression Modelling and Least-Squares: GSA Short Course: Session 1 RegressionDocument6 pagesRegression Modelling and Least-Squares: GSA Short Course: Session 1 Regressioncarles1972mmNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- Class 2 CDocument10 pagesClass 2 CAgathaNo ratings yet
- Applied Machine Learning: One Variable (Simple) Linear RegressionDocument38 pagesApplied Machine Learning: One Variable (Simple) Linear RegressionWanida KrataeNo ratings yet
- FALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIDocument6 pagesFALLSEM2023-24 SWE1002 TH VL2023240103269 2023-10-25 Reference-Material-IIIKartik SoniNo ratings yet
- Mathematics All Edited Final For RegularDocument138 pagesMathematics All Edited Final For RegularAddaa WondimeNo ratings yet
- Generating Functions: 1 Introductory ExamplesDocument9 pagesGenerating Functions: 1 Introductory Examplesb9902233No ratings yet
- Signal Processing, Representation, Modeling, and Analysis: Alfred M. Bruckstein & Ron KimmelDocument50 pagesSignal Processing, Representation, Modeling, and Analysis: Alfred M. Bruckstein & Ron KimmelIlya KotlovNo ratings yet
- Week 04Document101 pagesWeek 04Osii CNo ratings yet
- Wilson2020 Part1Document52 pagesWilson2020 Part1hu jackNo ratings yet
- SBE I - Biomedical Data Science (580.421/721) : Ren e Vidal September 7, 2018Document4 pagesSBE I - Biomedical Data Science (580.421/721) : Ren e Vidal September 7, 2018DavidNo ratings yet
- Inference Quals 1992-2019Document66 pagesInference Quals 1992-2019Anirban NathNo ratings yet
- Lecture 1Document48 pagesLecture 1GauravNo ratings yet
- MspacesDocument29 pagesMspacesNitish KumarNo ratings yet
- Fast Unsupervised Texture Segmentation Using Active Contours Model Driven by Bhattacharyya Gradient FlowDocument8 pagesFast Unsupervised Texture Segmentation Using Active Contours Model Driven by Bhattacharyya Gradient FlowMohammed Abdul RahmanNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- Linear Regression With One Variable: Model RepresentationDocument48 pagesLinear Regression With One Variable: Model RepresentationKo Có tênNo ratings yet
- MohamedDocument23 pagesMohamedmohammed issaNo ratings yet
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- Problem Set 0Document2 pagesProblem Set 0JUAN BECERRA MENANo ratings yet
- Multiple View Geometry: Exercise Sheet 8Document3 pagesMultiple View Geometry: Exercise Sheet 8Berkay ÖzerbayNo ratings yet
- DNN - M2 - Deep Feedforward NN 23decDocument97 pagesDNN - M2 - Deep Feedforward NN 23decManju Prasad NNo ratings yet
- Day 1 - Rules For DifferentiationDocument44 pagesDay 1 - Rules For DifferentiationRowmell ThomasNo ratings yet
- Lecture 4-Logistic-RegressionDocument50 pagesLecture 4-Logistic-RegressionNada ShaabanNo ratings yet
- Calculus BasicDocument4 pagesCalculus Basic郭大維No ratings yet
- AC-ED L04 - Logistic Regression, RegularizationDocument80 pagesAC-ED L04 - Logistic Regression, RegularizationAbel EspinNo ratings yet
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- Using Second DerivativeDocument23 pagesUsing Second DerivativeAljon Malinao FloresNo ratings yet
- The Power Rule and Other Rules For DifferentiationDocument23 pagesThe Power Rule and Other Rules For DifferentiationAngel EngbinoNo ratings yet
- Lecture 2 AnnotatedDocument60 pagesLecture 2 AnnotatedAdil SadikiNo ratings yet
- ch2 PDFDocument22 pagesch2 PDFJorge Vega RodríguezNo ratings yet
- Worksheet 1Document2 pagesWorksheet 1sultanhsu168No ratings yet
- Introduction To Matlab: Doikon@Document26 pagesIntroduction To Matlab: Doikon@Milind RavindranathNo ratings yet
- Day 1 - Rules For DifferentiationDocument23 pagesDay 1 - Rules For DifferentiationAron paul San MiguelNo ratings yet
- APP2Document3 pagesAPP2Dayana JimenezNo ratings yet
- Rules of DifferentiationDocument24 pagesRules of DifferentiationJordan RonquilloNo ratings yet
- Institute of Actuaries of India: CT3: Probability and Mathematical Statistics Indicative Solution November 2008Document9 pagesInstitute of Actuaries of India: CT3: Probability and Mathematical Statistics Indicative Solution November 2008euticusNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialCajun SefNo ratings yet
- 3: Divide and Conquer: Fourier Transform: PolynomialDocument8 pages3: Divide and Conquer: Fourier Transform: PolynomialIrmak ErkolNo ratings yet
- ML Week 4 To 10 PDFDocument146 pagesML Week 4 To 10 PDFdcs sfscollegeNo ratings yet
- PRACTICErational Char Find EqtnDocument4 pagesPRACTICErational Char Find EqtnMM J30No ratings yet
- Measurement of Centeral TendencyDocument34 pagesMeasurement of Centeral TendencyWondmageneUrgessaNo ratings yet
- Test 3 BDocument4 pagesTest 3 BHải VũNo ratings yet
- Deep Learning: Models and Optimization: Marco CuturiDocument272 pagesDeep Learning: Models and Optimization: Marco CuturiBojan BankovicNo ratings yet
- 2 D TransformationsDocument41 pages2 D Transformationsakanshalg1No ratings yet
- GopiSir GRNFunc CL9 PDFDocument45 pagesGopiSir GRNFunc CL9 PDFUjwal khatiwadaNo ratings yet
- Theory of Numbers - Lecture 12Document4 pagesTheory of Numbers - Lecture 12ANDHIKA NUGROHONo ratings yet
- SVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationDocument11 pagesSVM Incremental Learning, Adaptation and Optimization - IJCNN 2003 PresentationChris DiehlNo ratings yet
- Integración Por Sustitución 1Document6 pagesIntegración Por Sustitución 1jose_dino10005190No ratings yet
- SY 2324 STM 002 Derivative of Log and Exp Func. TrigonometryDocument42 pagesSY 2324 STM 002 Derivative of Log and Exp Func. Trigonometrynicabanados555No ratings yet
- ˆ β = (X X) X y: dyˆ i,i dyDocument7 pagesˆ β = (X X) X y: dyˆ i,i dyvishakhaNo ratings yet
- Nonlife Actuarial Models: Nonparametric Model EstimationDocument41 pagesNonlife Actuarial Models: Nonparametric Model Estimationvoikien01No ratings yet
- Differential EquationsDocument3 pagesDifferential Equationsme21b002No ratings yet
- Decision Trees: Decision Tree Is One of The Most Widely Used andDocument53 pagesDecision Trees: Decision Tree Is One of The Most Widely Used andAlka ChoudharyNo ratings yet
- 05 LogisticRegression PDFDocument23 pages05 LogisticRegression PDFAlka ChoudharyNo ratings yet
- FramesDocument5 pagesFramesAlka ChoudharyNo ratings yet
- Chapter 1Document1 pageChapter 1Alka ChoudharyNo ratings yet
- Bytesense - Forms - Nda Unilateral Signing LogDocument2 pagesBytesense - Forms - Nda Unilateral Signing LogJannatul ferdousNo ratings yet
- IOCL Employee Purchase ProgramDocument4 pagesIOCL Employee Purchase Programmpawan245No ratings yet
- Orthanc Tools JS DocumentationDocument17 pagesOrthanc Tools JS DocumentationRichardson VieiraNo ratings yet
- Usman's ResumeDocument1 pageUsman's Resumebsf2105191No ratings yet
- Midterm Exam (MIL)Document4 pagesMidterm Exam (MIL)NEAH SANTIAGONo ratings yet
- Project Status Report Template-AdvancedDocument3 pagesProject Status Report Template-AdvancedSaikumar SelaNo ratings yet
- Quiz - RadicalsDocument1 pageQuiz - RadicalsLEOGIE LAMUJERNo ratings yet
- Milestone2 Ee3043Document14 pagesMilestone2 Ee3043teoNo ratings yet
- Accounting AnalyticsDocument4 pagesAccounting AnalyticsATUL YADAVNo ratings yet
- Numerical Analysis Course Outline 2020Document2 pagesNumerical Analysis Course Outline 2020Muhammad Ahmad RazaNo ratings yet
- Data Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseDocument24 pagesData Integration in A Hadoop-Based Data Lake: A Bioinformatics CaseLewis TorresNo ratings yet
- Heavy Rock - Thrash MetalDocument101 pagesHeavy Rock - Thrash MetalRichard ONo ratings yet
- Digital AnswersDocument5 pagesDigital AnswersSachin JunejaNo ratings yet
- Department of Computer Science & Engineering: Time TableDocument14 pagesDepartment of Computer Science & Engineering: Time TableDevanshNo ratings yet
- Vehicle Accident Prevention Using Eye Blink Sensor - SUSHANTDocument39 pagesVehicle Accident Prevention Using Eye Blink Sensor - SUSHANTMayugam InfotechNo ratings yet
- SENR11930001Document5 pagesSENR11930001Muhammad RamadhanNo ratings yet
- EtaUltra Modbus MapDocument63 pagesEtaUltra Modbus MapSowarav KumarNo ratings yet
- 2 Osilasi TeredamDocument40 pages2 Osilasi TeredamAPNNo ratings yet
- HP StoreOnce Catalyst Best Practice With DPDocument55 pagesHP StoreOnce Catalyst Best Practice With DPJose MesenNo ratings yet
- MCBT - Teacher Survey ReadinessDocument137 pagesMCBT - Teacher Survey Readinesscristina tamonteNo ratings yet
- AWT ComponentsDocument28 pagesAWT ComponentsMahesh RaghvaniNo ratings yet
- Project Name: 18RRETEPD12430 and Oil Movement Area Units at Rre Installation of Closed Process CondensateDocument3 pagesProject Name: 18RRETEPD12430 and Oil Movement Area Units at Rre Installation of Closed Process CondensateYogesh MittalNo ratings yet
- Diosdado BanataoDocument3 pagesDiosdado BanataoJanice LahoylahoyNo ratings yet
- Jessica Jones: About Me Work HistoryDocument2 pagesJessica Jones: About Me Work HistoryAli RazaNo ratings yet
- Ethical HarkingDocument18 pagesEthical HarkingMakinde Yung FreemanNo ratings yet
- Buy Verified CashApp AccountDocument7 pagesBuy Verified CashApp AccountBuy Verified CashApp AccountNo ratings yet
- 03 - Aq - Xray - ff4Document35 pages03 - Aq - Xray - ff4katabalwa eric100% (2)
- Coursework CO4219-CO7219 - 2021Document4 pagesCoursework CO4219-CO7219 - 2021Binh TruongNo ratings yet