
0000 - Semi-Automatic Object Tracking in Video Sequences PDF
0000 - Semi-Automatic Object Tracking in Video Sequences PDF
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- FrancisAsuncion CostOfQualityDocument2 pagesFrancisAsuncion CostOfQualityMohamed MidouneNo ratings yet
- Project Organizational Chart of Wilmont PDFDocument1 pageProject Organizational Chart of Wilmont PDFMohamed MidouneNo ratings yet
- Project Charter PDFDocument2 pagesProject Charter PDFMohamed MidouneNo ratings yet
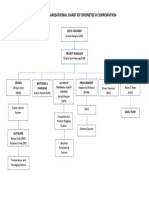
- Project Organizational Chart of Dronetech Corporation PDFDocument1 pageProject Organizational Chart of Dronetech Corporation PDFMohamed MidouneNo ratings yet
- Cost of Quality Assessment: Project Name Revision Number Revision DateDocument2 pagesCost of Quality Assessment: Project Name Revision Number Revision DateMohamed MidouneNo ratings yet
- Random Subcubes As A Toy Model For Constraint Satisfaction Problems. Mora ZdeborovaDocument22 pagesRandom Subcubes As A Toy Model For Constraint Satisfaction Problems. Mora ZdeborovaImperatur PeregrinusNo ratings yet
- QIPV 8 - Functions of RandomVariablesDocument11 pagesQIPV 8 - Functions of RandomVariablesMPD19I004 MADDUKURI SRINo ratings yet
- Ist Lecture PDFDocument4 pagesIst Lecture PDFGaurav KhangwalNo ratings yet
- Approximations: Rounding and Truncation: ExamplesDocument8 pagesApproximations: Rounding and Truncation: ExamplesGuestNo ratings yet
- Chapter 10 Worked SolutionsDocument82 pagesChapter 10 Worked SolutionspaulNo ratings yet
- Operations On Functions: ObjectivesDocument4 pagesOperations On Functions: ObjectivesRyan WilsonNo ratings yet
- Direct Numerical Integration MethodsDocument19 pagesDirect Numerical Integration MethodsallentvmNo ratings yet
- Normed Linear Space-1Document16 pagesNormed Linear Space-1P R SAMBHU RAJNo ratings yet
- Mohammed Hichem Mortad Counterexamples in Operator TheoryDocument613 pagesMohammed Hichem Mortad Counterexamples in Operator Theorydr.manarabdallaNo ratings yet
- MATHEMATICSDocument2 pagesMATHEMATICSLean Amara VillarNo ratings yet
- Mod - Concept For JEE/NEETDocument34 pagesMod - Concept For JEE/NEETujjwal pathakNo ratings yet
- CH 1 Systems of Linear EquationsDocument39 pagesCH 1 Systems of Linear EquationsMaeriel AggabaoNo ratings yet
- An Intuitive Guide To Linear AlgebraDocument16 pagesAn Intuitive Guide To Linear AlgebrafaisalNo ratings yet
- B.Sc. Mechanical Engineering 2018 & OnwardDocument38 pagesB.Sc. Mechanical Engineering 2018 & OnwardMohtasham NaeemNo ratings yet
- (Lecture Notes) Daniel Bump-Hecke Algebras (2010)Document120 pages(Lecture Notes) Daniel Bump-Hecke Algebras (2010)Marcelo Hernández CaroNo ratings yet
- Lesson 6 - Systems of InequalitiesDocument25 pagesLesson 6 - Systems of InequalitiesEd VillNo ratings yet
- Homemade ProblemsDocument48 pagesHomemade Problemsvidyakumari808940No ratings yet
- Sets and Relations: Dipanwita DebnathDocument46 pagesSets and Relations: Dipanwita DebnathDipanwita DebnathNo ratings yet
- CH 4. Trigonometry (Math +1)Document42 pagesCH 4. Trigonometry (Math +1)Dinesh BabuNo ratings yet
- TALLER DE SUPERACIÓN No. 1 ÁLGEBRADocument3 pagesTALLER DE SUPERACIÓN No. 1 ÁLGEBRALaura RomeroNo ratings yet
- Algebra 2 Honors PBADocument4 pagesAlgebra 2 Honors PBAJulieNo ratings yet
- MATHDocument2 pagesMATHBanupriya BalasubramanianNo ratings yet
- Turbulent Dispersion ForceDocument4 pagesTurbulent Dispersion Forceamin_zargaranNo ratings yet
- Path IntegralDocument32 pagesPath IntegralviskaNo ratings yet
- Load Flow: Power System Analysis - Epo 552Document12 pagesLoad Flow: Power System Analysis - Epo 552Aisamuddin SubaniNo ratings yet
- Exponential Moving AverageDocument9 pagesExponential Moving AverageReneNo ratings yet
- Functions and Quadratics Topic 2Document8 pagesFunctions and Quadratics Topic 2Syed Abdul Mussaver ShahNo ratings yet
- Exercise-I: 3 3 2 5 2 3 X X X X Cos Log Sin Log 3 2 SinDocument7 pagesExercise-I: 3 3 2 5 2 3 X X X X Cos Log Sin Log 3 2 SinJonathan ParkerNo ratings yet
- 3.3 Characteristics of Polynomial Functions in Factored FormDocument3 pages3.3 Characteristics of Polynomial Functions in Factored FormAshley ElliottNo ratings yet
- Neural Networks For Machine Learning: Lecture 6a Overview of Mini - Batch Gradient DescentDocument31 pagesNeural Networks For Machine Learning: Lecture 6a Overview of Mini - Batch Gradient DescentMario PeñaNo ratings yet











































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (541)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- FrancisAsuncion CostOfQualityDocument2 pagesFrancisAsuncion CostOfQualityMohamed MidouneNo ratings yet
- Project Organizational Chart of Wilmont PDFDocument1 pageProject Organizational Chart of Wilmont PDFMohamed MidouneNo ratings yet
- Project Charter PDFDocument2 pagesProject Charter PDFMohamed MidouneNo ratings yet
- Project Organizational Chart of Dronetech Corporation PDFDocument1 pageProject Organizational Chart of Dronetech Corporation PDFMohamed MidouneNo ratings yet
- Cost of Quality Assessment: Project Name Revision Number Revision DateDocument2 pagesCost of Quality Assessment: Project Name Revision Number Revision DateMohamed MidouneNo ratings yet
- Random Subcubes As A Toy Model For Constraint Satisfaction Problems. Mora ZdeborovaDocument22 pagesRandom Subcubes As A Toy Model For Constraint Satisfaction Problems. Mora ZdeborovaImperatur PeregrinusNo ratings yet
- QIPV 8 - Functions of RandomVariablesDocument11 pagesQIPV 8 - Functions of RandomVariablesMPD19I004 MADDUKURI SRINo ratings yet
- Ist Lecture PDFDocument4 pagesIst Lecture PDFGaurav KhangwalNo ratings yet
- Approximations: Rounding and Truncation: ExamplesDocument8 pagesApproximations: Rounding and Truncation: ExamplesGuestNo ratings yet
- Chapter 10 Worked SolutionsDocument82 pagesChapter 10 Worked SolutionspaulNo ratings yet
- Operations On Functions: ObjectivesDocument4 pagesOperations On Functions: ObjectivesRyan WilsonNo ratings yet
- Direct Numerical Integration MethodsDocument19 pagesDirect Numerical Integration MethodsallentvmNo ratings yet
- Normed Linear Space-1Document16 pagesNormed Linear Space-1P R SAMBHU RAJNo ratings yet
- Mohammed Hichem Mortad Counterexamples in Operator TheoryDocument613 pagesMohammed Hichem Mortad Counterexamples in Operator Theorydr.manarabdallaNo ratings yet
- MATHEMATICSDocument2 pagesMATHEMATICSLean Amara VillarNo ratings yet
- Mod - Concept For JEE/NEETDocument34 pagesMod - Concept For JEE/NEETujjwal pathakNo ratings yet
- CH 1 Systems of Linear EquationsDocument39 pagesCH 1 Systems of Linear EquationsMaeriel AggabaoNo ratings yet
- An Intuitive Guide To Linear AlgebraDocument16 pagesAn Intuitive Guide To Linear AlgebrafaisalNo ratings yet
- B.Sc. Mechanical Engineering 2018 & OnwardDocument38 pagesB.Sc. Mechanical Engineering 2018 & OnwardMohtasham NaeemNo ratings yet
- (Lecture Notes) Daniel Bump-Hecke Algebras (2010)Document120 pages(Lecture Notes) Daniel Bump-Hecke Algebras (2010)Marcelo Hernández CaroNo ratings yet
- Lesson 6 - Systems of InequalitiesDocument25 pagesLesson 6 - Systems of InequalitiesEd VillNo ratings yet
- Homemade ProblemsDocument48 pagesHomemade Problemsvidyakumari808940No ratings yet
- Sets and Relations: Dipanwita DebnathDocument46 pagesSets and Relations: Dipanwita DebnathDipanwita DebnathNo ratings yet
- CH 4. Trigonometry (Math +1)Document42 pagesCH 4. Trigonometry (Math +1)Dinesh BabuNo ratings yet
- TALLER DE SUPERACIÓN No. 1 ÁLGEBRADocument3 pagesTALLER DE SUPERACIÓN No. 1 ÁLGEBRALaura RomeroNo ratings yet
- Algebra 2 Honors PBADocument4 pagesAlgebra 2 Honors PBAJulieNo ratings yet
- MATHDocument2 pagesMATHBanupriya BalasubramanianNo ratings yet
- Turbulent Dispersion ForceDocument4 pagesTurbulent Dispersion Forceamin_zargaranNo ratings yet
- Path IntegralDocument32 pagesPath IntegralviskaNo ratings yet
- Load Flow: Power System Analysis - Epo 552Document12 pagesLoad Flow: Power System Analysis - Epo 552Aisamuddin SubaniNo ratings yet
- Exponential Moving AverageDocument9 pagesExponential Moving AverageReneNo ratings yet
- Functions and Quadratics Topic 2Document8 pagesFunctions and Quadratics Topic 2Syed Abdul Mussaver ShahNo ratings yet
- Exercise-I: 3 3 2 5 2 3 X X X X Cos Log Sin Log 3 2 SinDocument7 pagesExercise-I: 3 3 2 5 2 3 X X X X Cos Log Sin Log 3 2 SinJonathan ParkerNo ratings yet
- 3.3 Characteristics of Polynomial Functions in Factored FormDocument3 pages3.3 Characteristics of Polynomial Functions in Factored FormAshley ElliottNo ratings yet
- Neural Networks For Machine Learning: Lecture 6a Overview of Mini - Batch Gradient DescentDocument31 pagesNeural Networks For Machine Learning: Lecture 6a Overview of Mini - Batch Gradient DescentMario PeñaNo ratings yet