
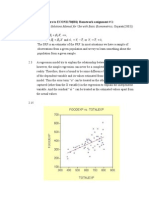
Solution of Problem Set 1 For Purity Hydrocarbon Data PDF
Solution of Problem Set 1 For Purity Hydrocarbon Data PDF
You might also like
- Solution Manual For Elementary Particle Physics An Intuitive Introduction 1st Edition Andrew J LarkoskiDocument38 pagesSolution Manual For Elementary Particle Physics An Intuitive Introduction 1st Edition Andrew J Larkoskiwoolfellinde4jive1100% (26)
- Dokumen - Tips Homework 3 Solution Department of Statistics Ovitekstat526 Spring11filespdfshw3 SolpdfstatDocument12 pagesDokumen - Tips Homework 3 Solution Department of Statistics Ovitekstat526 Spring11filespdfshw3 Solpdfstatbourday RachidNo ratings yet
- Business Statistics Assignment 5 Manish Chauhan (09-1128)Document14 pagesBusiness Statistics Assignment 5 Manish Chauhan (09-1128)manishNo ratings yet
- Intuitive Knowing As Spiritual ExperienceDocument237 pagesIntuitive Knowing As Spiritual ExperienceHugo Martin100% (1)
- Clean Room Requirements 20130927Document5 pagesClean Room Requirements 20130927HNmaichoi100% (1)
- 1 Background and Essentials: Answer: 10 nm-400 NM Corresponds To 124 Ev-3.1 EvDocument4 pages1 Background and Essentials: Answer: 10 nm-400 NM Corresponds To 124 Ev-3.1 EvhaifaniaNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- EconometricsII ExercisesDocument27 pagesEconometricsII ExercisesAkriti TrivediNo ratings yet
- CHP8 Practice QuestionsDocument15 pagesCHP8 Practice QuestionsTanmay TingreNo ratings yet
- Lecture Week3 V4Document16 pagesLecture Week3 V4raghav gargNo ratings yet
- HW10 Solu F09Document4 pagesHW10 Solu F09Nimroz MominNo ratings yet
- PLDocument5 pagesPLMy SpotifyNo ratings yet
- Linear Regression in RDocument7 pagesLinear Regression in Rmeric8669No ratings yet
- CHP8Document12 pagesCHP8Tanmay TingreNo ratings yet
- Principles 2 PDFDocument17 pagesPrinciples 2 PDFHasan AkhuamariNo ratings yet
- 0802 0691 PDFDocument21 pages0802 0691 PDFGalina AlexeevaNo ratings yet
- Exam1 02A PDFDocument6 pagesExam1 02A PDFCrizaldo MempinNo ratings yet
- Inference in The Regression ModelDocument4 pagesInference in The Regression ModelboNo ratings yet
- MS Excel BiochemistryDocument5 pagesMS Excel BiochemistryMarie St. Louis100% (1)
- Pract Exam 1Document5 pagesPract Exam 1Deepak Kumar DubeyNo ratings yet
- Assignment 2Document4 pagesAssignment 2mohamed ezzatNo ratings yet
- Linear Regression: March 28, 2013Document17 pagesLinear Regression: March 28, 2013dulanjaya jayalathNo ratings yet
- Assignment 3 MATH 277Document2 pagesAssignment 3 MATH 277R Nurul QANo ratings yet
- Testing of Hypothesis For Difference Between Population MeansDocument19 pagesTesting of Hypothesis For Difference Between Population MeansMainNo ratings yet
- Dsba SolutionDocument2 pagesDsba SolutionA011 Aman BakshiNo ratings yet
- Exam121022 SolDocument6 pagesExam121022 Solchiedzad madondoNo ratings yet
- Test 18Document2 pagesTest 18umamiNo ratings yet
- Keyws13 4Document9 pagesKeyws13 4aaaaaNo ratings yet
- Lec3 ppt2019Document18 pagesLec3 ppt2019lcaccompanyNo ratings yet
- SK025 KMJ Pre PSPM Set 4 (Solution)Document5 pagesSK025 KMJ Pre PSPM Set 4 (Solution)2022674978No ratings yet
- PS Solutions Chapter 14Document5 pagesPS Solutions Chapter 14Michael SubrotoNo ratings yet
- D Linear Regression With RDocument9 pagesD Linear Regression With RBùi Nguyên HoàngNo ratings yet
- Suggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YDocument7 pagesSuggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YPilSeung HeoNo ratings yet
- MIT18 05S14 ps9 Solutions PDFDocument5 pagesMIT18 05S14 ps9 Solutions PDFMd CassimNo ratings yet
- Actividad-David Sierra SalazarDocument10 pagesActividad-David Sierra Salazarfarid perez bustoNo ratings yet
- Hypothesis Testing in Multiple Linear Regression: BIOST 515 January 20, 2004Document28 pagesHypothesis Testing in Multiple Linear Regression: BIOST 515 January 20, 2004HazemIbrahimNo ratings yet
- Module 5Document28 pagesModule 5Eugene James Gonzales PalmesNo ratings yet
- Lecture Notes 7 1 1Document12 pagesLecture Notes 7 1 1Asad RazaNo ratings yet
- Mathematical Tripos: at The End of The ExaminationDocument27 pagesMathematical Tripos: at The End of The ExaminationDedliNo ratings yet
- Examples EconometricsDocument9 pagesExamples EconometricsAhihiNo ratings yet
- CUHK STAT3004 Assignment2 SolutionDocument4 pagesCUHK STAT3004 Assignment2 Solution屁屁豬No ratings yet
- Week6 Assignment SolutionsDocument14 pagesWeek6 Assignment Solutionsvicky.sajnaniNo ratings yet
- RegressionDocument7 pagesRegressionraj persaudNo ratings yet
- Sample Applied Statistics and Probability For EngineersDocument7 pagesSample Applied Statistics and Probability For EngineersALBERT DAODANo ratings yet
- Calibration CurveDocument13 pagesCalibration Curvecinvehbi711No ratings yet
- Numerical Methods: King Saud UniversityDocument24 pagesNumerical Methods: King Saud UniversityMalikAlrahabiNo ratings yet
- FandI CT3 200604 ReportDocument11 pagesFandI CT3 200604 Reportpriyanshu1495No ratings yet
- EE 627: Term 2/2016 Homework 4 Due April 25, 2017: Solution: The Autoregressive Polynomial Can Be Factorized AsDocument4 pagesEE 627: Term 2/2016 Homework 4 Due April 25, 2017: Solution: The Autoregressive Polynomial Can Be Factorized AsluscNo ratings yet
- 2022 SUMATH3020 Day 15Document4 pages2022 SUMATH3020 Day 15Abby HorneNo ratings yet
- Maths Hpas-2017 Main Paper I Q2-Q3Document5 pagesMaths Hpas-2017 Main Paper I Q2-Q3sanjayb1976gmailcomNo ratings yet
- Econ0064 Final Exam 2018-19 Term3Document7 pagesEcon0064 Final Exam 2018-19 Term3nirujank123No ratings yet
- MAST20005 Statistics Assignment 2Document9 pagesMAST20005 Statistics Assignment 2Anonymous na314kKjOANo ratings yet
- 2101 F 17 Assignment 1Document8 pages2101 F 17 Assignment 1dflamsheepsNo ratings yet
- Tugas MTKDocument24 pagesTugas MTKGhalih Hakiki KavisaNo ratings yet
- Summation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable CoefficientsDocument33 pagesSummation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable Coefficientsadsfhire fklwjeNo ratings yet
- Answer Form Experimental Problem No. 2 Birefringence of Mica Task 2.1 A) Experimental Setup For I - (0.5 Points)Document14 pagesAnswer Form Experimental Problem No. 2 Birefringence of Mica Task 2.1 A) Experimental Setup For I - (0.5 Points)PhanNo ratings yet
- Regression Midterm SheetDocument10 pagesRegression Midterm SheetEllianna BrandelNo ratings yet
- Mid Sem Papaer - RoboticsDocument2 pagesMid Sem Papaer - RoboticsshubhamNo ratings yet
- B. Frequency Domain Representation of Lti Systems: ObjectiveDocument4 pagesB. Frequency Domain Representation of Lti Systems: Objectivenaiksuresh100% (1)
- Catalogue V2 - 2012 Final (Full Copy)Document132 pagesCatalogue V2 - 2012 Final (Full Copy)Richard PayneNo ratings yet
- Speed Control of Three Phase Induction MotorDocument28 pagesSpeed Control of Three Phase Induction MotorRajeev Valunjkar100% (1)
- Mandakini Hydropower Limited PDFDocument42 pagesMandakini Hydropower Limited PDFAnil KhanalNo ratings yet
- Dialysis: Prepared byDocument31 pagesDialysis: Prepared byVimal PatelNo ratings yet
- Tiruvannamalai and RajinikanthDocument2 pagesTiruvannamalai and RajinikanthashokhaNo ratings yet
- The Benefits of Prayer Wheels: by Lama Zopa RinpocheDocument2 pagesThe Benefits of Prayer Wheels: by Lama Zopa RinpocheThiagoFerrettiNo ratings yet
- General Chemistry 1: Quarter 2 - Module 4 Polymers & BiomoleculesDocument22 pagesGeneral Chemistry 1: Quarter 2 - Module 4 Polymers & BiomoleculesKaren de los ReyesNo ratings yet
- Essential Conditions For Efficient Engine OperationDocument4 pagesEssential Conditions For Efficient Engine OperationMelanie Saldivar CapalunganNo ratings yet
- HomeAwayJamalMahjoub WSTEXTDocument11 pagesHomeAwayJamalMahjoub WSTEXTVanDesignsNo ratings yet
- Experiment 1: Latent Heat of Liquid Nitrogen: On OffDocument2 pagesExperiment 1: Latent Heat of Liquid Nitrogen: On Offjmccarthy_03No ratings yet
- Emccd CameraDocument4 pagesEmccd CameraJongsoo KimNo ratings yet
- Home Science Biology Molecular Biology Difference Between Purines and Pyrimidines Difference Between Purines and PyrimidinesDocument11 pagesHome Science Biology Molecular Biology Difference Between Purines and Pyrimidines Difference Between Purines and PyrimidinesChala Tekalign HareruNo ratings yet
- Banaba, The Scientific Name of Which IsDocument2 pagesBanaba, The Scientific Name of Which Iskill_noj_olarcNo ratings yet
- 3 Legged 5 Why - Effective Root Cause AnalysisDocument40 pages3 Legged 5 Why - Effective Root Cause AnalysisJohn OoNo ratings yet
- 90203-1085DEB Arc Welding Operation Manual (D Series)Document178 pages90203-1085DEB Arc Welding Operation Manual (D Series)Ihcene BoudaliNo ratings yet
- Posture ClassDocument56 pagesPosture Classnarainder kumarNo ratings yet
- Class 8 Chapter 5 The Summit WithinDocument6 pagesClass 8 Chapter 5 The Summit WithinPrathamesh . M LaddhadNo ratings yet
- B737 PneumaticsDocument9 pagesB737 Pneumaticsgreg mNo ratings yet
- Foundations Expansive Soils: Chen CDocument6 pagesFoundations Expansive Soils: Chen CBolton Alonso Yanqui SotoNo ratings yet
- ProjectDocument32 pagesProjectFavour NwachukwuNo ratings yet
- Week 4 - Stadelman-Cohen & Hillman (2014)Document22 pagesWeek 4 - Stadelman-Cohen & Hillman (2014)kehanNo ratings yet
- BU-00038-Grinding - Polishing - Brochure - BU Automet250Document36 pagesBU-00038-Grinding - Polishing - Brochure - BU Automet250Atul KumarNo ratings yet
- Pore Pressure-Engineering GeologyDocument26 pagesPore Pressure-Engineering GeologyChiranjaya HulangamuwaNo ratings yet
- MaritimeReporter1989 12 01Document58 pagesMaritimeReporter1989 12 01vinipaulinoNo ratings yet
- Test-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseDocument10 pagesTest-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseCabinet VeterinarNo ratings yet
- 04 - Rotational Motion - JEE PDFDocument124 pages04 - Rotational Motion - JEE PDFCefas Almeida50% (2)
- S 5Document2 pagesS 5Neethu Krishna KNo ratings yet
- MSDS Bentonil API (BENTONITE) - PT CLARIANTDocument6 pagesMSDS Bentonil API (BENTONITE) - PT CLARIANTDikta amelia lorensaNo ratings yet
























































































Download as pdf or txt
You might also like
- Solution Manual For Elementary Particle Physics An Intuitive Introduction 1st Edition Andrew J LarkoskiDocument38 pagesSolution Manual For Elementary Particle Physics An Intuitive Introduction 1st Edition Andrew J Larkoskiwoolfellinde4jive1100% (26)
- Dokumen - Tips Homework 3 Solution Department of Statistics Ovitekstat526 Spring11filespdfshw3 SolpdfstatDocument12 pagesDokumen - Tips Homework 3 Solution Department of Statistics Ovitekstat526 Spring11filespdfshw3 Solpdfstatbourday RachidNo ratings yet
- Business Statistics Assignment 5 Manish Chauhan (09-1128)Document14 pagesBusiness Statistics Assignment 5 Manish Chauhan (09-1128)manishNo ratings yet
- Intuitive Knowing As Spiritual ExperienceDocument237 pagesIntuitive Knowing As Spiritual ExperienceHugo Martin100% (1)
- Clean Room Requirements 20130927Document5 pagesClean Room Requirements 20130927HNmaichoi100% (1)
- 1 Background and Essentials: Answer: 10 nm-400 NM Corresponds To 124 Ev-3.1 EvDocument4 pages1 Background and Essentials: Answer: 10 nm-400 NM Corresponds To 124 Ev-3.1 EvhaifaniaNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- EconometricsII ExercisesDocument27 pagesEconometricsII ExercisesAkriti TrivediNo ratings yet
- CHP8 Practice QuestionsDocument15 pagesCHP8 Practice QuestionsTanmay TingreNo ratings yet
- Lecture Week3 V4Document16 pagesLecture Week3 V4raghav gargNo ratings yet
- HW10 Solu F09Document4 pagesHW10 Solu F09Nimroz MominNo ratings yet
- PLDocument5 pagesPLMy SpotifyNo ratings yet
- Linear Regression in RDocument7 pagesLinear Regression in Rmeric8669No ratings yet
- CHP8Document12 pagesCHP8Tanmay TingreNo ratings yet
- Principles 2 PDFDocument17 pagesPrinciples 2 PDFHasan AkhuamariNo ratings yet
- 0802 0691 PDFDocument21 pages0802 0691 PDFGalina AlexeevaNo ratings yet
- Exam1 02A PDFDocument6 pagesExam1 02A PDFCrizaldo MempinNo ratings yet
- Inference in The Regression ModelDocument4 pagesInference in The Regression ModelboNo ratings yet
- MS Excel BiochemistryDocument5 pagesMS Excel BiochemistryMarie St. Louis100% (1)
- Pract Exam 1Document5 pagesPract Exam 1Deepak Kumar DubeyNo ratings yet
- Assignment 2Document4 pagesAssignment 2mohamed ezzatNo ratings yet
- Linear Regression: March 28, 2013Document17 pagesLinear Regression: March 28, 2013dulanjaya jayalathNo ratings yet
- Assignment 3 MATH 277Document2 pagesAssignment 3 MATH 277R Nurul QANo ratings yet
- Testing of Hypothesis For Difference Between Population MeansDocument19 pagesTesting of Hypothesis For Difference Between Population MeansMainNo ratings yet
- Dsba SolutionDocument2 pagesDsba SolutionA011 Aman BakshiNo ratings yet
- Exam121022 SolDocument6 pagesExam121022 Solchiedzad madondoNo ratings yet
- Test 18Document2 pagesTest 18umamiNo ratings yet
- Keyws13 4Document9 pagesKeyws13 4aaaaaNo ratings yet
- Lec3 ppt2019Document18 pagesLec3 ppt2019lcaccompanyNo ratings yet
- SK025 KMJ Pre PSPM Set 4 (Solution)Document5 pagesSK025 KMJ Pre PSPM Set 4 (Solution)2022674978No ratings yet
- PS Solutions Chapter 14Document5 pagesPS Solutions Chapter 14Michael SubrotoNo ratings yet
- D Linear Regression With RDocument9 pagesD Linear Regression With RBùi Nguyên HoàngNo ratings yet
- Suggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YDocument7 pagesSuggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YPilSeung HeoNo ratings yet
- MIT18 05S14 ps9 Solutions PDFDocument5 pagesMIT18 05S14 ps9 Solutions PDFMd CassimNo ratings yet
- Actividad-David Sierra SalazarDocument10 pagesActividad-David Sierra Salazarfarid perez bustoNo ratings yet
- Hypothesis Testing in Multiple Linear Regression: BIOST 515 January 20, 2004Document28 pagesHypothesis Testing in Multiple Linear Regression: BIOST 515 January 20, 2004HazemIbrahimNo ratings yet
- Module 5Document28 pagesModule 5Eugene James Gonzales PalmesNo ratings yet
- Lecture Notes 7 1 1Document12 pagesLecture Notes 7 1 1Asad RazaNo ratings yet
- Mathematical Tripos: at The End of The ExaminationDocument27 pagesMathematical Tripos: at The End of The ExaminationDedliNo ratings yet
- Examples EconometricsDocument9 pagesExamples EconometricsAhihiNo ratings yet
- CUHK STAT3004 Assignment2 SolutionDocument4 pagesCUHK STAT3004 Assignment2 Solution屁屁豬No ratings yet
- Week6 Assignment SolutionsDocument14 pagesWeek6 Assignment Solutionsvicky.sajnaniNo ratings yet
- RegressionDocument7 pagesRegressionraj persaudNo ratings yet
- Sample Applied Statistics and Probability For EngineersDocument7 pagesSample Applied Statistics and Probability For EngineersALBERT DAODANo ratings yet
- Calibration CurveDocument13 pagesCalibration Curvecinvehbi711No ratings yet
- Numerical Methods: King Saud UniversityDocument24 pagesNumerical Methods: King Saud UniversityMalikAlrahabiNo ratings yet
- FandI CT3 200604 ReportDocument11 pagesFandI CT3 200604 Reportpriyanshu1495No ratings yet
- EE 627: Term 2/2016 Homework 4 Due April 25, 2017: Solution: The Autoregressive Polynomial Can Be Factorized AsDocument4 pagesEE 627: Term 2/2016 Homework 4 Due April 25, 2017: Solution: The Autoregressive Polynomial Can Be Factorized AsluscNo ratings yet
- 2022 SUMATH3020 Day 15Document4 pages2022 SUMATH3020 Day 15Abby HorneNo ratings yet
- Maths Hpas-2017 Main Paper I Q2-Q3Document5 pagesMaths Hpas-2017 Main Paper I Q2-Q3sanjayb1976gmailcomNo ratings yet
- Econ0064 Final Exam 2018-19 Term3Document7 pagesEcon0064 Final Exam 2018-19 Term3nirujank123No ratings yet
- MAST20005 Statistics Assignment 2Document9 pagesMAST20005 Statistics Assignment 2Anonymous na314kKjOANo ratings yet
- 2101 F 17 Assignment 1Document8 pages2101 F 17 Assignment 1dflamsheepsNo ratings yet
- Tugas MTKDocument24 pagesTugas MTKGhalih Hakiki KavisaNo ratings yet
- Summation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable CoefficientsDocument33 pagesSummation by Parts Operators For Finite Difference Approximations of Second-Derivatives With Variable Coefficientsadsfhire fklwjeNo ratings yet
- Answer Form Experimental Problem No. 2 Birefringence of Mica Task 2.1 A) Experimental Setup For I - (0.5 Points)Document14 pagesAnswer Form Experimental Problem No. 2 Birefringence of Mica Task 2.1 A) Experimental Setup For I - (0.5 Points)PhanNo ratings yet
- Regression Midterm SheetDocument10 pagesRegression Midterm SheetEllianna BrandelNo ratings yet
- Mid Sem Papaer - RoboticsDocument2 pagesMid Sem Papaer - RoboticsshubhamNo ratings yet
- B. Frequency Domain Representation of Lti Systems: ObjectiveDocument4 pagesB. Frequency Domain Representation of Lti Systems: Objectivenaiksuresh100% (1)
- Catalogue V2 - 2012 Final (Full Copy)Document132 pagesCatalogue V2 - 2012 Final (Full Copy)Richard PayneNo ratings yet
- Speed Control of Three Phase Induction MotorDocument28 pagesSpeed Control of Three Phase Induction MotorRajeev Valunjkar100% (1)
- Mandakini Hydropower Limited PDFDocument42 pagesMandakini Hydropower Limited PDFAnil KhanalNo ratings yet
- Dialysis: Prepared byDocument31 pagesDialysis: Prepared byVimal PatelNo ratings yet
- Tiruvannamalai and RajinikanthDocument2 pagesTiruvannamalai and RajinikanthashokhaNo ratings yet
- The Benefits of Prayer Wheels: by Lama Zopa RinpocheDocument2 pagesThe Benefits of Prayer Wheels: by Lama Zopa RinpocheThiagoFerrettiNo ratings yet
- General Chemistry 1: Quarter 2 - Module 4 Polymers & BiomoleculesDocument22 pagesGeneral Chemistry 1: Quarter 2 - Module 4 Polymers & BiomoleculesKaren de los ReyesNo ratings yet
- Essential Conditions For Efficient Engine OperationDocument4 pagesEssential Conditions For Efficient Engine OperationMelanie Saldivar CapalunganNo ratings yet
- HomeAwayJamalMahjoub WSTEXTDocument11 pagesHomeAwayJamalMahjoub WSTEXTVanDesignsNo ratings yet
- Experiment 1: Latent Heat of Liquid Nitrogen: On OffDocument2 pagesExperiment 1: Latent Heat of Liquid Nitrogen: On Offjmccarthy_03No ratings yet
- Emccd CameraDocument4 pagesEmccd CameraJongsoo KimNo ratings yet
- Home Science Biology Molecular Biology Difference Between Purines and Pyrimidines Difference Between Purines and PyrimidinesDocument11 pagesHome Science Biology Molecular Biology Difference Between Purines and Pyrimidines Difference Between Purines and PyrimidinesChala Tekalign HareruNo ratings yet
- Banaba, The Scientific Name of Which IsDocument2 pagesBanaba, The Scientific Name of Which Iskill_noj_olarcNo ratings yet
- 3 Legged 5 Why - Effective Root Cause AnalysisDocument40 pages3 Legged 5 Why - Effective Root Cause AnalysisJohn OoNo ratings yet
- 90203-1085DEB Arc Welding Operation Manual (D Series)Document178 pages90203-1085DEB Arc Welding Operation Manual (D Series)Ihcene BoudaliNo ratings yet
- Posture ClassDocument56 pagesPosture Classnarainder kumarNo ratings yet
- Class 8 Chapter 5 The Summit WithinDocument6 pagesClass 8 Chapter 5 The Summit WithinPrathamesh . M LaddhadNo ratings yet
- B737 PneumaticsDocument9 pagesB737 Pneumaticsgreg mNo ratings yet
- Foundations Expansive Soils: Chen CDocument6 pagesFoundations Expansive Soils: Chen CBolton Alonso Yanqui SotoNo ratings yet
- ProjectDocument32 pagesProjectFavour NwachukwuNo ratings yet
- Week 4 - Stadelman-Cohen & Hillman (2014)Document22 pagesWeek 4 - Stadelman-Cohen & Hillman (2014)kehanNo ratings yet
- BU-00038-Grinding - Polishing - Brochure - BU Automet250Document36 pagesBU-00038-Grinding - Polishing - Brochure - BU Automet250Atul KumarNo ratings yet
- Pore Pressure-Engineering GeologyDocument26 pagesPore Pressure-Engineering GeologyChiranjaya HulangamuwaNo ratings yet
- MaritimeReporter1989 12 01Document58 pagesMaritimeReporter1989 12 01vinipaulinoNo ratings yet
- Test-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseDocument10 pagesTest-Retest Reliability of The Speech-Evoked Auditory Brainstem ResponseCabinet VeterinarNo ratings yet
- 04 - Rotational Motion - JEE PDFDocument124 pages04 - Rotational Motion - JEE PDFCefas Almeida50% (2)
- S 5Document2 pagesS 5Neethu Krishna KNo ratings yet
- MSDS Bentonil API (BENTONITE) - PT CLARIANTDocument6 pagesMSDS Bentonil API (BENTONITE) - PT CLARIANTDikta amelia lorensaNo ratings yet