
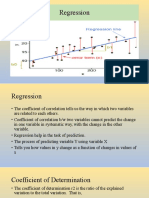
10 Regression Analysis
10 Regression Analysis
You might also like
- 0-WD792-CJ250-01504 - Rev.B - Inspection and Test Plan For Instrument Cables InstallationDocument4 pages0-WD792-CJ250-01504 - Rev.B - Inspection and Test Plan For Instrument Cables InstallationResearcherNo ratings yet
- Developments in International Safety Glass Test Method StandardsDocument30 pagesDevelopments in International Safety Glass Test Method StandardsKedar A. MalusareNo ratings yet
- Waiting Time ParadoxDocument9 pagesWaiting Time ParadoxmelanocitosNo ratings yet
- CADS Bearing PileDocument42 pagesCADS Bearing PileDavidNo ratings yet
- RX 3240 HFDocument3 pagesRX 3240 HFRobert XieNo ratings yet
- Chapter 2-Descriptive StatisticsDocument18 pagesChapter 2-Descriptive StatisticsAyn RandNo ratings yet
- Correlation Between SPT N Value and Shear Wave VelocityDocument20 pagesCorrelation Between SPT N Value and Shear Wave VelocityprateeksuperNo ratings yet
- Eurocode 2: Design of Concrete StructuresDocument42 pagesEurocode 2: Design of Concrete StructuresLim Shwe WenNo ratings yet
- Corporate Finance - Assignment September 2017 isuTxyQsX4 PDFDocument3 pagesCorporate Finance - Assignment September 2017 isuTxyQsX4 PDFA Kaur MarwahNo ratings yet
- 02 Response To Harmonic & Impulsive LoadingDocument14 pages02 Response To Harmonic & Impulsive LoadingMar MartillanoNo ratings yet
- Latex Workshop PDFDocument159 pagesLatex Workshop PDFsimranNo ratings yet
- Corporate Finance-Assignment June 2017 PDFDocument2 pagesCorporate Finance-Assignment June 2017 PDFnbala.iyerNo ratings yet
- Assignment DMBA103 MBA 1 Set-1 and 2 Mar 2022Document3 pagesAssignment DMBA103 MBA 1 Set-1 and 2 Mar 2022Assignment SolveNo ratings yet
- Assignment - Corporate Finance Capital Budgeting Case Study Project Details Year Project A Project BDocument4 pagesAssignment - Corporate Finance Capital Budgeting Case Study Project Details Year Project A Project BAnshum SethiNo ratings yet
- Brief Review of TensorsDocument15 pagesBrief Review of TensorsG Hernán Chávez LandázuriNo ratings yet
- TGN 1 6 Notional Loading Edited3Document3 pagesTGN 1 6 Notional Loading Edited3thowchin100% (1)
- School of Egineering and TechnologyDocument5 pagesSchool of Egineering and TechnologyChot BensonNo ratings yet
- Technical Guidance Notes: An IntroductionDocument1 pageTechnical Guidance Notes: An IntroductionMohanNo ratings yet
- MGF, Discrete Statistical Distributions - 551Document49 pagesMGF, Discrete Statistical Distributions - 551SatheeskumarNo ratings yet
- Structural DesignDocument2 pagesStructural DesigncustomerxNo ratings yet
- Multiple RegressionDocument20 pagesMultiple RegressiontariqravianNo ratings yet
- Chap 3 Weighted Residual and Energy Method For 1D Problems: Finite Element Analysis and Design Nam-Ho KimDocument47 pagesChap 3 Weighted Residual and Energy Method For 1D Problems: Finite Element Analysis and Design Nam-Ho KimNarendra KulkarniNo ratings yet
- Beam TheoryDocument61 pagesBeam Theorysaleemm_2No ratings yet
- fx-991EX Quick Reference Guide PDFDocument48 pagesfx-991EX Quick Reference Guide PDFSblNo ratings yet
- Flat Slabs Under EqDocument182 pagesFlat Slabs Under EqAWAN88855No ratings yet
- 1.040 Project Management: Mit OpencoursewareDocument21 pages1.040 Project Management: Mit OpencoursewareAlfalej MourbiNo ratings yet
- BPG Rationalising Flat SlabDocument4 pagesBPG Rationalising Flat SlabAlf HorsemanNo ratings yet
- Linear Static Analysis of A Cantilever Beam (SI Units) : WorkshopDocument16 pagesLinear Static Analysis of A Cantilever Beam (SI Units) : WorkshophfathollahiNo ratings yet
- DIN 1052 Checks PDFDocument22 pagesDIN 1052 Checks PDFxyzhynNo ratings yet
- PERT ExampleDocument9 pagesPERT ExampleRenad ObaidNo ratings yet
- Financial StatementDocument36 pagesFinancial StatementKopal GargNo ratings yet
- Module 6A Estimating RelationshipsDocument104 pagesModule 6A Estimating Relationshipscarolinelouise.bagsik.acctNo ratings yet
- Chap3 - Multiple RegressionDocument56 pagesChap3 - Multiple RegressionNguyễn Lê Minh AnhNo ratings yet
- Quarter 4 LasDocument20 pagesQuarter 4 LasDECEDERIO CANDOLENo ratings yet
- Introduction To Machine Learning Week 2 AssignmentDocument8 pagesIntroduction To Machine Learning Week 2 AssignmentAkash barapatreNo ratings yet
- Pearson Correlation CoefficientDocument14 pagesPearson Correlation CoefficientGideon GallardoNo ratings yet
- Lesson 3 - Quality Control and Calculations - SchoologyDocument3 pagesLesson 3 - Quality Control and Calculations - SchoologydyoNo ratings yet
- Analysis Interpretation and Use of Test DataDocument50 pagesAnalysis Interpretation and Use of Test DataJayson EsperanzaNo ratings yet
- STATQ3LAS10Document6 pagesSTATQ3LAS10respondekylamaeNo ratings yet
- To Prepare and Validate Instrument in ResearchDocument12 pagesTo Prepare and Validate Instrument in ResearchAchmad MuttaqienNo ratings yet
- Regression AnalysisDocument5 pagesRegression AnalysisAllen Kurt RamosNo ratings yet
- Complete - Lesson 2 CorrDocument26 pagesComplete - Lesson 2 CorrMARION JUMAO-AS GORDONo ratings yet
- Lecture 2: MRA and Inference: Dr. Yundan GongDocument52 pagesLecture 2: MRA and Inference: Dr. Yundan GongVIKTORIIANo ratings yet
- 11-Simple Linear RegressionDocument25 pages11-Simple Linear RegressionMUHAMMAD AZRAI MOHD ZUNAIDINo ratings yet
- Module 5 - Lesson 5Document8 pagesModule 5 - Lesson 5Angelica PatagNo ratings yet
- Week11-Lecture 11ML Algorithms Metrics - UpdatedDocument29 pagesWeek11-Lecture 11ML Algorithms Metrics - UpdatedfgfdgfdgfdNo ratings yet
- Evaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDocument13 pagesEvaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDhananjay ChhabraNo ratings yet
- Chapter 6 (Part Ii)Document41 pagesChapter 6 (Part Ii)Natasha GhazaliNo ratings yet
- Measures of DispersionDocument17 pagesMeasures of DispersionAthar AslamNo ratings yet
- RegressionDocument8 pagesRegressionFast ComputersNo ratings yet
- Correlation and RegrationDocument57 pagesCorrelation and RegrationShoyo HinataNo ratings yet
- Econometrics Assignment AnswerDocument13 pagesEconometrics Assignment Answertigistugizaw37No ratings yet
- Lecture Z TestDocument5 pagesLecture Z TestMarlon MoraNo ratings yet
- Multiple Linear Regression: MMA1402 - Regression and Time Series ModelingDocument16 pagesMultiple Linear Regression: MMA1402 - Regression and Time Series ModelingKaneki KenNo ratings yet
- Correlation and Linear RegressionDocument25 pagesCorrelation and Linear RegressionMudita ChawlaNo ratings yet
- CH 14Document12 pagesCH 14Piyush rajNo ratings yet
- Linear - Regression & Evaluation MetricsDocument31 pagesLinear - Regression & Evaluation Metricsreshma acharyaNo ratings yet
- MODULE 5 and 6 STATISTICS AND PROBABILITY - Docx (1) - PDFDocument9 pagesMODULE 5 and 6 STATISTICS AND PROBABILITY - Docx (1) - PDFGraecel Ramirez100% (2)
- Validity and Reliability: I Qra Development Academy Reporter: Nur - Salam Sultan SEPT. 21, 2019Document22 pagesValidity and Reliability: I Qra Development Academy Reporter: Nur - Salam Sultan SEPT. 21, 2019Nur-salam SultanNo ratings yet
- Schaum's Easy Outline of Probability and Statistics, Revised EditionFrom EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionNo ratings yet
- 2022 Is Online and Distance LearningDocument13 pages2022 Is Online and Distance LearningJohn Lewis SuguitanNo ratings yet
- RRL ExcellenceDocument5 pagesRRL ExcellenceJohn Lewis SuguitanNo ratings yet
- RIZAL031 Life and Works of RizalDocument1 pageRIZAL031 Life and Works of RizalJohn Lewis SuguitanNo ratings yet
- PROCESSORIENTEDAssessmentDocument1 pagePROCESSORIENTEDAssessmentJohn Lewis SuguitanNo ratings yet
- PhilosophyDocument11 pagesPhilosophyJohn Lewis SuguitanNo ratings yet
- TOS IfurungDocument2 pagesTOS IfurungJohn Lewis SuguitanNo ratings yet
- SS 3 Human GeographyDocument8 pagesSS 3 Human GeographyJohn Lewis SuguitanNo ratings yet
- MCTQ PearlDocument1 pageMCTQ PearlJohn Lewis SuguitanNo ratings yet
- ErrorDocument1 pageErrorJohn Lewis SuguitanNo ratings yet
- Assessment ToolDocument1 pageAssessment ToolJohn Lewis SuguitanNo ratings yet
- BALIKAS NI ILOKANO DaniwDocument1 pageBALIKAS NI ILOKANO DaniwJohn Lewis SuguitanNo ratings yet
- Hipparchus FlorenceNightingaleDocument1 pageHipparchus FlorenceNightingaleJohn Lewis SuguitanNo ratings yet
- Earth ScienceDocument9 pagesEarth ScienceJohn Lewis SuguitanNo ratings yet
- Edited LazoDocument53 pagesEdited LazoJohn Lewis SuguitanNo ratings yet
- Pe 1Document4 pagesPe 1John Lewis SuguitanNo ratings yet
- TNT 12 Q1 - 0101 - PS - Definition, Characteristics, and Elements of A TrendDocument43 pagesTNT 12 Q1 - 0101 - PS - Definition, Characteristics, and Elements of A TrendJoed TapuroNo ratings yet
- SS 4 Asian StudiesDocument5 pagesSS 4 Asian StudiesJohn Lewis SuguitanNo ratings yet
- SS 5 Physical GeographyDocument5 pagesSS 5 Physical GeographyJohn Lewis SuguitanNo ratings yet
- ONE WAY TOS IfurungDocument2 pagesONE WAY TOS IfurungJohn Lewis SuguitanNo ratings yet
- RubricDocument1 pageRubricJohn Lewis SuguitanNo ratings yet
- Research Proposal Final GROUP 1 CLUSTER 2 FOR PRINTDocument49 pagesResearch Proposal Final GROUP 1 CLUSTER 2 FOR PRINTJohn Lewis SuguitanNo ratings yet
- Weathering 2Document1 pageWeathering 2John Lewis SuguitanNo ratings yet
- Igneous Rock Metamorphic RockDocument2 pagesIgneous Rock Metamorphic RockJohn Lewis SuguitanNo ratings yet
- Ed217 Counselling SyllabusDocument3 pagesEd217 Counselling SyllabusJohn Lewis SuguitanNo ratings yet
- Research Methodology: Divine Word College of Laoag Graduate SchoolDocument12 pagesResearch Methodology: Divine Word College of Laoag Graduate SchoolJohn Lewis SuguitanNo ratings yet
- 2020-2021 English SyllabusDocument6 pages2020-2021 English SyllabusJohn Lewis SuguitanNo ratings yet
- Redmarks LazoDocument54 pagesRedmarks LazoJohn Lewis SuguitanNo ratings yet
- 2022 Is Online and Distance LearningDocument13 pages2022 Is Online and Distance LearningJohn Lewis SuguitanNo ratings yet
- The Problem Rationale: Divine Word College of Laoag Graduate SchoolDocument20 pagesThe Problem Rationale: Divine Word College of Laoag Graduate SchoolJohn Lewis SuguitanNo ratings yet
- Guided Online/Offline Active Learning (Goal) Videos in Mathematics 3Document16 pagesGuided Online/Offline Active Learning (Goal) Videos in Mathematics 3John Lewis SuguitanNo ratings yet
- Chapter 15Document43 pagesChapter 15mannsahil72No ratings yet
- Predictive Modelling Project - n1Document36 pagesPredictive Modelling Project - n1Girish Chadha100% (4)
- Oliver MonographDocument217 pagesOliver MonographOliver EboyNo ratings yet
- Researching On Factors Affecting Consumers' Decision To Use E5 BIOFUEL in Hanoi CityDocument45 pagesResearching On Factors Affecting Consumers' Decision To Use E5 BIOFUEL in Hanoi CityNhư HảoNo ratings yet
- The Effect of Covid-19 in KabaddiDocument25 pagesThe Effect of Covid-19 in KabaddiShadman RafidNo ratings yet
- The Moderating Effect of Profitability On The Relationship Between Ownership Structure and Corporate Tax Avoidance in Nigeria ListDocument16 pagesThe Moderating Effect of Profitability On The Relationship Between Ownership Structure and Corporate Tax Avoidance in Nigeria ListDivine ugboduNo ratings yet
- 10 - Eda To Prediction DietanicDocument21 pages10 - Eda To Prediction DietanicKhan RafiNo ratings yet
- A Caution Regarding Rules of Thumb For Variance Inflation FactorsDocument18 pagesA Caution Regarding Rules of Thumb For Variance Inflation FactorsParag Jyoti DuttaNo ratings yet
- Merger and AcquisitionsDocument8 pagesMerger and AcquisitionsSandeep SahooNo ratings yet
- Corporate Governance and Cost of Capital in Oecd Countries: Aws AlharesDocument21 pagesCorporate Governance and Cost of Capital in Oecd Countries: Aws AlharesOZZYMANNo ratings yet
- Primer of Applied Regression Analysis of Variance 3Rd Edition Edition Stanton A Glantz All ChapterDocument67 pagesPrimer of Applied Regression Analysis of Variance 3Rd Edition Edition Stanton A Glantz All Chapterjeanette.rasmussen227100% (4)
- Jasa (Jurnal Akuntansi, Audit Dan Sistem Informasi Akuntansi) Vol. 4 No. 1 /april 2020 Issn 2550-0732 Print / Issn 2655-8319 OnlineDocument13 pagesJasa (Jurnal Akuntansi, Audit Dan Sistem Informasi Akuntansi) Vol. 4 No. 1 /april 2020 Issn 2550-0732 Print / Issn 2655-8319 OnlineMoch MunjiNo ratings yet
- Tutorial13 Basic TimeSeriesDocument80 pagesTutorial13 Basic TimeSeriesGhulam NabiNo ratings yet
- Retail Supply Chain Service Levels The Role of Inventory StorageDocument24 pagesRetail Supply Chain Service Levels The Role of Inventory StorageBassma EL GHALBZOURINo ratings yet
- PMIRDocument124 pagesPMIRhashvishuNo ratings yet
- Laekemariam Haile PDFDocument26 pagesLaekemariam Haile PDFchiroNo ratings yet
- Interview QuestionsDocument13 pagesInterview QuestionsPrakash ChandraNo ratings yet
- Determinants of Career Change of Overseas Filipino Professionals in The Middle EastDocument14 pagesDeterminants of Career Change of Overseas Filipino Professionals in The Middle EastLee Hock SengNo ratings yet
- 810007Document4 pages810007Vasim ShaikhNo ratings yet
- Pratama 2020Document4 pagesPratama 2020IrailtonNo ratings yet
- Impact of Provision of Litigation Supports Through Forensic Investigations On Corporate Fraud Prevention in NigeriaDocument8 pagesImpact of Provision of Litigation Supports Through Forensic Investigations On Corporate Fraud Prevention in NigeriaPremier Publishers100% (1)
- Final Report Aman DwivediDocument48 pagesFinal Report Aman Dwivediaman DwivediNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- Najed Massad Sulaiman AlrawashdehDocument53 pagesNajed Massad Sulaiman AlrawashdehNajed RawashdehNo ratings yet
- Trans Employees, Transitioning, and Job SatisfactionDocument54 pagesTrans Employees, Transitioning, and Job SatisfactionUsman AsgharNo ratings yet
- Bagozzi - 1984 - Expectancy-Value Attitude Models An Analysis of Critical Measurement Issues PDFDocument16 pagesBagozzi - 1984 - Expectancy-Value Attitude Models An Analysis of Critical Measurement Issues PDFDante EdwardsNo ratings yet
- Rogersetal JPSP InPress ManuscriptPrepublicationDocument87 pagesRogersetal JPSP InPress ManuscriptPrepublicationApy BobbyNo ratings yet
- Risk ReportingDocument20 pagesRisk ReportingRomy WidjajaNo ratings yet
- Internasional 5Document9 pagesInternasional 5M Rizki Rabbani 1802112922No ratings yet
- Effect of Service Quality On Customer Loyalty: A Study of Hotels in EthiopiaDocument10 pagesEffect of Service Quality On Customer Loyalty: A Study of Hotels in EthiopiaIAEME PublicationNo ratings yet





















































































































Download as pdf or txt
You might also like
- 0-WD792-CJ250-01504 - Rev.B - Inspection and Test Plan For Instrument Cables InstallationDocument4 pages0-WD792-CJ250-01504 - Rev.B - Inspection and Test Plan For Instrument Cables InstallationResearcherNo ratings yet
- Developments in International Safety Glass Test Method StandardsDocument30 pagesDevelopments in International Safety Glass Test Method StandardsKedar A. MalusareNo ratings yet
- Waiting Time ParadoxDocument9 pagesWaiting Time ParadoxmelanocitosNo ratings yet
- CADS Bearing PileDocument42 pagesCADS Bearing PileDavidNo ratings yet
- RX 3240 HFDocument3 pagesRX 3240 HFRobert XieNo ratings yet
- Chapter 2-Descriptive StatisticsDocument18 pagesChapter 2-Descriptive StatisticsAyn RandNo ratings yet
- Correlation Between SPT N Value and Shear Wave VelocityDocument20 pagesCorrelation Between SPT N Value and Shear Wave VelocityprateeksuperNo ratings yet
- Eurocode 2: Design of Concrete StructuresDocument42 pagesEurocode 2: Design of Concrete StructuresLim Shwe WenNo ratings yet
- Corporate Finance - Assignment September 2017 isuTxyQsX4 PDFDocument3 pagesCorporate Finance - Assignment September 2017 isuTxyQsX4 PDFA Kaur MarwahNo ratings yet
- 02 Response To Harmonic & Impulsive LoadingDocument14 pages02 Response To Harmonic & Impulsive LoadingMar MartillanoNo ratings yet
- Latex Workshop PDFDocument159 pagesLatex Workshop PDFsimranNo ratings yet
- Corporate Finance-Assignment June 2017 PDFDocument2 pagesCorporate Finance-Assignment June 2017 PDFnbala.iyerNo ratings yet
- Assignment DMBA103 MBA 1 Set-1 and 2 Mar 2022Document3 pagesAssignment DMBA103 MBA 1 Set-1 and 2 Mar 2022Assignment SolveNo ratings yet
- Assignment - Corporate Finance Capital Budgeting Case Study Project Details Year Project A Project BDocument4 pagesAssignment - Corporate Finance Capital Budgeting Case Study Project Details Year Project A Project BAnshum SethiNo ratings yet
- Brief Review of TensorsDocument15 pagesBrief Review of TensorsG Hernán Chávez LandázuriNo ratings yet
- TGN 1 6 Notional Loading Edited3Document3 pagesTGN 1 6 Notional Loading Edited3thowchin100% (1)
- School of Egineering and TechnologyDocument5 pagesSchool of Egineering and TechnologyChot BensonNo ratings yet
- Technical Guidance Notes: An IntroductionDocument1 pageTechnical Guidance Notes: An IntroductionMohanNo ratings yet
- MGF, Discrete Statistical Distributions - 551Document49 pagesMGF, Discrete Statistical Distributions - 551SatheeskumarNo ratings yet
- Structural DesignDocument2 pagesStructural DesigncustomerxNo ratings yet
- Multiple RegressionDocument20 pagesMultiple RegressiontariqravianNo ratings yet
- Chap 3 Weighted Residual and Energy Method For 1D Problems: Finite Element Analysis and Design Nam-Ho KimDocument47 pagesChap 3 Weighted Residual and Energy Method For 1D Problems: Finite Element Analysis and Design Nam-Ho KimNarendra KulkarniNo ratings yet
- Beam TheoryDocument61 pagesBeam Theorysaleemm_2No ratings yet
- fx-991EX Quick Reference Guide PDFDocument48 pagesfx-991EX Quick Reference Guide PDFSblNo ratings yet
- Flat Slabs Under EqDocument182 pagesFlat Slabs Under EqAWAN88855No ratings yet
- 1.040 Project Management: Mit OpencoursewareDocument21 pages1.040 Project Management: Mit OpencoursewareAlfalej MourbiNo ratings yet
- BPG Rationalising Flat SlabDocument4 pagesBPG Rationalising Flat SlabAlf HorsemanNo ratings yet
- Linear Static Analysis of A Cantilever Beam (SI Units) : WorkshopDocument16 pagesLinear Static Analysis of A Cantilever Beam (SI Units) : WorkshophfathollahiNo ratings yet
- DIN 1052 Checks PDFDocument22 pagesDIN 1052 Checks PDFxyzhynNo ratings yet
- PERT ExampleDocument9 pagesPERT ExampleRenad ObaidNo ratings yet
- Financial StatementDocument36 pagesFinancial StatementKopal GargNo ratings yet
- Module 6A Estimating RelationshipsDocument104 pagesModule 6A Estimating Relationshipscarolinelouise.bagsik.acctNo ratings yet
- Chap3 - Multiple RegressionDocument56 pagesChap3 - Multiple RegressionNguyễn Lê Minh AnhNo ratings yet
- Quarter 4 LasDocument20 pagesQuarter 4 LasDECEDERIO CANDOLENo ratings yet
- Introduction To Machine Learning Week 2 AssignmentDocument8 pagesIntroduction To Machine Learning Week 2 AssignmentAkash barapatreNo ratings yet
- Pearson Correlation CoefficientDocument14 pagesPearson Correlation CoefficientGideon GallardoNo ratings yet
- Lesson 3 - Quality Control and Calculations - SchoologyDocument3 pagesLesson 3 - Quality Control and Calculations - SchoologydyoNo ratings yet
- Analysis Interpretation and Use of Test DataDocument50 pagesAnalysis Interpretation and Use of Test DataJayson EsperanzaNo ratings yet
- STATQ3LAS10Document6 pagesSTATQ3LAS10respondekylamaeNo ratings yet
- To Prepare and Validate Instrument in ResearchDocument12 pagesTo Prepare and Validate Instrument in ResearchAchmad MuttaqienNo ratings yet
- Regression AnalysisDocument5 pagesRegression AnalysisAllen Kurt RamosNo ratings yet
- Complete - Lesson 2 CorrDocument26 pagesComplete - Lesson 2 CorrMARION JUMAO-AS GORDONo ratings yet
- Lecture 2: MRA and Inference: Dr. Yundan GongDocument52 pagesLecture 2: MRA and Inference: Dr. Yundan GongVIKTORIIANo ratings yet
- 11-Simple Linear RegressionDocument25 pages11-Simple Linear RegressionMUHAMMAD AZRAI MOHD ZUNAIDINo ratings yet
- Module 5 - Lesson 5Document8 pagesModule 5 - Lesson 5Angelica PatagNo ratings yet
- Week11-Lecture 11ML Algorithms Metrics - UpdatedDocument29 pagesWeek11-Lecture 11ML Algorithms Metrics - UpdatedfgfdgfdgfdNo ratings yet
- Evaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDocument13 pagesEvaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDhananjay ChhabraNo ratings yet
- Chapter 6 (Part Ii)Document41 pagesChapter 6 (Part Ii)Natasha GhazaliNo ratings yet
- Measures of DispersionDocument17 pagesMeasures of DispersionAthar AslamNo ratings yet
- RegressionDocument8 pagesRegressionFast ComputersNo ratings yet
- Correlation and RegrationDocument57 pagesCorrelation and RegrationShoyo HinataNo ratings yet
- Econometrics Assignment AnswerDocument13 pagesEconometrics Assignment Answertigistugizaw37No ratings yet
- Lecture Z TestDocument5 pagesLecture Z TestMarlon MoraNo ratings yet
- Multiple Linear Regression: MMA1402 - Regression and Time Series ModelingDocument16 pagesMultiple Linear Regression: MMA1402 - Regression and Time Series ModelingKaneki KenNo ratings yet
- Correlation and Linear RegressionDocument25 pagesCorrelation and Linear RegressionMudita ChawlaNo ratings yet
- CH 14Document12 pagesCH 14Piyush rajNo ratings yet
- Linear - Regression & Evaluation MetricsDocument31 pagesLinear - Regression & Evaluation Metricsreshma acharyaNo ratings yet
- MODULE 5 and 6 STATISTICS AND PROBABILITY - Docx (1) - PDFDocument9 pagesMODULE 5 and 6 STATISTICS AND PROBABILITY - Docx (1) - PDFGraecel Ramirez100% (2)
- Validity and Reliability: I Qra Development Academy Reporter: Nur - Salam Sultan SEPT. 21, 2019Document22 pagesValidity and Reliability: I Qra Development Academy Reporter: Nur - Salam Sultan SEPT. 21, 2019Nur-salam SultanNo ratings yet
- Schaum's Easy Outline of Probability and Statistics, Revised EditionFrom EverandSchaum's Easy Outline of Probability and Statistics, Revised EditionNo ratings yet
- 2022 Is Online and Distance LearningDocument13 pages2022 Is Online and Distance LearningJohn Lewis SuguitanNo ratings yet
- RRL ExcellenceDocument5 pagesRRL ExcellenceJohn Lewis SuguitanNo ratings yet
- RIZAL031 Life and Works of RizalDocument1 pageRIZAL031 Life and Works of RizalJohn Lewis SuguitanNo ratings yet
- PROCESSORIENTEDAssessmentDocument1 pagePROCESSORIENTEDAssessmentJohn Lewis SuguitanNo ratings yet
- PhilosophyDocument11 pagesPhilosophyJohn Lewis SuguitanNo ratings yet
- TOS IfurungDocument2 pagesTOS IfurungJohn Lewis SuguitanNo ratings yet
- SS 3 Human GeographyDocument8 pagesSS 3 Human GeographyJohn Lewis SuguitanNo ratings yet
- MCTQ PearlDocument1 pageMCTQ PearlJohn Lewis SuguitanNo ratings yet
- ErrorDocument1 pageErrorJohn Lewis SuguitanNo ratings yet
- Assessment ToolDocument1 pageAssessment ToolJohn Lewis SuguitanNo ratings yet
- BALIKAS NI ILOKANO DaniwDocument1 pageBALIKAS NI ILOKANO DaniwJohn Lewis SuguitanNo ratings yet
- Hipparchus FlorenceNightingaleDocument1 pageHipparchus FlorenceNightingaleJohn Lewis SuguitanNo ratings yet
- Earth ScienceDocument9 pagesEarth ScienceJohn Lewis SuguitanNo ratings yet
- Edited LazoDocument53 pagesEdited LazoJohn Lewis SuguitanNo ratings yet
- Pe 1Document4 pagesPe 1John Lewis SuguitanNo ratings yet
- TNT 12 Q1 - 0101 - PS - Definition, Characteristics, and Elements of A TrendDocument43 pagesTNT 12 Q1 - 0101 - PS - Definition, Characteristics, and Elements of A TrendJoed TapuroNo ratings yet
- SS 4 Asian StudiesDocument5 pagesSS 4 Asian StudiesJohn Lewis SuguitanNo ratings yet
- SS 5 Physical GeographyDocument5 pagesSS 5 Physical GeographyJohn Lewis SuguitanNo ratings yet
- ONE WAY TOS IfurungDocument2 pagesONE WAY TOS IfurungJohn Lewis SuguitanNo ratings yet
- RubricDocument1 pageRubricJohn Lewis SuguitanNo ratings yet
- Research Proposal Final GROUP 1 CLUSTER 2 FOR PRINTDocument49 pagesResearch Proposal Final GROUP 1 CLUSTER 2 FOR PRINTJohn Lewis SuguitanNo ratings yet
- Weathering 2Document1 pageWeathering 2John Lewis SuguitanNo ratings yet
- Igneous Rock Metamorphic RockDocument2 pagesIgneous Rock Metamorphic RockJohn Lewis SuguitanNo ratings yet
- Ed217 Counselling SyllabusDocument3 pagesEd217 Counselling SyllabusJohn Lewis SuguitanNo ratings yet
- Research Methodology: Divine Word College of Laoag Graduate SchoolDocument12 pagesResearch Methodology: Divine Word College of Laoag Graduate SchoolJohn Lewis SuguitanNo ratings yet
- 2020-2021 English SyllabusDocument6 pages2020-2021 English SyllabusJohn Lewis SuguitanNo ratings yet
- Redmarks LazoDocument54 pagesRedmarks LazoJohn Lewis SuguitanNo ratings yet
- 2022 Is Online and Distance LearningDocument13 pages2022 Is Online and Distance LearningJohn Lewis SuguitanNo ratings yet
- The Problem Rationale: Divine Word College of Laoag Graduate SchoolDocument20 pagesThe Problem Rationale: Divine Word College of Laoag Graduate SchoolJohn Lewis SuguitanNo ratings yet
- Guided Online/Offline Active Learning (Goal) Videos in Mathematics 3Document16 pagesGuided Online/Offline Active Learning (Goal) Videos in Mathematics 3John Lewis SuguitanNo ratings yet
- Chapter 15Document43 pagesChapter 15mannsahil72No ratings yet
- Predictive Modelling Project - n1Document36 pagesPredictive Modelling Project - n1Girish Chadha100% (4)
- Oliver MonographDocument217 pagesOliver MonographOliver EboyNo ratings yet
- Researching On Factors Affecting Consumers' Decision To Use E5 BIOFUEL in Hanoi CityDocument45 pagesResearching On Factors Affecting Consumers' Decision To Use E5 BIOFUEL in Hanoi CityNhư HảoNo ratings yet
- The Effect of Covid-19 in KabaddiDocument25 pagesThe Effect of Covid-19 in KabaddiShadman RafidNo ratings yet
- The Moderating Effect of Profitability On The Relationship Between Ownership Structure and Corporate Tax Avoidance in Nigeria ListDocument16 pagesThe Moderating Effect of Profitability On The Relationship Between Ownership Structure and Corporate Tax Avoidance in Nigeria ListDivine ugboduNo ratings yet
- 10 - Eda To Prediction DietanicDocument21 pages10 - Eda To Prediction DietanicKhan RafiNo ratings yet
- A Caution Regarding Rules of Thumb For Variance Inflation FactorsDocument18 pagesA Caution Regarding Rules of Thumb For Variance Inflation FactorsParag Jyoti DuttaNo ratings yet
- Merger and AcquisitionsDocument8 pagesMerger and AcquisitionsSandeep SahooNo ratings yet
- Corporate Governance and Cost of Capital in Oecd Countries: Aws AlharesDocument21 pagesCorporate Governance and Cost of Capital in Oecd Countries: Aws AlharesOZZYMANNo ratings yet
- Primer of Applied Regression Analysis of Variance 3Rd Edition Edition Stanton A Glantz All ChapterDocument67 pagesPrimer of Applied Regression Analysis of Variance 3Rd Edition Edition Stanton A Glantz All Chapterjeanette.rasmussen227100% (4)
- Jasa (Jurnal Akuntansi, Audit Dan Sistem Informasi Akuntansi) Vol. 4 No. 1 /april 2020 Issn 2550-0732 Print / Issn 2655-8319 OnlineDocument13 pagesJasa (Jurnal Akuntansi, Audit Dan Sistem Informasi Akuntansi) Vol. 4 No. 1 /april 2020 Issn 2550-0732 Print / Issn 2655-8319 OnlineMoch MunjiNo ratings yet
- Tutorial13 Basic TimeSeriesDocument80 pagesTutorial13 Basic TimeSeriesGhulam NabiNo ratings yet
- Retail Supply Chain Service Levels The Role of Inventory StorageDocument24 pagesRetail Supply Chain Service Levels The Role of Inventory StorageBassma EL GHALBZOURINo ratings yet
- PMIRDocument124 pagesPMIRhashvishuNo ratings yet
- Laekemariam Haile PDFDocument26 pagesLaekemariam Haile PDFchiroNo ratings yet
- Interview QuestionsDocument13 pagesInterview QuestionsPrakash ChandraNo ratings yet
- Determinants of Career Change of Overseas Filipino Professionals in The Middle EastDocument14 pagesDeterminants of Career Change of Overseas Filipino Professionals in The Middle EastLee Hock SengNo ratings yet
- 810007Document4 pages810007Vasim ShaikhNo ratings yet
- Pratama 2020Document4 pagesPratama 2020IrailtonNo ratings yet
- Impact of Provision of Litigation Supports Through Forensic Investigations On Corporate Fraud Prevention in NigeriaDocument8 pagesImpact of Provision of Litigation Supports Through Forensic Investigations On Corporate Fraud Prevention in NigeriaPremier Publishers100% (1)
- Final Report Aman DwivediDocument48 pagesFinal Report Aman Dwivediaman DwivediNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- Najed Massad Sulaiman AlrawashdehDocument53 pagesNajed Massad Sulaiman AlrawashdehNajed RawashdehNo ratings yet
- Trans Employees, Transitioning, and Job SatisfactionDocument54 pagesTrans Employees, Transitioning, and Job SatisfactionUsman AsgharNo ratings yet
- Bagozzi - 1984 - Expectancy-Value Attitude Models An Analysis of Critical Measurement Issues PDFDocument16 pagesBagozzi - 1984 - Expectancy-Value Attitude Models An Analysis of Critical Measurement Issues PDFDante EdwardsNo ratings yet
- Rogersetal JPSP InPress ManuscriptPrepublicationDocument87 pagesRogersetal JPSP InPress ManuscriptPrepublicationApy BobbyNo ratings yet
- Risk ReportingDocument20 pagesRisk ReportingRomy WidjajaNo ratings yet
- Internasional 5Document9 pagesInternasional 5M Rizki Rabbani 1802112922No ratings yet
- Effect of Service Quality On Customer Loyalty: A Study of Hotels in EthiopiaDocument10 pagesEffect of Service Quality On Customer Loyalty: A Study of Hotels in EthiopiaIAEME PublicationNo ratings yet